将爬取的数据保存到mysql中
为了把数据保存到mysql费了很多周折,早上再来折腾,终于折腾好了
安装数据库
1、pip install pymysql(根据版本来装)
2、创建数据
打开终端 键入mysql -u root -p 回车输入密码
create database scrapy (我新建的数据库名称为scrapy)
3、创建表
use scrapy;
create table xiaohua (name varchar(200) ,url varchar(100));
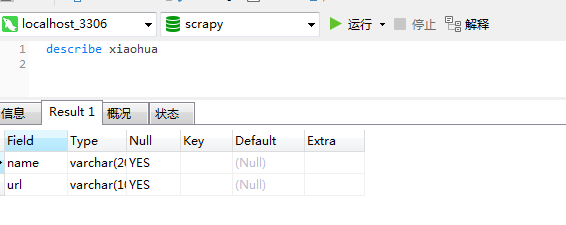
数据库部分就酱紫啦
4、编写pipeline
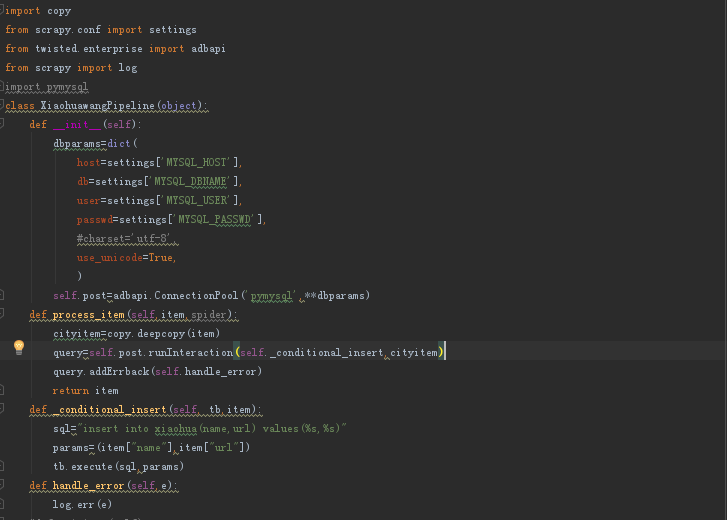
5、编写setting

6、编写spider文件
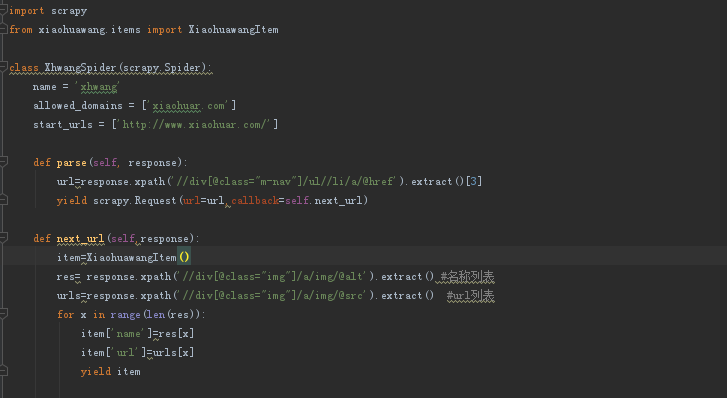
7、爬取数据保存到mysql
scrapy crawl xhwang
之前报错为2018-10-18 09:05:50 [scrapy.log] ERROR: (1241, 'Operand should contain 1 column(s)')
因为我的spider代码中是这样
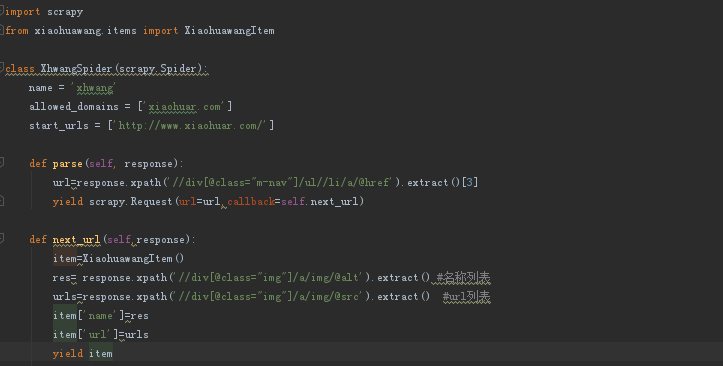
附一张网上找到的答案

错误原因:item中的结果为{'name':[xxx,xxxx,xxxx,xxx,xxxxxxx,xxxxx],'url':[yyy,yyy,yy,y,yy,y,y,y,y,]},这种类型的数据
更正为6下面代码后出现如下会有重复

然后又查了下原因终于解决问题之所在
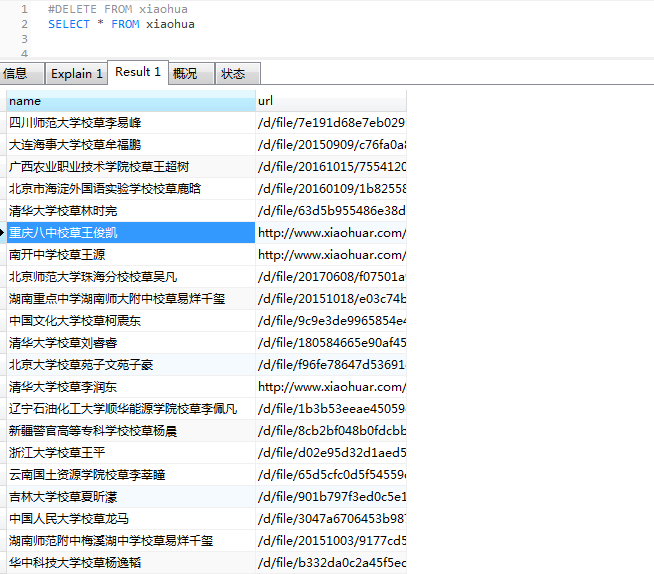
在图上可以看出,爬取的数据结果是没有错的,但是在保存数据的时候出错了,出现重复数据。那为什么会造成这种结果呢?
其原因是由于spider的速率比较快,scrapy操作数据库相对较慢,导致pipeline中的方法调用较慢,当一个变量正在处理的时候
一个新的变量过来,之前的变量值就会被覆盖了,解决方法是对变量进行保存,在保存的变量进行操作,通过互斥确保变量不被修改。
在pipeline中修改如下代码

完成以上设定再来爬取,OK 大功告成(截取部分)
将爬取的数据保存到mysql中的更多相关文章
- 1.scrapy爬取的数据保存到es中
先建立es的mapping,也就是建立在es中建立一个空的Index,代码如下:执行后就会在es建lagou 这个index. from datetime import datetime fr ...
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- 顺企网 爬取16W数据保存到Mongodb
import requests from bs4 import BeautifulSoup import pymongo from multiprocessing.dummy import Pool ...
- Asp.net Session 保存到MySql中
一 网站项目引入"mysql.web.dll" 二 web.config配置中添加mysql数据库连接字符串 <connectionStrings> <remov ...
- Python scrapy爬虫数据保存到MySQL数据库
除将爬取到的信息写入文件中之外,程序也可通过修改 Pipeline 文件将数据保存到数据库中.为了使用数据库来保存爬取到的信息,在 MySQL 的 python 数据库中执行如下 SQL 语句来创建 ...
- c# 抓取和解析网页,并将table数据保存到datatable中(其他格式也可以,自己去修改)
使用HtmlAgilityPack 基础请参考这篇博客:https://www.cnblogs.com/fishyues/p/10232822.html 下面是根据抓取的页面string 来解析并保存 ...
- Excel文件数据保存到SQL中
1.获取DataTable /// <summary> /// 查询Excel文件中的数据 /// </summary> /// <param name="st ...
- Redis使用场景一,查询出的数据保存到Redis中,下次查询的时候直接从Redis中拿到数据。不用和数据库进行交互。
maven使用: <!--redis jar包--> <dependency> <groupId>redis.clients</groupId> < ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
随机推荐
- Kafka实战-简单示例
1.概述 上一篇博客<Kafka实战-Kafka Cluster>中,为大家介绍了Kafka集群的安装部署,以及对Kafka集群Producer/Consumer.HA等做了相关测试,今天 ...
- vue-03-style与class
1, 绑定html class 1), 直接绑定 <div> isActive 为true, 则显示 active css <p v-bind:class="{active ...
- ionic的学习-02路由中的几个参数
Part1 路由中的几个参数 第一步:看几个参数的位置 ①ionic中是通过<ion-nav-view></ion-nav-view>实现不同模板渲染跳转的. ②ionic中 ...
- Java 8 新特性-菜鸟教程 (9) -Java8 Base64
Java8 Base64 在Java 8中,Base64编码已经成为Java类库的标准. Java 8 内置了 Base64 编码的编码器和解码器. Base64工具类提供了一套静态方法获取下面三种B ...
- vuex状态管理之学习笔记
概述及使用场景 Vuex 是一个主要应用在中大型单页应用的类似于 Flux 的数据管理架构.它主要帮我们更好地组织代码,以及把应用内的的状态保持在可维护.可理解的状态. 但如果是简单的应用 ,就没有必 ...
- memcache 安装及使用
memcache时php使用memcached的一个扩展,是一种分布式内存对象缓存系统.用来存储经常要查询到的数据,减少对数据库的访问,提高整体网站的速度. 简单提一下memcache与redis区别 ...
- MySQL优化(1)--------常用的优化步骤
在开始博客之前,还是同样的给一个大概的目录结构,实则即为一般MySQL的优化步骤 1.查看SQL的执行频率---------------使用show status命令 2.定位哪些需要优化的SQL-- ...
- SQL 数据库加字段声明
ALTER TABLE dbo.C_TrainPlan ADD MailCost DATETIME EXECUTE sp_addextendedproperty N'MS_Description', ...
- XML部分
XML文档定义有几种形式?它们之间有何本质区别?解析XML文档有哪几种方式? 两种形式:DTD以及schema: 本质区别:schema本身是xml的,可以被XML解析器解析(这也是从DTD上发展sc ...
- ASP .NET MVC HtmlHelper扩展——简化“列表控件”的绑定
在众多表单元素中,有一类<select>元素用于绑定一组预定义列表.传统的ASP.NET Web Form中,它对应着一组重要的控件类型,即ListControl,我们经常用到DropDo ...