MySQL 高可用之主从复制
MySQL主从复制简介
Mysql的主从复制方案,都是数据传输的,只不过MySQL无需借助第三方工具,而是自带的同步复制功能,MySQL的主从复制并不是磁盘上文件直接同步,而是将binlog日志发送给从库,由从库将binlog文件里的内容写入本地数据库。
在生产环境中,MySQL主从复制都是异步方式同步,即不是实时同步数据。
MySQL主从复制原理
1.主从复制中的线程及文件
- 主库线程:
- Dump(IO) thread(也成为
IO线程):在复制过程中,主库发送二进制日志的线程
- Dump(IO) thread(也成为
- 从库线程:
- IO thread:向主库请求binlog日志,并且接受binlog日志的线程
- SQL thread:专门用于请求binlog日志的线程,将其内容写入数据库
- 主库的文件:
- binlog文件:主库的binlog日志
- 从库的文件:
- relaylog:中继日志,存储请求过来的binlog日志
- master.info:
- 从库连接主库的重要参数(user,password,ip,port)
- 记录最后一次获取过主库的binlog日志的位置点
- relay-log.info
- 存储从库SQL线程已经执行过的relaylog日志位置点
Mysql主从复制图解:
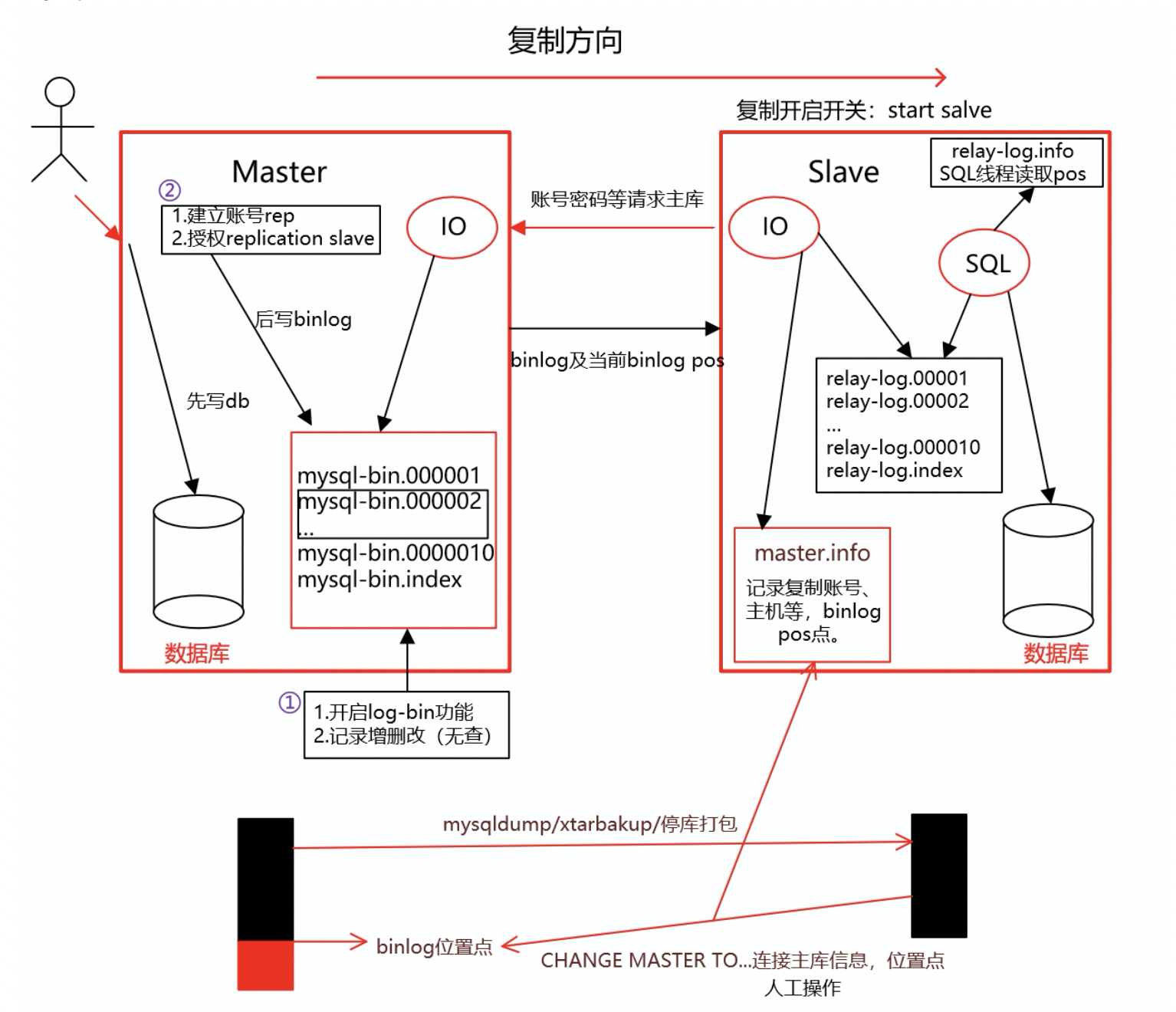
从库读取master.info文件中的信息(连接参数,最后一次请求binlog的位置点),向主库请求binlog文件,主库接受到从库发送过来的信息后(验证通过),将本地对应的binlog日志发送至从库,从库接收到binlog文件后,会存储到TCP/IP缓存中,并发送ACK给主库,告诉主库自己已经收到binlog日志了,那么主库收到ACK后接着干别的事了,从库将TCP/IP缓存中的内容写入到本地的relaylog日志文件中,从库会将最后一次获取到的binglog位置点更新至master.info文件,然后IO线程读取relay-log.info中的最后一次执行到的relaylog位置点(以这个位置点为起点,往后执行中继日志),最后将relaylog日志文件中对应的位置点的内容写入(恢复)数据库中,执行完数据写入后,将最后最后一次执行数据写入(恢复)的relaylog位置点更新至relay-log.info文件
每一次binglog请求都是按照上面所写的循序来执行
MySQL主从复制部署
MySQL主从复制条件
- 两台以上mysql实例(多台物理机或多个mysql实例)
- 开启
binlog功能,确保所有实例server-id不同 - 主库建立
同步账号(replication slave特殊的权限) - 将全备文件恢复到
从库上(需人为操作) - 从库配置
master.info(change master..),复制的binlog位置点(需人为操作) - start
slave复制开关
1.环境规划
所有机器统一centos7.4系统环境,并且都已经安装好了mysql 5.7.20
| 主机名 | IP地址 | 服务 |
|---|---|---|
| db01 | 10.0.0.51 | mysql 主库 |
| db02 | 10.0.0.52 | mysql 从库 |
2.所有mysql都开启binlog功能,确保所有mysql的server-id不同
需要添加的配置如下:
#主库 /etc/my.cnf
[mysqld]
server_id=1
log-bin=/application/mysql/data/mysql-bin
sync_binlog = 1
binlog_format = row
skip-name-resolve #关闭域名解析
#从库 /etc/my.cnf
[mysqld]
server_id=2
log-bin=/application/mysql/data/mysql-bin
sync_binlog = 1
binlog_format = row
skip-name-resolve
提示:从库的relay-log路径可自定义,默认在data目录下以主机为前缀保存
server-id 用于全网唯一标识一台mysql机器
2.主库授权主从复制用户
replication slave 一个特殊的权限,专门用于主从复制
mysql> grant replication slave on *.* to rep@'10.0.0.%' identified by '123456';
3.主库将数据库数据做全备,然后将备份文件推送至从库
- 主和从同时搭建新的环境,就不需要备份主库数据,恢复从库了,直接从第一个binlog(mysql-bin.000001)开头位置(120)
- 如果主库已经工作了很长时间了,那么需要备份主库数据,恢复到从库,然后从库从备份的时间点起,自动进行复制
#1.将数据库的数据全备到/backup目录下
[root@db01 ~]# mysqldump -uroot -p123456 -A -B -R --master-data=2 --single-transaction |gzip >/backup/full_$(date +%F).sql.gz
#2.将全备通过scp推送到从库的/backup目录下
[root@db01 ~]# scp /backup/full_2019-01-15.sql.gz root@10.0.0.52:/backup
提示:/backup 目录请自行创建
4.从库将备份文件恢复至数据库
#1.解压备份文件
[root@db02 ~]# gunzip /backup/full_2019-01-15.sql.gz
#2.进入数据库,将备份文件导入到本地数据库
mysql> source /backup/full_2019-01-15.sql
#3.检查数据是否恢复成功
mysql> show databases;
5.从库上都找到binlog位置点
虽然全备文件已经恢复到了从库,但是全备之后的数据的变化是没有进行备份的,所以从库还需要指定binlog位置点,这样从库才知道该从哪里开始同步数据
#直接在从库的全备文件中找到binlog位置点
[root@db02 /]# sed -n '22p' /backup/full_2019-01-15.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154;
6.从库配置master info
master info就是指配置一系列主从复制参数,该参数为change master to,来实现主从复制
#1.进入数据库配置 change master to
change master to
master_host='10.0.0.51',
master_port=3306,
master_user='rep',
master_password='123456',
master_log_file='mysql-bin.000001',
master_log_pos=154;
#2.开启主从同步功能(开启IO和SQL线程),
mysql> start slave;
#3.查看主从复制的状态(截取部分)
#当在slave状态中可以看到如下参数,都为yes表明成功,(从库有一个IO和一个SQL)
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
change master to参数解释:
master_host='10.0.0.51', #主库的IP地址
master_port=3306, #主库的端口
master_user='rep', #主库上创建的用于复制的用户rep
master_password='123456', #rep用户的密码
master_log_file='mysql-bin.000001', #二进制日志文件的名称
master_log_pos=154; #二进制日志偏移量
提示:mysql> help change master to 可获取配置案例
slave的操作命令:
mysql> stop slave; #停止slave
mysql> reset slave; #清空slave的配置参数(change master to)
从库的master.info和relay-log.info文件
#执行完change master to命令后,会自动生成master.info文件,保存change master to的参数和最后一次获取binlog日志文件名和对应的位置点
ls /application/mysql/data/master.info
#执行完start slave命令后,会自动生成relay-log.info文件,保存已执行过的relaylog的位置点
ls /application/mysql/data/relay-log.info
7.主库创建数据库,在到从库验证数据是否同步
#1.主库创建数据库:sample
mysql> create database sample;
#2.从库查看数据是否同步
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| case1 |
| case2 |
| mysql |
| performance_schema |
| sample |
| sys |
| test |
| xmh |
+--------------------+
从库去向主库请求的binlog日志会保存在从库本地的relaylog日志中
[root@db02 /]# ls /application/mysql/data/db02-relay-bin.*
/application/mysql/data/db02-relay-bin.000001
/application/mysql/data/db02-relay-bin.000002
/application/mysql/data/db02-relay-bin.index
扩展:从库开启记录binlog功能
从库需要记录binlog的应用场景为:当前的从库还需要作为其它从库的主库,例如:级联复制和双主互为主从场景的情况下
#从库的my.cnf中加入如下参数,然后重启服务生效即可
log-slave-updates #开启从库记录binlog功能
log-bin = /application/mysql/data/mysql-bin
expire_logs_days = 7 #bin-log保留时间(只保留7天)
MySQL 高可用之主从复制的更多相关文章
- 003.MySQL高可用主从复制新增slave
一 基础环境 主机名 系统版本 MySQL版本 主机IP master CentOS 6.8 MySQL 5.6 172.24.8.10 slave01 CentOS 6.8 MySQL 5.6 17 ...
- MySQL高可用主从复制新增slave
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html作者:木二 目录 一 基础环境 二 新增slave2方案 2.1 方案1:-复制主库 2.2 方案2 ...
- MySQL高可用架构之MHA
简介: MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是 ...
- mysql高可用架构
高可用 高可用(High Availabiltity) 应用提供持续不间断(可用)的服务的能力 系统高可用性的评价通常用可用率表示 造成不可用的原因 硬件故障(各种) 预期中的系统软硬件维护 ...
- [转载] MySQL高可用方案选型参考
原文: http://imysql.com/2015/09/14/solutions-of-mysql-ha.shtml?hmsr=toutiao.io&utm_medium=toutiao. ...
- MySQL高可用之MHA的搭建 转
http://www.cnblogs.com/muhu/p/4045780.html http://www.cnblogs.com/gomysql/p/3675429.html http://www ...
- MySQL高可用之MHA (转)
MySQL高可用之MHA MHA简介 MHA是由日本人yoshinorim(原就职于DeNA现就职于FaceBook)开发的比较成熟的MySQL高可用方案.MHA能够在30秒内实现故障切换,并能在故障 ...
- mysql高可用方案MHA介绍
mysql高可用方案MHA介绍 概述 MHA是一位日本MySQL大牛用Perl写的一套MySQL故障切换方案,来保证数据库系统的高可用.在宕机的时间内(通常10-30秒内),完成故障切换,部署MHA, ...
- 搭建MySQL高可用负载均衡集群
1.简介 使用MySQL时随着时间的增长,用户量以及数据量的逐渐增加,访问量更是剧增,最终将会使MySQL达到某个瓶颈,那么MySQL的性能将会大大降低.这一结果也不利于软件的推广. 那么如何跨过这个 ...
随机推荐
- ELK学习实验010:Logstash简介
Logstash是具有实时流水线功能的开源数据收集引擎.Logstash可以动态统一来自不同来源的数据,并将数据规范化为您选择的目标.清除所有数据并使其民主化,以用于各种高级下游分析和可视化用例. 虽 ...
- $NOIp$做题记录
虽然去年做了挺多了也写了篇一句话题解了但一年过去也忘得差不多了$kk$ 所以重新来整理下$kk$ $2018(4/6$ [X]积木大赛 大概讲下$O(n)$的数学方法. 我是从分治类比来的$QwQ$. ...
- 博帝飚速盘 16G
设备制造商: Patriot Memory当前协议 : USB2.0输入电流 : 300mA 芯片制造商: 群联(Phison)芯片型号 : PS2251-38闪存颗粒 : 美光( ...
- 子网划分及NAT技术总结
近段项目需要用到网络相关的知识,硬着头皮又回顾了一波,这里做一下记录. 一 分类的IP地址 我们使用的IP地址(IP V4)可以划分为A,B,C,D,E 5个类型,其中的D,为组播地址,E类地址为保留 ...
- 【JavaScript学习笔记】函数、数组、日期
一.函数 一个函数应该只返回一种类型的值. 函数中有一个默认的数组变量arguments,存储着传入函数的所有参数. 为了使用函数参数方便,建议给参数起个名字. function fun1(obj, ...
- es6中的面向对象写法
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http ...
- 快速搭建一个自己的个人博客(Github Pages~二次元主题)
前言 本次的一个布局技术都写的非常详细了,只要按着来就行,不过,先说明本次主题为二次元主题. 如果真的喜欢本主题的不妨可以试一试(==建议跟据目录来看==) 在很久很久以前.... 嘛,就在前不久我正 ...
- 通过HttpClient的方式去Curd数据⭐⭐⭐⭐
在网上看博客的时候,看到这系列的文章,别特帮,强烈推荐 里面有一章节是通过HttpClient的方法去更新数据的,新颖,记录下. ⭐⭐⭐1:创建一个Model数据模型 这个类创建一个数据对象,Http ...
- load文件到hive,并保存
DataFrame usersDF = sqlContext.read().load("hdfs://spark1:9000/users.parquet"); usersDF.se ...
- python 黏包现象
一.黏包 1.tcp有黏包现象 表现两种情况 发送的数据过小且下面还有一个发送数据,这两个数据会一起发送 发送的数据过大,超过最大缓存空间,超出的部分在下一次发送的时候发送 原因: tcp是面向流的, ...