scrapy运行的整个流程
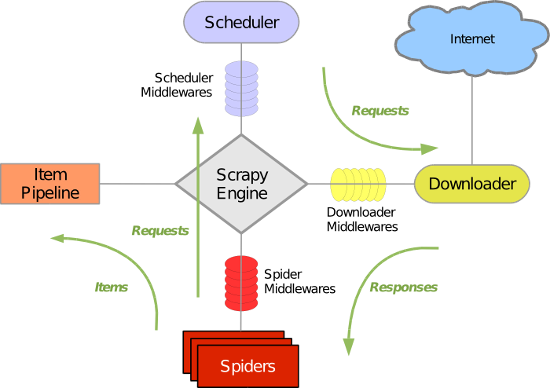
Spiders:
负责处理所有的response,从这里面分析提取数据,获取Item字段所需要的数据,并将需要跟进的URL提交给引擎,再次进入到Scheduler调度器中
Engine:
框架的核心,负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据的传递等
Scheduler:
它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理队列,当引擎需要的时候,交还给引擎
Downloader:
负责下载Engine发送过来的所有的requests请求,并将其获取到的response交还给Engine,由Engine交给Spider来进行处理
ItemPipeline:
它负责处理Spider中获取到的Item,并交给进行后期处理(详细分析、过滤、存储等)的地方
DownloaderMiddlewares(下载中间件):
介于Scrapy引擎和下载器之间的中间件,主要是处理Scrapy引擎与下载器之间的请求以及响应
SpiderMiddlewares(Spider中间件):
介于Scrapy引擎和爬虫之间的中间件,主要工作是处理蜘蛛的响应输入和请求输出
SchedulerMiddlewares(调度中间件):
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的响应和请求
执行顺序:
- Spider的yield将requests发送给Engine
- Engine对requests不做任何的处理就发送给Scheduler
- Scheduler(url调度器),生成requests交给Engine
- Engine拿到requests,通过middleware进行层层过滤发送给Downloader
- downloader在网上获取到response数据之后,又经过middleware进行层层过滤发送给Engine
- Engine获取到response之后,返回给Spider,Spider的parse()方法对获取到的response数据进行处理解析出items或者requests
- 将解析出来的items或者requests发送给Engine
- Engine获取到items或者requests,将items发送给ITEMPIPELINES,将requests发送给Scheduler
只有当调度器中不存在任何的requests的时候,整个程序才会停止(也就是说,对于下载失败的URL,scrapy也会重新进行下载)
1.引擎:Hi!Spider, 你要处理哪一个网站?
2.Spider:老大要我处理xxxx.com(初始URL)。
3.引擎:你把第一个需要处理的URL给我吧。
4.Spider:给你,第一个URL是xxxxxxx.com。
5.引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6.调度器:好的,正在处理你等一下。
7.引擎:Hi!调度器,把你处理好的request请求给我。
8.调度器:给你,这是我处理好的request
9.引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
10.下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11.引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12.Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13.引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14.管道、调度器:好的,现在就做!
开发Scrapy爬虫的步骤
- 创建项目:scrapy startproject 项目名称
- 明确目标:便携item,明确你要爬取的目标
- 制作爬虫:编写爬虫,开始爬取网页
- 存储内容:设计管道存储爬取内容
- 添加启动程序的文件:就是启动的main文件
parse方法的工作机制:
- 因为使用的是yield,而不是return。parse函数将会被当作一个生成器使用,scrapy回逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型
- 如果是requests则加入爬取队列,如果是item类型则使用Pipeline处理,其他的就返回错误信息
- scrapy取到第一部分的requests不会立马就去发送这个requests,只是把这个requests放到队列里,然后接着从生成器礼获取
- 取尽第一部分的requests,然后在获取第二部分的item,取到item之后,就会放到对应的pipeline里进行处理
- parse方法作为回调函数复制给了Request,指定parse方法来处理这些请求
- Request对象经过调度,执行生成scrapy.http.response()的响应对象,并送回给parse方法,直到调度器中没有Request(递归的思路)
- 取完之后,parse方法工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作
- 程序在取得各个页面的items之前,会先处理完之前所有的requests队列里的请求,然后在提取items
- 综上所述一切,scrapy引擎和调度器将会负责到底
scrapy运行的整个流程的更多相关文章
- scrapy运行机制
Scrapy主要包括了以下组件: 引擎(Scrapy)用来处理整个系统的数据流, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回 ...
- scrapy的 安装 及 流程 转
安装 linux 和 mac 直接 pip install scrapy 就行 windows 安装步骤 a. pip3 install wheel b. 下载twist ...
- 玩转Windows服务系列——服务运行、停止流程浅析
通过研究Windows服务注册卸载的原理,感觉它并没有什么特别复杂的东西,Windows服务正在一步步退去它那神秘的面纱,至于是不是美女,大家可要睁大眼睛看清楚了. 接下来研究一下Windows服务的 ...
- Web程序的运行原理及流程(一)
自己做Web程序的开发也有两年多了 从最开始跟风学框架 到第一用上框架的欣喜若狂 我相信每个程序员都是这样过来的 在大学学习一门语言 学会后往往很想做一个实际的项目出来 我当时第一次做WEB项目看 ...
- 玩转Windows服务系列——服务运行、停止流程浅析
原文:玩转Windows服务系列——服务运行.停止流程浅析 通过研究Windows服务注册卸载的原理,感觉它并没有什么特别复杂的东西,Windows服务正在一步步退去它那神秘的面纱,至于是不是美女,大 ...
- [转] Linux下程序的加载、运行和终止流程
TAG: linux, main, _start DATE: 2013-08-08 原文地址: http://blog.csdn.net/tigerscorpio/article/details/62 ...
- Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程 1.核心组件 # 引擎(Scrapy) 对整个系统的数据流进行处理, 触发事务(框架核心). # 调度器(Scheduler) 用来接受引擎发过来的请求. 由过滤 ...
- 浅析Scrapy框架运行的基本流程
本篇博客将从Twisted的下载任务基本流程开始介绍,然后再一步步过渡到Scrapy框架的基本运行流程,其中还会需要我们自定义一个Low版的Scrapy框架.但内容不会涉及太多具体细节,而且需要注意的 ...
- Scrapy运行流程
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示). 下面对每个组件都做了简单介绍,并给出了详细内容的链接.数据流如下所描述. 来源于https://scrap ...
随机推荐
- 【NOI2019模拟2019.6.27】B (生成函数+整数划分dp|多项式exp)
Description: \(1<=n,k<=1e5,mod~1e9+7\) 题解: 考虑最经典的排列dp,每次插入第\(i\)大的数,那么可以增加的逆序对个数是\(0-i-1\). 不难 ...
- 码云挂了,无法访问gitee
解决方式1.修改dns为114.114.114.114 2.hosts文件添加212.64.62.174 gitee.com
- 牛客多校第八场 G Gemstones 栈/贪心
题意: 对于一个序列,把可以把连着三个相同的字母拿走,问最多拿走多少组. 题解: 直接模拟栈,三个栈顶元素相同则答案+1,并弹出栈 #include<bits/stdc++.h> usin ...
- [转]WinForm DataGridView 绑定泛型List(List<T>)/ArrayList不显示的原因和解决
背景:无意间遇到了一个不大不小的问题,希望对一些遇到的人有所帮助! 一.问题 WinForm DataGridView 绑定泛型List (List<T>)/ArrayList不显示,UI ...
- CVE-2018-3246 weblogic xxe
使用P牛2018-2894的容器 http://192.168.245.130:7001/ws_utc/begin.do 导入测试用例 上传时抓取数据包 POST /ws_utc/resources/ ...
- 使用反射机制,获取 ArrayList 的容量大小
本文所有说明及代码示例都是基于JDK 1.8 ArrayList 提供size()方法获取当前集合的元素数量,但无法知道当前集合的容量,翻看 ArrayList 的源代码,可以看到字段 elemen ...
- 分布式存储glusterfs
什么是glusterfs? Glusterfs是一个开源分布式文件系统,具有强大的横向扩展能力,可支持数PB存储容量的数干客户端,通过网络互联成一个并行的网络文件系统.具有可扩展性.高性能.高可用性等 ...
- [Java]读取文件方法大全(转载)
1.按字节读取文件内容2.按字符读取文件内容3.按行读取文件内容4.随机读取文件内容 public class ReadFromFile { /** * 以字节为单位读取文件,常用于读二进制文件,如图 ...
- 随笔记录 MBR扇区故障系统备份与还原 2019.8.7
系统备份: [root@localhost ~]# mkdir /abc [root@localhost ~]# mount /dev/sdb1 /abc [root@localhost ~]# dd ...
- XSS攻击原理
本文转载的地址:http://www.2cto.com/Article/201209/156182.html Xss(cross-site scripting)攻击指的是攻击者往Web页面里插入恶意h ...