【Java】HashMap源码分析——常用方法详解
上一篇介绍了HashMap的基本概念,这一篇着重介绍HasHMap中的一些常用方法:
put()
get()
**resize()**
首先介绍resize()这个方法,在我看来这是HashMap中一个非常重要的方法,是用来调整HashMap中table的容量的,在很多操作中多需要重新计算容量。
源码如下:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
可以看到这段代码非常庞大,其内容可以分为两大部分:
第一部分计算并生成新的哈希表(空表):
// 记录原表
Node<K,V>[] oldTab = table;
// 得到原来哈希表的总长度,及原来总容量
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 得到原来最佳容量
int oldThr = threshold;
// 存放新的总容量、新最佳容量的变量
int newCap, newThr = 0;
if (oldCap > 0) {
// 原来总容量达到或超过HashMap的最大容量,则最佳容量设置为int类型的最大值
// 且原来容量不变,直接返回,不做后需调整
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 让新的总容量等于原来容量的二倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 新的最佳容量也变为原来的二倍
newThr = oldThr << 1;
}
// 原来总容量为0,将新的总容量设置为最佳容量,构造方法出入参数是一个派生的Map的时候,就会使用派生的Map计算出新的最佳容量
else if (oldThr > 0)
newCap = oldThr;
else {
// 原来总容量和原来最佳容量都没有定义
// 新的总容量设为默认值16
// 新的最佳容量=默认负载因子×默认容量=0.75×16=12
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 判断上述操作后新的最佳容量是否计算,若没有,就利用负载因子和新的总容量计算
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 更新当前的最佳容量
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 生成新的哈希表,即一维数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 更新哈希表
table = newTab;
可以看出上述操作仅仅是生成了一张大小合适的哈希表,但表还是空的,后面的操作就是把以前的表中的元素重新排列,移动到当前表中合适的位置!
第二部分将原表元素移动到新表合适的位置:
// 先判断原表是或否为空
if (oldTab != null) {
// 遍历原表(一维数组)中的所有元素,
for (int j = 0; j < oldCap; ++j) {
// 记录原来一维数组中下标为j的元素
Node<K,V> e;
// 只对有效元素进行操作
if ((e = oldTab[j]) != null) {
//将原表中的元素置空
oldTab[j] = null;
if (e.next == null)
// 当前元素没有后继,那么直接把它放在新表中合适位置
// 其中e.hash & (newCap - 1)在我上一篇博客有介绍
// 就是以该节点的hash值和新表总容量取余,将余数作为下标
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 当前元素有后继,且后继是红黑树
// 进行有关红黑树的相应操作
// 这里不详细介绍红黑树的操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这里就进行有关链表的移动
// 这两组结点变量,分别代表两条不同链表的头和尾
// 低位的头和尾
Node<K,V> loHead = null, loTail = null;
// 高位的头和尾
Node<K,V> hiHead = null, hiTail = null;
// 下一节点
Node<K,V> next;
do {
// 让next等于当前结点的后继结点
next = e.next;
// 这个位运算实际上判断的是该节点在新表中的位置是否发生改变
// 成立则说明没有改变,还是原来表中下标为j的位置
if ((e.hash & oldCap) == 0) {
// 若是首结点,则让低位的头等于当前结点
if (loTail == null)
loHead = e;
else
// 若不是首结点,则让低位的尾等于当前结点
loTail.next = e;
// 让低位的尾移动到当前
loTail = e;
}
// 这里就说明其在新表中的位置发生了改变,则要将其放入另一条链表
else {
// 若是首结点,则让高位的头等于当前结点
if (hiTail == null)
hiHead = e;
else
// 若不是首结点,则让高位的尾等于当前结点
hiTail.next = e;
// 让高位的尾移动到当前
hiTail = e;
}
} while ((e = next) != null);
// 原来位置的这条链表还存在
if (loTail != null) {
// 置空低位的尾的next
loTail.next = null;
// 将该链表的头结点放入新表下标为j的位置,即原表中的原位置
newTab[j] = loHead;
}
// 新位置上的链表存在
if (hiTail != null) {
// 置空高位的尾的next
hiTail.next = null;
// 将该链表的头结点放入新表中下标为j+原表长度的位置
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
链表的移动如图:
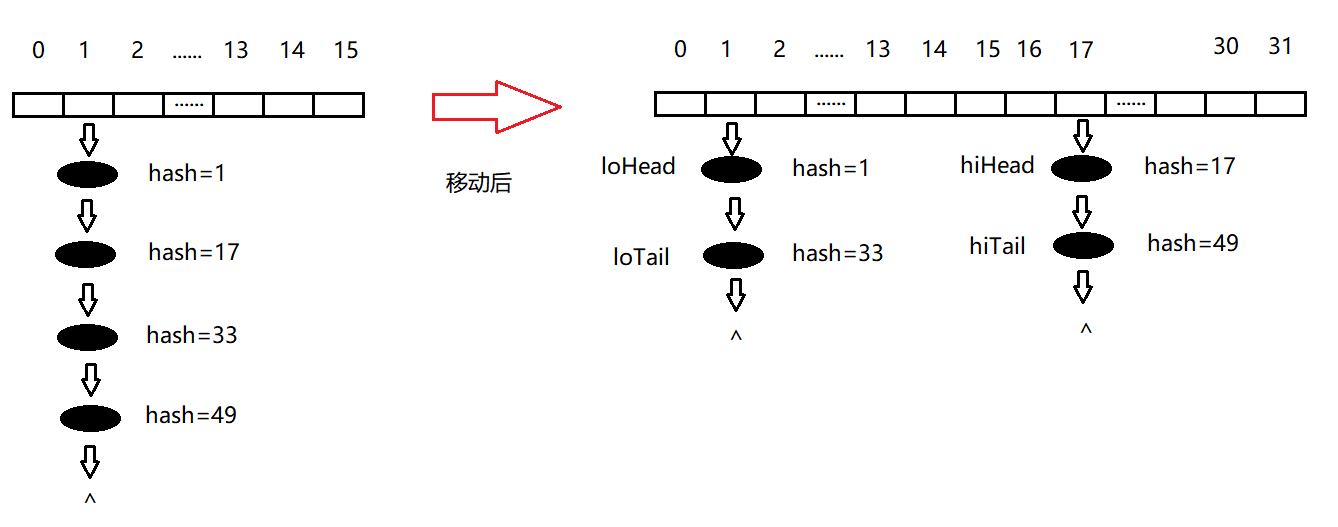
可以看出,这个方法可以使得单个结点重新散列,链表可以拆分成两条,红黑树重新移动,这样使得新的哈希表分布比以前均匀!
下面来分析put方法:
源码如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
这里我们可以知道其调用了内部的一个putVal方法:
首先第一个参数是通过内部的hash方法(在前一篇博客有介绍过)计算出键对象的hash(int类型)值,再把key和value对象传过去,置于后面两个参数先不着急
先来看下putVal方法是如何说明的:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* // 看以看出,put方法传入的onlyIfAbsent是false,那么就会改变原来已存在的值
* @param onlyIfAbsent if true, don't change existing value
* // 这个参数先不考虑,往后慢慢分析
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
该方法内容:
// 用于保存原表
Node<K,V>[] tab;
// 保存下标为hash的结点
Node<K,V> p;
// n用来记录表长
int n, i;
// 先检查原表是否存在,或者是空表
if ((tab = table) == null || (n = tab.length) == 0)
// 如果为空就生成一张大小为16的新表
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果以该方法形参hash对表长取余,令其作为下标的表中的元素为空,那么就产生一个新结点放在这个位置
tab[i] = newNode(hash, key, value, null);
else {
// 如果该结点不空,那么就会出现两种情况:链表和红黑树
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 如果当前结点的hash并且key值(指针值和内容值)相等,由于onlyIfAbsent是false,那么就会改变这个结点的V值,先用e将其保存起来
e = p;
else if (p instanceof TreeNode)
// 如果当前结点是一棵红黑树,那么就进行红黑树的平衡,这里不讨论红黑树的问题
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 这里就对链表进行操作
// 从头开始遍历这条链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
// 如果该节点的next为空
// 就需要新增一个结点追加其后
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 这里进行红黑树阈值的判断,由于TREEIFY_THRESHOLD默认值是8,binCount是从0开始,那么当链表长度大于等于8的时候,就将该链表转换成红黑树,并且结束循环
treeifyBin(tab, hash);
break;
}
// 这里和之前的判断是一样的
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 让p = p->next
p = e;
}
}
// 若e非空,则就是说明原表中存在hash值相等,且key的值或内容相同的结点
if (e != null) {
// 将原来的V值保存
V oldValue = e.value;
// 判断是否是需要进行覆盖原来V值的操作
if (!onlyIfAbsent || oldValue == null)
// 覆盖原来的V值
e.value = value;
// 这个方法是一个空的方法,预留的一个操作,不用去管它
afterNodeAccess(e);
// 由于在这里面的操作只是替换了原来的V值,并没有改变原来表的大小,直接返回oldValue
return oldValue;
}
}
// 操作数自增
++modCount;
// 实际大小自增
// 若其大于最佳容量进行扩容的操作,使其分布均匀
if (++size > threshold)
resize();
// 这也是一个空的方法,预留操作
afterNodeInsertion(evict);
// 并没有替换原来的V值,返回null
return null;
下来是get方法,逻辑相对简单不难分析:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
同样也是通过hash方法计算出key对象的hash值,调用内部的getNode方法:
final Node<K,V> getNode(int hash, Object key) {
// 记录表对象
Node<K,V>[] tab;
// 记录第一个结点和当前节点
Node<K,V> first, e;
// 记录表长
int n;
// 记录K值
K k;
// 表非空或者长度大于0才对其操作
// 并且key的hash值对表长取余为下标,其所对应的哈希表中的结点存在
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 当前结点满足情况,直接返回给该节点
if (first.hash == hash &&
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 后面就分为两种情况:在红黑树或者链表中查找
if ((e = first.next) != null) {
// 当前结点是红黑树,进行红黑树的查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 进行链表的遍历
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
若有不足还请指出!
我在CSDN也放了一篇【Java】HashMap源码分析——常用方法详解
【Java】HashMap源码分析——常用方法详解的更多相关文章
- Java HashMap源码分析(含散列表、红黑树、扰动函数等重点问题分析)
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- java HashMap源码分析(JDK8)
这两天在复习JAVA的知识点,想更深层次的了解一下JAVA,所以就看了看JAVA的源码,把自己的分析写在这里,也当做是笔记吧,方便记忆.写的不对的地方也请大家多多指教. JDK1.6中HashMap采 ...
- Java HashMap源码分析
貌似HashMap跟ConcurrentHashMap是面试经常考的东西,抽空来简单分析下它的源码 构造函数 /** * Constructs an empty <tt>HashMap&l ...
- jQuery源码分析-构造函数详解
在jQuery.js的构造函数中,充分利用了JavsScript语言的动态性——对行参的类型和个数没有的严格要求,以至于一个函数可以实现多种功能需求,也为JavaScript语言的多态性提供了基础,在 ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
- Java集合源码分析(四)HashMap
一.HashMap简介 1.1.HashMap概述 HashMap是基于哈希表的Map接口实现的,它存储的是内容是键值对<key,value>映射.此类不保证映射的顺序,假定哈希函数将元素 ...
- 【Java】HashMap源码分析——基本概念
在JDK1.8后,对HashMap源码进行了更改,引入了红黑树.在这之前,HashMap实际上就是就是数组+链表的结构,由于HashMap是一张哈希表,其会产生哈希冲突,为了解决哈希冲突,HashMa ...
- Java BAT大型公司面试必考技能视频-1.HashMap源码分析与实现
视频通过以下四个方面介绍了HASHMAP的内容 一. 什么是HashMap Hash散列将一个任意的长度通过某种算法(Hash函数算法)转换成一个固定的值. MAP:地图 x,y 存储 总结:通过HA ...
- Java源码解析——集合框架(五)——HashMap源码分析
HashMap源码分析 HashMap的底层实现是面试中问到最多的,其原理也更加复杂,涉及的知识也越多,在项目中的使用也最多.因此清晰分析出其底层源码对于深刻理解其实现有重要的意义,jdk1.8之后其 ...
随机推荐
- 06-jQuery的文档操作
之前js中咱们学习了js的DOM操作,也就是所谓的增删改查DOM操作.通过js的DOM的操作,大家也能发现,大量的繁琐代码实现我们想要的效果.那么jQuery的文档操作的API提供了便利的方法供我们操 ...
- 【python-HTMLTestRunner】生成HTMLTestRunner报告报错ERROR 'ascii' codec can't decode byte 0xe5 in position 0: ordinal not in range(128)
[python-HTMLTestRunner]生成HTMLTestRunner报告报错:ERROR 'ascii' codec can't decode byte 0xe5 in position 0 ...
- Beta冲刺 (7/7)
Part.1 开篇 队名:彳艮彳亍团队 组长博客:戳我进入 作业博客:班级博客本次作业的链接 Part.2 成员汇报 组员1:(组长)柯奇豪 过去两天完成了哪些任务 部分代码的整合 编辑文章部分的完成 ...
- sqrt()函数对素数判断的优化
素数是只有1和本身能整除的整数.所以在求素数的时候,要将素数与1到素数本身中间的所有整数都相除,看是否有整除的数,如果有,那肯定不是素数了.但是从算法上考虑,为了减少重复量,开平方后面的数就不用相除了 ...
- Python logging模块简介
logging模块提供logger,handler,filter,formatter. logger:提供日志接口,供应用代码使用.logger最长用的操作有两类:配置和发送日志消息.可以通过logg ...
- 进度条(progress_bar)
环境:linux.centos6.5 #include<stdio.h> #include<unistd.h> int main() { ]={'\0'}; char ch[] ...
- 剑指offer编程题Java实现——面试题13在O(1)时间内删除链表节点
题目:给定单向链表的头指针和一个节点指针,定义一个函数在O(1)时间删除该节点. 由于给定的是单向链表,正常删除链表的时间复杂度是查找链表的时间复杂度即O(n),如果要求在O(1)时间复杂度内删除节点 ...
- react中使用阿里Viser图表
参考demo的codesandbox:https://codesandbox.io/s/kxxxx3w5kv 使用步骤: 1. 安装依赖 viser-react和@antv/data-set 2 ...
- Java中的代理机制
Java的三种代理模式 代理模式是一种设计模式,提供了对目标对象额外的访问方式,即通过代理对象访问目标对象,这样可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能. 简言之,代理模 ...
- HTML+JS实现网站公告信息滚动显示
一.可以直接使用marquee标签来实现 注意: 这个标签首先在早期的IE版本中加进来,后来逐渐被其他浏览器支持,W3C的不建议使用它. <marquee>在HTML和HTML5中都属于废 ...