Level DB 小调研
一、 概况:
1、 背景:
随着信息技术的高速发展,数据存储量和流量呈现爆炸式增长。目前百度统计日 PV(日点击量)已超过 75 亿次,中国网民在百度上进行50 亿次的搜索请求,百度贴吧日 PV 十亿,每天发帖三千多万;百度知道为中国网民解决了2.3亿个问题,日均 PV4.17 亿。百度的数据总量已接近几千个PB,每天要响应几百万次的搜索请求,每天处理 100PB 数据。
如此庞大的数据量给数据储存系统带来了巨大挑战,单机PC基本无法处理如此大量的PB级数据,分机存储成为大势所趋,于是自上世纪便提出的分布式系统理论成为当下最优解,Level DB也在近年应运而生。
2、简介:
Level DB 是一个持久性数据存储量能达到 Billion 级别的非常高效的键值型C++函数库,于2011年由Google发布。在其底层实现上使用了 LSM-tree(Log Structured Merge Tree)算法,以牺牲随机读换取顺序写,从而实现了数据的高效持久化存储。
LSM-tree 的思想其实非常易于理解,就是将对数据的大量修改以增量的形式保持在内存中,当数据量达到指定的大小限制后将这些修改操作批量写入磁盘,即顺序写;读取时需要合并磁盘中的历史数据和内存中最近的修改操作。LSM 树的优势在于有效地规避了磁盘随机写入问题,但读取时可能需要访问较多的磁盘文件。
Level DB 通过将数据更多地缓存在内存中,提高数据的命中率,避免读数据时过多的访问磁盘,进而提高读数据的整体效率。它有如下特点:
1. 基于 Key/Value 的持久化存储系统,与 Redis 这种基于 Key/Value 的内存型存储系统不同之处在于,Level DB 将大部分的数据存储到磁盘介质上,这样就不会有太多的内存开销,从而提高了效率。
2. 键值是任意字节的数组。数据通过键存储排序。调用者提供一个定制的比较重载的排序顺序。前后迭代是以数据为支撑的。
3. 能够有序的存储记录的键值,在系统中相邻的键值是按照一个比较函数,依次有序的存储在介质中,这个比较方法可以自行定义,Levle DB 根据这个比较方法依次来保存记录。
4. 通过一个虚拟接口,外部活动(如文件系统操作等)就能传送,用户就能定制操作系统的相互作用。Level DB 不仅提供数据读取、写入以及删除等简单的接口,而且也提供批量存取服务。
5. 支持数据快照(可理解为只读权限的数据库。Snapshot 不但有为报表提供静态的视图服务的优点,而且当与数据库镜像结合使用时提供读写分离功能,而最重要的一点可以利用数据库快照来快速恢复数据库。)功能,通过建立瞬间的快照,能够使写操作不会影响到读操作,能够在读操作过程中始终看到一致的数据,避免脏数据等不一致性问题。
6. 支持数据压缩功能,通过使用 Snappy(Snappy 是一个以 BSD 协议开源的开发包,提供数据压缩和数据解压功能。用来压缩较为大量级的数据,其稳定性和健壮性较好。)压缩库自动压缩数据。这对不仅可以增快读/写效率而且有助于减小存储空间。
7. 只是一套 c++程序库,底层提供了抽象接口,允许用户定制,不是 SQL数据库,没有数据关系模型,单机系统没有 client-server。
集群化 Level DB 存储系统解决方案在很大程度上突破了传统意义上附属于主机的存储设备只能存放数据的范畴,而现代的存储系统以大量廉价的普通计算机为基础平台,配合复杂的管理软件来存放海量数据,并能对这些大量级的数据进行管理使其可靠、高效、合理性管理。集群化 Level DB 在大量廉价物理机上,基于 Level DB 核提供基本的数据存储服务,采取各种策略保证数据的完整性、系统的可靠性,使其存储、读写等服务有更高的效率。
二、 原理简介:
实际上 Level DB 就是一个数据存储系统和基于该系统的接口规范。它的存储介质是文件和内存,通过拍照我们能看到这样的情景:

Level DB 整体架构图
如图所示,系统的整体静态架构由六部分组成:内存中的 Mem Table 和Immutable Mem Table;磁盘的 Current 文件、Manifest 文件、Log 文件和 SSTable(Sorted Strings Table)几种主要文件。
Level DB 中的 Mem Table 文件当需要写入一条记录时,系统会先向 log 文件中插入该记录,当成功插入到 log 文件后,再去将该记录写入到 Mem Table 中,成功写入到 Mem Table 后才算完成一次基本写入成功。而说 Level DB 写入速度极快的首要原因,也正是由于它的一次写入数据只涉及到一次内存写入和磁盘写入的操作。
为尽量避免数据丢失,Level DB采用先将数据写入到 Log 文件,然后释放到系统 Memtable,一旦宕机也可以从 Log 将数据恢复到 Memtable。
在插入数据时,Memtable 达到一定大小就会将内容导出到外部文件,Levle DB 会重新生成 Log 文件和 Mem Table,旧的 Memtable 就变为了 Immutable Memtable。从字面上我们就能够看出,Mem Table 的内容 Mem Table 的内容只能进行读操作。新数据会被记录到新产生的 Log 文件和 Memtable 中,同时后台将 Immutable Memtable 到数据保存到磁盘。内存中的记录不停释放到介质中并进行 Compaction 操作后形成了 SSTable,而 SSTable 是由一类层级构成的文件,第一层为 Level 0,第二层为 Level 1,直到第 12 层为止。
SSTable 中的每个文件属于哪一层的层级,而且顺序的存储着记录的 Key值,事实上在文件中 key 值越小的记录排列的顺序越靠前。所以必然有文件中的最小 key 值与最大 key 值,当然这些信息也同样是极为重要的,Level DB 系统中的Manifest 文件负责记载 SSTable 各个文件的管理信息,例如层级信息,文件名称,最小 key 值与最大 key 值等信息。下图是 Manifest存储信息的示意图:
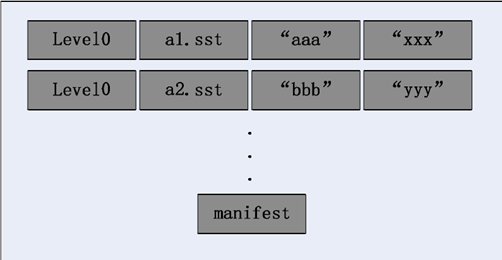
Manifest示意图
如图所示,看到两个文件,即 Level 0 的两个文件,都记在了 key 范围,a1 的 key 范围是“aaa”到“xxx”,文件 a2 的 key 范围是“bbb”到“yyy”,两者 key部分就重叠了。
Current 文件只负责记录当前系统使用的 Manifest 文件名。上面我们知道了系统的运行会不断的进行 Compaction 操作,SSTable 也随之改变,而 Manifest文件也会随之发生改变,同样会产生一个新的 Manifest 文件来记录这些信息,而Current 文件则是记录当前系统所正在使用到底是哪个 Manifest 文件。
以上为Level DB的总体架构,以下展示Level DB读写数据流程图:

Level DB 读取数据流程图
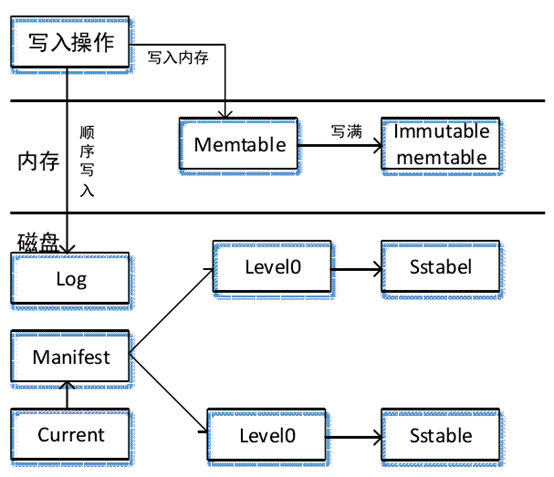
Level DB 写入数据流程图
根据 Google 给出的测试报告,Level DB 具有很高的写入速度,其随机写性能可以达到40万条记录每秒,而随机读性能也达到 6 万条记录每秒。
总而言之,Level DB 是一个非常高效的海量键值存储引擎、一个用 C++实现的类库、一个单机持久化存储系统,广泛应用于各种需要处理庞大数据量的企业中,也十分受到分布式系统研究领域学者们的青睐,近年来在云计算、集群化数据等领域表现活跃。
Level DB 小调研的更多相关文章
- 屠龙之路_击败DB小boss_FifthDay
摘要:服务器大魔王被击败的消息传到了恶龙boss那里,恶龙大怒派出了自己的首级大将DB人称小boss,但小boss的名号并没有吓到七位屠龙勇士,经过他们齐心协力的进攻,最终击败了DB,小boss临死前 ...
- SQLite 小调研
一. 概况: SQLite 是 D. Richard Hipp 于 2000 年采用 C 语言编写的一个轻量级.跨平台的关系型数据库,支持大部分 SQL92 标准(比如视图.事务.触发器.blob 数 ...
- trove,测试,db小解析
# Copyright 2014 Tesora Inc.# All Rights Reserved.## Licensed under the Apache License, Version 2.0 ...
- MySQL 小调研
一. 概况: MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL ...
- 关于level DB的相关资料
可以参考: http://blog.csdn.net/houzengjiang/article/details/7718548 http://www.cnblogs.com/haippy/archiv ...
- Fog of War小调研
看起来LOL和DOTA2都用的是格子来做的战争阴影,并且是用PP做的.
- Redis 小调研
一. 概况: Redis是一款开源的.网络化的.基于内存的.可进行数据持久化的Key-Value存储系统.它的数据模型建立在外层,类似于其它结构化存储系统,是通过Key映射Value的方式来建立字典以 ...
- Neo4j 小调研
一. 概况: 在图计算中,基本的数据结构表达式是:G= ( V,E ),V=vertex( 节点 ),E=edge(边) .图数据库中数据模型主要以节点和关系(边)来体现,也可以处理键值对.数据具有如 ...
- Elastic Search 小调研
一.概况: Elastic Search 是一个基于Apache Lucene™工具包的开源搜索引擎.无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进.性能最好的.功能最全的搜索引擎库 ...
随机推荐
- 使用Emacs来编程
使用Emacs来编程 */--> code {color: #FF0000} pre.src {background-color: #002b36; color: #839496;} code ...
- a标签动态修改手机号跳到拨打界面
<div class="primaryButton"> <a :href.stop="'tel:' + createData.salesPhone&qu ...
- ASP.NET MVC SignalR 简单聊天推送笔记
介绍:(抄袭于网络) ASP.NET SignalR 是为 ASP.NET 开发人员提供的一个库,可以简化开发人员将实时 Web 功能添加到应用程序的过程.实时 Web 功能是指这样一种功能:当所连接 ...
- BZOJ 4289 最短路+优化建图
题意:给出一个N个点M条边的无向图,经过一个点的代价是进入和离开这个点的两条边的边权的较大值,求从起点1到点N的最小代价.起点的代价是离开起点的边的边权,终点的代价是进入终点的边的边权. 解法:参考h ...
- Codeforces 348C Subset Sums 分块思想
题意思路:https://www.cnblogs.com/jianrenfang/p/6502858.html 第一次见这种思路,对于集合大小分为两种类型,一种是重集合,一种是轻集合,对于重集合,我们 ...
- Springmvc集成CXF请看教程二
转自: http://www.cnblogs.com/xiaochangwei/p/5399507.html 继上一篇webService入门之后,http://www.cnblogs.com/xia ...
- vue 条件渲染v-if v-show
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 防火墙---CentOS
1.查看防火墙状态 firewall-cmd --state 2.停止防火墙 systemctl stop firewalld.service 3.禁止开机启动防火墙 systemctl disabl ...
- React 组件间传值
壹 .了解React传值的数据 一. 创建组件的方法 一 . 1 通过function声明的组件特点是: 1)function创建的组件是没有state属性,而state属性决定它是不是有生命周期 ...
- mongodb数据库管道操作
1.$project(修改文档的结构,可以用来重命名.增加或删除文档中的字段) db.order.aggregate([ { $project:{ rade_no:1, all_price:1} } ...