kafka结合Spark-streming的直连(Direct)方式
说明:此程序使用的scala编写
在spark-stream+kafka使用的时候,有两种连接方式一种是Receiver连接方式,一种是Direct连接方式。
两种连接方式简介:
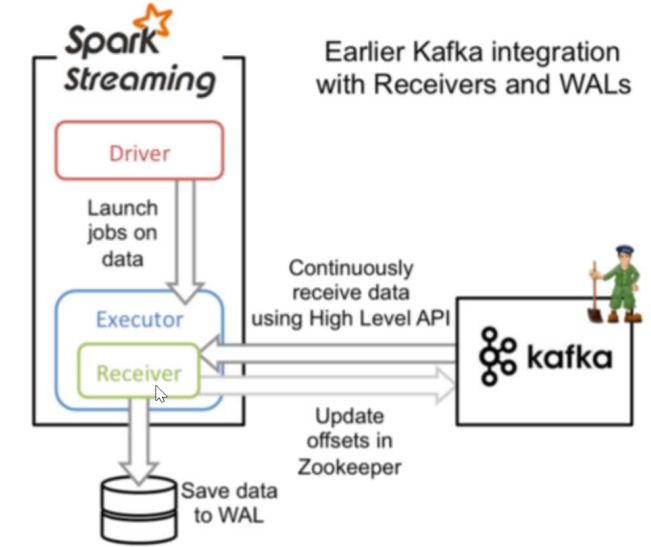
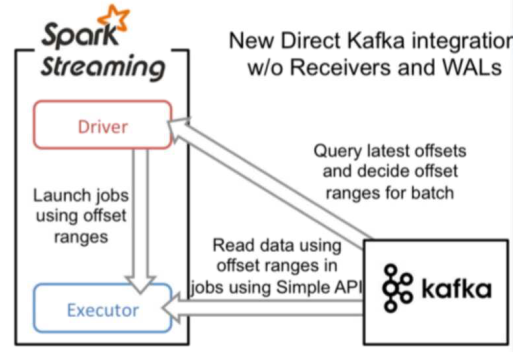
两者的区别:
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import kafka.utils.{ZKGroupTopicDirs, ZkUtils}
import org.I0Itec.zkclient.ZkClient
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Duration, StreamingContext}
import redis.clients.jedis.Jedis object KafkaDirectConsumer {
def main(args: Array[String]): Unit = {
// 创建streaming
val conf = new SparkConf().setAppName("demo").setMaster("local[2]")
val ssc = new StreamingContext(conf, Duration(5000))
// 创建
// 指定消费者组
val groupid = "gp01"
// 消费者
val topic = "tt1"
// 创建zk集群连接
val zkQuorum = "spark101:2181,spark102:2181,spark103:2181"
// 创建kafka的集群连接
val brokerList = "spark101:9092,spark102:9092,spark103:9092"
// 创建消费者的集合
// 在streaming中可以同时消费多个topic
val topics: Set[String] = Set(topic)
// 创建一个zkGroupTopicDir对象
// 此对象里面存放这zk组和topicdir的对应信息
// 就是在zk中写入kafka的目录
// 传入 消费者组,消费者,会根据传入的参数生成dir然后存放在zk中
val TopicDir = new ZKGroupTopicDirs(groupid, topic)
// 获取存放在zk中的dir目录信息 /gp01/offset/tt
val zkTopicPath: String = s"${TopicDir.consumerOffsetDir}"
// 准备kafka的信息、
val kafkas = Map(
// 指向kafka的集群
"metadata.broker.list" -> brokerList,
// 指定消费者组
"group.id" -> groupid,
// 从头开始读取数据
"auto.offset.reset" -> kafka.api.OffsetRequest.SmallestTimeString
)
// 创建一个zkClint客户端,用host 和 ip 创建
// 用于从zk中读取偏移量数据,并更新偏移量
// 传入zk集群连接
val zkClient = new ZkClient(zkQuorum)
// 拿到zkClient后去,zk中查找是否存在文件
// /gp01/offset/tt/0/10001
// /gp01/offset/tt/1/20001
// /gp01/offset/tt/2/30001
val clientOffset = zkClient.countChildren(zkTopicPath)
// 创建空的kafkaStream 里面用于存放从kafka接收到的数据
var kafkaStream: InputDStream[(String, String)] = null
// 创建一个存放偏移量的Map
// TopicAndPartition [/gp01/offset/tt/0,10001]
var fromOffsets: Map[TopicAndPartition, Long] = Map()
// 判断,是否妇女放过offset,若是存放过,则直接从记录的
// 偏移量开始读
if (clientOffset > 0) {
// clientOffset的数量就是 分区的数目量
for (i <- 0 until clientOffset) {
// 取出 /gp01/offset/tt/i/ 10001 -> 偏移量
val paratitionOffset = zkClient.readData[String](s"${zkTopicPath}/${i}")
// tt/ i
val tp = TopicAndPartition(topic, i)
// 添加到存放偏移量的Map中
fromOffsets += (tp -> paratitionOffset.toLong)
}
// 现在已经把偏移量全部记录在Map中了
// 现在读kafka中的消息
// key 是kafka的kay,为null, value是kafka中的消息
// 这个会将kafka的消息进行transform 最终kafka的数据都会变成(kafka的key,message)这样的tuple
val messageHandlers = (mmd: MessageAndMetadata[String, String]) => (mmd.key(), mmd.message())
// 通过kafkaUtils来创建DStream
// String,String,StringDecoder,StringDecoder,(String,String)
// key,value,key的解码方式,value的解码方式,(接受的数据格式)
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, (String, String)](
ssc, kafkas, fromOffsets, messageHandlers
)
} else { // 若是不存在,则直接从头读
// 根据kafka的配置
kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkas, topics)
} // 偏移量范围
var offsetRanges = Array[OffsetRange]() kafkaStream.foreachRDD {
kafkaRDD =>
// 得到kafkaRDD,强转为HasOffsetRanges,获得偏移量
// 只有Kafka可以强转为HasOffsetRanges
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges // 触发Action,这里去第二个值为真实的数据
val mapRDD = kafkaRDD.map(_._2)
/*=================================================*/
// mapRDD为数据,在这里对数据操作
// 在这里写你自己的业务处理代码代码
// 此程序可以直接拿来使用,经历过层层考验 /*=================================================*/ // 存储更新偏移量
for (o <- offsetRanges) {
// 获取dir
val zkPath = s"${zkTopicPath}/${o.partition}"
ZkUtils.updatePersistentPath(zkClient, zkPath, o.untilOffset.toString)
}
} ssc.start()
ssc.awaitTermination() }
}
以上为Direct直连方式的代码,直接可以使用的,根据自己的集群,和topic,groupid等配置稍作修改即可。
kafka结合Spark-streming的直连(Direct)方式的更多相关文章
- Spark Streaming消费Kafka Direct方式数据零丢失实现
使用场景 Spark Streaming实时消费kafka数据的时候,程序停止或者Kafka节点挂掉会导致数据丢失,Spark Streaming也没有设置CheckPoint(据说比较鸡肋,虽然可以 ...
- Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现(转)
原文链接:Spark+Kafka的Direct方式将偏移量发送到Zookeeper实现 Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- Spark Streaming、Kafka结合Spark JDBC External DataSouces处理案例
场景:使用Spark Streaming接收Kafka发送过来的数据与关系型数据库中的表进行相关的查询操作: Kafka发送过来的数据格式为:id.name.cityId,分隔符为tab zhangs ...
- TOP100summit:【分享实录-Microsoft】基于Kafka与Spark的实时大数据质量监控平台
本篇文章内容来自2016年TOP100summit Microsoft资深产品经理邢国冬的案例分享.编辑:Cynthia 邢国冬(Tony Xing):Microsoft资深产品经理.负责微软应用与服 ...
- 整合Kafka到Spark Streaming——代码示例和挑战
作者Michael G. Noll是瑞士的一位工程师和研究员,效力于Verisign,是Verisign实验室的大规模数据分析基础设施(基础Hadoop)的技术主管.本文,Michael详细的演示了如 ...
- Kafka与Spark案例实践
1.概述 Kafka系统的灵活多变,让它拥有丰富的拓展性,可以与第三方套件很方便的对接.例如,实时计算引擎Spark.接下来通过一个完整案例,运用Kafka和Spark来合理完成. 2.内容 2.1 ...
- Spark Streaming揭秘 Day15 No Receivers方式思考
Spark Streaming揭秘 Day15 No Receivers方式思考 在前面也有比较多的篇幅介绍了Receiver在SparkStreaming中的应用,但是我们也会发现,传统的Recei ...
随机推荐
- <Listener>servletContextListener、httpSessionListener和servletRequestListener使用整理
在java web应用中,listener监听器似乎是不可缺少的.经常常使用来监听servletContext.httpSession.servletRequest等域对象的创建.销毁以及属性的变化等 ...
- centos7系统下,配置学校客户端网络记录
存在的情况 1.学校的网络客户端绑定了个人的电脑MAC地址.绑定了IP地址. 2.我有两台笔记本,一台用了4年多,想用这台(B)直接装centos7系统,然后新买的笔记本(A)做为经常用的,系统为wi ...
- MySQL DDL--ghost执行模板和参数
常用GHOST模板 ##================================================## mysql_ip="127.0.0.1" mysql_ ...
- Visual Studio 2017中使用正则修改部分内容
最近在项目中想实现一个小工具,需要根据类的属性<summary>的内容加上相应的[Description]特性,需要实现的效果如下 修改前: /// <summary> /// ...
- 背水一战 Windows 10 (89) - 文件系统: 读写文本数据, 读写二进制数据, 读写流数据
[源码下载] 背水一战 Windows 10 (89) - 文件系统: 读写文本数据, 读写二进制数据, 读写流数据 作者:webabcd 介绍背水一战 Windows 10 之 文件系统 读写文本数 ...
- Java学习笔记48(DBUtils工具类一)
上一篇的例子可以明显看出,在增删改查的时候,很多的代码都是重复的, 那么,是否可以将增删改查封装成一个类,方便使用者 package demo; /* * 实现JDBC的工具类 * 定义方法,直接返回 ...
- mybatis-plus代码生成器
public class MyBatisPlusGenerator { public static void main(String[] args) throws SQLException { //1 ...
- Spark SQL读取hive数据时报找不到mysql驱动
Exception: Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "BoneC ...
- 从零开始学 Web 之 ES6(二)ES5的一些扩展
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- SQOOP安装部署
1.环境准备 1.1软件版本 sqoop-1.4.5 下载地址 2.配置 sqoop的配置比较简单,下面给出需要配置的文件 2.1环境变量 sudo vi /etc/profile SQOOP_HOM ...