每日一问2:堆(heap)和栈(stack)的区别
因为这里没有明确指出堆是指数据结构还是存储方式,所以两个尝试都回答一下。
一.堆和栈作为数据结构
1.堆(heap),也叫做优先队列(priority queue),队列中允许的操作是先进先出(FIFO),在队尾插入元素,在队头取出元素。而堆也是一样,在堆底插入元素,在堆顶取出元素,但是堆中元素的排列不是按照到来的先后顺序,而是按照一定的优先顺序排列的。这个优先顺序可以是元素的大小或者其他规则。
2.栈(stack),是一种运算受限的线性表,栈中允许的操作时先进后出(FILO),在栈顶插入元素,在栈顶取出元素。另,堆栈连在一起就只指栈,也就是说堆栈指的是栈。
二.堆和栈作为存储方式
1.栈区,指由编译器在需要的时候分配,在不需要的时候自动清除的变量的存储区。里面的变量通常是局部变量、函数参数等。在一个进程中,位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用。和堆一样,用户栈在程序执行期间可以动态地扩展和收缩。
2.堆区,指由 new 分配而不是编译器自动分配的内存块,由应用程序控制,一般一个 new 就要对应一个 delete。如果程序员没有释放掉,那么在程序结束后,操作系统会自动回收。堆可以动态地扩展和收缩。
详细区别:
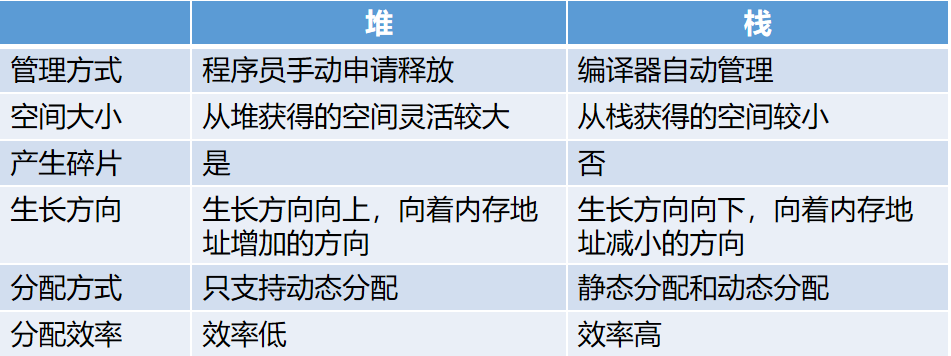
产生这些区别的原因:
生长方向:栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++ 函数库提供的,它的机制是很复杂的,例如为了分配一块内存,库函数会按照一定的算法(具体的算法可以参考数据结构/操作系统)在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间(可能是由于内存碎片太多),就有可能调用系统功能去增加程序数据段的内存空间,这样就有机会分到足够大小的内存,然后进行返回。显然,堆的效率比栈要低得多。
————————————————
参考博文:https://blog.csdn.net/qq_35637562/article/details/78550953 https://www.cnblogs.com/youxin/p/3313288.html
每日一问2:堆(heap)和栈(stack)的区别的更多相关文章
- Java中堆(heap)和栈(stack)的区别
简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存. 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分 ...
- 堆(heap)和栈(stack)的区别
转: 一.预备知识―程序的内存分配 一个由c/C++编译的程序占用的内存分为以下几个部分 1.栈区(stack)― 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等.其操作方式类似于数据结构中 ...
- 转载C#中堆(heap)和栈(stack)的区别
转载原地址 http://www.cnblogs.com/wangshenhe/archive/2013/02/18/2916275.html [转]C#堆和栈的区别 理解堆与栈对于理解.NET中的 ...
- 数据结构与算法--堆(heap)与栈(stack)的区别
堆和栈的区别 在C.C++编程中,经常需要操作的内存可分为以下几个类别: 栈区(stack):由编译器自动分配和释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构中的栈. 堆区(heap ...
- JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )(转载)
想想面试的时候很多会问jvm这方面的问题虽然还是菜鸟不太能用到现在但是还是了解一下, 找资料的时候看见个大佬写的很好转载到这方便以后自己复习和给大佬做宣传 以下为大佬的博客原文: 这两天看了一下深入浅 ...
- [转]JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题: 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(h ...
- 堆heap和栈Stack(百科)
堆heap和栈Stack 在计算机领域,堆栈是一个不容忽视的概念,堆栈是两种数据结构.堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除.在单片机应用中,堆栈 ...
- JVM 内存初学 堆(heap)、栈(stack)和方法区(method)
这两天看了一下深入浅出JVM这本书,推荐给高级的java程序员去看,对你了解JAVA的底层和运行机制有比较大的帮助.废话不想讲了.入主题:先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(he ...
- 转:JVM 内存初学 (堆(heap)、栈(stack)和方法区(method) )
原文地址:JVM 内存初学 (堆(heap).栈(stack)和方法区(method) ) 博主推荐 深入浅出JVM 这本书 先了解具体的概念:JAVA的JVM的内存可分为3个区:堆(heap).栈( ...
随机推荐
- js毫秒数转天时分秒
formatDuring: function(mss) { var days = parseInt(mss / (1000 * 60 * 60 * 24)); var hours = pars ...
- 【原生JS】动态分页样式效果
效果图如下: html: <body> <div> <table id="btnbox"> <tbody> <tr>&l ...
- [转]React入门看这篇就够了
摘要: 很多值得了解的细节. 原文:React入门看这篇就够了 作者:Random Fundebug经授权转载,版权归原作者所有. React 背景介绍 React 入门实例教程 React 起源于 ...
- cdmc2016数据挖掘竞赛题目Android Malware Classification
http://www.csmining.org/cdmc2016/ Data Mining Tasks Description Task 1: 2016 e-News categorisation F ...
- jps简介
java虚拟机进程状态工具-jps 功能简介 列出指定机器上的虚拟机的进程状态 命令格式 jps [ options ] [ hostid ] 其中options选项可有 选项 作用描述 -q 只输出 ...
- H3C STP监控与维护
- linux进程一个阻塞 I/O 的例子
最后, 我们看一个实现了阻塞 I/O 的真实驱动方法的例子. 这个例子来自 scullpipe 驱 动; 它是 scull 的一个特殊形式, 实现了一个象管道的设备. 在驱动中, 一个阻塞在读调用上的 ...
- The Preliminary Contest for ICPC Asia Nanjing 2019ICPC南京网络赛
B.super_log (欧拉降幂) •题意 定一个一个运算log*,迭代表达式为 给定一个a,b计算直到迭代结果>=b时,最小的x,输出对m取余后的值 •思路 $log*_{a}(1)=1+l ...
- JavaSE基础知识---常用对象API之String类
一.String类 Java中用String类对字符串进行了对象的封装,这样的好处在于对象封装后可以定义N多属性和行为,就可以对字符串这种常见的数据进行方便的操作. 格式:(1)String s1 = ...
- 快排java代码
定一个基准位,递归左右两边排序. public void fun(){ int arr[] = {2,3,4,5,6,7,822,3,4,5,8,6,5,4,2,1}; //System.out.pr ...