使用 R 语言挖掘 QQ 群聊天记录
1、获取数据
从 QQ 消息管理器中导出消息记录,保存的文本类型选择 txt 文件。这里获取的是某群从 2016-04-18 到 2016-05-07 期间的聊天记录,记录样本如下所示。
消息记录(此消息记录为文本格式,不支持重新导入) ================================================================
消息分组:我的QQ群
================================================================
消息对象:QQGroup
================================================================ 2016-04-18 20:04:00 谁来弄死我(1122334455)
ip 主机名 2016-04-18 20:04:20 我来弄死谁(66554432)
这个我配了 2016-04-18 20:04:29 我来弄死谁(66554432)
hadoop集群是正常的 2016-04-18 20:05:07 谁来弄死我(1122334455)
自己找吧 2016-04-18 20:05:20 我来弄死谁(66554432)
spark集群运行作业的时候就抱这错了 2016-04-18 20:05:29 我来弄死谁(66554432)
我都找了好几天了
2、数据预处理
打开 R 软件,先通过 File—>Change dir 切换到聊天文件所在目录。
引入包:
library(stringr)
library(plyr)
library(lubridate)
library(ggplot2)
library(reshape2)
library(igraph)
没有的包要通过命令 install.packages(”扩展包名”) 安装。
读取聊天记录文件到内存:
qqsrcdata<-readLines("QQGroup.txt",encoding="UTF-8")
这里我们不关心聊天内容,只看时间和发言人,所以,我们把类似 “2016-04-18 20:04:20 我来弄死谁(66554432)” 这样的内容提取出来。这里要用到正则表达式,对此不懂的可参考 正则表达式30分钟入门教程。对 R 语言的 grep、sub、gregexpr 等字符串处理函数不熟的,网上搜一下,资料多的是。
srcdata<-qqsrcdata[grep("^\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2} .+$",qqsrcdata)]
看看 srcdata 内容,就已经全是发言时间和发言人信息了,没有其它闲杂数据。
然后再从 srcdata 中提取发言时间和发言人信息,分别存到列表 data 的 time 和 id 中。对发言人信息的提取很简单:
data={} # 创建一个空的 list
data$id<-sub("\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2} ", "", srcdata)
对发言时间的提取要稍麻烦些,因为时间字符串的长度不一样,有些是 18 位,如 “2016-04-18 7:36:32”,有些是 19 位,如 “2016-04-18 19:24:01”,所以,在提取时间时,需先用 gregexpr 确定时间字符串的起始和结束位置,然后再用 substring 提取出相应的时间,注意 substring 和 sub 是不同的函数。
getcontent <- function(s,g){
substring(s,g,g+attr(g,'match.length')-1) # 读取 s 中的数据
}
gg<-gregexpr("\\d{4}-\\d{2}-\\d{2} \\d+:\\d{2}:\\d{2}",srcdata,perl=TRUE)
for(j in 1:length(gg))
{
data$time[j]<-getcontent(srcdata[j],gg[[j]])
}
现在时间和发言人信息都读到 data 的 time 和 id 中了,可以确认下提取内容:data、data$id、data$time。
还没完,时间还是字符串,还需要继续处理:
# 数据整理
# 将字符串中的日期和时间划分为不同变量
temp1 <- str_split(data$time,' ')
result1 <- ldply(temp1,.fun=NULL)
names(result1) <- c('date','clock') #分离年月日
temp2 <- str_split(result1$date,'-')
result2 <- ldply(temp2,.fun=NULL)
names(result2) <- c('year','month','day') # 分离小时分钟
temp3 <- str_split(result1$clock,':')
result3 <- ldply(temp3,.fun=NULL)
names(result3) <- c('hour','minutes','second') # 合并数据
newdata <- cbind(data,result1,result2,result3) # 转换日期为时间格式
newdata$date <- ymd(newdata$date) # 提取星期数据
newdata$wday <- wday(newdata$date) # 转换数据格式
newdata$month <- ordered(as.numeric(newdata$month) )
newdata$year <- ordered(newdata$year)
newdata$day <- ordered(as.numeric(newdata$day))
newdata$hour <- ordered(as.numeric(newdata$hour))
newdata$wday <- ordered(newdata$wday)
至此,数据预处理完成,时间和发言人数据都已合适地存到 newdata 中,可以开始任性地分析了~
3、数据分析
- 一星期中每天合计的聊天记录次数,可以看到该 QQ 群的聊天兴致随星期的分布。
qplot(wday,data=newdata,geom='bar')
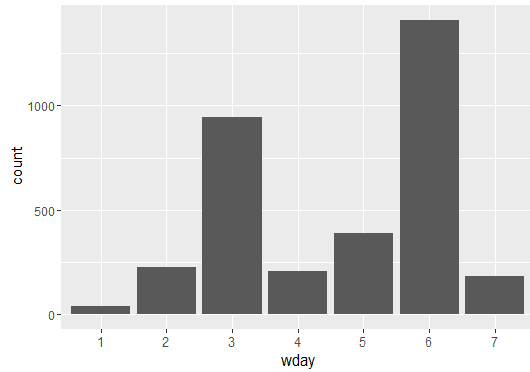
周三是工作日,还这么活跃,周六话最多,周日估计出去玩了,周一专心上班。
- 聊天兴致在一天中的分布。
qplot(hour,data=newdata,geom='bar')
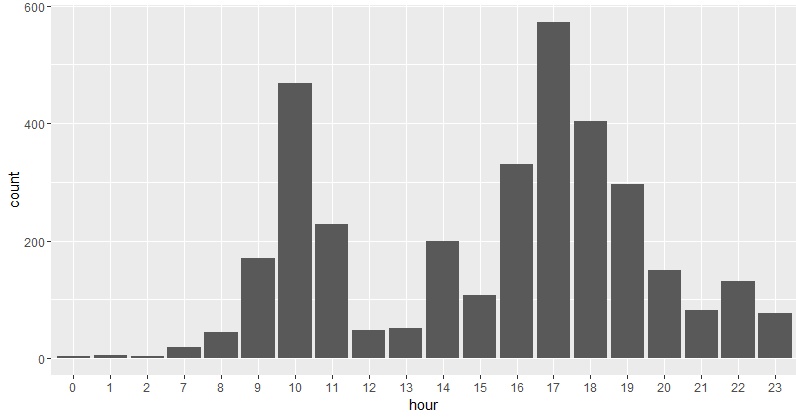
这群一天中聊得最嗨的是上午 10 点和下午 17 点,形成两个高峰。
- 前十大发言最多用户
user <- as.data.frame(table(newdata$id)) # 用 table 统计频数
user <- user[order(user$Freq,decreasing=T),]
user[1:10,] # 显示前十大发言人的 ID 和 发言次数
topuser <- user[1:10,]$Var1 # 存前十大发言人的 ID

- 根据活跃天数统计前十大活跃用户
# 活跃天数计算
# 将数据展开为宽表,每一行为用户,每一列为日期,对应数值为发言次数
flat.day <- dcast(newdata,id~date,length,value.var='date')
flat.mat <- as.matrix(flat.day[-1]) #转为矩阵
# 转为0-1值,以观察是否活跃
flat.mat <- ifelse(flat.mat>0,1,0)
# 根据上线天数求和
topday <- data.frame(flat.day[,1],apply(flat.mat,1,sum))
names(topday) <- c('id','days')
topday <- topday[order(topday$days,decreasing=T),]
# 获得前十大活跃用户
topday[1:10,]

- 寻找聊天峰值日
# 观察每天的发言次数
# online.day为每天的发言次数
online.day <- sapply(flat.day[,-1],sum) # -1 表示去除第一列,第一列是 ID
tempdf <- data.frame(time=ymd(names(online.day)),online.day )
qplot(x=time,y=online.day ,ymin=0,ymax=online.day ,data=tempdf,geom='linerange')# 观察到有少数峰值日,看超过200次发言以上是哪几天
names(which(online.day>200))
- 每天活跃人数统计
#根据flat.day数据观察每天活跃用户变化
# numday为每天发言人数
numday <- apply(flat.mat,2,sum)
tempdf <- data.frame(time=ymd(names(numday)),numday)
qplot(x=time,y=numday,ymin=0,ymax=numday,data=tempdf,geom='linerange')
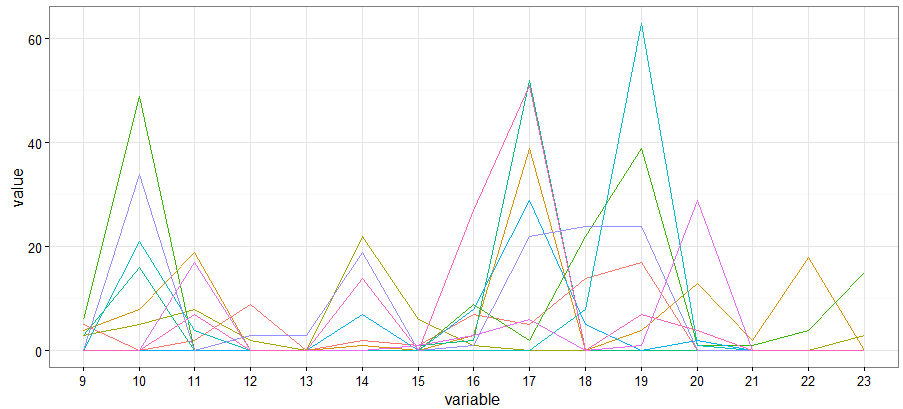
- 十强选手的日内情况
# 再观察十强选手的日内情况
flat.hour <- dcast(newdata,id~hour,length,value.var='hour',subset=.(id %in% topuser))
# 平行坐标图
hour.melt <- melt(flat.hour)
p <- ggplot(data=hour.melt,aes(x=variable,y=value))
p + geom_line(aes(group=id,color=id))+theme_bw()+theme(legend.position = "none")
- 连续对话的次数,以三十分钟为间隔
# 连续对话的次数,以三十分钟为间隔
newdata$realtime <- strptime(newdata$time,'%Y-%m-%d %H:%M')
# 时间排序有问题,按时间重排数据
newdata2 <- newdata[order(newdata$realtime),]
# 将数据按讨论来分组
group <- rep(1,dim(newdata2)[1])
for (i in 2:dim(newdata2)[1]) {
d <- as.numeric(difftime(newdata2$realtime[i],
newdata2$realtime[i-1],
units='mins'))
if ( d < 30) {
group[i] <- group[i-1]
}
else {group[i] <- group[i-1]+1}
}
barplot(table(group))

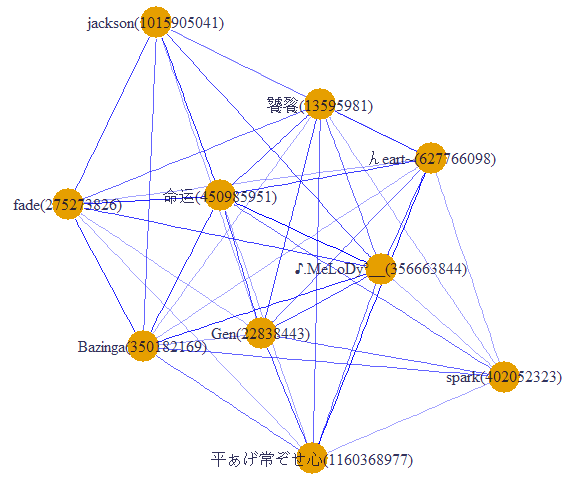
- 画社交网络图
# 得到 93 多组对话
newdata2$group <- group # igraph进行十强之间的网络分析
# 建立关系矩阵,如果两个用户同时在一次群讨论中出现,则计数+1
newdata3 <- dcast(newdata2, id~group, sum,value.var='group',subset=.(id %in% user[1:10,]$Var1))#
newdata4 <- ifelse(newdata3[,-1] > 0, 1, 0)
rownames(newdata4) <- newdata3[,1]
relmatrix <- newdata4 %*% t(newdata4)
# 很容易看出哪两个人聊得最多
deldiag <- relmatrix-diag(diag(relmatrix))
which(deldiag==max(deldiag),arr.ind=T) # 根据关系矩阵画社交网络画
g <- graph.adjacency(deldiag,weighted=T,mode='undirected')
g <-simplify(g)
V(g)$label<-rownames(relmatrix)
V(g)$degree<- degree(g)
layout1 <- layout.fruchterman.reingold(g)
#egam <- 10*E(g)$weight/max(E(g)$weight)
egam <- (log(E(g)$weight)+1) / max(log(E(g)$weight)+1)
#V(g)$label.cex <- V(g)$degree / max(V(g)$degree)+ .2
V(g)$label.color <- rgb(0, 0, .2, .8)
V(g)$frame.color <- NA
E(g)$width <- egam
E(g)$color <- rgb(0, 0, 1, egam)
plot(g, layout=layout1)
- 找到配对
#找到配对
pairlist=data.frame(pair=1:length(attributes(deldiag)$dimnames[[1]]))
rownames(pairlist)<-attributes(deldiag)$dimnames[[1]] for(i in (1:length(deldiag[1,])))
{
pairlist[i,1]<-attributes(which(deldiag[i,]==max(deldiag[i,]),arr.ind=T))$names[1]
}
pairlist pairmatrix=data.frame(pairA=1:length(attributes(deldiag)$dimnames[[1]]),pairB=1:length(attributes(deldiag)$dimnames[[1]]))
pairmatrix=data.frame(pair=1:length(attributes(deldiag)$dimnames[[1]])) for(i in (1:dim(deldiag)[1]))
{
deldiag[i,] <- ifelse(deldiag[i,] == max(deldiag[i,]), 1, 0)
}
deldiag

参考资料:
[1] 正则表达式30分钟入门教程
[2] 来玩玩QQ群的数据
使用 R 语言挖掘 QQ 群聊天记录的更多相关文章
- QQ群聊天记录文件分割
嗯,如题 是个蛋疼物 目前QQ的聊天记录导出功能很让人郁闷 三种聊天记录格式的导出 1 TXT 没图 2 BAK 只能再导入QQ使用 3 MHT 有图有字,缺点是一旦聊天记录很多,文件体积 ...
- 特定用户QQ群聊天记录导出的实现
一.把QQ群的聊天记录txt格式导出 消息管理器 -> 选择要导出的群 -> 右击.导出 这里要注意 : 导出之后的 文本是 unicode 编码的,需要转换 ==|| 之前不知道,搞 ...
- R语言绘制QQ图
无论是直方图还是经验分布图,要从比较上鉴别样本是否处近似于某种类型的分布是困难的 QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布 R语言,代码如下: > qqnorm(w);qqline ...
- 一梦江湖费六年——QQ群聊天分析
本文结构: 一.那些年我们加过的QQ群 二.数据读入和整理(一)--来自蓝翔的挖掘机 二.数据读入和整理(二)--你不知道的事 三.聊天宏观(1)--寤寐思服 三.聊天宏观(2)日月篇 三.聊天宏观( ...
- R语言︱异常值检验、离群点分析、异常值处理
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:异常值处理一般分为以下几个步骤:异常 ...
- R语言︱处理缺失数据&&异常值检验、离群点分析、异常值处理
在数据挖掘的过程中,数据预处理占到了整个过程的60% 脏数据:指一般不符合要求,以及不能直接进行相应分析的数据 脏数据包括:缺失值.异常值.不一致的值.重复数据及含有特殊符号(如#.¥.*)的数据 数 ...
- 零基础数据分析与挖掘R语言实战课程(R语言)
随着大数据在各行业的落地生根和蓬勃发展,能从数据中挖金子的数据分析人员越来越宝贝,于是很多的程序员都想转行到数据分析, 挖掘技术哪家强?当然是R语言了,R语言的火热程度,从TIOBE上编程语言排名情况 ...
- [译]用R语言做挖掘数据《五》
介绍 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: 1. ...
- [译]用R语言做挖掘数据《四》
回归 一.实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 2. 环境介绍 本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到程序: 1. ...
随机推荐
- spring管理的类如何调用非spring管理的类
spring管理的类如何调用非spring管理的类. 就是使用一个spring提供的感知概念,在容器启动的时候,注入上下文即可. 下面是一个工具类. import org.springframewor ...
- spring和springboot
Spring四大原则: 1.使用POJO进行轻量级和最小侵入式开发 2.通过依赖注入和基于接口编程实现松耦合 3,.通过AOP和默认习惯进行声明式编程 4.使用AOP和模版template减少模式化代 ...
- nginx安装lua模块实现高并发
nginx安装lua扩展模块 1.下载安装LuaJIT-2.0.4.tar.gz wget -c http://luajit.org/download/LuaJIT-2.0.4.tar.gz tar ...
- vue-cli 搭建的项目,无法用本地IP访问
项目是用vue-cli搭建的,是基于移动端的,需要在手机上测试的时候发现用ip访问不了,用localhost是可以访问的,网上查资料的解决办法(此为Mac机子的解决办法): 在config文件里面的i ...
- 家庭记账本之微信小程序(五)
wxml的学习 WXML(WeiXin Markup Language)是框架设计的一套标签语言,结合基础组件.事件系统,可以构建出页面的结构. 用以下一些简单的例子来看看WXML具有什么能力: 数据 ...
- JS关键字和保留字汇总(小记)
ECMA-262 描述了一组具有特定用途的关键字.这些关键字可用于表示控制语句的开始或结束,或者用于执行特定操作等.按照规则,关键字也是语言保留的,不能用作标识符.以下就是ECMAScript的全部关 ...
- [macOS] error when brew updating
I want to update the brew, then run brew update but unluckly, i got these error /usr/local/Library/b ...
- Python 第五阶段 学习记录之----ORM
ORM: orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了 ...
- 必须添加对程序集"System.Core"的引用
在项目下的web.config中添加 <compilation debug="true" targetFramework="4.0"> <as ...
- Maven setting.xml文件详解(转)
maven的配置文件settings.xml存在于两个地方: 1.安装的地方:${M2_HOME}/conf/settings.xml 2.用户的目录:${user.home}/.m2/setting ...