深度残差网络——ResNet学习笔记
深度残差网络—ResNet总结
写于:2019.03.15—大连理工大学
论文名称:Deep Residual Learning for Image Recognition
作者:微软亚洲研究院的何凯明等人 论文地址:https://arxiv.org/pdf/1512.03385v1.pdf
摘要:
随着人们对于神经网络技术的不断研究和尝试,每年都会诞生很多新的网络结构或模型。这些模型大都有着经典神经网络的特点,但是又会有所变化。你说它们是杂交也好,是变种也罢,总之针对神经网络的创新的各种办法那真叫大开脑洞。而这些变化通常影响的都是使得这些网络在某些分支领域或者场景下表现更为出色(虽然我们期望网络的泛化性能够在所有的领域都有好的表现)。深度残差网络(deep residual network)就是众多变种中的一个代表,而且在某些领域确实效果不错,例如目标检测(object detection)。
1、引言
2015年时,还在MSRA的何恺明祭出了ResNet这个“必杀技”,在ISLVRC和COCO上“横扫”了所有的对手,可以说是顶级高手用必杀技进行了一场杀戮。除了取得了辉煌的成绩之外,更重要的意义是启发了对神经网络的更多的思考。可以说深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件。
ResNet的作者何恺明获得了CVPR2016最佳论文奖。那么ResNet为什么会如此优异的表现呢?其实ResNet是解决了深度CNN模型难训练的问题,我们知道2014年的VGG才19层,而15年的ResNet多达152层,这在网络深度完全不是一个量级上,所以如果是第一眼看到这个层数的话,肯定会觉得ResNet是靠深度取胜。事实当然是这样,但是ResNet还有架构上的trick,这才使得网络的深度发挥出作用,这个trick就是残差学习(Residual learning)。接下来我们将详细分析ResNet的原理。
2、为什么会提出ResNet残差网络呢?
VGG网络试着探寻了一下深度学习网络的深度究竟可以深到何种程度还可以持续提高分类的准确率。对于传统的深度学习网络,我们普遍认为网络深度越深(参数越多)非线性的表达能力越强,该网络所能学习到的东西就越多。我们凭借这一基本规则,经典的CNN网络从LetNet-5(5层)和AlexNet(8层)发展到VGGNet(16-19),再到后来GoogleNet(22层)。根据VGGNet的实验结果可知,在某种程度上网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果,从图1中也可以看出网络越深而效果越好的一个实践证据。
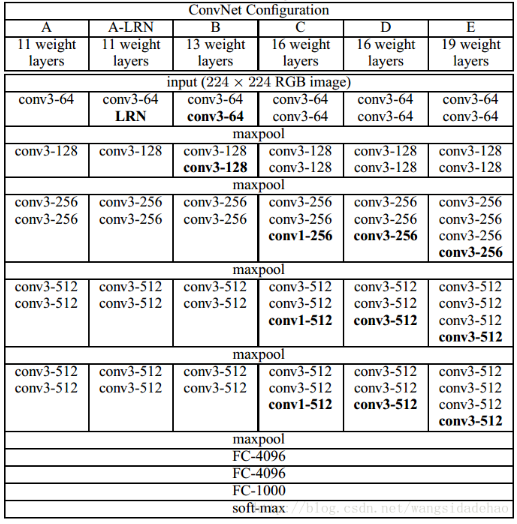
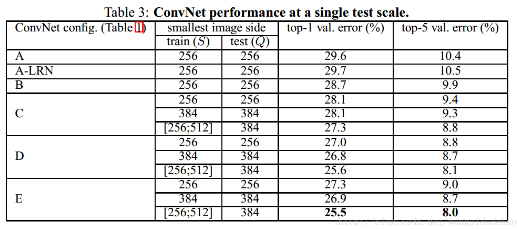
图1:VGGNet网络结构和实验结果
但是更深的网络其性能一定会更好吗?我们后来发现传统的CNN网络结构随着层数加深到一定程度之后,越深的网络反而效果更差,过深的网络竟然使分类的准确率下降了(相比于较浅的CNN而言)。比较结果如图2。
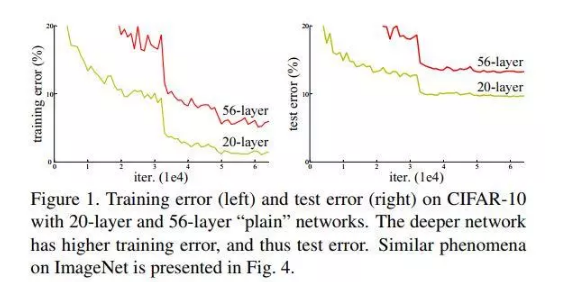
图2:常规的CNN网络过分加深网络层数会带来分类准确率的降低
为什么CNN网络层数增加分类的准确率却下降了呢?难道是因为模型参数过多表达能力太强出现了过拟合?难道是因为数据集太小出现过拟合?显然都不是!!!我们来看,什么是过拟合呢?过拟合就是模型在训练数据上的损失不断减小,在测试数据上的损失先减小再增大,这才是过拟合现象。根据图2 的结果可以看出:56层的网络比20层网络在训练数据上的损失还要大。这可以肯定不会是过拟合问题。因此,我们把这种问题称之为网络退化问题(Degradation problem)。
我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
何恺明举了一个例子:考虑一个训练好的网络结构,如果加深层数的时候,不是单纯的堆叠更多的层,而是堆上去一层使得堆叠后的输出和堆叠前的输出相同,也就是恒等映射/单位映射(identity mapping),然后再继续训练。这种情况下,按理说训练得到的结果不应该更差,因为在训练开始之前已经将加层之前的水平作为初始了,然而实验结果结果表明在网络层数达到一定的深度之后,结果会变差,这就是退化问题。这里至少说明传统的多层网络结构的非线性表达很难去表示恒等映射(identity mapping),或者说你不得不承认目前的训练方法或许有点问题,才使得深层网络很难去找到一个好的参数去表示恒等映射(identity mapping)。
3、深度残差网络结构学习(Deep Residual learning)
(1)残差单元
这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。对于一个堆积层结构(几层堆积而成)当输入为x时其学习到的特征记为H(x),现在我们希望其可以学习到残差F(x) = H(x) - x,这样其实原始的学习特征是H(x)。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为F(x) = 0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如图3所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
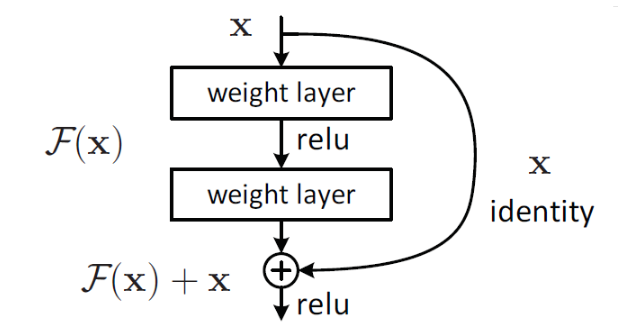
图3:残差学习单元
为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
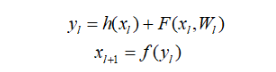
其中,XL和XL+1分别表示第L个残差单元的输入和输出,注意每个残差单元一般包含多层结构。F是残差函数,表示学习到的残差,而h(XL) = XL表示恒等映射,f 是ReLu激活函数。基于上式,我们求得从浅层 l 到深层 L 的学习特征。
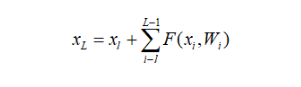
我们可以知道,对于传统的CNN,直接堆叠的网络相当于一层层地做——仿射变换-非线性变换,而仿射变换这一步主要是矩阵乘法。所以总体来说直接堆叠的网络相当于是乘法性质的计算。而在ResNet中,相对于直接堆叠的网络,因为shortcut的出现,计算的性质从乘法变成了加法。计算变的更加稳定。当然这些是从前向计算的角度,从后向传播的角度,如果代价函数用Loss表示,则有

也就是说,无论是哪层,更高层的梯度成分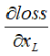 都可以直接传过去。小括号中的1表明短路机制(shortcut)可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。这样一来梯度的衰减得到进一步抑制,并且加法的计算让训练的稳定性和容易性也得到了提高。所以可训练的网络的层数也大大增加了。
都可以直接传过去。小括号中的1表明短路机制(shortcut)可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有1的存在也不会导致梯度消失。这样一来梯度的衰减得到进一步抑制,并且加法的计算让训练的稳定性和容易性也得到了提高。所以可训练的网络的层数也大大增加了。
(2)恒等映射/单位映射(identity mapping)
我们知道残差单元通过 identity mapping 的引入在输入和输出之间建立了一条直接的关联通道,从而使得强大的有参层集中学习输入和输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X 。当输入和输出通道数相同时,我们自然可以如此直接使用X进行相加。而当它们之间的通道数目不同时,我们就需要考虑建立一种有效的 identity mapping 函数从而可以使得处理后的输入X与输出Y的通道数目相同即Y = F(X, Wi) + Ws*X。
当X与Y通道数目不同时,作者尝试了两种 identity mapping 的方式。一种即简单地将X相对Y缺失的通道直接补零从而使其能够相对齐的方式,另一种则是通过使用1x1的conv来表示Ws映射从而使得最终输入与输出的通道达到一致的方式。
(3)瓶颈(BottleNeck)模块
如下图4所示,左图是一个很原始的常规模块(Residual block),实际使用的时候,残差模块和Inception模块一样希望能够降低计算消耗。所以论文中又进一步提出了“瓶颈(BottleNeck)”模块,思路和Inception一样,通过使用1x1 conv来巧妙地缩减或扩张feature map维度从而使得我们的3x3 conv的filters数目不受外界即上一层输入的影响,自然它的输出也不会影响到下一层module。不过它纯是为了节省计算时间进而缩小整个模型训练所需的时间而设计的,对最终的模型精度并无影响。
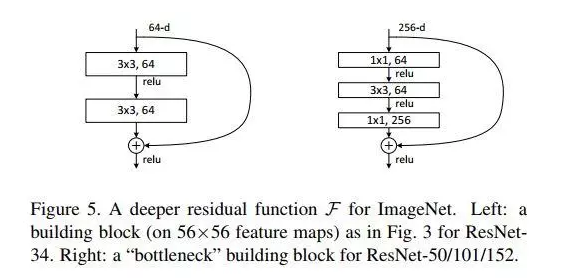
图4:BottleNeck模块
(4)ResNet的结构
ResNet网络是参考了VGG19的网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,featuremap的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示featuremap数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
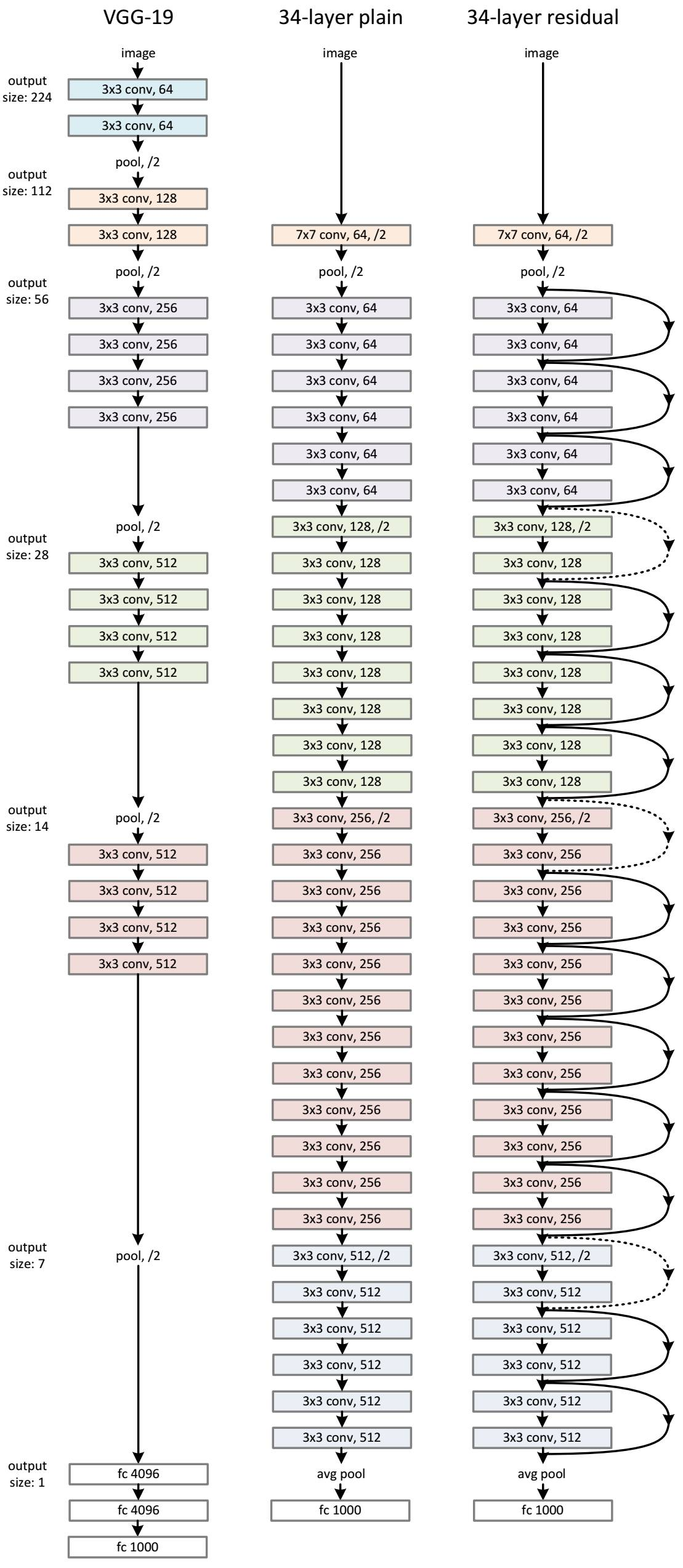
图5 ResNet网络结构图
表1 不同深度的ResNet
下面我们再分析一下残差单元,ResNet使用两种残差单元,如图6所示。左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:(1)采用zero-padding增加维度,此时一般要先做一个downsamp,可以采用strde=2的pooling,这样不会增加参数;(2)采用新的映射(projection shortcut),一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然都可以采用projection shortcut。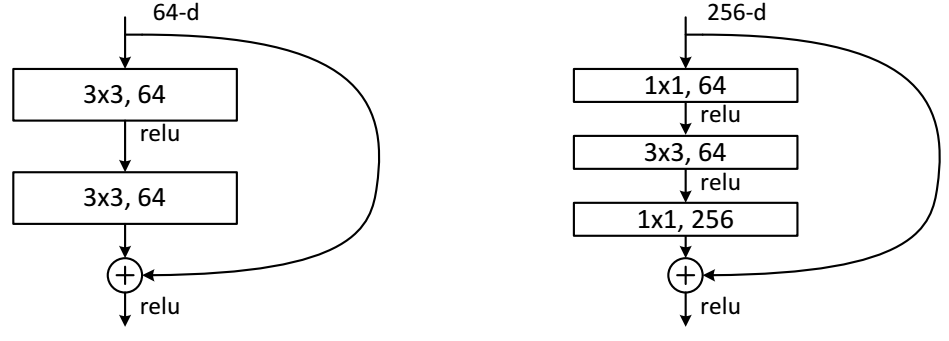
图6 不同的残差单元
作者对比18-layer和34-layer的网络效果,如图7所示。可以看到普通的网络出现退化现象,但是ResNet很好的解决了退化问题。
图7 18-layer和34-layer的网络效果
最后展示一下ResNet网络与其他网络在ImageNet上的对比结果,如表2所示。可以看到ResNet-152其误差降到了4.49%,当采用集成模型后,误差可以降到3.57%。
表2 ResNet与其他网络的对比结果
(5)ResNet的进一步改进
在2015年的ILSVRC比赛获得第一之后,何恺明对残差网络进行了改进,主要是把ReLu给移动到了conv之前,相应的shortcut不在经过ReLu,相当于输入输出直连。并且论文中对ReLu,BN和卷积层的顺序做了实验,最后确定了改进后的残差网络基本构造模块,如下图8所示,因为对于每个单元,激活函数放在了仿射变换之前,所以论文叫做预激活残差单元(pre-activation residual unit)。作者推荐在短路连接(shortcut)采用恒等映射(identity mapping)。

图8 改进后的残差单元及效果
参考博客:
你必须要知道的CNN模型ResNet:https://blog.csdn.net/u013709270/article/details/78838875
经典分类CNN模型系列其四:https://www.jianshu.com/p/93990a641066
深度残差网络——ResNet学习笔记的更多相关文章
- 深度残差网络(ResNet)
引言 对于传统的深度学习网络应用来说,网络越深,所能学到的东西越多.当然收敛速度也就越慢,训练时间越长,然而深度到了一定程度之后就会发现越往深学习率越低的情况,甚至在一些场景下,网络层数越深反而降低了 ...
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- CNN卷积神经网络_深度残差网络 ResNet——解决神经网络过深反而引起误差增加的根本问题,Highway NetWork 则允许保留一定比例的原始输入 x。(这种思想在inception模型也有,例如卷积是concat并行,而不是串行)这样前面一层的信息,有一定比例可以不经过矩阵乘法和非线性变换,直接传输到下一层,仿佛一条信息高速公路,因此得名Highway Network
from:https://blog.csdn.net/diamonjoy_zone/article/details/70904212 环境:Win8.1 TensorFlow1.0.1 软件:Anac ...
- 残差网络resnet学习
Deep Residual Learning for Image Recognition 微软亚洲研究院的何凯明等人 论文地址 https://arxiv.org/pdf/1512.03385v1.p ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
- 深度学习——手动实现残差网络ResNet 辛普森一家人物识别
深度学习--手动实现残差网络 辛普森一家人物识别 目标 通过深度学习,训练模型识别辛普森一家人动画中的14个角色 最终实现92%-94%的识别准确率. 数据 ResNet介绍 论文地址 https:/ ...
- 残差网络ResNet笔记
发现博客园也可以支持Markdown,就把我之前写的博客搬过来了- 欢迎转载,请注明出处:http://www.cnblogs.com/alanma/p/6877166.html 下面是正文: Dee ...
- Dual Path Networks(DPN)——一种结合了ResNet和DenseNet优势的新型卷积网络结构。深度残差网络通过残差旁支通路再利用特征,但残差通道不善于探索新特征。密集连接网络通过密集连接通路探索新特征,但有高冗余度。
如何评价Dual Path Networks(DPN)? 论文链接:https://arxiv.org/pdf/1707.01629v1.pdf在ImagNet-1k数据集上,浅DPN超过了最好的Re ...
- 关于深度残差网络(Deep residual network, ResNet)
题外话: From <白话深度学习与TensorFlow> 深度残差网络: 深度残差网络的设计就是为了克服这种由于网络深度加深而产生的学习效率变低,准确率无法有效提升的问题(也称为网络退化 ...
随机推荐
- ssl checker
ssl checker showThis server is vulnerable to the POODLE attack. If possible, disable SSL 3 t` POODLE ...
- 【JZOJ3422】水叮当的舞步
description 水叮当得到了一块五颜六色的格子形地毯作为生日礼物,更加特别的是,地毯上格子的颜色还能随着踩踏而改变. 为了讨好她的偶像虹猫,水叮当决定在地毯上跳一支轻盈的舞来卖萌~~~ 地毯上 ...
- 分享安装Apache、MySQL、PHP、LAMP的完整教程
Operation timed out after 30000 milliseconds with 0 out of -1 bytes received请注意,在Linux中输入密码时,不会显示您输入 ...
- python 随便笔记
1 判断字符串中是否有数字 i.isdigit()==True else False #判断是否是数字i.isalpha()==True else False #判断是否是字母 i.isspace() ...
- python相关软件安装流程图解——虚拟机操作——复制虚拟机主机——CentOS-7-x86_64-DVD-1810
请先确保已经安装了虚拟机 python相关软件安装流程图解——虚拟机安装——CentOS-7-x86_64-DVD-1810——CentOS-01下载 https://www.cnblogs.com/ ...
- sql还原数据库时候改变数据库名
需求:在做图书馆数据整合时候,由于有两个校区,用的是分离开的同一个数据库,数据库名字都一样的,现在我要整合在一起,我的想法是把两个数据库先还原到我本地,用写好的脚本整合到一起.所以,我还原两个数据库时 ...
- HYNB Round 8: 2016 ICPC Amritapuri Regionals
HYNB Round 8: 2016 ICPC Amritapuri Regionals A - Tim and BSTs 做法 经典的树 DP 问题. \(dp[u][i]\) 表示考虑以 u 为根 ...
- java 测试时 程序的 运行时间
检测一个JAVA程序的运行时间方法:long startTime = System.currentTimeMillis();//获取当前时间//doSomeThing(); //要运行的java程 ...
- 笔记:Python操作sql
python操作mysql步骤: 创建connect连接 conn = connect(host='127.0.0.1', port=3306, user='root', password='1234 ...
- [转]async & await 的前世今生(Updated)
async 和 await 出现在C# 5.0之后,给并行编程带来了不少的方便,特别是当在MVC中的Action也变成async之后,有点开始什么都是async的味道了.但是这也给我们编程埋下了一些隐 ...