使用Pycharm写一个网络爬虫
在初步了解网络爬虫之后,我们接下来就要动手运用Python来爬取网页了。
我们知道,网络爬虫应用一般分为两个步骤:
1.通过网页链接获取内容;
2.对获得的网页内容进行处理
这两个步骤需要分别使用不同的函数库:requests和beautifulsoup4。所以我们要安装这两个第三方库。
我所用的编辑器是 Pycharm,它带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成等。本次安装第三方库是在Pycharm下进行安装的。
Pychram安装第三方库:
安装第三方库有很多方法,我这里用的是Pycharm自带功能进行下载安装:(当然也可以用pip方法进行安装)
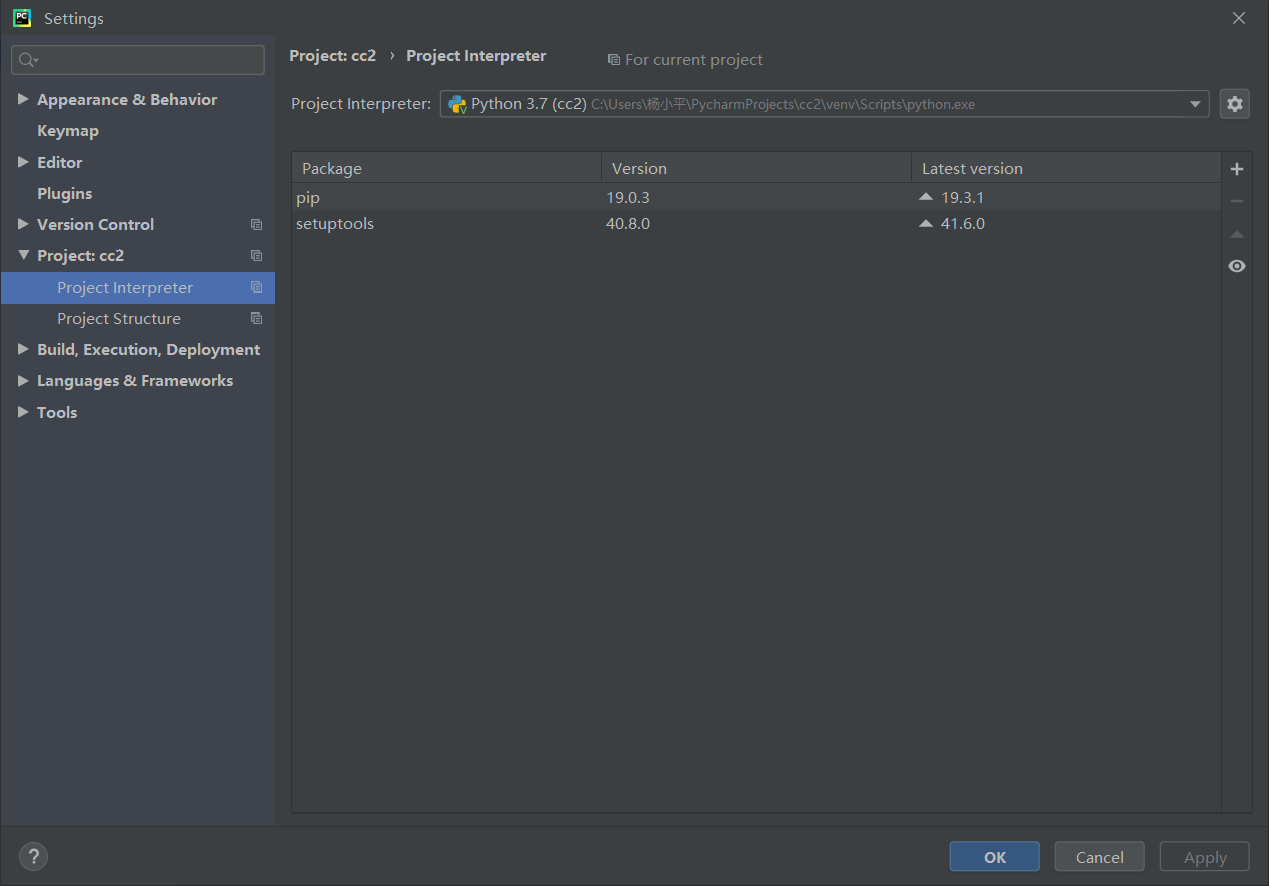
打开:File→Settings→Project: cc(这里的文件名是cc)→Project Interpreter ,就会显示你已经安装好的库。
这里我已经安装好了requests和beautifulsoup4库,所以下图显示出来了。
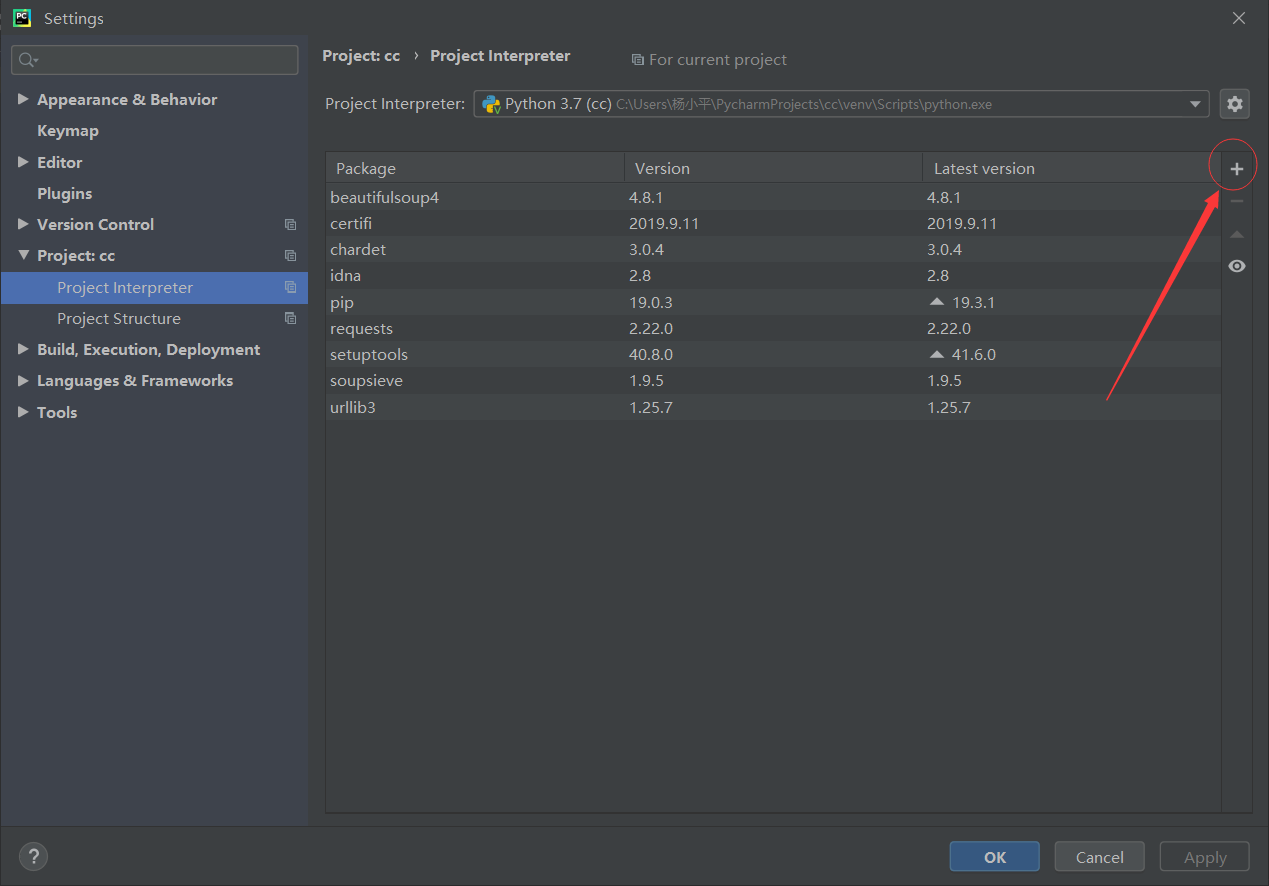
点击“+”,在弹出的搜索框中输入要安装第三方库的名称,例如“requests”。
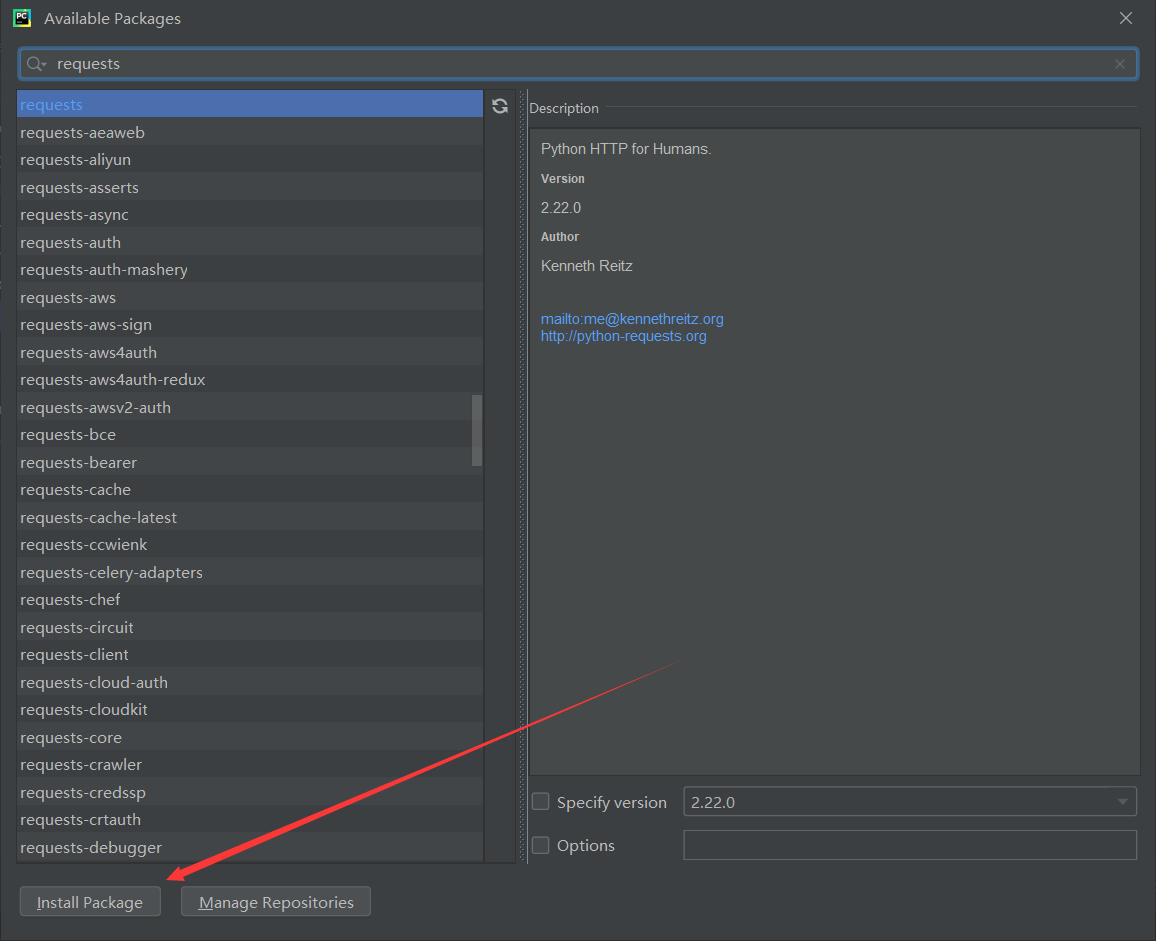
在弹出的选项中选中需要安装的库后,点击“Install Package”。待下载完成后就安装成功了。
同理,安装beautifulsoup4时,在搜索框里搜索“beautifulsoup4”,进行安装就可以了、
下面介绍一下第三方库:
requests库
requests库是一个简洁且简单的处理HTTP请求的第三方库,它的最大优点是程序编写过程更接近正常URL访问过程。这个库建立在Python语言的urllib3库的基础上,类似这种在其他函数库之上再封装功能、提供更友好函数的方式在Python 语言中十分常见。
requests库支持非常丰富的链接访问功能,包括国际域名和URL获取、HTTP长连接和连接缓存、HTTP会话和Cookie保持、浏览器使用风格的SSL验证、基本的摘要认证、有效的键值对Cookie记录、自动解压缩、自动内容解码、文件分块上传、HTTP(S)代理功能、连接超时处理、流数据下载等。
如何使用requests库?requests库提供了一些常用函数如下:
requests库中的网页请求函数
| 函数 | 描述 |
| get(url, [timeout=n]) | 对应于HTTP的GRT方式,获取网页最常用的方法,可以增加timeout=n参数,设定每次请求超时时间为n秒 |
| post(url,data={''key}:''value) | 对应于HTTP的DELETE方式 |
| delete(url) | 对应于HTTP的HEAD方式 |
| head(url) | 对应于HTTP的HEAD方式 |
| option(url) | 对应于HTTP的OPTION方式 |
| put(url,data={'key':'value'}) | 对应于HTTP的PUT方式,其中字典用于传递客户数据 |
一般运用这些函数的方法是requests.函数名(),不同的函数有不同的功能。
import requests
r=requests.get("http://www.baidu.com/")
r.encoding="utf-8" #编码方式为utf-8,不加的话会出现中文乱码
print(r.text)
代码运行结果为:
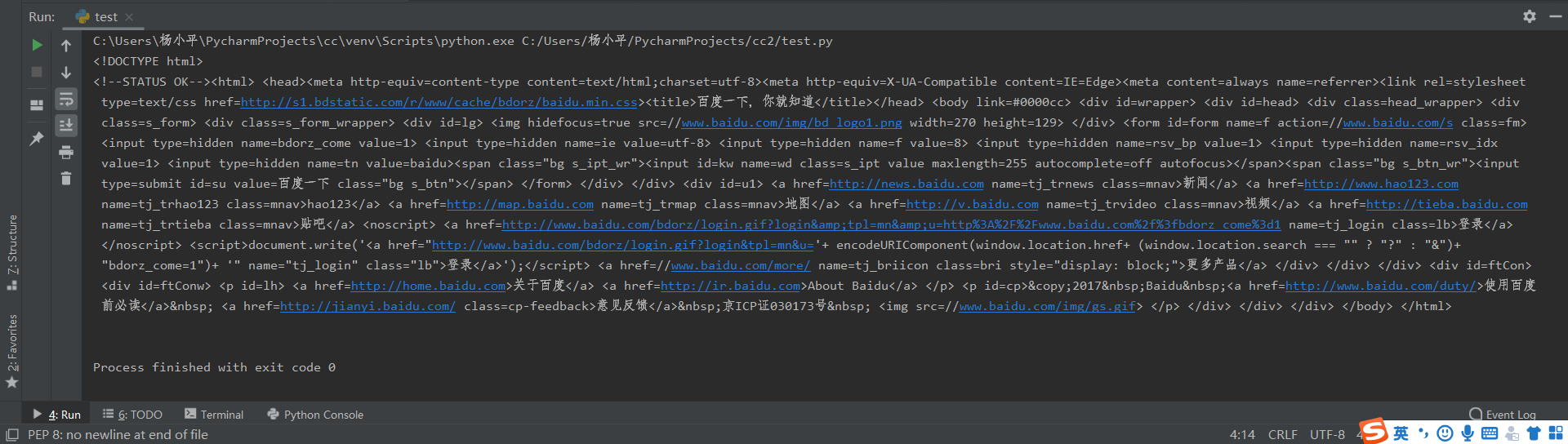
和浏览器的交互过程一样,用requests.get()代表请求,它返回的Response代表响应。返回的内容作为一个对象更便于操作,下面是Response对象的属性
Response对象的属性
| 属性 | 描述 |
| status_code | HTTP请求的返回状态,整数,200表示连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| encoding | HTTP响应内容的编码方式 |
| content | HTTP响应内容的二进制形式 |
import requests
r=requests.get("http://www.baidu.com/") print(r.status_code)
print(r.text)
print(r.encoding)
print(r.content)
运行结果如下,可以看到爬取网页的一系列信息。
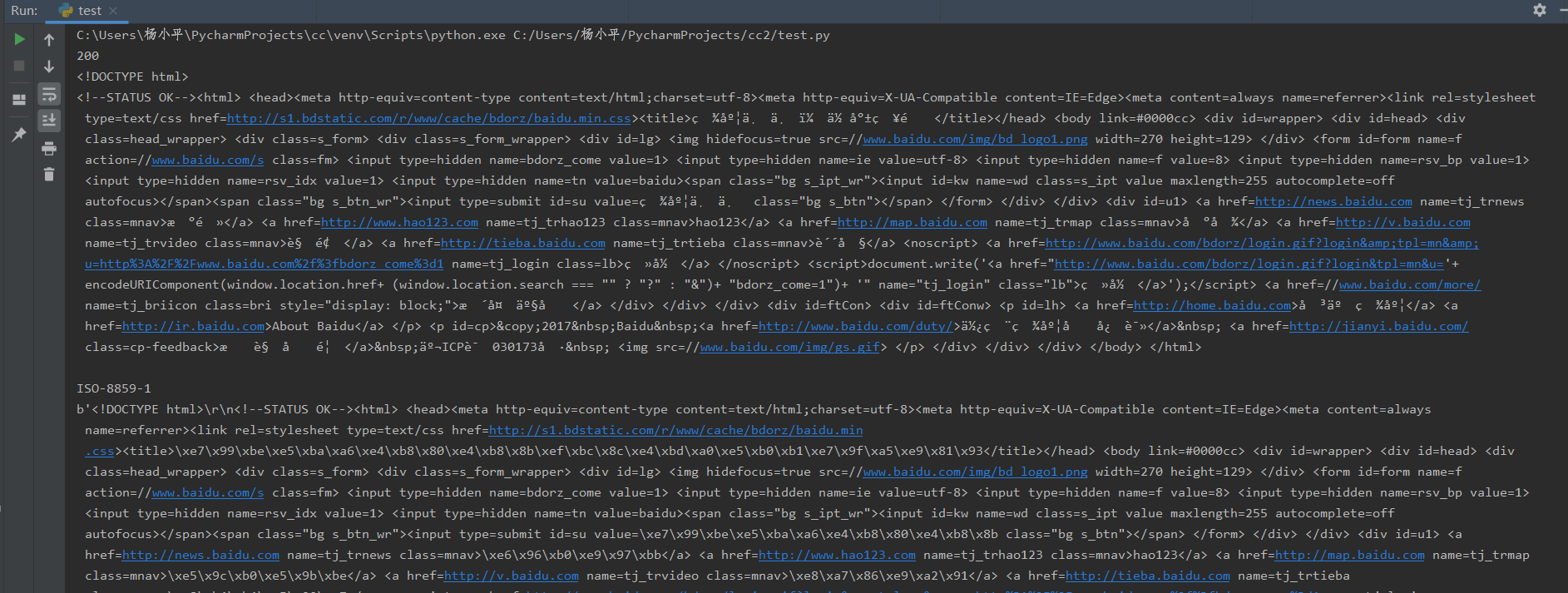
Response对象还有一些方法。
Response对象的方法
| 方法 | 描述 |
| json() | 如果HTTP响应内容包括JSON格式数据,则该方法解析JSON数据 |
| raise_for_status() | 如果不是200,则产生异常 |
使用requests 库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,提取有用信息,这需要处理HTML和XML的函数库。
beautifulsoup4库
beautifulsoup4库,也称为Beautiful Soup 库或bs4库,用于解析和处理HTML和XML。需要注意的是,它不是BeautifulSoup库。它的最大优点是能根据HTML和XML语法建立解析树,进而高效解析其中的内容。
HTML建立的Web页面一般非常复杂, 除了有用的内容信息外,还包括大量用于页面格式的元素,直接解析一个Web网页需要深入了解HTML语法,而且比较复杂。beautifulsoup4 库将专业的Web页面格式解析部分封装成函数,提供了若干有用且便捷的处理函数。
beautifulsoup4库采用面向对象思想实现,简单地说,它把每个页面当作一个对象,通过<a>.<b>的方式调用对象的属性(即包含的内容),或者通过<a>.<b>0的方式调用方法(即处理函数)。在使用beautifulsoup4库之前,需要进行引用,由于这个库的名字非常特殊且采用面向对象方式组织,可以用from-import方式从库中直接引用BeautifulSoup 类。
例如:
from bs4 import BeautifulSoup
HTML中主要结构都变成了BeautifulSoup对象的一个属性,可以通过<a>.<b>获得,下面是BeautifulSoup中常用的一些属性:
BeautifulSoup对象的常用属性
| 属性 | 描述 |
| head | HTML页面的<head>内容 |
| title | HTML页面标题,在<head>之中,由<title>标记 |
| body | HTML页面的<body>内容 |
| p | HTML页面中第一个<p>内容 |
| strings | HTML页面所有呈现在Web上的字符串,即标签上的内容 |
| stripped_strings | HTML页面所有呈现在Web上的非空格字符串 |
import requests
from bs4 import BeautifulSoup
r=requests.get("http://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text) print(soup.head)
print(soup.title)
print(soup.strings)
结果如下:

BeautifulSoup属性与HTML属性的标签名称相同。每一个Tag标签在beautifulsoup4库中也是一个对象,成为Tag对象。所以可以通过Tag对象的属性多的相应的内容,Tag对象的属性如下所示:
标签对象的常用属性
| 属性 | 描述 |
| name | 字符串,标签的名字,比如div |
| attrs | 字典,包含了原来页面Tag所有的属性,比如href |
| contents | 列表,这个Tag下所有子Tag的内容 |
| string | 字符串,Tag所包围的文本,网页中真实的文字 |
import requests
from bs4 import BeautifulSoup
r=requests.get("http://www.baidu.com/")
r.encoding="utf-8"
soup=BeautifulSoup(r.text) print(soup.a)
print(soup.a.string)
结果如下:

由于HTML语法可以在标签中嵌套其他标签,所以,string 属性的返回值遵循如下原则。
(1)如果标签内部没有其他标签,string 属性返回其中的内容。
(2)如果标签内部还有其他标签,但只有一个标签,string 属性返回最里面标签的内容。
(3)如果标签内部有超过1层嵌套的标签,string 属性返回None (空字符串)。HTML语法中同一个标签会有很多内容,例如<a>标签,百度首页一共有13处,直接调用soup.a只能返回第一个。
遇到的问题:
1.在Pycharm使用Python爬取网页时,爬取的网页源码显示在一行,网页源码没有换行。
例如:
import requests
r=requests.get("http://www.baidu.com/")
r.encoding="utf-8"
print(r.text)
运行上述代码,你会发现你爬取的网页源码显示在一行内。

解决办法:点击箭头所指的按钮,控制台就会自动换行了。

2.Pycharm在安装好第三方库时,在新建一个项目时,你会发现之前已经安装的第三方库不能使用。
新建一个项目,你会发现它没有之前安装的第三方库了
这时,你可以点击下拉框,再在下拉框中选择“show all”

这时,你可以找到上一个你已经安装好第三方库的项目,选中然后确认

再点击确定
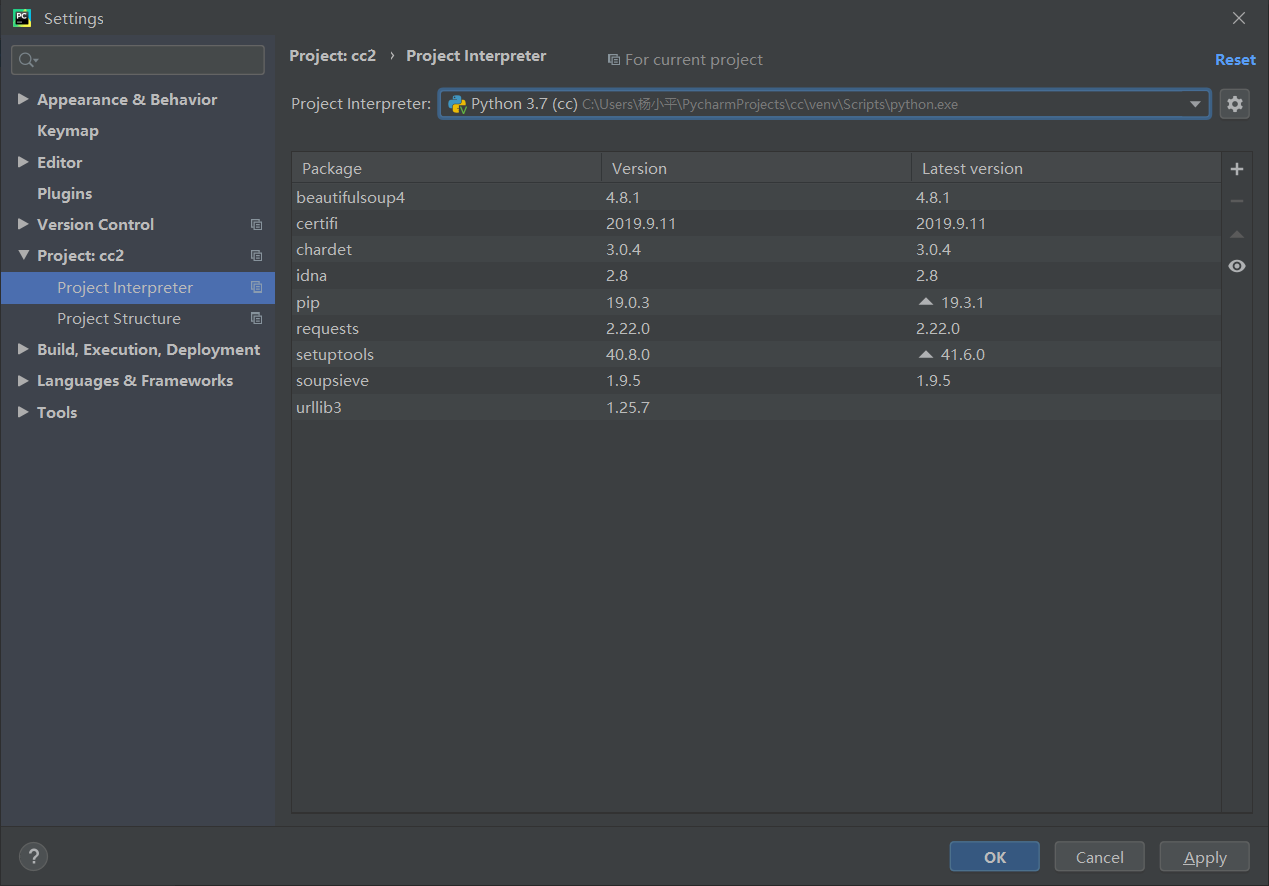
然后运行代码,你就会发现可以使用第三方库了

使用Pycharm写一个网络爬虫的更多相关文章
- 使用 Scrapy 构建一个网络爬虫
来自weixin 记得n年前项目需要一个灵活的爬虫工具,就组织了一个小团队用Java实现了一个爬虫框架,可以根据目标网站的结构.地址和需要的内容,做简单的配置开发,即可实现特定网站的爬虫功能.因为要考 ...
- 使用Scrapy构建一个网络爬虫
记得n年前项目需要一个灵活的爬虫工具,就组织了一个小团队用Java实现了一个爬虫框架,可以根据目标网站的结构.地址和需要的内容,做简单的配置开发,即可实现特定网站的爬虫功能.因为要考虑到各种特殊情形, ...
- Python之小测试:用正则表达式写一个小爬虫用于保存贴吧里的所有图片
很简单的两步: 1.获取网页源代码 2.利用正则表达式提取出图片地址 3.下载 #!/usr/bin/python #coding=utf8 import re # 正则表达式 import urll ...
- WebLogic写的网络爬虫
一.前言 最近因为有爬一些招聘网站的招聘信息的需要,而我之前也只是知道有"网络爬虫"这个神奇的名词,具体是什么.用什么实现.什么原理.如何实现比较好都不清楚,因此最近大致研究了一下 ...
- 爬虫入门 手写一个Java爬虫
本文内容 涞源于 罗刚 老师的 书籍 << 自己动手写网络爬虫一书 >> ; 本文将介绍 1: 网络爬虫的是做什么的? 2: 手动写一个简单的网络爬虫; 1: 网络爬虫是做 ...
- WebMagic写的网络爬虫
一.前言 最近因为有爬一些招聘网站的招聘信息的需要,而我之前也只是知道有“网络爬虫”这个神奇的名词,具体是什么.用什么实现.什么原理.如何实现比较好都不清楚,因此最近大致研究了一下,当然,研究的并不是 ...
- Python 网络爬虫 004 (编程) 如何编写一个网络爬虫,来下载(或叫:爬取)一个站点里的所有网页
爬取目标站点里所有的网页 使用的系统:Windows 10 64位 Python语言版本:Python 3.5.0 V 使用的编程Python的集成开发环境:PyCharm 2016 04 一 . 首 ...
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
- 用Python写一个小爬虫吧!
学习了一段时间的web前端,感觉有点看不清前进的方向,于是就写了一个小爬虫,爬了51job上前端相关的岗位,看看招聘方对技术方面的需求,再有针对性的学习. 我在此之前接触过Python,也写过一些小脚 ...
随机推荐
- com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=404, reply-text=NOT_FOUND - no queue 'springCloudBus.anonymous.6Xa99MDZTJyHKdPqMyoVEA' in
项目启动报此异常,解决方式:用root权限登陆rabbitmq,admin处添加vhost
- SpringCloud学习笔记(二):微服务概述、微服务和微服务架构、微服务优缺点、微服务技术栈有哪些、SpringCloud是什么
从技术维度理解: 微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底 地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事, 从技术角度看就是一种小而独立的处理过程,类 ...
- centos7 yum 安装tomcat7
查看yum中tomcat信息 yum info tomcat 安装 yum install tomcat 安装管理界面 yum install tomcat-webapps tomcat-admin- ...
- <随便写>佛祖,哈哈!
print(" _ooOoo_ ") print(" o8888888o ") print(" 88 . 88 ") print(" ...
- 从0开始学习ssh之岗位管理
岗位应该有如下属性,id.名称.说明.新建role.java.添加id,name,description并增加三个的get set方法. 之后建立Role.hbm.xml 并加入到applicatio ...
- 如何转移Pycharm的设置或者缓存到其他盘
因为Pycharm项目缓存C:\Users\wq\.PyCharm2017.2\system\caches下面的content.dat.storageData特别大,占用很多C盘空间,所以我就想办法, ...
- mysql批量增加表中新列存储过程
一般访问量比较大的网站,请求日志表都是每天一张表独立创建. 业务需要为每张表都添加一个新列,纠结了半天,写了个存储过程如下: 日志表结构类型 tbl_ads_req_20140801, tbl_ads ...
- mysql5.7基于gtid进行搭建主从复制过程
gtid_mode = onenforce-gtid-consistency = onskip_name_resolve # 去掉域名解析二进制日志必须开启,且格式为ROWserver-id必须配置成 ...
- 搭建nodejs代理服务器,从而解决跨域问题
先在同级处新建js文件(app.js) 使用时npm 安装 Node.js 模块语法 也就是对应的文件所在地“npm install”一下 然后安装对应需要的模块: expresspathreques ...
- 19-10-25-G-悲伤
此题未通过 [ 老帅哥 ] 认证. ZJ一下: T1,明显是二分答案+$dij/SPFA$ T2,没看懂题. T3,打了一个$\Theta(N^2)$暴力. 事实上…… T1,T2死了. T1中 每次 ...