4.DataFrame(快速开始)
快速开始

基本概念
''' 在使用 DataFrame 时,需要了解三个对象上的操作:Collection(DataFrame) ,Sequence,Scalar Collection(DataFrame)表示表结构(或者二维结构) Sequence表示列(一维结构) Scalar表示标量 要注意的是,这些对象仅在使用 Pandas 数据创建后会包含实际数据 而在 ODPS 表上创建的对象中并不包含实际的数据, 而仅仅包含对这些数据的操作,实质的存储和计算会在 ODPS 中进行。 ''' # 创建DataFrame ''' 通常情况下,你唯一需要直接创建的 Collection 对象是 DataFrame,这一对象用于引用数据源 可能是一个 ODPS 表, ODPS 分区,Pandas DataFrame或sqlalchemy.Table(数据库表) 用这几种数据源时,相关的操作相同,这意味着你可以不更改数据处理的代码 仅仅修改输入/输出的指向, 便可以简单地将小数据量上本地测试运行的代码迁移到 ODPS 上, 而迁移的正确性由 PyODPS 来保证。 创建 DataFrame 非常简单,只需将 Table 对象、 pandas DataFrame 对象或者 sqlalchemy Table 对象传入即可。 '''

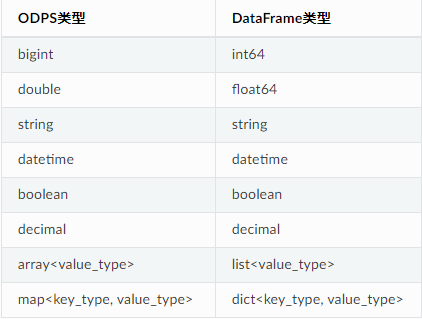
# 列类型 ''' DataFrame包括自己的类型系统,在使用Table初始化的时候,ODPS的类型会被进行转换。 这样做的好处是,能支持更多的计算后端。 目前,DataFrame的执行后端支持ODPS SQL、pandas以及数据库(MySQL和Postgres)。 PyODPS DataFrame 包括以下类型 int8,int16,int32,int64,float32,float64,boolean,string,decimal,datetime,list,dict ODPS的字段和DataFrame的类型映射关系如下: '''
4.DataFrame(快速开始)的更多相关文章
- 今天整理了几个在使用python进行数据分析的常用小技巧、命令。
提高Python数据分析速度的八个小技巧 01 使用Pandas Profiling预览数据 这个神器我们在之前的文章中就详细讲过,使用Pandas Profiling可以在进行数据分析之前对数据进行 ...
- 如何通过Elasticsearch Scroll快速取出数据,构造pandas dataframe — Python多进程实现
首先,python 多线程不能充分利用多核CPU的计算资源(只能共用一个CPU),所以得用多进程.笔者从3.7亿数据的索引,取200多万的数据,从取数据到构造pandas dataframe总共大概用 ...
- Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程 ...
- [大数据之Spark]——快速入门
本篇文档是介绍如何快速使用spark,首先将会介绍下spark在shell中的交互api,然后展示下如何使用java,scala,python等语言编写应用.可以查看编程指南了解更多的内容. 为了良好 ...
- Apache Spark 2.2.0 中文文档 - 快速入门 | ApacheCN
快速入门 使用 Spark Shell 进行交互式分析 基础 Dataset 上的更多操作 缓存 独立的应用 快速跳转 本教程提供了如何使用 Spark 的快速入门介绍.首先通过运行 Spark 交互 ...
- (原)怎样解决python dataframe loc,iloc循环处理速度很慢的问题
怎样解决python dataframe loc,iloc循环处理速度很慢的问题 1.问题说明 最近用DataFrame做大数据 处理,发现处理速度特别慢,追究原因,发现是循环处理时,loc,iloc ...
- pandas.DataFrame学习系列1——定义及属性
定义: DataFrame是二维的.大小可变的.成分混合的.具有标签化坐标轴(行和列)的表数据结构.基于行和列标签进行计算.可以被看作是为序列对象(Series)提供的类似字典的一个容器,是panda ...
- Pandas快速入门笔记
我正以Python作为突破口,入门机器学习相关知识.出于机器学习实践过程中的需要,我快速了解了一下提供了类似关系型或标签型数据结构的Pandas的使用方法.下面记录相关学习笔记. 数据结构 Panda ...
- spark RDD,DataFrame,DataSet 介绍
弹性分布式数据集(Resilient Distributed Dataset,RDD) RDD是Spark一开始就提供的主要API,从根本上来说,一个RDD就是你的数据的一个不可变的分布式元素集合,在 ...
随机推荐
- Android面试收集录2 Broadcast Receiver详解
1.Broadcast Receiver广播接收器简单介绍 1.1.定义 Broadcast Receiver(广播接收器),属于Android四大组件之一 在Android开发中,Broadcast ...
- P2370 yyy2015c01的U盘
P2370 yyy2015c01的U盘 题目背景 在2020年的某一天,我们的yyy2015c01买了个高端U盘. 题目描述 你找yyy2015c01借到了这个高端的U盘,拷贝一些重要资料,但是你发现 ...
- android systemtrace 报错
折腾了很久,妈的,终于可以跑出来systemtrace了.如果你跟我一样,老是生成trace失败,那么,按我说的啦: 坑就在,你必须选一个路径存放trace.html,你不选一个,他就生成不了. 打开 ...
- C# Json 序列化大全--任我行
public class JsonHelper { /// <summary> /// 将Model转换为Json字符串 /// </summary> /// <type ...
- 《Cracking the Coding Interview》——第16章:线程与锁——题目5
2014-04-27 20:16 题目:假设一个类Foo有三个公有的成员方法first().second().third().请用锁的方法来控制调用行为,使得他们的执行循序总是遵从first.seco ...
- U盘的容量变小了怎么办?
之前买了个U盘,后来给朋友装系统弄成U盘启动盘了,就发现U盘容量变少了几百兆,原来是因为做U盘启动盘的时候,U盘启动盘制作软件都是把写入U盘的PE文件隐藏了,防止用户不小心删除文件. 所以说这些空间应 ...
- Python全栈工程师(函数的传参)
ParisGabriel 感谢 大家的支持 每天坚持 一天一篇 点个订 ...
- nyoj 题目37 回文字符串
回文字符串 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 所谓回文字符串,就是一个字符串,从左到右读和从右到左读是完全一样的,比如"aba".当 ...
- Java分布式数据导出实践
伴随业务发展日益剧增,对数据的要求越来越多也越来越高. 用户在浏览器发起导出请求--web服务器接收请求--请求后台获取数据--数据统计后生成excel或其他图标--响应给客户端 整个过程至少5步,才 ...
- 【bzoj3561】DZY Loves Math VI 莫比乌斯反演
题目描述 给定正整数n,m.求 输入 一行两个整数n,m. 输出 一个整数,为答案模1000000007后的值. 样例输入 5 4 样例输出 424 题解 莫比乌斯反演 (为了方便,以下公式默认$ ...