Windows下mnist数据集caffemodel分类模型训练及测试
1. MNIST数据集介绍
MNIST是一个手写数字数据库,样本收集的是美国中学生手写样本,比较符合实际情况,大体上样本是这样的:

MNIST数据库有以下特性:
- 包含了60000个训练样本集和10000个测试样本集;
- 分4部分,分别是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集,每个标签的值是0~9之间的数字;
- 原始图像归一化大小为28*28,以二进制形式保存
2. Windows+caffe框架下MNIST数据集caffemodel分类模型训练及测试
1. 下载mnist数据
2. 将MNIST数据集转换为lmdb数据文件
- 它们都是键/值对嵌入式数据库管理系统编程库
- 虽然lmdb的内存消耗是leveldb的1.1倍,但是lmdb的处理速度比leveldb快10%到15%,另外lmdb允许多种训练模型同时读取同一组数据集。
- lmdb取代了leveldb成为了caffe默认的数据集生成格式。
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte .\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte .\examples\mnist\mnist_train_lmdb
echo.
.\Build\x64\Debug\convert_mnist_data.exe .\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte .\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte .\examples\mnist\mnist_test_lmdb
pause 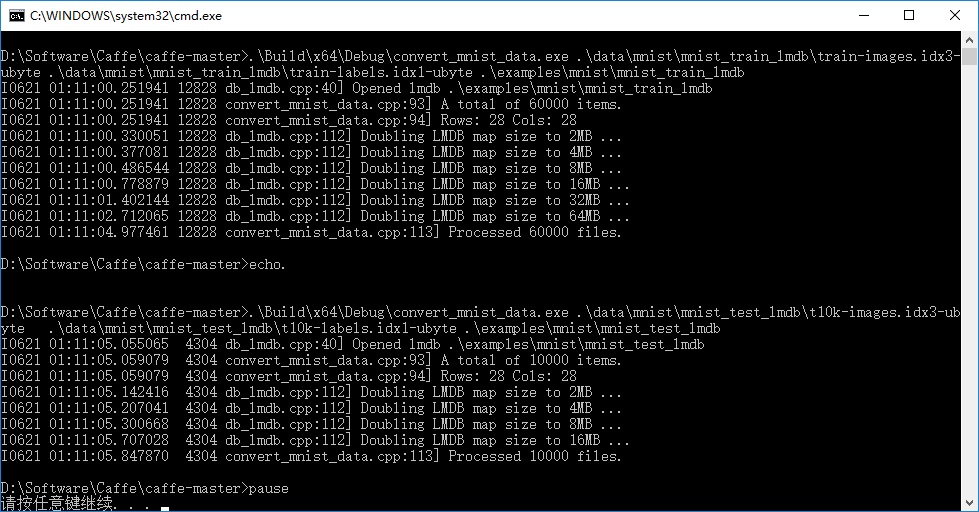
3. 计算数据库的均值文件
.\Build\x64\Debug\compute_image_mean.exe .\examples\mnist\mnist_train_lmdb .\examples\mnist\mean.binaryproto
pause 双击运行,执行结果:
4. lenet训练参数设置
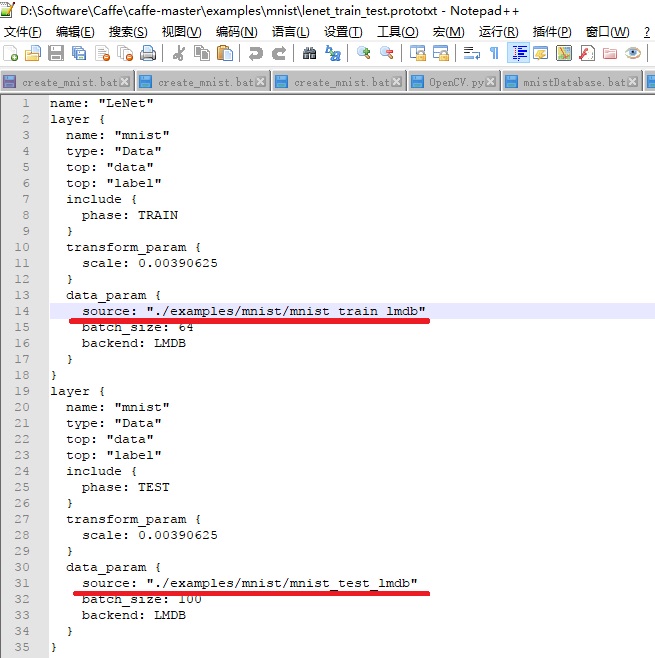
设置lmdb文件路径
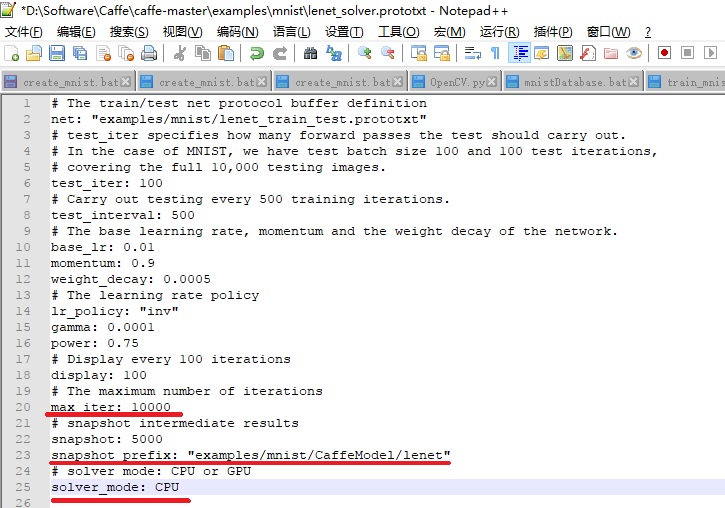
设置lenet训练参数
- GPU or CPU: caffe中lenet的训练参数默认是使用GPU,这里修改为CPU;
- 最大迭代次数: 最大迭代次数默认是10000,一般情况下最大迭代次数越大,训练的模型越准确,训练耗时也越长,这里max_iter的值10000不做修改。
- caffemodel生成路径:训练完成之后会生成caffemodel分类模型,默认生成路径是在mnist根目录,这里修改为mnist目录下的CaffeModel文件夹内,snapshot_prefix: "examples/mnist/CaffeModel/lenet";
5. 执行lenet模型训练,生成caffemodel
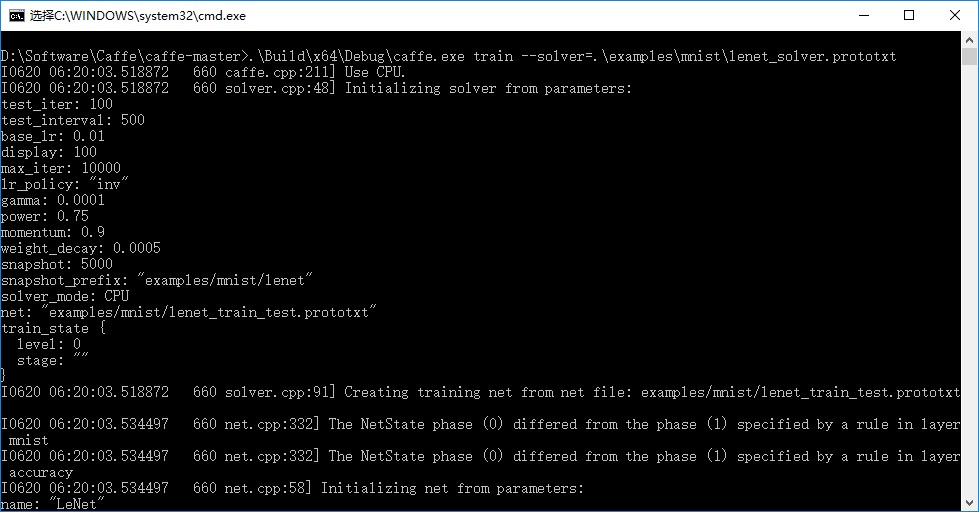
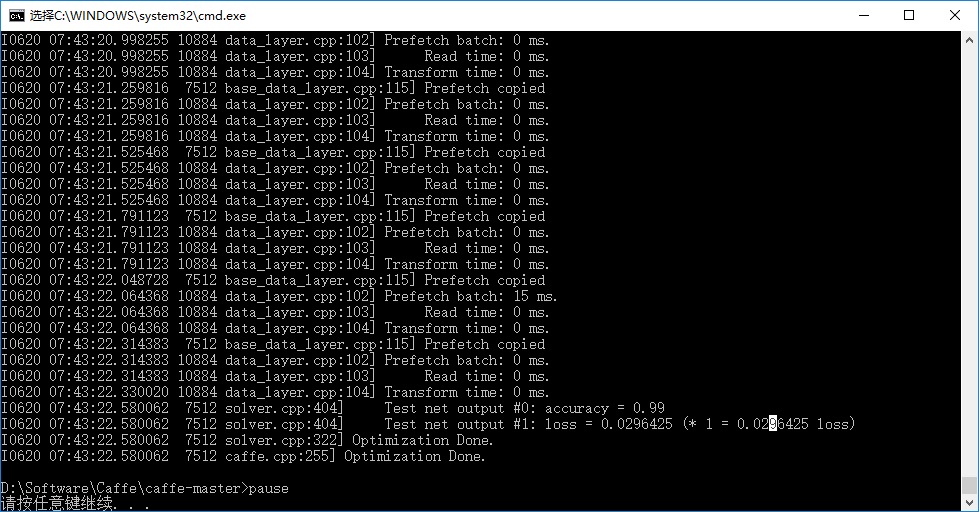
.\Build\x64\Debug\caffe.exe train --solver=examples/mnist/lenet_solver.prototxt
pause双击运行,开始训练:
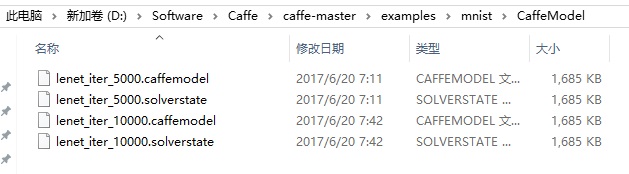
- lenet_iter_10000.caffemodel 和 lenet_iter_5000.caffemodel: 这两个文件是最终生成的caffemodel分类模型;
- lenet_iter_10000.solverstate 和 lenet_iter_5000.solverstate : 这两个文件是记录当前训练状态信息文件。在跑训练模型的时候遇到断电等异常情况导致训练中断,再次训练的时候就不必浪费时间从头开始训练,只需要调用 .solverstate文件,从上次训练中断的位置处继续训练即可,具体使用方法略过。
6. 使用caffemodel测试一下mnist测试数据集的分类准确率
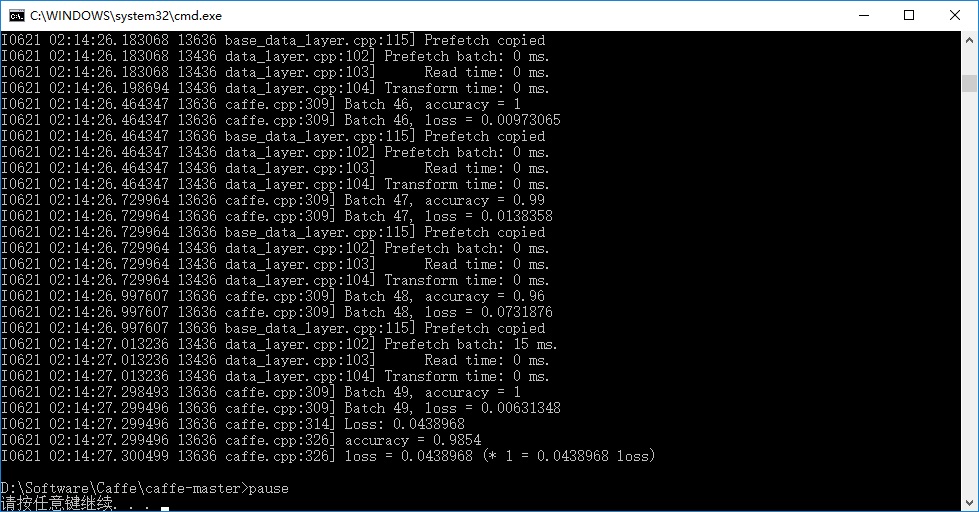
.\Build\x64\Debug\caffe.exe test --model=.\examples\mnist\lenet_train_test.prototxt -weights=.\examples\mnist\CaffeModel\lenet_iter_10000.caffemodel
pause 程序会根据lenet_train_test.prototxt文件里设置的测试数据集的路径自动加载到测试数据,双击运行,完成之后得到测试数据集的识别准确率,约为98.5%:
Windows下mnist数据集caffemodel分类模型训练及测试的更多相关文章
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- TensorFlow 下 mnist 数据集的操作及可视化
from tensorflow.examples.tutorials.mnist import input_data 首先需要连网下载数据集: mnsit = input_data.read_data ...
- 关于 Poco::TCPServer框架 (windows 下使用的是 select模型) 学习笔记.
说明 为何要写这篇文章 ,之前看过阿二的梦想船的<Poco::TCPServer框架解析> http://www.cppblog.com/richbirdandy/archive/2010 ...
- 比较windows下的5种IO模型
看到一个很有意思的解释: 老陈有一个在外地工作的女儿,不能经常回来,老陈和她通过信件联系.他们的信会被邮递员投递到他们的信箱里. 这和Socket模型非常类似.下面我就以老陈接收信件为例讲解Socke ...
- fcn模型训练及测试
1.模型下载 1)下载新版caffe: https://github.com/BVLC/caffe 2)下载fcn代码: https://github.com/shelhamer/fcn.berkel ...
- Ubuntu16.04下caffe CPU版的图片训练和测试
一 数据准备 二.转换为lmdb格式 1.首先,在examples下面创建一个myfile的文件夹,来用存放配置文件和脚本文件.然后编写一个脚本create_filelist.sh,用来生成train ...
- windows下php7.1安装redis扩展以及redis测试使用全过程
最近做项目,需要用到redis相关知识.在Linux下,redis扩展安装起来很容易,但windows下还是会出问题的.因此,特此记下自己实践安装的整个过程,以方便后来人. 一,php中redis扩展 ...
- windows下php7.1安装redis扩展以及redis测试使用全过程(转)
最近做项目,需要用到redis相关知识.在Linux下,redis扩展安装起来很容易,但windows下还是会出问题的.因此,特此记下自己实践安装的整个过程,以方便后来人. 一,php中redis扩展 ...
- Tensorflow学习教程------利用卷积神经网络对mnist数据集进行分类_利用训练好的模型进行分类
#coding:utf-8 import tensorflow as tf from PIL import Image,ImageFilter from tensorflow.examples.tut ...
随机推荐
- HDU 4307 Contest 1
http://www.cnblogs.com/staginner/archive/2012/08/13/2636826.html 自己看过后两周吧,重新写了一遍.很受启发的.对于0.1,可以使用最小割 ...
- atitit。流程图的设计与制作 attilax 总结
atitit.流程图的设计与制作 attilax 总结 1. 流程图的规范1 2. 画图语言2 2.1. atitit.CSDN-markdown编辑器2 2.2. js-sequence-diagr ...
- JavaScript 没有函数重载&Arguments对象
对于学过Java的人来说.函数重载并非一个陌生的概念,可是javaScript中有函数重载么...接下来我们就进行測试 <script type="text/javascript&qu ...
- Educational Codeforces Round 6 A. Professor GukiZ's Robot 水
A. Professor GukiZ's Robot Professor GukiZ makes a new robot. The robot are in the point with coor ...
- bzoj3173: [Tjoi2013]最长上升子序列(树状数组+二分倒推)
3173: [Tjoi2013]最长上升子序列 题目:传送门 题解: 好题! 怎么说吧...是应该扇死自己...看错了两次题: 每次加一个数的时候,如果当前位置有数了,是要加到那个数的前面,而不是直 ...
- apiCloud中Frame框的操作,显示与隐藏Frame
Frame是一层一层的概念, 有的位于上层,有的位于下层. 1.加载菜单 2.加载页面层 3.首页拆分出内容层,这个时候内容层位于页面层的上方,当点击其他页面的时候,内容层遮挡住了他们 解决方案一 判 ...
- sublime配置python运行环境
1.sublime下载与插件管理 1.1 下载 官网地址:https://www.sublimetext.com/3 1.2 安装Package Control管理插件 使用ctrl + ` (感叹后 ...
- UISrcoll控件简单介绍
UISrcoll控件,简单的说就是让界面滑动 当使用uiimageview的时候,给控件设置图片素材时,图片的大小会根据控件的大小,自动做缩放 当使用uibutton的时候,如果是设置背景图,name ...
- DISM
C:\WINDOWS\system32>DISM /Online /Cleanup-image /RestoreHealth 部署映像服务和管理工具版本: 10.0.16193.1001 映像版 ...
- HTTP的请求及响应
前言 本文主要包括以下内容: HTTP是什么? HTTP 请求包括哪些部分? HTTP 响应包括哪些部分? 如何用Chrome开发者工具查看 HTTP 请求及请求的内容? 如何使用 curl 命令? ...