caffe(13) 数据可视化(python接口)配置
caffe程序是由c++语言写的,本身是不带数据可视化功能的。只能借助其它的库或接口,如opencv, python或matlab。大部分人使用python接口来进行可视化,因为python出了个比较强大的东西:ipython notebook, 现在的最新版本改名叫jupyter notebook,它能将python代码搬到浏览器上去执行,以富文本方式显示,使得整个工作可以以笔记的形式展现、存储,对于交互编程、学习非常方便。
python环境不能单独配置,必须要先编译好caffe,才能编译python环境。
python环境的配置说起来简单,做起来非常复杂。在安装的过程中,可能总是出现这样那样的问题。因此强烈建议大家用anaconda来进行安装,anaconda把很多与python有关的库都收集在一起了,包括numpy,scipy等等,因此,我们只需要下载对应系统,对应版本的anaconda来安装就可以了。
如果你想通过anaconda来安装,请跳过第一、二步,直接进入第三步开始:
一、安装python和pip
一般linux系统都自带python,所以不需要安装。如果没有的,安装起来也非常方便。安装完成后,可用version查看版本
# python --version
pip是专门用于安装python各种依赖库的,所以我们这里安装一下pip1.5.6
先用链接下载安装包 https://pypi.python.org/packages/source/p/pip/pip-1.5.6.tar.gz,然后解压,里面有一个setup.py的文件,执行这个文件就可以安装pip了
# sudo python setup.py install
有些电脑可能会提示 no moudle name setuptools 的错误,这是没有安装setuptools的原因。那就需要先安装一下setuptools, 到https://pypi.python.org/packages/source/s/setuptools/setuptools-19.2.tar.gz 下载安装包setuptools-19.2.tar.gz,然后解压执行
# sudo python setup.py install
就要以安装setuptools了,然后再回头去重新安装pip。执行的代码都是一样的,只是在不同的目录下执行。
二、安装pyhon接口依赖库
在caffe根目录的python文件夹下,有一个requirements.txt的清单文件,上面列出了需要的依赖库,按照这个清单安装就可以了。
在安装scipy库的时候,需要fortran编译器(gfortran),如果没有这个编译器就会报错,因此,我们可以先安装一下。
首先回到caffe的根目录,然后执行安装代码:
# cd ~/caffe
# sudo apt-get install gfortran
# for req in $(cat requirements.txt); do sudo pip install $req; done
安装完成以后,我们可以执行:
# sudo pip install -r python/requirements.txt
就会看到,安装成功的,都会显示Requirement already satisfied, 没有安装成功的,会继续安装。
在安装的时候,也许问题会有一大堆。这时候你就知道anaconda的好处了。
三、利用anaconda来配置python环境
如果你上面两步已经没有问题了,那么这一步可以省略。
如果你想简单一些,利用anaconda来配置python环境,那么直接从这一步开始,可以省略上面两步。
先到https://www.continuum.io/downloads 下载anaconda, 现在的版本有python2.7版本和python3.5版本,下载好对应版本、对应系统的anaconda,它实际上是一个sh脚本文件,大约280M左右。我下载的是linux版的python 2.7版本。
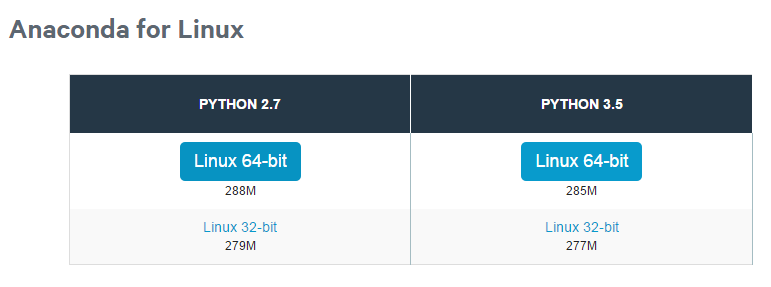
下载成功后,在终端执行(2.7版本):
# bash Anaconda2-2.4.1-Linux-x86_64.sh
或者3.5 版本:
# bash Anaconda3-2.4.1-Linux-x86_64.sh
在安装的过程中,会问你安装路径,直接回车默认就可以了。有个地方问你是否将anaconda安装路径加入到环境变量(.bashrc)中,这个一定要输入yes
安装成功后,会有当前用户根目录下生成一个anaconda2的文件夹,里面就是安装好的内容。
输入conda list 就可以查询,你现在安装了哪些库,常用的numpy, scipy名列其中。如果你还有什么包没有安装上,可以运行
conda install *** 来进行安装,
如果某个包版本不是最新的,运行 conda update *** 就可以了。
四、编译python接口
首先,将caffe根目录下的python文件夹加入到环境变量
打开配置文件bashrc
# sudo vi ~/.bashrc
在最后面加入
export PYTHONPATH=/home/xxx/caffe/python:$PYTHONPATH
注意 /home/xxx/caffe/python 是我的路径,这个地方每个人都不同,需要修改
保存退出,更新配置文件
# sudo ldconfig
然后修改编译配置文件Makefile.config. 我的配置是:

## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome! # cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1 # CPU-only switch (uncomment to build without GPU support).
# CPU_ONLY := 1 # uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0 # uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1 # Uncomment if you're using OpenCV 3
# OPENCV_VERSION := 3 # To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++ # CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr # CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the *_50 lines for compatibility.
CUDA_ARCH := -gencode arch=compute_20,code=sm_20 \
-gencode arch=compute_20,code=sm_21 \
-gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_50,code=compute_50 # BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
BLAS := atlas
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas # Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib # This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app # NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
# PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
ANACONDA_HOME := $(HOME)/anaconda2
PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python2.7 \
$(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \ # We need to be able to find libpythonX.X.so or .dylib.
# PYTHON_LIB := /usr/lib
PYTHON_LIB := $(ANACONDA_HOME)/lib # Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib # Uncomment to support layers written in Python (will link against Python libs)
WITH_PYTHON_LAYER := 1 # Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib # If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib # Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1 BUILD_DIR := build
DISTRIBUTE_DIR := distribute # Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1 # The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0 # enable pretty build (comment to see full commands)
Q ?= @
修改完编译配置文件后,最后进行编译:
# sudo make pycaffe
编译成功后,不能重复编译,否则会提示 Nothing to be done for "pycaffe"的错误。
防止其它意外的错误,最好还编译一下:
# sudo make test -j8
# sudo make runtest -j8
也许你在编译runtest的时候,会报这样的错误:
.build_release/test/test_all.testbin: error while loading shared libraries: libhdf5.so.10: cannot open shared object file: No such file or directory
这是因为 libhdf5.so的版本问题,你可以进入/usr/lib/x86_64-linux-gnu看一下,你的libhdf5.so.x中的那个x是多少,比如我的是libhdf5.so.7
因此可以执行下面几行代码解决:
# cd /usr/lib/x86_64-linux-gnu
# sudo ln -s libhdf5.so.7 libhdf5.so.10
# sudo ln -s libhdf5_hl.so.7 libhdf5_hl.so.10
# sudo ldconfig
最终查看python接口是否编译成功:
进入python环境,进行import操作
# python
>>> import caffe
如果没有提示错误,则编译成功。
五、安装jupyter
安装了python还不行,还得安装一下ipython,后者更加方便快捷,更有自动补全功能。而ipython notebook是ipython的最好展现方式。最新的版本改名为jupyter notebook,我们先来安装一下。(如果安装了anaconda, jupyter notebook就已经自动装好,不需要再安装)
# sudo pip install jupyter
安装成功后,运行notebook
# jupyter notebook
就会在浏览器中打开notebook, 点击右上角的New-python2, 就可以新建一个网页一样的文件,扩展名为ipynb。在这个网页上,我们就可以像在命令行下面一样运行python代码了。输入代码后,按shift+enter运行,更多的快捷键,可点击上方的help-Keyboard shortcuts查看,或者先按esc退出编辑状态,再按h键查看。
caffe(13) 数据可视化(python接口)配置的更多相关文章
- ubuntu16.04+caffe+python接口配置
在Windows上用了一个学期的caffe了.深感各种不便,于是乎这几天在ubuntu上配置了caffe和它的python接口,现在记录配置过程,亲测可用: 环境:ubuntu16.04 , caff ...
- Caffe学习系列(13):数据可视化环境(python接口)配置
caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较 ...
- Caffe学习系列(11):数据可视化环境(python接口)配置
参考:http://www.cnblogs.com/denny402/p/5088399.html 这节配置python接口遇到了不少坑. 1.我是利用anaconda来配置python环境,在将ca ...
- Windows+Caffe+VS2013+python接口配置过程
前段时间在笔记本上配置了Caffe框架,中间过程曲曲折折,但由于懒没有将详细过程总结下来,这两天又在一台配置较高的台式机上配置了Caffe,配置时便非常后悔当初没有写到博客中去,现已配置好Caffe, ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- windows10下基于vs2015的 caffe安装教程及python接口实现
啦啦啦:根据网上的教程前一天安装失败,第二天才安装成功.其实caffe的安装并不难,只是网上的教程不是很全面,自己写一个,留作纪念. 准备工作 Windows10 操作系统 vs2015(c++编译器 ...
- 数据可视化 -- Python
前提条件: 熟悉认知新的编程工具(jupyter notebook) 1.安装:采用pip的方式来安装Jupyter.输入安装命令pip install jupyter即可: 2.启动:安装完成后,我 ...
- Windows下caffe的python接口配置
主要是因为,发现很多代码是用python编写的,在这里使用的python安装包是anaconda2. 对应下载地址为: https://www.continuum.io/downloads/ 安装py ...
- Echarts数据可视化series-scatter散点图,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
随机推荐
- http://www.secrepo.com 安全相关的数据获取源
来自:http://www.secrepo.com Network MACCDC2012 - Generated with Bro from the 2012 dataset A nice datas ...
- 【App 开发框架 - App Framework】
http://edm.mcake.com/mark/jqmboi/#plugins 官网:http://app-framework-software.intel.com/index.php 官方API ...
- HttpClient get和HttpClient Post请求的方式获取服务器的返回数据
1.转自:https://blog.csdn.net/alinshen/article/details/78221567?utm_source=blogxgwz4 /* * 演示通过HttpClie ...
- ETL工具的功能和kettle如何来提供这些功能
不多说,直接上干货! 大家会有一个疑惑,本系列博客是Kettle,那怎么扯上ETL呢? Kettle是一款国外开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行. 说白了 ...
- SSRS参数不能默认全选的解决方法
解决方法选自<SQL Server 2008 R2 Reporting Services 报表服务>一书,亲测有效. 注意:参数默认值如果是字符串需要类型转换 =CStr("AL ...
- 005.ES2016新特性--装饰器
装饰器在设计阶段可以对类和属性进行注释和修改,在Angular2中装饰器非常常用,可以用来定义组件.指令以及管道,并且可以与框架提供的依赖注入机制配合使用. 从本质上上讲,装饰器的最大作用是修改预定义 ...
- swift语言点评十一-Methods
Assigning to self Within a Mutating Method Mutating methods can assign an entirely new instance to t ...
- html转word文档
html转word文档 package cn.com.szhtkj.util; import java.io.ByteArrayInputStream; import java.io.File; im ...
- 基于 Token 的身份验证:JSON Web Token
最近了解下基于 Token 的身份验证,跟大伙分享下.很多大型网站也都在用,比如 Facebook,Twitter,Google+,Github 等等,比起传统的身份验证方法,Token 扩展性更强, ...
- WebSocket 前端封装
$.extend({ socketWeb:function (opt) { if("WebSocket" in window){ var setting=$.extend({ ur ...