Kaggle实战分类问题2
Kaggle实战之二分类问题
0. 前言
- “尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题。”
- 本系列参考书 "Hands-on machine learning with scikit-learn and tensorflow"以及kaggle相关资料
1. MNIST 数据集
MNIST是最常用的用来实验分类模型的数据集,有7w多张手写0-9的白底黑字数字图像,每张图像大小 28*28,共784个像素,像素取值范围为[0-255],0表示白色背景,255表示纯黑,如下图:

2. 二分类器
数字识别是个多分类问题,首先我们从两分类问题开始入手,即判断一张图片是5或者非5。应用sklearn线性模型的SGDClassifier直接训练,损失函数默认是 hinge loss,即SVM分类器,如果想用logistic regression来分类,可以选用 log loss。SGDClassifier 分类器还支持不同的损失函数,如 perceptron等,这里就不一一列举了。由于SGD分类器对训练样本的顺序是敏感的,所以在模型训练之前需要shuffle训练集。
用SVM训练结束后,用模型预测得到测试集的预测结果,评估准确率(accuracy)大概是96%,看起来是一个不错的结果,但是如果我们把所有的测试样本都判定为非5,准确率也能有90%(十分之九都是对的)。看来光凭准确率,在这种情况下不能说明我们模型学习得很好,看来如何评价模型的学习能力不是件那么简单的事情。
“观察到的一个有意思的细节:一些喜好机器学习或者数据科学的初学工程师和有机器学习或者数据科学背景的科学家,在工作上的主要区别在于如何对待负面的实验(包括线下和线上)结果。初学者往往就开始琢磨如何改模型,加Feature,调参数;思考如何从简单模型转换到复杂模型。有经验的人往往更加去了解实验的设置有没有问题;实验的Metrics的Comparison是到底怎么计算的;到真需要去思考模型的问题的时候,有经验的人往往会先反思训练数据的收集情况,测试数据和测试评测的真实度问题。初学者有点类似程咬金的三板斧,有那么几个技能,用完了,要是还没有效果,也就完了。而有经验的数据科学家,往往是从问题出发,去看是不是对问题本质的把握(比如优化的目标是不是对;有没有Counterfactual的情况)出现了偏差,最后再讨论模型。”
—— by @洪亮劼
3. 效果评测
从源头出发,如下图,x、o分别表示label为负和正的样本,划分为上下两列,假设模型预测值是一个连续值(如为正的概率),把正负样本按照预测值从低到高分别排列好。一个好的模型,应该是左上角分布较密集,表示很多负样本预测值较小,右下角分布也很密集,表示为模型预测正样本的概率值普遍偏高。当然,一般模型也无法做到百分之百的分类准确,所以存在少量的负样本预测概率较高,正样本预测概率偏低,如图右上角和左下角。
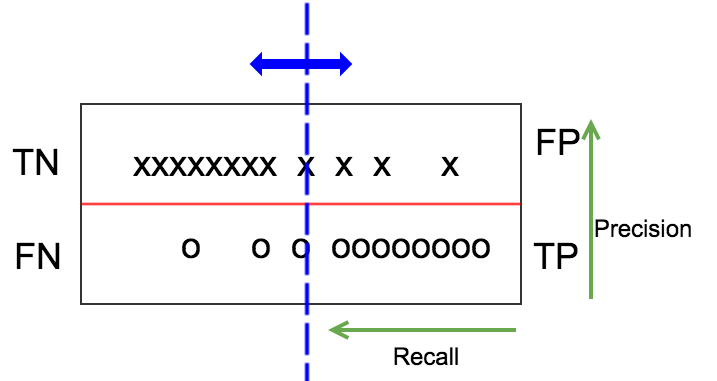
Confusion Matrix
我们设定一个阈值,用图中蓝色的竖线表示,高于阈值的模型预测为正样本,反之则为负样本。这个阈值是我们可以自行设定的,蓝色的竖线可以左右移动。红色的横线和蓝色的竖线将整个测试集数据分成四个部分,TN(True Positive)、FP(False Positive)、FN(False Negative)、TP(True Positive)。TPR(TP rate)即recall= TP/(TP+FN),precision=TP/(TP+FP)。上面我们计算accuracy实际上是 (TN+TP)/ALL,对于一个测试集来说,底下分母是不变的,如果TN对比TP很大,TP的变动很难通过accuracy反映出来。一个好的分类器,应该TP包含大部分圆圈,FP和FN几乎为空,所以很多比赛的评测指标是precision和recall的harmonic平均值,即:
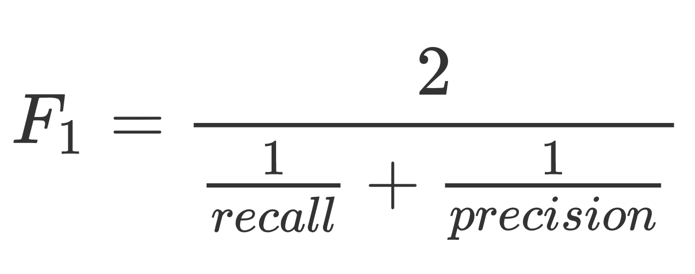
harmonic平均比直接除以2更看重较小的那个值,只有两个值都比较大,整体才会大。
PR曲线和ROC曲线
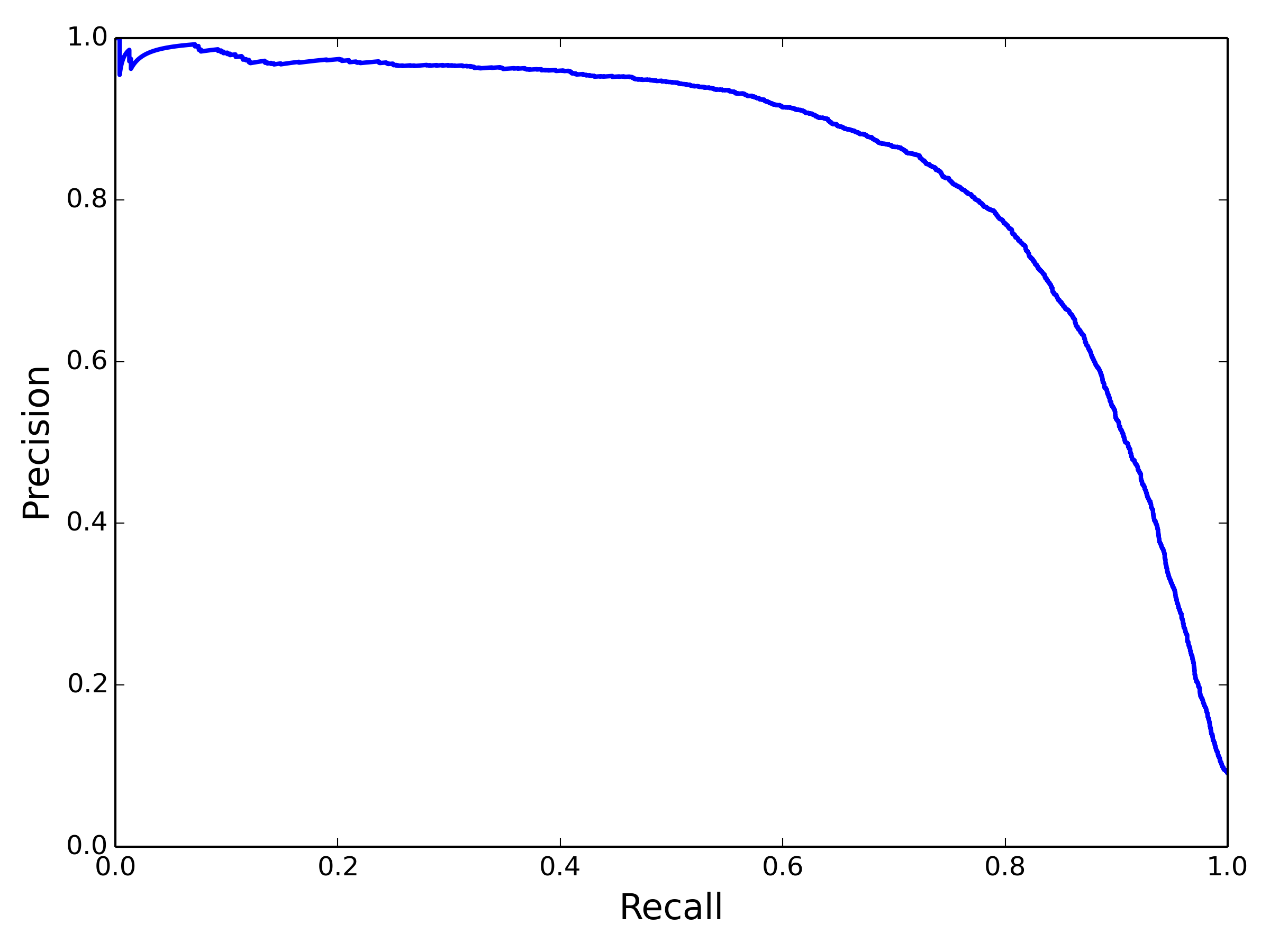
为了得到较好的F1,需要调节适当的阈值。蓝色的线从最左往右滑动时,recall= TP/(TP+FN),分母不变,分子逐渐变小,从1单调递减到0。precision=TP/(TP+FP),分子和分母同时变小,总体上,TP变小的速度慢很多,大体上是递增的,但是并不绝对单调,尤其在靠近右侧。经常可以看到TP-1,FP不变,则precision反而变小:

关于Recall和Precision的tradeoff,还可以画一条PR 曲线:
ROC曲线是另外一种衡量二分类模型的方法,y轴是recall=TP/(TP+FN),x轴是FPR=FP/(FP+TN):
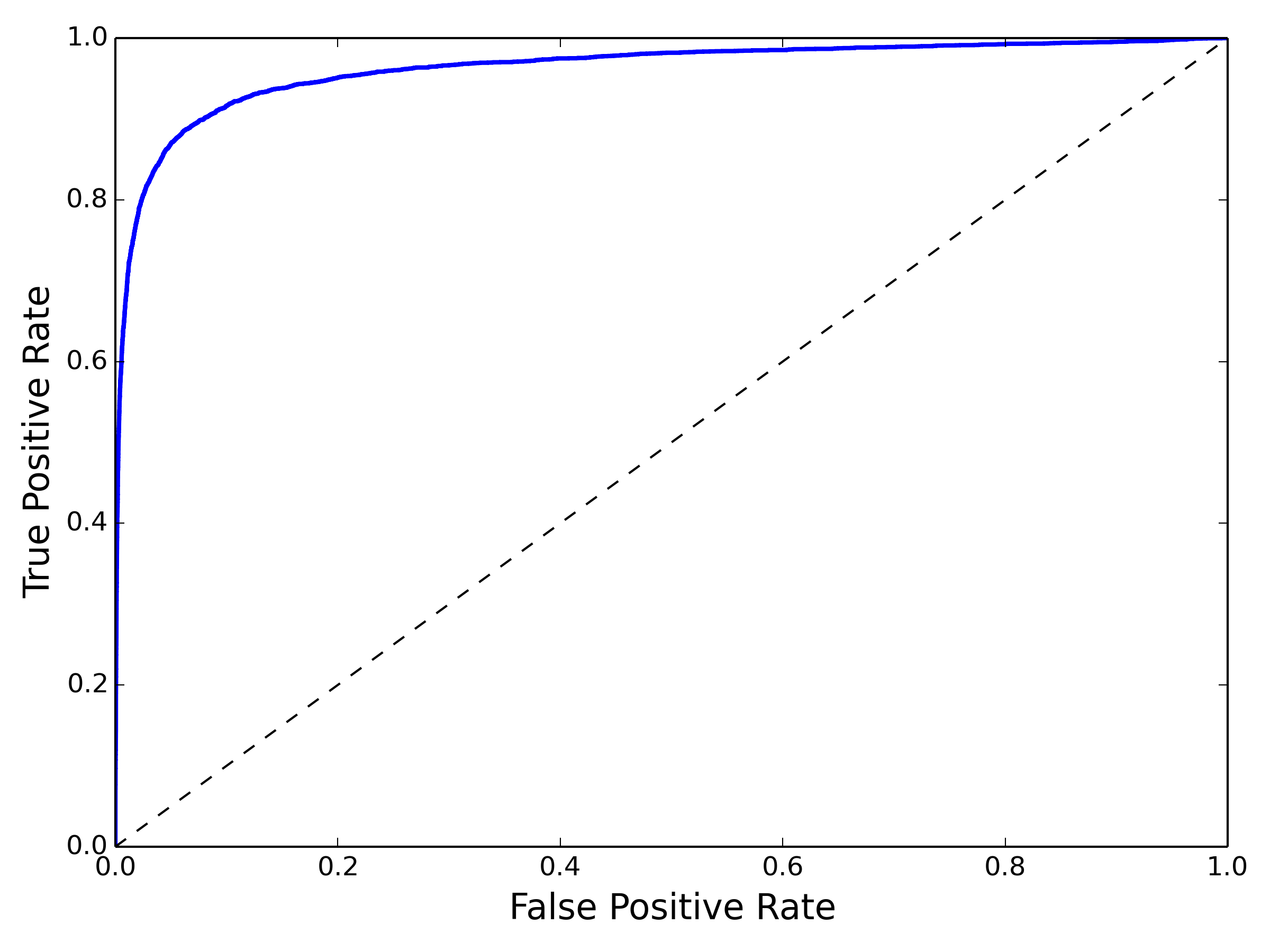
PR曲线与ROC曲线的区别在于,PR曲线不关心TN(x、y计算公式都没有包含TN),所以在负样本比例很高的时候,PR曲线波动比ROC曲线明显,更能体现优化空间。另外,ROC曲线关心TN恰好也是它的优势,比如在推荐、搜索等learn to rank 任务中,我们关心的是整个数据集的排序情况,TN也是需要考虑在内的,所以经常离线计算AUC(ROC曲线下方面积)来衡量rank model的优劣。
中场休息时间。。。喝口茶~ 欢迎关注公众号:kaggle实战,或博客:http://www.cnblogs.com/daniel-D/
4. 多分类器与误差分析
多分类器是指能区别两个以上类别的分类器,比如手写数字识别这个数据集要区分0-9,像大型图像数据集可能有几万个类别。有些算法可以直接区分多类,如softmax、RF或者贝叶斯,有些算法无法直接区分,比如上面用到的线性分类器等二分类器。二分类器也可以组合形成多分类器,常见的策略有 One vs All和 One vs One。
在数字识别这个任务中,One vs All(OVA) 一共要训练10个分类器,分别是0 vs 非0,1 vs 非1……预测的时候,10个分类器依次输出为0,为1等的概率,可直接取最大概率作为预测值。One vs One则需要10*(10-1)/ 2个分类器,依次是 0 vs 1,0 vs 2……8 vs 9。OVO和OVA在实际使用不多,这里就不赘述了。
用RF模型训练后,在预测集上预测图像属于哪个类别,由于模型不是百分百准确的,会有0判定成1或者1判定成2的情况,用rowIndex表示实际的label,colIndex表示预测的label,统计预测的label落到实际label的个数,可以得到以下矩阵:

可视化之后得到下图:
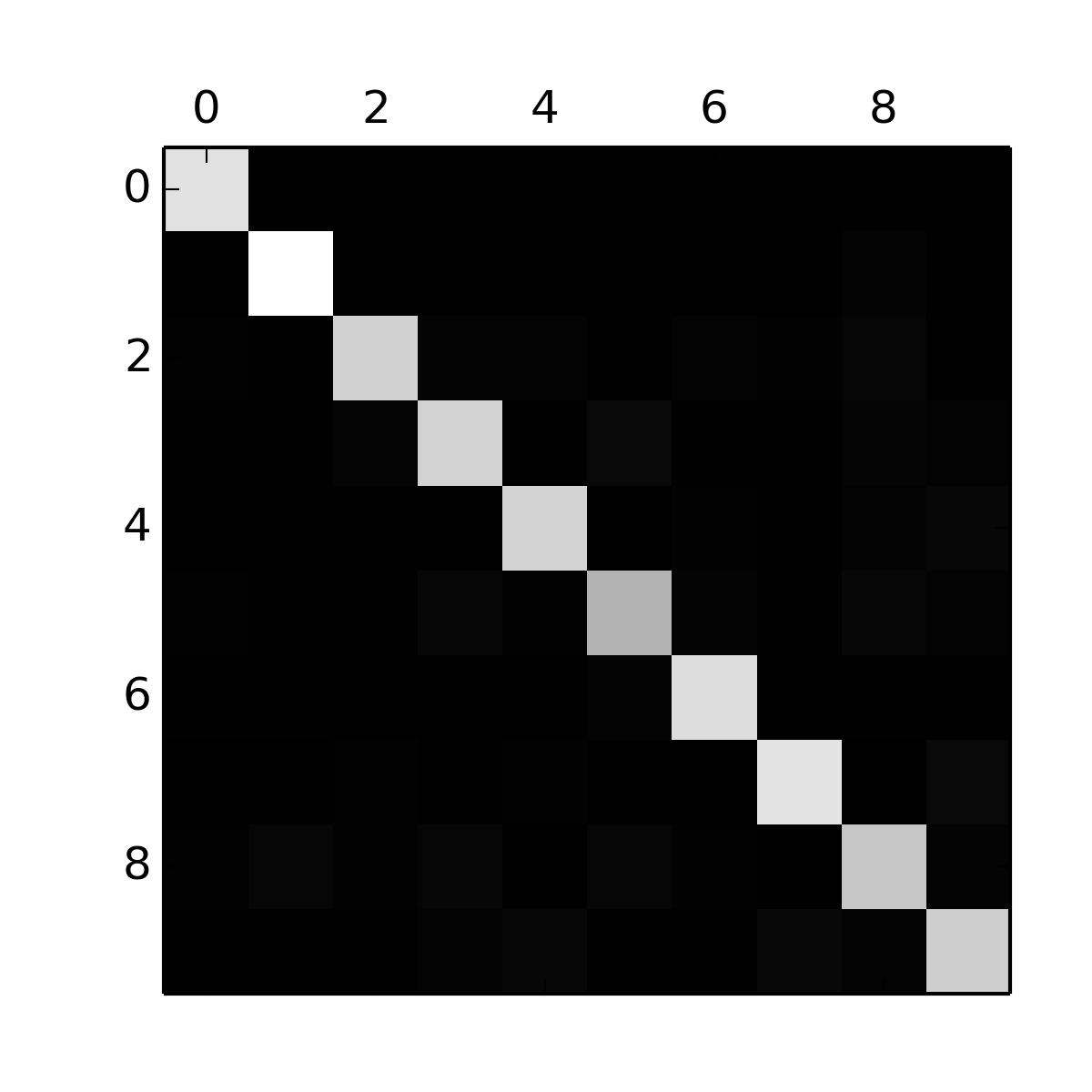
可以看到对角线方块很亮,说明所有类别基本判定准确。但是“5”方块较暗,可能是由于5的图片数量较少,或者5的准确率偏低导致,要具体分析数据才能找到原因。除了对角线方块,我们还想分析其余方块的情况,可以把Confusion Matrix每个元素处理该行的总和,对角线置0,得到下图:

可以看到3和5、7和9都容易混淆,想通过RF模型要提升效果的突破口可能就在这里。
5. Kaggle 实战
实际上,3和5、7和9容易混淆的原因在于,他们形态较为相似,直接用像素作为特征,相同的数字,在图像中旋转微小角度或者平移,都会导致像素空间的巨大变化,kaggle上高分kernel普遍都用神经网络里的CNN来提取特征,准确率可以轻松超过98%。预处理流程为:
- 把 label 从0-9的dense编码转化为 one hot encode编码
- 分割出4w个训练集和2k个验证集
然后定义一个最常用CNN网络结构和主要的超参数如下:
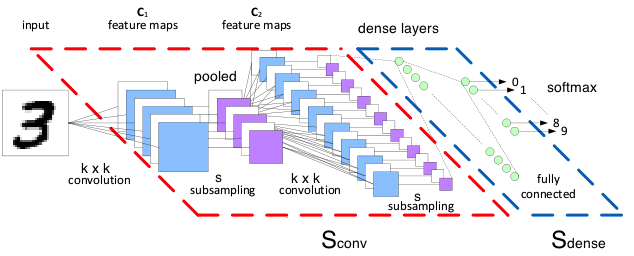
卷积参数:一般设置stride=1,卷积后保持原尺寸,用0填充,非线性变换采用relu;pooling大小2*2,stride=2,取maxPooling
网络结构:
- input:(40000, 28, 28, 1)
- conv1:kernel [5, 5, 1, 32] => (40000, 28, 28, 32)
- maxPool1:kernel [1, 2, 2, 1] => (40000, 14, 14, 32)
- conv2:kernel [5, 5, 32, 64] => (40000, 14, 14, 64)
- maxPool2: kernel [1, 2, 2, 1] => (40000, 7, 7, 64)
- flat:(40000,7*7*64) => (40000, 3136)
- FC1: (40000, 1024),非线性变换仍然可以采用relu
- dropout: 0.5
- FC2:(40000, 10)
- Loss:cross-entropy
由于MNIST数据集各类分布都比较均匀,用准确率就能较好评估模型了,比其他指标更加直白
详细代码可以参考这个kernel:https://www.kaggle.com/kakauandme/tensorflow-deep-nn
参考资料
- Kaggle: TensorFlow deep NN
- Book: Hands-on machine learning with scikit-learn and tensorflow
- Code:03_classification.ipynb
附:公众号

顺便测试下赞赏码


Kaggle实战分类问题2的更多相关文章
- Kaggle实战之二分类问题
0. 前言 1. MNIST 数据集 2. 二分类器 3. 效果评测 4. 多分类器与误差分析 5. Kaggle 实战 0. 前言 "尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手 ...
- Kaggle实战之一回归问题
0. 前言 1.任务描述 2.数据概览 3. 数据准备 4. 模型训练 5. kaggle实战 0. 前言 "尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题 ...
- 机器学习(一):记一次k一近邻算法的学习与Kaggle实战
本篇博客是基于以Kaggle中手写数字识别实战为目标,以KNN算法学习为驱动导向来进行讲解. 写这篇博客的原因 什么是KNN kaggle实战 优缺点及其优化方法 总结 参考文献 写这篇博客的原因 写 ...
- 【项目实战】kaggle产品分类挑战
多分类特征的学习 这里还是b站刘二大人的视频课代码,视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9 相关注释已经标明了(就当是笔记),因此在这 ...
- Python机器学习实践与Kaggle实战(转)
https://mlnote.wordpress.com/2015/12/16/python%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E8%B7%B5 ...
- Kaggle实战——点击率预估
https://blog.csdn.net/chengcheng1394/article/details/78940565 原创文章,转载请注明出处: http://blog.csdn.net/che ...
- kaggle实战记录 =>Digit Recognizer
date:2016-09-13 今天开始注册了kaggle,从digit recognizer开始学习, 由于是第一个案例对于整个流程目前我还不够了解,首先了解大神是怎么运行怎么构思,然后模仿.这样的 ...
- kaggle 实战 (1): PCA + KNN 手写数字识别
文章目录 加载package read data PCA 降维探索 选择50维度, 拆分数据为训练集,测试机 KNN PCA降维和K值筛选 分析k & 维度 vs 精度 预测 生成提交文件 本 ...
- 基于Colab Pro & Google Drive的Kaggle实战
原文:https://hippocampus-garden.com/kaggle_colab/ 原文标题:How to Kaggle with Colab Pro & Google Drive ...
随机推荐
- make---GNU编译工具
make命令是GNU的工程化编译工具,用于编译众多相互关联的源代码问价,以实现工程化的管理,提高开发效率. 知识扩展 无论是在linux 还是在Unix环境 中,make都是一个非常重要的编译命令.不 ...
- sparkR处理Gb级数据集
spark集群搭建及介绍:敬请关注 数据集:http://pan.baidu.com/s/1sjYN7lF 总结:使用sparkR进行数据分析建模相比R大致有3-5倍的提升 查看原始数据集:通过iri ...
- android应用开发-从设计到实现 3-9 Origami动态原型设计
动态原型设计 动态的可交互原型产品,是产品经理和界面设计师向开发人员阐释自己设计的最高效工具. 开发人员不须要推測设计师要什么样的效果,照着原型产品做就好了. 非常多创业团队也发现了产品人的这个刚需, ...
- 转:向IOS设备发送推送通知
背景 SMS 和 MMS 消息是由无线运营商通过设备的电话号码向特定设备提供的.实现 SMS/MMS 的服务器端应用程序的开发人员必须费大量精力才能与现有的封闭电信基础架构进行交互(其中包括获取电话号 ...
- 使用QML自绘页面导航条
使用QML自绘页面导航条 近期使用QML制作项目,依照要求.须要制作成分页的插件.遗憾的是,QML的控件库Qt Quick都没有现成的控件,于是我尝试着自己实现自绘页面导航条. 原创文章,反对未声明的 ...
- #学习笔记#——JavaScript 数组部分编程(七)
24.柯里化 首先想解释一下,“柯里化”的意思, [在计算机科学中,柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结 ...
- 51Nod 1006 最长公共子序列Lcs问题 模板题
给出两个字符串A B,求A与B的最长公共子序列(子序列不要求是连续的). 比如两个串为: abcicba abdkscab ab是两个串的子序列,abc也是,abca也是,其中abca是这两个 ...
- netty实现TCP长连接
所用jar包 netty-all-4.1.30.Final.jar 密码:rzwe NettyConfig.java,存放连接的客户端 import io.netty.channel.group.Ch ...
- IOS经常使用的性能优化策略
1.用ARC管理内存 2.对于UITableView使用重用机制 3.UIView及其子类设置opaque=true 4.主进程是用来绘制UI的,所以不要堵塞 5.慎用XIB,由于XIB创建UIVie ...
- Apache-DBUtils包对数据库的操作
•commons-dbutils 是 Apache 组织提供的一个开源 JDBC工具类库,它是对JDBC的简单封装.学习成本极低.而且使用dbutils能极大简化jdbc编码的工作量,同一时候也不会影 ...