程序员眼中的 SQL Server-非聚集索引能给我们带来什么?
写在前面
最近在做的一个项目,页面访问的时候很慢(大概几秒钟的样子),然后用日志记录的方式,来排查这个问题,最后发现是 Entity Framework 初始化的一个坑(大概要花 6-7 秒),详见:《来,给Entity Framework热热身》,但是除了这个问题,还发现当一些用户数据量很大的时候,访问也是有些慢,这个就不是 Entity Framework 的问题了(因为初始化已完成),用 Sql Server Profiler 来跟踪页面访问的时 SQL 的执行情况,因为应用程序很简单,页面加载的时候,跟踪检测到三个 SQL 执行,看了下也没什么问题(两个获取数量,一个获取列表),数量获取的 SQL,这个应该执行会很快,所以把分析焦点放在了那个获取列表的 SQL 上,因为 SQL 没什么问题,那应该是关于这条 SQL 建的索引有问题。注:上面所说项目中大概有 100 万的数据。
关于数据库中的索引概念,记得在很早之前整理了一篇博文《T-Sql(八)字段索引和数据加密》,现在来看,写的真是一坨屎,概念讲的再多没个毛用,关键在于对实际应用中产生问题的分析。在研究这个问题之前,搜了一些相关资料,主要来自园中的几位 SQL Server 大神(CareySon、桦仔、听风吹雨等),稍微看了下,关于索引,主要是一些数据库专业术语,看的不是很明白,作为程序员,我们知道索引分为聚集性索引和非聚集性索引,聚集性索引一般为主键(也可以不是),在创建表的时候会自动创建,针对上面我那个应用查询问题,查询条件是一些非主键字段,所以这边探讨下非聚集性索引。
我不会说一些数据库概念,所以只能用做一些实践来理解概念的意义,以下应用场景中的用例是虚拟出来的,只是作为个人研究使用。
程序员应该有刨根问底的怪癖,虽然这是个数据库问题。
应用场景
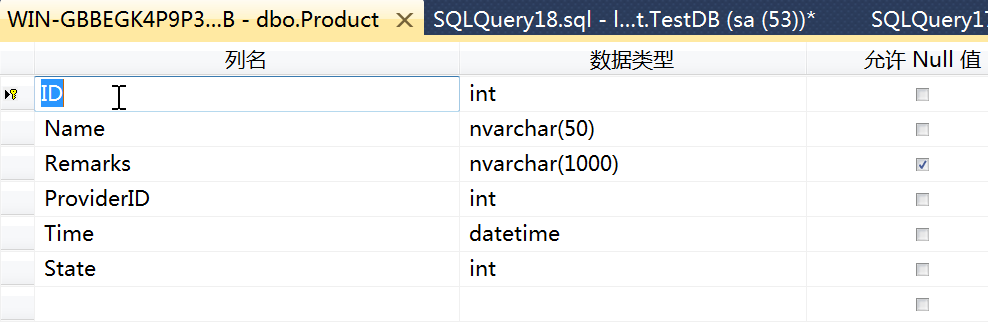
有一个 Product 表,字段如下:
数据添加脚本:
begin tran
declare @index int
set @index=0
while(@index<1000000)
begin
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题1','我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1我是测试备注1',1,GETDATE(),0)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题2','我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2我是测试备注2',1,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题3','我是测试备注3',3,GETDATE(),1)
insert into [dbo].[Product]([Name],Remarks,ProviderID,[Time],[State])
values('我是测试标题4','我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4我是测试备注4',4,GETDATE(),1)
set @index=@index+1
end
commit
Product 表中插入了四百万的数据,为了接近我们现实生产环境,所以对数据进行了不同插入。
一般应用环境查询,有时候我们会针对一个字段进行 where 查询,有时候也会 and 另一个字段进行查询,这个时候,关于这两个字段的索引怎么建?还是不需要建?是分别建两个?还是建一个组合的?其实说真的,可能看到这的数据库大神会莞尔一笑,但是作为程序员,这些我真不知道,搜索的资料中也并没有对这些鸡毛蒜皮进行的说明,没办法,只能自己瞎折腾下。我们下面要做是 ProviderID 和 State 的查询操作,有分别查询,也有组合查询,然后我们再对 Product 表建立这两个字段的索引,看看有什么不同之处?还有就是针对不同的索引方式,查询又会有什么不同?我们睁大眼睛来看一下。
问题分析
我再对上面的分析进行说明下,首先,查询主要为2种:
- where ProviderID=?
- where ProviderID=? and State=?
非聚集性索引的创建主要为3种:
- 不创建索引
- ProviderID 字段索引
- ProviderID 和 State 字段索引
针对这个应用场景和上面的分析,会得出 3*2 六种结果,其实我最想知道的是下面的第三种,即创建一个组合字段索引,对单个字段的查询会不会有影响?还有就是反过来,单个字段的索引创建,对组合字段查询会不会有影响?当然试过了才知道,看一下执行结果。
执行结果
测试脚本:
declare @begin_date datetime
declare @end_date datetime
select @begin_date = getdate()
select * from [dbo].[Product] where ...
select @end_date = getdate()
select datediff(ms,@begin_date,@end_date) as '用时/毫秒'
为了接近测试结果,每次语句执行三次,然后再取平均值,截图太麻烦了,这边就直接贴下执行结果。
不创建索引
where ProviderID=1(二百万数据)
执行结果:13806毫秒,13380毫秒,12730毫秒
平均结果:13305毫秒where ProviderID=1 and State=1(一百万数据)
执行结果:6556毫秒,6613毫秒,6706毫秒
平均结果:6625毫秒
创建索引字段 ProviderID
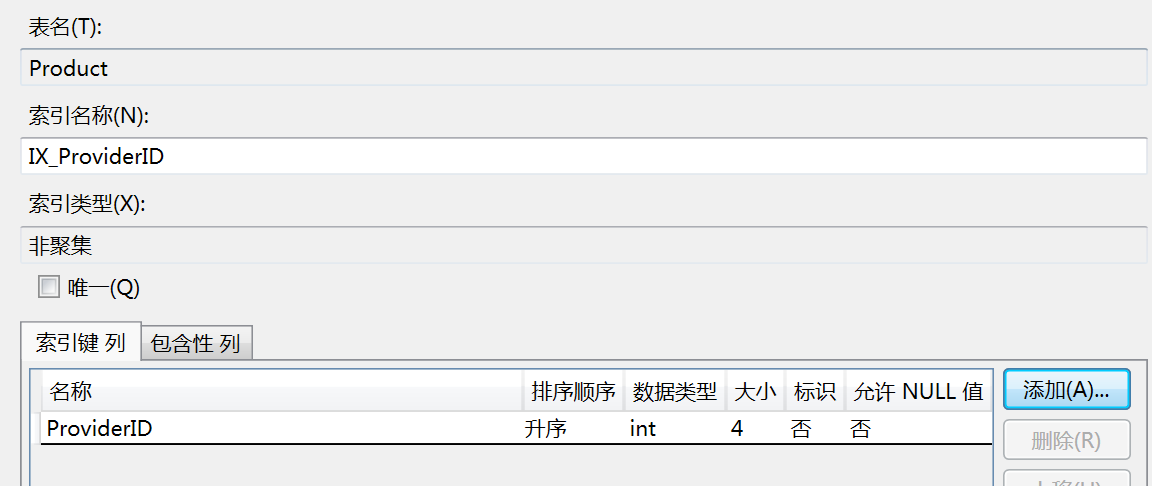
where ProviderID=1
执行结果:13986毫秒,13810毫秒,15853毫秒
平均结果:14549毫秒where ProviderID=1 and State=1
执行结果:7153毫秒,7190毫秒,13950毫秒
平均结果:7122毫秒
创建索引字段 ProviderID 和 State
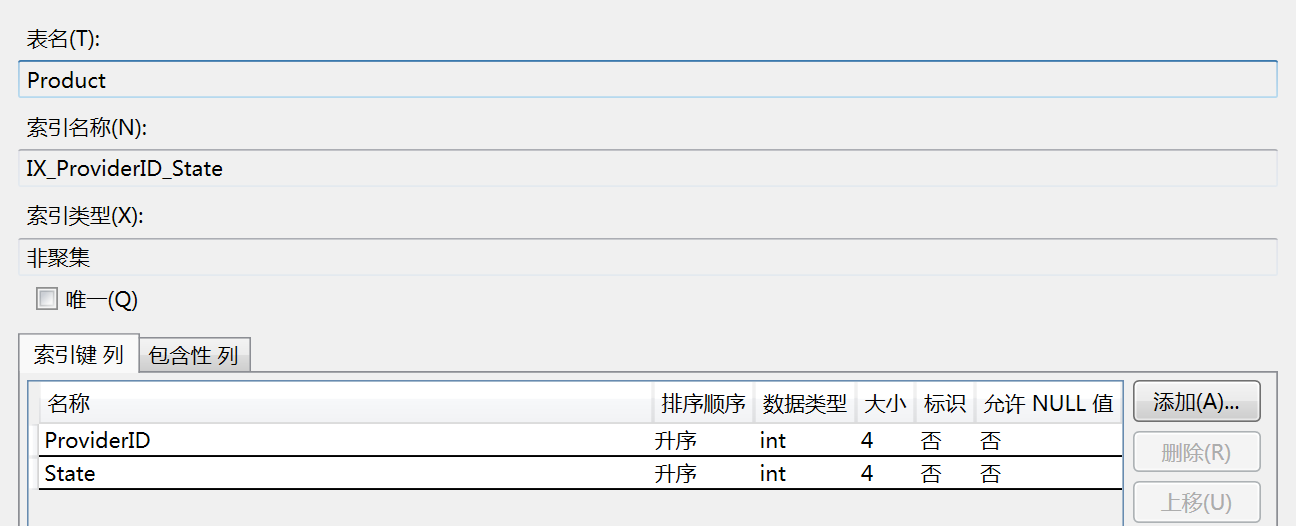
where ProviderID=1
执行结果:13840毫秒,14163毫秒,15853毫秒
平均结果:14618毫秒where ProviderID=1 and State=1
执行结果:7033毫秒,7220毫秒,7023毫秒
平均结果:7152毫秒
结果分析

虽然测试的有些不完整,但是看到结果,哥有些凌乱了(建了索引,性能反而会降低?),难道是我插入的数据有问题?还是创建索引有问题?还是我人品有问题???坐等数据库大神指教。。。
程序员眼中的 SQL Server-非聚集索引能给我们带来什么?的更多相关文章
- 程序员眼中的 SQL Server-执行计划教会我如何创建索引?
先说点废话 以前有 DBA 在身边的时候,从来不曾考虑过数据库性能的问题,但是,当一个应用程序从头到脚都由自己完成,而且数据库面对的是接近百万的数据,看着一个页面加载速度像乌龟一样,自己心里真是有种挫 ...
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- SQL Server 非聚集索引的覆盖,连接,交叉和过滤 <第二篇>
在SQL Server中,非聚集索引其实可以看做是一个含有聚集索引的表,但相对实际的表来说,非聚集索引中所存储的表的列数要少得多,一般就是索引列,聚集键(或RID).非聚集索引仅仅包含源表中的非聚集索 ...
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- 但从谈论性能点SQL Server选择聚集索引键
简单介绍 在SQL Server中,数据是按页进行存放的.而为表加上聚集索引后,SQL Server对于数据的查找就是依照聚集索引的列作为keyword进行了. 因此对于聚集索引的选择对性能的影响就变 ...
- 探究SQL添加非聚集索引,性能提高几十倍之谜
上周,技术支持反映:客户的一个查询操作需要耗时6.1min左右,在跟进代码后,简化了数据库的查询后仍然收效甚微.后来,技术总监分析了sql后,给其中的一个表添加的一个非聚集索引(三个字段)后,同样的查 ...
- SQL SERVER中非聚集索引的覆盖,连接,交叉,过滤
1.覆盖索引:select和where中包含的结果集中应存在“非聚集索引列”,这样就不用查找基表了,索引表即可搞定: 2.索引交叉:索引的交叉可以理解成建立多个非聚集索引之间的join,如表实体一 ...
- 图解SQL Server:聚集索引、唯一索引、主键
http://www.cnblogs.com/chenxizhang/archive/2010/01/14/1648042.html
随机推荐
- java基础3_循环语句,数组
java中的循环: Java中提供了3中循环结构: while do-while for ① 循环结构的作用? 可以不断重复执行循环结构中的代码: ② 上面的3个循环结构功能都是一样的,只是结构 ...
- javascript array sort()
[5,10,1].sort(); 结果[1,10,5] 有点出人意料. array.sort( sortFunction )可选-指定如何比较元素顺序的函数名称 如果省略sortFunction参数, ...
- Ubuntu 14.04--php的安装和配置
更新源列表 打开"终端窗口",输入"sudo apt-get update"-->回车-->"输入root用户的密码"--& ...
- canvas初探1
刚申请的博客,当然这也是第一篇.对于canvas也是刚开始着手进行学习,有哪些不对的地方,还望看到本篇博文的朋友指正. 1.canvas的历史 首先,它是HTML5的一个标签. 它是为了客户端矢量图形 ...
- SDOI 2016 游戏
树链剖分 线段树维护区间最小值,区间最大值 更新,对于每一个区间,找到当前区间的最小值的最大值,和要更新的值比较,如果比最大值还大,则此数对于以后的询问无任何贡献,直接返回即可,若有贡献,则一直递归到 ...
- androidannotations 简单复制与点击事件(1)
现在最火的android开发框架 简单描述一下 这一篇简单描述寻找控件以及事件的使用 1.该方法可以不用写setconteview @EActivity(R.layout.activity_main) ...
- Mono 3.2 测试NPinyin 中文转换拼音代码
C#中文转换为拼音NPinyin代码 在Mono 3.2下运行正常,Spacebuilder 有使用到NPinyin组件,代码兼容性没有问题. using System; using System. ...
- 常用SQL[ORACLE]
1.常用系统函数 2.常用sql语句 3.一些定义和关键字 4.需要注意点 1.常用系统函数 ↑ --decode decode(column,if_value,value,elseif_ ...
- 让浏览器不再显示 https 页面中的 http 请求警报
HTTPS 是 HTTP over Secure Socket Layer,以安全为目标的 HTTP 通道,所以在 HTTPS 承载的页面上不允许出现 http 请求,一旦出现就是提示或报错: Mix ...
- 企业IT管理员IE11升级指南【4】—— IE企业模式介绍
企业IT管理员IE11升级指南 系列: [1]—— Internet Explorer 11增强保护模式 (EPM) 介绍 [2]—— Internet Explorer 11 对Adobe Flas ...