Ubuntu 安装 hadoop
安装完Linux后,我们继续(VMWare 安装 Linux http://blog.csdn.net/hanjun0612/article/details/55095955)
这里我们开始学习安装 hadoop
如果你是 Ubuntu desktop版本,
那么直接在主界面 按下 Ctrl+alt+T 调出 终端界面,这样就和 server版一样可以使用命令安装了。
安装hadoop
(参照如下链接,这两篇教程简单明了,推荐看一下,
当然楼主也拷贝过来方便大家查阅,并且根据自己的安装包修改了几处)
参考 http://www.cnblogs.com/kinglau/p/3794433.html
http://www.powerxing.com/install-hadoop/
一、在Ubuntu下创建hadoop组和hadoop用户
增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户。
1、创建hadoop用户组

2、创建hadoop用户
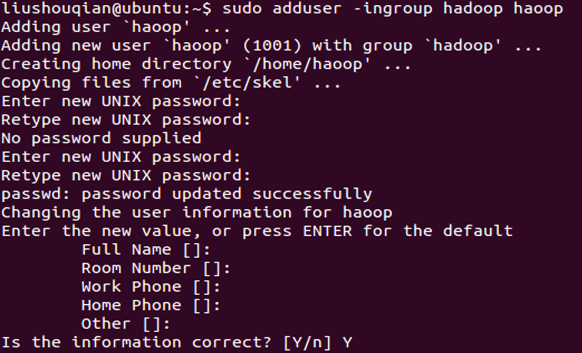
sudo adduser -ingroup hadoop hadoop
回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。
如果不输入密码,回车后会重新提示输入密码,即密码不能为空。
最后确认信息是否正确,如果没问题,输入 Y,回车即可。
3、为hadoop用户添加权限
输入:sudo gedit /etc/sudoers
回车,打开sudoers文件
给hadoop用户赋予和root用户同样的权限

添加这句话,如下图 hadoop ALL=(ALL:ALL) ALL

二、用新增加的hadoop用户登录Ubuntu系统
三、安装ssh
sudo apt-get install openssh-server
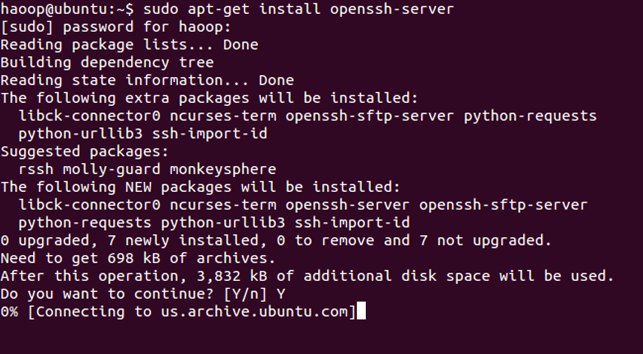
安装完成后,启动服务
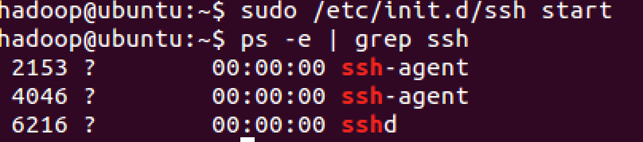
sudo /etc/init.d/ssh start
查看服务是否正确启动:ps -e | grep ssh
设置免密码登录,生成私钥和公钥
ssh-keygen -t rsa -P ""
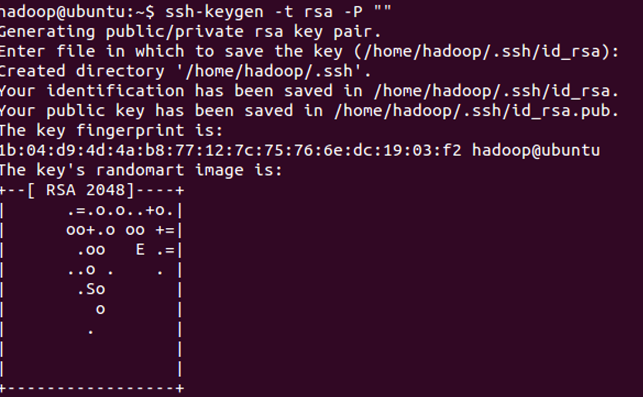
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys

登录ssh
ssh localhost
退出
exit
四、安装Java环境
sudo apt-get install openjdk-7-jdk
查看安装结果,输入命令:java -version,结果如下表示安装成功。

五、安装hadoop2.4.0
1、官网下载http://mirrors.cnnic.cn/apache/hadoop/common/
下载 “stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件
2、安装
两种安装方法(楼主用的第二种)
方法一,解压
sudo tar xzf hadoop-2.4.0.tar.gz
假如我们要把hadoop安装到/usr/local下
拷贝到/usr/local/下,文件夹为hadoop
sudo mv hadoop-2.4.0 /usr/local/hadoop

赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop

方法二,(记得修改命令中你的hadoop版本)
我们选择将 Hadoop 安装至 /usr/local/ 中:
- sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
- cd /usr/local/
- sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
- sudo chown -R hadoop ./hadoop # 修改文件权限
命令
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
- cd /usr/local/hadoop
- ./bin/hadoop version
安装结束~~~准备进入配置阶段
3、配置
1)配置~/.bashrc
配置该文件前需要知道Java的安装路径,用来设置JAVA_HOME环境变量,可以使用下面命令行查看安装路径
update-alternatives - -config java
执行结果如下:

完整的路径为
/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java
我们只取前面的部分 /usr/lib/jvm/java-7-openjdk-amd64
配置.bashrc文件
sudo gedit ~/.bashrc
此处分为2个方法(楼主使用第二个方法)
方法一,该命令会打开该文件的编辑窗口,在文件末尾追加下面内容,然后保存,关闭编辑窗口。
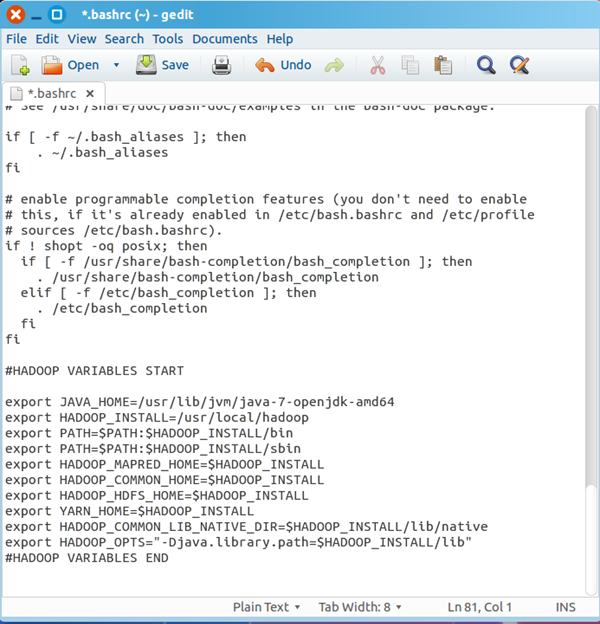
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
最终结果如下图:
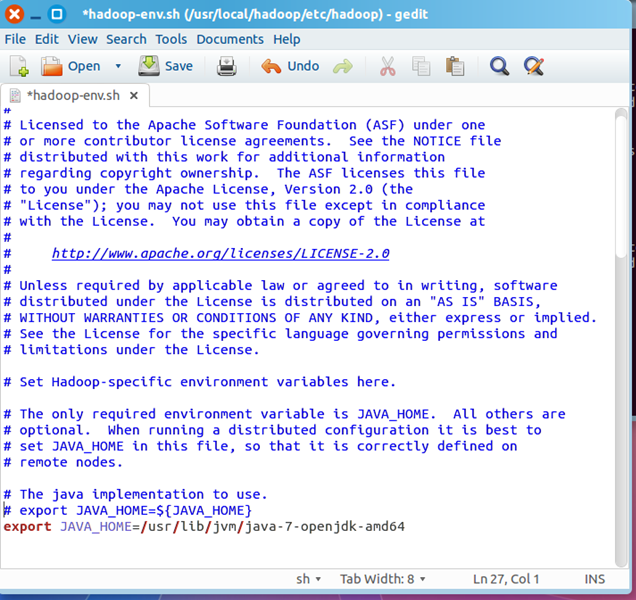
2)编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh
执行下面命令,打开该文件的编辑窗口
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
找到JAVA_HOME变量,修改此变量如下
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
修改后的hadoop-env.sh文件如下所示:
PS: 楼主是使用下面这个方法的,只在bashrc头部添加一句就好了
方法二
先运行
- dpkg -L openjdk-7-jdk | grep '/bin/javac'
命令
该命令会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是正确的路径了。如输出路径为 /usr/lib/jvm/java-7-openjdk-amd64/bin/javac,则我们需要的路径为 /usr/lib/jvm/java-7-openjdk-amd64。
然后运行 sudo
gedit ~/.bashrc
在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK安装路径”改为上述命令得到的路径,并保存:
(也就是之前运行 dpkg -L openjdk-7-jdk | grep '/bin/javac' 命令后出现的路径去除/bin/javac)
- export JAVA_HOME=JDK安装路径
如下图所示(该文件原本可能不存在,内容为空,这不影响):

source ~/.bashrc
设置好后我们来检验一下是否设置正确:
- echo $JAVA_HOME # 检验变量值
- java -version
- $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
命令
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java 的输出结果一样,如下图所示:
-version
 成功配置JAVA_HOME变量
成功配置JAVA_HOME变量
这样,Hadoop 所需的 Java 运行环境就安装好了。
六、WordCount测试
单机模式安装完成,下面通过执行hadoop自带实例WordCount验证是否安装成功
先执行:cd /usr/local/hadoop 跳转到此目录,然后才能执行 mkdir input 命令
/usr/local/hadoop路径下创建input文件夹
mkdir input
拷贝README.txt到input
cp README.txt input
执行WordCount
bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.4.0-sources.jar org.apache.hadoop.examples.WordCount input output
(PS:运行这一句时,要看一下自己的jar是多少版本的,我们下载的应该是2.7.3
所以替换后:bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.3-sources.jar org.apache.hadoop.examples.WordCount input output
)

执行结果:
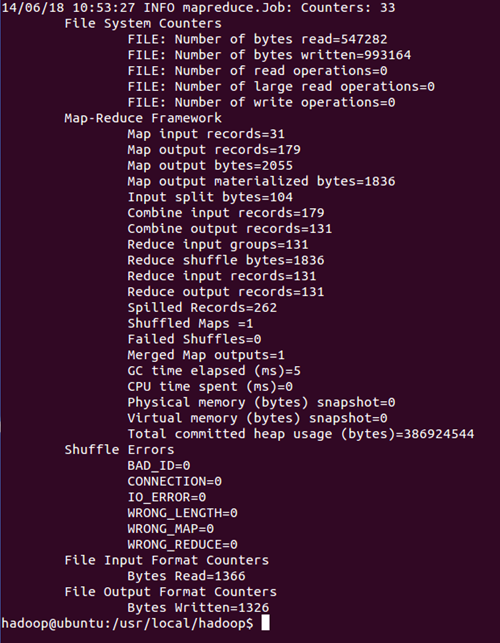
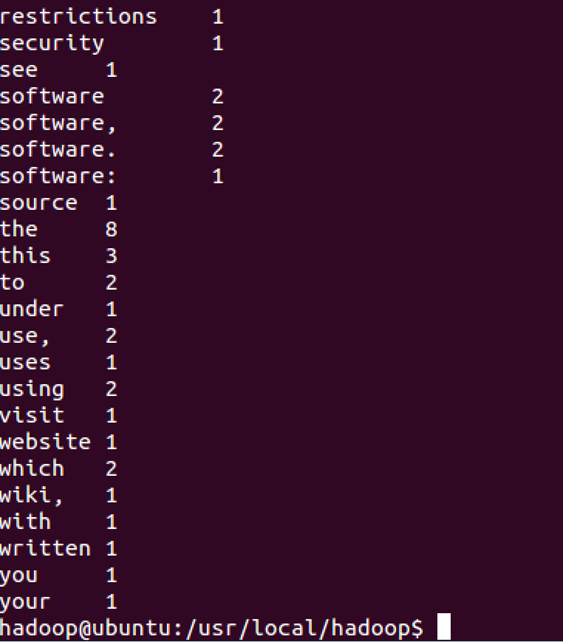
执行 cat output/*,查看字符统计结果
Ubuntu 安装 hadoop的更多相关文章
- Ubuntu安装Hadoop与Spark
更新apt 用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了.按 ctrl+alt+t 打开终端窗口,执行如下命令: sudo a ...
- ubuntu安装hadoop经验
安装环境: 1 linux系统 2 或(windows下)虚拟机 本文在linux系统ubuntu下尝试安装hadoop 安装前提 1 安装JDK(安装oracle公司的JDK ) (1)检查是否已安 ...
- Ubuntu 安装hadoop 伪分布式
一.安装JDK : http://www.cnblogs.com/E-star/p/4437788.html 二.配置SSH免密码登录1.安装所需软件 sudo apt-get ins ...
- Ubuntu安装Hadoop
系统:Ubuntu16.04 JDK:jdk-8u201 Hadoop:3.1.2 一.安装JDK https://www.cnblogs.com/tanrong/p/10641803.html 二. ...
- ubuntu安装hadoop 若干问题的解决
问题1:安装openssh-server失败 原因: 下列软件包有未满足的依赖关系: openssh-server : 依赖: openssh-client (= 1:5.9p1-5ubuntu1) ...
- Ubuntu - 安装hadoop(简约版)
相关版本: VMware ubuntuKylin16.04 JDK :openjdk Hadoop-2.9.1 步骤: 1.SSH 配置 [ 远程登陆 ] [ 配置SSH免码登陆 ] *测试:ssh ...
- 在Ubuntu上单机安装Hadoop
最近大数据比较火,所以也想学习一下,所以在虚拟机安装Ubuntu Server,然后安装Hadoop. 以下是安装步骤: 1. 安装Java 如果是新机器,默认没有安装java,运行java –ver ...
- [Hadoop入门] - 2 ubuntu安装与配置 hadoop安装与配置
ubuntu安装(这里我就不一一捉图了,只引用一个网址, 相信大家能力) ubuntu安装参考教程: http://jingyan.baidu.com/article/14bd256e0ca52eb ...
- 安装Hadoop及Spark(Ubuntu 16.04)
安装Hadoop及Spark(Ubuntu 16.04) 安装JDK 下载jdk(以jdk-8u91-linux-x64.tar.gz为例) 新建文件夹 sudo mkdir /usr/lib/jvm ...
随机推荐
- Emacs 番茄钟 pomidor
Windows 10 pomidor:https://github.com/TatriX/pomidor alert :https://github.com/jwiegley/alert toaste ...
- Python 爬取 11 万 Java 程序员信息竟有这些重大发现!
一提到程序猿,我们的脑子里就会出现这样的画面: 或者这样的画面: 心头萦绕的字眼是:秃头.猝死.眼镜.黑白 T 恤.钢铁直男-- 而真实的程序猿们,是每天要和无数数据,以及数十种编程语言打交道.上能手 ...
- Apache cxf暴露接口以及客户端调用之WebService初步理解
在我们真实的项目中,经常会调用别人提供给我们的接口,或者在自己的团队中, restful风格的前后端分离也经常会提供一个后端接口暴露出去供app,或者.net/C/C++程序员去调用,此时就需要使用到 ...
- 微信小程序之wx.request:fail错误,真机预览请求无效问题解决,安卓,ios网络预览异常
新版开发者工具增加了https检查功能:可使用此功能直接检查排查ssl协议版本问题: 可能原因:0:后台域名没有配置0.1:域名不支持https1:没有重启工具:2:域名没有备案,或是备案后不足24小 ...
- 身在上海的她,该不该继续"坚持"前端开发?
作者:13 GitHub:https://github.com/ZHENFENG13 版权声明:本文为原创文章,未经允许不得转载. 一 对于目前的IT行业,我实在不想她还没在这个行业中站稳脚跟就开始有 ...
- Azure Load Balancer : 简介
Azure 提供的负载均衡服务叫 Load Balancer,它工作在 ISO 七层模型的第四层,通过分析 IP 层及传输层(TCP/UDP)的流量实现基于 "IP + 端口" 的 ...
- 一文让你完全弄懂Stegosaurus
国内关于 Stegosaurus 的介绍少之又少,一般只是单纯的工具使用的讲解之类的,并且本人在学习过程中也是遇到了很多的问题,基于此种情况下写下此文,也是为我逝去的青春时光留个念想吧~ Stegos ...
- Centos下MooseFS(MFS)分布式存储共享环境部署记录
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连,分布式文件系统的实际基于客户机/服务器模式.目前 ...
- C_数据结构_链式二叉树
# include <stdio.h> # include <malloc.h> struct BTNode { int data; struct BTNode * pLchi ...
- PAT甲题题解-1130. Infix Expression (25)-中序遍历
博主欢迎转载,但请给出本文链接,我尊重你,你尊重我,谢谢~http://www.cnblogs.com/chenxiwenruo/p/6789828.html特别不喜欢那些随便转载别人的原创文章又不给 ...