Python全栈之路--Django ORM详解
ORM:(在django中,根据代码中的类自动生成数据库的表也叫--code first)
ORM:Object Relational Mapping(关系对象映射)
我们写的类表示数据库中的表
我们根据这个类创建的对象是数据库表里的一行数据
obj.id obj.name.....就是数据库一行数据中的一部分数据
ORM--First:
我们在学习django中的orm的时候,我们可以把一对多,多对多,分为正向和反向查找两种方式。
class UserType(models.Model):
caption = models.CharField(max_length=32) class UserInfo(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField()
user_type = models.ForeignKey('UserType')#外键
正向查找:ForeignKey在 UserInfo表中,如果从UserInfo表开始向其他的表进行查询,这个就是正向操作,反之如果从UserType表去查询其他的表这个就是反向操作。
马上就要开始我们的orm查询之旅!!!
建表+配置url+views中写相应的函数
models.py(在django中仅且只能在这里写数据库的相关类)
class UserType(models.Model):
caption = models.CharField(max_length=32) class UserInfo(models.Model):
username = models.CharField(max_length=32)
age = models.IntegerField()
user_type = models.ForeignKey('UserType')
这里我们使用sqlite3数据库,在settings中使用默认设置就可以了
url.py中的配置
from django.conf.urls import url
from django.contrib import admin
from app01 import views urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^user_type',views.user_type),
url(r'^user_info',views.user_info),
]
views.py先不进行任何操作,我们先保证正常访问已经设置的url
from django.shortcuts import render,HttpResponse def user_type(req):
return HttpResponse("ok") def user_info(req):
return HttpResponse("ok")
先在表中插入几个数据用于测试:
usertype表

userinfo表数据插入:
所以我们在创建UserType数据的时候有两种方法:第一种方法是直接根据这个字段进行添加数据!给user_type 加 '_id'
def user_info(request):
dic = {'username':'mosson','age':18,'user_type_id':1}
models.UserInfo.objects.create(**dic)
return HttpResponse('OK')
或者通过对象添加
#先获取组的对象
usertype = models.UserType.objects.fiter(id=2)
#添加的时候直接添加对象就可以
models.UserInfo.objects.create(username='seven',age=18,user_type=usertype) #写成一行也行
models.UserInfo.objects.create(username='lile',age=18,user_type=models.UserType.objects.filter(id=1))
django的get方法是从数据库的取得一个匹配的结果,返回一个对象,如果记录不存在的话,它会报错。
django的filter方法是从数据库的取得匹配的结果,返回一个对象列表,如果记录不存在的话,它会返回[]。

ORM的一对多:
我们在设计表结构的时候什么时候使用一对多呢?
比如我们在建立用户的时候有个菜单让我们选择用户类型的时候,使用一对多!!
1、一对多的正向查找:
正向查:ForeignKey在UserInfo表里,如果根据UserInfo这张表去查询这两张关联的表的合起来的内容就是正向查
反向查:ForeignKey不在UserType里,如果根据UserType这张表去查询这两张关联的表的合起来的内容就是反向查
正向查-demo1--查询所有用户为COO 的用户
在django中外键就相当于简单的使用__连表,在外键那个对象中封装了user_type表中的所有字段
我们要查询所有用户为CEO的用户,我们是不是的根据UserType这张表去查,如果是跨表查询使用“双下划线” + 属性
from app01 import models
def index(req):
ret = models.UserInfo.objects.filter(user_type__caption='COO')
print(ret)
for item in ret:
print(item,item.username,item.age,item.user_type.caption)
return HttpResponse("OK")
查询结果:

反向查询:--
我们可以根据下面的命令,取出一个用户组,那么对于这个用户组他有多少个用户呢?
models.UserType.objects.get(id=1)
obj=models.UserType.objects.get(id=1)
obj.caption====得到在UserType表中id为1对应的caption
obj.id======得到在UserType表中id为1
obj.userinfo_set #理解为一种能力,可以获取所有当前这个用户类型的用户/或者这个用户类型的多个用户
obj.userinfo_set.all() #获取所有用户类型为COO的用户
obj.userinfo_set.filter(username='tim') #获取用户类型为COO的并且用户为tim的用户 '''
这.userinfo_set.相当于什么?它相当于 models.UserInfo.objects.filter(user_type=obj) '''
反向查询实例:查询COO用户下的所有的用户名
ret = models.UserType.objects.filter(caption='COO').values('userinfo__username')
for item in ret:
print(item,type(item))
方法二、
ret = models.UserType.objects.filter(caption='COO').first()
for item in ret.userinfo_set.all():
print(item.username)
总结:
正向查找:
filter(跨表的时候,应该是对象__跨表的字段)
获取这个值的时候,拿到了一行数据的时候 line.对象.跨表的字段
反向查找:
filter(关联这个表的表明) 自动创建和表明相同的对象,通过这个对象__跨表的字段
line.自动创建和表明相同的对象_set.方法

ORM多对多 系统生成第三张表:
多对多和一对多没有任何关系
models.py
class Host(models.Model):
hostname = models.CharField(max_length=32)
port = models.IntegerField() class HostAdmin(models.Model):
username = models.CharField(max_length=32)
email = models.CharField(max_length=32)
host = models.ManyToManyField('Host')
当我们在host表里和hostadmin表里添加数据时和第三章关系表没有任何关系,当我们这样去建立表时,第三张表里面的列就已经固定了,分别是这两个表的id
给主机表添加数据:
def index(req):
#主机数据
models.Host.objects.create(hostname='host1.test.com', port=80)
models.Host.objects.create(hostname='host2.test.com', port=80)
models.Host.objects.create(hostname='host3.test.com', port=80)
models.Host.objects.create(hostname='host4.test.com', port=80)
#用户数据
models.HostAdmin.objects.create(username='alex', email='alex@qq.com')
models.HostAdmin.objects.create(username='mosson', email='mosson@qq.com')
models.HostAdmin.objects.create(username='aliven', email='aliven@qq.com')
models.HostAdmin.objects.create(username='wusir', email='wusir@qq.com')
数据中的效果:

空的关系表

多对多正向、反向添加数据

正向添加数据:
def index(request):
#正向添加数据
#找到用户dali这个
admin_obj = models.HostAdmin.objects.get(username='dali')
#找到主机
host_list = models.Host.objects.filter(id__lt=3)
#通过找到的dali的对象.add去添加数据
admin_obj.host.add(*host_list)
'''
admin_obj 通过大力这个对象.add 去操作的主机,
大力的ID为 2 主机ID为:(1,2)
那就会生成这样的表:
#2 1
#2 2
'''
return HttpResponse('OK')
反向添加数据:
def index(request):
#反向添加数据
#获取主机
host_obj = models.Host.objects.get(id=3)
#获取用户列表
admin_list = models.HostAdmin.objects.filter(id__gt=1)
#和一对多一样的道理
host_obj.hostadmin_set.add(*admin_list)
#host_obj = 3 管理员ID = 2 3 4
#3 2
#3 3
#3 4
return HttpResponse('OK')
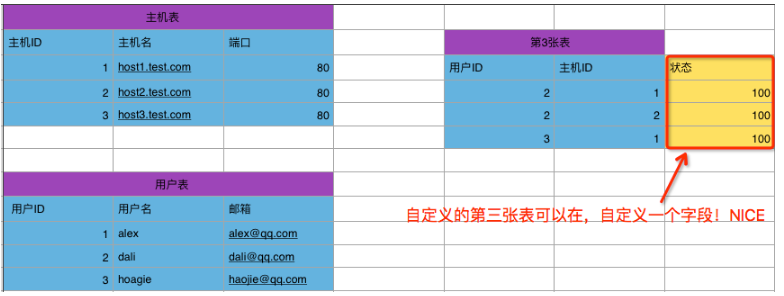
ORM 多对多 自定义 第三张表
class HostInfo(models.Model):
hostname = models.CharField(max_length=32)
port = models.IntegerField() class UserMap(models.Model):
username = models.CharField(max_length=32)
email = models.CharField(max_length=32) #through告诉Django用那张表做关联
host = models.ManyToManyField(HostInfo , through='HostRelation') class HostRelation(models.Model):
host = models.ForeignKey('HostInfo')
user = models.ForeignKey('UserMap') '''
并且这里我们可以添加多个关系,比如在加一个字段
usertype = models.ForeignKey('UserType')
或者增加一个普通字段
status = models.CharField(max_length=32)
'''
现在咱们自己创建了第三张表了。现在我们已经会了两种方式创建第三张表了,当我们使用自定义创建的第三张表的时候,在去添加数据的时候!
就不能使用第一种方式对象添加了!
现在我们有第三张表了这个对象了,我们就不需要管另外两张表了,直接添加就行了! 0 0 !
添加主机和用户--
def index(req):
models.HostInfo.objects.create(hostname='alex.test.com', port=80)
models.HostInfo.objects.create(hostname='seven.test.com', port=80)
models.HostInfo.objects.create(hostname='mosson.test.com', port=80)
models.UserMap.objects.create(username='alex', email='alex@qq.com')
models.UserMap.objects.create(username='seven', email='seven@qq.com')
models.UserMap.objects.create(username='mosson', email='mosson@qq.com')
return HttpResponse('ok')
将数据插入到第三张表中---办法1:
插入单条数据
def index(request):
models.HostRelation.objects.create(
user = models.UserMap.objects.get(id=1),
host = models.HostInfo.objects.get(id=1)
)
return HttpResponse('OK')
多对多两种方式对比和查询
查询--方法一:
第一种方式都是基于表中的对象去找到第三张表! 通过间接的方式找到这张表的句柄!
#正向查
admin_obj = models.HostAdmin.objects.get(id=1)
admin_obj.host.all()
#反相差
host_obj = models.Host.objects.get(id=1)
host_obj.hostadmin_set.all()
查询--方法二:
用第二种方法就没有正向和反向这么一说了,直接查即可!
relation_list = models.HostRelation.objects.all()
for item in relation_list: #每一个item就是一个关系
print (item.user.username)
print( item.host.hostname)
relation_list = models.HostRelation.objects.filter(user__username='mosson')
for item in relation_list: #每一个item就是一个关系
print( item.user.username)
print (item.host.hostname)
通过第二种方式可以把所有的关系都找到,第一种方式可以把所有的关系表都找到吗?
第一种方式只能找到某一个人管理的机器,不能把有的对应关系找到!
select_related的作用:
class UserType(models.Model):
caption = models.CharField(max_length=32) class UserInfo(models.Model):
user_type = models.ForeignKey('UserType') #这个user_type是一个对象,对象里面封装了ID和caption
username = models.CharField(max_length=32)
age = models.IntegerField()
select_related的作用,他就是用来优化查询的,没有他也可以,用它主要是用来优化ForeignKey
def index(request):
ret = models.UserInfo.objects.all()
#咱们看下他执行的什么SQL语句
print( ret.query)
'''
SELECT "app01_userinfo"."id", "app01_userinfo"."user_type_id", "app01_userinfo"."username", "app01_userinfo"."age" FROM "app01_userinfo"
'''
加上select_related是什么样子的
def user_info(request):
ret = models.UserInfo.objects.all().select_related()
#咱们看下他执行的什么SQL语句
print ret.query SELECT "app01_userinfo"."id",
"app01_userinfo"."user_type_id",
"app01_userinfo"."username",
"app01_userinfo"."age",
"app01_usertype"."id",
"app01_usertype"."caption" FROM
"app01_userinfo" INNER JOIN "app01_usertype" ON ("app01_userinfo"."user_type_id" = "app01_usertype"."id")
所以说select_related就是优化查询的!
ORM连表操作的梳理:
一、一对多创建
1、创建数据
通过对象创建
或者通过对象字段_id创建
2、查找
正向查找
在通过filter的时候跨表使用 双下划线 '__'
在获取值得时候通过.跨表
反向查找
Django自动生成 表名_set
其他操作和正向查找一样
二、多对对
1、自动生成关系表
间接的方式获取关系表,如果是正向的:一行数据的对象.ManyToMany字典就行 反向:一行数据的对象.表名_set
2、自定义关系表(推荐)不管是添加、修改只对关系表操作就行
三、select_related
用于优化查询,一次性将查询的表和ForiegnKey关联的表一次性加载到内存。
Django中的F和Q
F:用来批量修改数据(使用查询条件的值)
demo:比如我有个price这个列,我想让price自增10或者某一些自增10
# from django.db.models import F
# models.Tb1.objects.update(num=F('num')+10)
Q:用来做条件查询的
默认的django的查询只是且操作如下:
models.UserInfo.objects.filter(username='mosson',age='18')
找到用户名为:mosson且age=18的数据
有没有这么一种情况:username=mosson或 username=wusir 或 username=alex 并且 age=18的需求?原生的查询是不支持的!所以就用到了Q~
第一步:
#生成一个搜索对象
search_q = Q() #在生成两个搜索对象
search1 = Q()
search2 = Q() 第二步:
#标记search1中的搜索条件为 ‘ 或’ 查询
search1.connector = 'OR' #把搜索条件加入到search1中
search1.children.append(('字段名','字段内容'))
search1.children.append(('字段名','字段内容'))
search1.children.append(('字段名','字段内容'))
search1.children.append(('字段名','字段内容')) #标记search2中的搜索条件为 ‘ 或’ 查询
search2.connector = 'OR' #把搜索条件加入到search2中
search2.children.append(('字段名','字段内容'))
search2.children.append(('字段名','字段内容'))
search2.children.append(('字段名','字段内容'))
search2.children.append(('字段名','字段内容')) 第三步:
#把多个搜索条件进行合并
search_q.add(search1,'AND')
search_q.add(search2,'AND') 第四步:
#执行搜索
models.HostInfo.objects.filter(search_q)
实例:
在前端获取搜索条件的时候我把相同类型的搜索写成字典的形式{字段名:[条件结合列表]},这样我在查询的时候直接通过循环字典就可以把搜索条件分为不同的子条件!
function SearchSubmit() {
//清空当前列表
$('#table-body').children().remove();
//设置一个空字典
SEARCH_DIC = {};
//找到所有的搜索框体
var search_data = $('.inputs').find("input[is-condition='true']");
//循环找到的内容
$.each(search_data,function (index,data) {
//获取搜索的类型
/*
这里需要注意:重点:::::
这里和Django的Q可以进行耦合,在我们定义搜索的类型的时候可以直接写成我们要搜索的的'库中的字段或者条件都可以!!!'
如下:
<input is-condition="true" type="text" placeholder="逗号分割多条件" class="form-control no-radius" name="hostname" />
*/
var search_name = $(this).attr('name');
//获取搜索的值
var search_value = $(this).val();
if(SEARCH_DIC.hasOwnProperty(search_name)){//判断是否有这个KEY
SEARCH_DIC[search_name].push(search_value)
}else{
SEARCH_DIC[search_name] = [search_value]
}
} );//ajax请求结束
$.get("{% url 'search_info' %}",{'search_list':JSON.stringify(SEARCH_DIC)},function(callback){
$('#table-body').append(callback)
});//搜索按钮结束
重点:
在前端我们定义input的name属性的时候,我们可以直接定义为数据库中的“字段名”,并且在Django的Q中支持跨表操作“双下划线”,所以我们在定义name的时候可以直接定义双下划线操作
search1.children.append(('字段名'__'跨表字段名','跨表字段内容'))
@login_auth
def search_info(request):
#获取用户请求的数据
user_post = json.loads(request.GET['search_list'])
print user_post
#生成搜索对象
Serach_Q = Q()
#循环字典并生成搜索条件集合
for k,v in user_post.items():
#生成一个搜索结合
q = Q()
#生命集合中的搜索条件为'或'条件
q.connector = 'OR'
#循环字典中的value,value是前端传过来的条件集合
for i in v:
#在搜索条件集合中增加条件,条件为元组形式,k为字典中的key! key是字段名或者跨表字段名或者支持_gt等
#i为字典中的vlaue中的元素,为条件
#
q.children.append((k,i))
#没循环一次后后,吧他加入到总的搜索条件中
Serach_Q.add(q,'AND')
#使用总的搜索条件进行查询
data = models.HostInfo.objects.filter(Serach_Q)
#拼接字符串并返回
html = []
for i in data:
html.append(
"<tr>"+
"<td>" + "<input type='checkbox' >"+ "</td>" +
"<td name='host_id'>" + '%s' %i.id + "</td>" +
"<td name='host_name' edit='true'>" + i.hostname + "</td>"+
"<td name='host_ip' edit='true'>" + i.hostip + "</td>"+
"<td name='host_port' edit='true'>" + '%s' %i.hostport + "</td>"+
"<td name='host_business' edit='true' edit-type='select' global-key='BUSINESS' select-val='" + '%s' %i.hostbusiness_id + "'>" + i.hostbusiness.hostbusiness + "</td>"+
"<td name='host_status' edit='true' edit-type='select' global-key='STATUS' select-val='" + '%s' %i.hoststatus_id + "'>" + i.hoststatus.hoststatus + "</td>"+
"</tr>"
) html = mark_safe("".join(html))
return HttpResponse(html)
Python全栈之路--Django ORM详解的更多相关文章
- python 全栈之路
目录 Python 全栈之路 一. Python 1. Python基础知识部分 2. Python -函数 3. Python - 模块 4. Python - 面对对象 5. Python - 文 ...
- Python全栈之路----目录
Module1 Python基本语法 Python全栈之路----编程基本情况介绍 Python全栈之路----常用数据类型--集合 Module2 数据类型.字符编码.文件操作 Python全栈之路 ...
- Python全栈之路目录结构
基础 1.Python全栈之路-----基础篇 2.Python全栈之路---运算符与基本的数据结构 3.Python全栈之路3--set集合--三元运算--深浅拷贝--初识函数 4.Python全栈 ...
- Python全栈之路----常用模块----hashlib加密模块
加密算法介绍 HASH Python全栈之路----hash函数 Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列 ...
- Python全栈开发:django网络框架(一)
Python的WEB框架有Django.Tornado.Flask 等多种,Django相较与其他WEB框架其优势为:大而全,框架本身集成了ORM.模型绑定.模板引擎.缓存.Session等诸多功能. ...
- Python全栈之路6--正则表达式
正则本身就是一门语言: 正则表达式使用单个字符串来描述.匹配一系列符合某个句法规则的字符串,在文本处理方面功能非常强大,也经常用作爬虫,来爬取特定内容,Python本身不支持正则,但是通过导入re模块 ...
- Python全栈之路----常用模块----re 模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是 re. re的匹配语法有以下几种 re.match 从头开始匹配 re.search 匹配包含 re.fin ...
- Python全栈之路----函数----返回值
函数外部的代码想要获取函数的执行结果,就可以在函数里用return语句,把结果返回. def stu_register(name,age,course='PY',country='CN'): prin ...
- Python之路【第二十一篇】Django ORM详解
ORM回顾 关系对象映射(Object Relational Mapping,简称ORM). django中遵循 Code Frist 的原则,即:根据代码中定义的类来自动生成数据库表. 对于ORM框 ...
随机推荐
- webdiyer aspnet pager最近又用这个。还是记录下。
这个是页面里的代码需要在上面引入: <%@ Register Assembly="AspNetPager" Namespace="Wuqi.Webdiyer&quo ...
- Secret Cow code(USACO)
题目描述:zxyer为了防止他的标程被别人抄走,他在计算机中的rar文件上设置了一个密码,其中每一个密码都有一个初始字符串,字符串由大写字母组成,且长度不超过30位,每一个密码还有一个询问,询问为一个 ...
- C++ 图像处理类库
GIFLIB是一个 C 语言的 Gif 图像处理库.支持 Gif 图像读写. 如果需要单独处理某类图片格式,以上类库是比较好的选择,如果处理的格式种类比较多,下面的类库是比较好的选择. ImageMa ...
- 在windows系统上word转pdf
一.前言:我在做文件转换过程中遇到的一些坑,在这里记录下,因为项目需求,需要使用html转pdf,由于itext转换质量问题(一些Css属性不起作用),导致只能通过word文件作为跳板来转换到pdf文 ...
- Selenium2+python自动化10-登录案例【转载】
前言 前面几篇都是讲一些基础的定位方法,没具体的案例,小伙伴看起来比较枯燥,有不少小伙伴给小编提建议以后多出一些具体的案例.本篇就是拿部落论坛作为测试项目,写一个简单的登录测试脚本. 在写登录脚本的时 ...
- Mac下安装node.js , Ionic
访问node.js官网(https://nodejs.org/en/download/),下载相应的版本. 下载完,点击安装 [默认目录] Node.js v8.9.3 to /usr/local/ ...
- [BZOJ4760][Usaco2017 Jan]Hoof, Paper, Scissors dp
4760: [Usaco2017 Jan]Hoof, Paper, Scissors Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 136 Solv ...
- 利用Lambda获取类中属性名称
public class TypeInfoHelper { public static string GetPropertyName<T>(Expression<Func<T, ...
- js 抽奖小案例
Luck Draw 在线演示:九宫格抽奖 对九宫格形式的抽奖页面进行了一些简单封装.以后有机会再更新其他形式的抽奖.
- ECNU 3462 最小 OR 路径 (贪心 + 并查集)
题目链接 EOJ Monthly 2018.1 Problem F 先假设答案的每一位都是$1$,然后从高位开始,选出那些该位置上为$0$的所有边,并查集判断连通性. 如果$s$和$t$可以连通的话 ...