HashMap 原理解析
HashMap是由数组加链表的结合体。如下图:
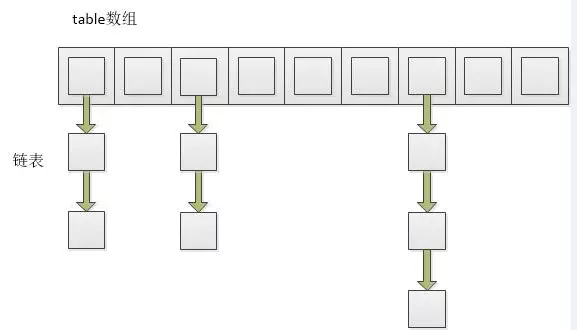
图中可以看出HashMap底层就是一个数组结构,每个数组中又存储着链表(链表的引用)
JDK1.6实现hashmap的方式是采用位桶(数组)+链表的方式,即散列链表方式。JDK1.8则是采用位桶+链表/红黑树的方式,即当某个位桶的链表长度达到某个阈值(8)的时候,这个链表就转化成红黑树,这样大大减少了查找时间。
存储查找原理:
- 存储:首先获取key的hashcode,然后取模数组的长度,这样可以快速定位到要存储到数组中的坐标,然后判断数组中是否存储元素,如果没有存储则,新构建Node节点,把Node节点存储到数组中,如果有元素,则迭代链表(红黑二叉树),如果存在此key,默认更新value,不存在则把新构建的Node存储到链表的尾部。
- 查找:同上,获取key的hashcode,通过hashcode取模数组的长度,获取要定位元素的坐标,然后迭代链表,进行每一个元素的key的equals对比,如果相同则返回该元素。
HashMap在相同元素个数时,数组的长度越大,则Hash的碰撞率越低,则读取的效率就越高,数组长度越小,则碰撞率高,读取速度就越慢。典型的空间换时间的例子。
下面我们分析HashMap的源码:
HashMap的结构属性:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
//存储数据的Node数组
transient Node<K,V>[] table;
//返回Map中所包含的Map.Entry<K,V>的Set视图。
transient Set<Map.Entry<K,V>> entrySet;
//当前存储元素的总个数
transient int size;
//HashMap内部结构发生变化的次数,主要用于迭代的快速失败(下面代码有分析此变量的作用)
transient int modCount;
//下次扩容的临界值,size>=threshold就会扩容,threshold等于capacity*load factor
int threshold;
//装载因子
final float loadFactor; //默认装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//由链表转换成红黑树的阈值TREEIFY_THRESHOLD
static final int TREEIFY_THRESHOLD = 8;
//由红黑树的阈值转换链表成UNTREEIFY_THRESHOLD
static final int UNTREEIFY_THRESHOLD = 6;
//默认容量(16)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//数组的最大容量 (1073741824)
static final int MAXIMUM_CAPACITY = 1 << 30;
//当桶中的bin(链表中的元素)被树化时最小的hash表容量。(如果没有达到这个阈值,即hash表容量小于MIN_TREEIFY_CAPACITY,当桶中bin的数量太多时会执行resize扩容操作)这个MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。
static final int MIN_TREEIFY_CAPACITY = 64;
略...
链表的结构
static class Node<K,V> implements Map.Entry<K,V> {
//hash
final int hash;
final K key;
V value;
Node<K,V> next;
略...
红黑二叉树的结构
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父节点
TreeNode<K,V> left; //左节点
TreeNode<K,V> right; //右节点
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
HashMap.put(key, value)插入方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//p:链表节点 n:数组长度 i:链表所在数组中的索引坐标
Node<K,V>[] tab; Node<K,V> p; int n, i;
//判断tab[]数组是否为空或长度等于0,进行初始化扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//判断tab指定索引位置是否有元素,没有则,直接newNode赋值给tab[i]
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//如果该数组位置存在Node
else {
//首先先去查找与待插入键值对key相同的Node,存储在e中,k是那个节点的key
Node<K,V> e; K k;
//判断key是否已经存在(hash和key都相等)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//如果Node是红黑二叉树,则执行树的插入操作
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//否则执行链表的插入操作(说明Hash值碰撞了,把Node加入到链表中)
else {
for (int binCount = 0; ; ++binCount) {
//如果该节点是尾节点,则进行添加操作
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断如果链表长度,如果链表长度大于8则调用treeifyBin方法,判断是扩容还是把链表转换成红黑二叉树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果键值存在,则退出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//把p执行p的子节点,开始下一次循环(p = e = p.next)
p = e;
}
}
//在循环中判断e是否为null,如果为null则表示加了一个新节点,不是null则表示找到了hash、key都一致的Node。
if (e != null) { // existing mapping for key
V oldValue = e.value;
//判断是否更新value值。(map提供putIfAbsent方法,如果key存在,不更新value,但是如果value==null任何情况下都更改此值)
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//此方法是空方法,什么都没实现,用户可以根据需要进行覆盖
afterNodeAccess(e);
return oldValue;
}
}
//只有插入了新节点才进行++modCount;
++modCount;
//如果size>threshold则开始扩容(每次扩容原来的1倍)
if (++size > threshold)
resize();
//此方法是空方法,什么都没实现,用户可以根据需要进行覆盖
afterNodeInsertion(evict);
return null;
}
1.判断键值对数组tab[i]是否为空或为null,否则执行resize()进行扩容;
2.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向6,如果table[i]不为空,转向3;
3.判断链表(或二叉树)的首个元素是否和key一样,不一样转向④,相同转向6;
4.判断链表(或二叉树)的首节点 是否为treeNode,即是否是红黑树,如果是红黑树,则直接在树中插入键值对,不是则执行5;
5.遍历链表,判断链表长度是否大于8,大于8的话把链表转换为红黑树(还判断数组长度是否小于64,如果小于只是扩容,不进行转换二叉树),在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;如果调用putIfAbsent方法插入,则不更新值(只更新值为null的元素)。
6.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
1、首先判断数组的长度是否小于64,如果小于64则进行扩容
2、否则把链表结构转换成红黑二叉树结构
modCount 变量的作用
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
疑问解答:
1、hash取余数,为什么不用取模操作呢,而用tab[i = (n - 1) & hash]?
它通过 (n - 1) & hash来得到该对象的保存位,而HashMap底层数组的长度总是2的n次方,这是HashMap在速度上的优化。当length总是2的n次方时, (n - 1) & hash运算等价于对length取模,也就是h%length,但是&比%具有更高的效率。
2、为什么使用红黑二叉树呢?
因为在好的算法,也避免不了hash的碰撞,避免不了链表过长的的情况,一旦出现链表过长,则严重影响到HashMap的性能。JDK8对HashMap做了优化,把链表长度超过8个的,则改成红黑二叉树,提高访问的速度。
HashMap 原理解析的更多相关文章
- Java 7 和 Java 8 中的 HashMap原理解析
HashMap 可能是面试的时候必问的题目了,面试官为什么都偏爱拿这个问应聘者?因为 HashMap 它的设计结构和原理比较有意思,它既可以考初学者对 Java 集合的了解又可以深度的发现应聘者的数据 ...
- Java集合详解(三):HashMap原理解析
概述 本文是基于jdk8_271版本进行分析的. HashMap是Map集合中使用最多的.底层是基于数组+链表实现的,jdk8开始底层是基于数组+链表/红黑树实现的.HashMap也会动态扩容,与Ar ...
- HashMap原理解析
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O(1 ...
- HASHMAP原理解析,不错的文章
http://blog.csdn.net/vking_wang/article/details/14166593
- (转)HashMap深入原理解析
[HashMap]深入原理解析 分类: 数据结构 自考 equals与“==”(可以参考自己的另一篇博文) 1,基本数据类型(byte,short,char,int,long,float,double ...
- HashMap数据结构与实现原理解析(干货)
HashMap 数据结构解析: HashMap内部使用hash表(本质是一个数组见图一) HashMap使用hash算法计算得到存放的索引位置,以此来加快查询速度,(比ArrayList还要快) 同样 ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
- Volley 实现原理解析(转)
Volley 实现原理解析 转自:http://blog.csdn.net/fengqiaoyebo2008/article/details/42963915 1. 功能介绍 1.1. Volley ...
- java集合框架之java HashMap代码解析
java集合框架之java HashMap代码解析 文章Java集合框架综述后,具体集合类的代码,首先以既熟悉又陌生的HashMap开始. 源自http://www.codeceo.com/arti ...
随机推荐
- React 从零搭建项目 使用 create-react-app脚手架
一.安装 npm install -g create-react-app 版本校验:create-react-app --version 二.创建项目 create-react-app指令默认调用np ...
- Win7中右下角“小喇叭”声音图标消失的解决方法?(已解决)
Win7中右下角"小喇叭"声音图标消失的解决方法?(已解决) 1.打开任务管理器. 2.右键explorer.exe选择右键结束. 3.在按ctrl+shift+Esc,或者用al ...
- COGS 775 山海经
COGS 775 山海经 思路: 求最大连续子段和(不能不选),只查询,无修改.要求输出该子段的起止位置. 线段树经典模型,每个节点记录权值和sum.左起最大前缀和lmax.右起最大后缀和rmax.最 ...
- HDU-1260_Tickets
Tickets Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Problem Des ...
- Vue.js 第5章 webpack配置
为什么我们需要打包构建工具:因为我们以后做项目的时候,会使用到很多种不同的工具或者语言,这些工具或者语言其实浏览器并不支持 webpack 是一个现代 JavaScript 应用程序的模块打包器(mo ...
- 5-2 正则表达式及其re模块
一 正则表达式 在线测试工具 http://tool.chinaz.com/regex/ 字符 量词 贪婪匹配 贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配,<.*&g ...
- 【[Offer收割]编程练习赛9 B】水陆距离
[题目链接]:http://hihocoder.com/problemset/problem/1478 [题意] [题解] 一开始把所有的水域的位置都加入到队列中去; 然后跑一个bfs. 第一次到达的 ...
- PyTorch 学习笔记(四):权值初始化的十种方法
pytorch在torch.nn.init中提供了常用的初始化方法函数,这里简单介绍,方便查询使用. 介绍分两部分: 1. Xavier,kaiming系列: 2. 其他方法分布 Xavier初始化方 ...
- [kuangbin带你飞]专题九 连通图E POJ 3177 Redundant Paths
这个题最开始我想的是,直接缩点求双连通分量,连接这些双联通分量不就行了吗? 但是其实是不对的,双连通内部双联通,我们如果任意的连接一条边在这些双联通分量之间,他们之间有没有桥其实并不知道. 我应该是求 ...
- 深入Java线程管理(四):线程通讯
线程间的相互作用 线程间的相互作用:线程之间需要一些协调通信,来共同完成一件任务. Object类中相关的方法有两个notify方法和三个wait方法: http://docs.oracle.com/ ...