yarn架构——本质上是在做解耦 将资源分配和应用程序状态监控两个功能职责分离为RM和AM
Hadoop YARN架构解读
原Mapreduce架构
原理
架构图如下:

原 MapReduce 程序的流程:
首先用户程序 (JobClient) 提交了一个 job,job 的信息会发送到 Job
Tracker 中,Job Tracker需要与集群中的机器定时通信 (heartbeat), 需要管理哪些程序应该跑在哪些机器上,需要管理所有
job 失败、重启等操作。
TaskTracker 是 Map-reduce
集群中每台机器都有的一个部分,它的职责有两个:一是监视自己所在机器的资源情况,二是监视当前机器的 tasks 运行状况。TaskTracker
需要把这些信息通过 heartbeat 发送给 JobTracker,JobTracker 会搜集这些信息以给新提交的 job
分配运行在哪些机器上。上图虚线箭头就是表示消息的发送 - 接收的过程。
存在的问题
- JobTracker单点故障。
- JobTracker的管理负荷过大,业界普遍认可的并行节点上限是4000。
- TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现资源枯竭。
其他问题摘抄如下:
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
从
操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 )
时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应
用程序是不是适用新的 Hadoop 版本而浪费大量时间。
一句话总结:JobTracker干的事儿太多了。
YARN架构
架构图如下:

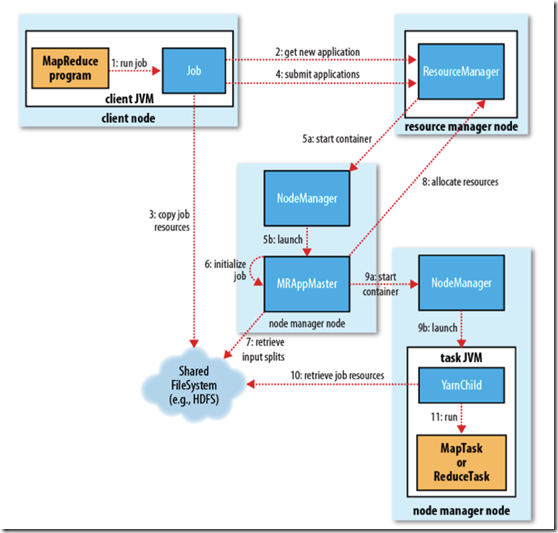
基本思想是将 JobTracker 两个主要的功能分离成单独的组件,这两个功能是资源管理和任务调度 / 监控。
ResourceManager
管理所有应用程序计算资源的分配,每一个应用的 ApplicationMaster 负责相应的调度和协调。一个应用程序无非是一个单独的传统的
MapReduce 任务或者是一个 DAG( 有向无环图 ) 任务。ResourceManager
和每一台机器的节点管理服务器能够管理用户在那台机器上的进程并能对计算进行组织。NodeManager
是每一台机器框架的代理,是执行应用程序的容器,监控应用程序的资源使用情况 (CPU,内存,硬盘,网络 ) 并且向调度器汇报。
架构变化的总结
原来的JobTracker和TaskTracker是从物理节点的角度来设置,但每个
节点内部还包括资源监控、任务调度的功能。改版之后,从逻辑上进行功能模块设计,ResourceManager专门负责管理和分配资
源,NodeManager是RM在各节点上的代理,每个应用有一个ApplicationMaster,但不放在RM节点上,而是分布式存放,用来管理
应用在各节点上的运行、向RM申请资源。这样,原来JobTracker被分解为两个功能模块,并且不在同一个节点上运行,自然降低了RM节点(原
JobTracker节点)的管理负荷。
摘自:http://www.jianshu.com/p/3b9179534127
yarn架构——本质上是在做解耦 将资源分配和应用程序状态监控两个功能职责分离为RM和AM的更多相关文章
- GAN初步——本质上就是在做优化,对于生成器传给辨别器的生成图片,生成器希望辨别器打上标签 1,体现在loss上!
from:https://www.sohu.com/a/159976204_717210 GAN 从 2014 年诞生以来发展的是相当火热,比较著名的 GAN 的应用有 Pix2Pix.CycleGA ...
- Deep Belief Network简介——本质上是在做逐层无监督学习,每次学习一层网络结构再逐步加深网络
from:http://www.cnblogs.com/kemaswill/p/3266026.html 1. 多层神经网络存在的问题 常用的神经网络模型, 一般只包含输入层, 输出层和一个隐藏层: ...
- 大数据DDos检测——DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然! 和一个句子的分词算法CRF没有区别!
DDos攻击本质上是时间序列数据,t+1时刻的数据特点和t时刻强相关,因此用HMM或者CRF来做检测是必然!——和一个句子的分词算法CRF没有区别!注:传统DDos检测直接基于IP数据发送流量来识别, ...
- ARIMA模型——本质上是error和t-?时刻数据差分的线性模型!!!如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理!ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数
https://www.cnblogs.com/bradleon/p/6827109.html 文章里写得非常好,需详细看.尤其是arima的举例! 可以看到:ARIMA本质上是error和t-?时刻 ...
- Spark2.1.0模型设计与基本架构(上)
随着近十年互联网的迅猛发展,越来越多的人融入了互联网——利用搜索引擎查询词条或问题:社交圈子从现实搬到了Facebook.Twitter.微信等社交平台上:女孩子们现在少了逛街,多了在各大电商平台上的 ...
- 详细分析 Java 中实现多线程的方法有几种?(从本质上出发)
详细分析 Java 中实现多线程的方法有几种?(从本质上出发) 正确的说法(从本质上出发) 实现多线程的官方正确方法: 2 种. Oracle 官网的文档说明 方法小结 方法一: 实现 Runnabl ...
- Yarn架构详解
Yarn架构介绍Yarn/MRv2最基本的想法是将原JobTracker主要的资源管理和job调度/监视功能分开作为两个单独的守护进程.有一个全局的ResourceManager(RM)和每个Appl ...
- YARN架构设计详解
一.YARN基本服务组件 YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager ...
- Java进阶专题(十七) 系统缓存架构设计 (上)
前言 我们将先从Redis.Nginx+Lua等技术点出发,了解缓存应用的场景.通过使用缓存相关技术,解决高并发的业务场景案例,来深入理解一套成熟的企业级缓存架构如何设计的.本文Redis部分总结 ...
随机推荐
- POJ 1200 Hash
我的hash从来没写对过........ (白学了快一年OI --原来连个hash都没写对过) 但是 但是 今天是一个值得纪念的日子. 看看标题 我竟然在写hash的题解. (好了好了 废话少说) 题 ...
- ACM_支离破碎(递推dp)
支离破碎 Time Limit: 4000/2000ms (Java/Others) Problem Description: 远古时期有一位魔王想向一座宫殿里的公主求婚.为了考验魔王的智力,太后给了 ...
- Java单例模式 多种实现方式
一:通过静态私有成员实现单例模式 (1):私有化构造函数 (2):new静态实例属性对象,加锁. 单例类: package SinglePag; /* * 构造函数私有化,结合锁+静态的概念 实现单例 ...
- 几个概念:x86、x86-64和IA-32、IA-64
最近在学习操作系统方面的知识,学习操作系统难免要和CPU打交道,虽然现在CPU和操作系统不像计算机发展初期一样是绑定在一起的,但是大家都知道操作系统和CPU Architecture的联系是很紧密的, ...
- Angular ui-router的常用配置参数详解
一.$urlRouterProvider服务 $urlRouterProvidfer负责监听$location,当$location变化时,$urlRouterProvider将在规则列表中查找匹配的 ...
- (转) RabbitMQ学习之远程过程调用(RPC)(java)
http://blog.csdn.net/zhu_tianwei/article/details/40887885 在一般使用RabbitMQ做RPC很容易.客户端发送一个请求消息然后服务器回复一个响 ...
- MySQL_基本操作
sql语句 Sql语句主要用于存取数据,查询数据,更新数据和管理数据库系统. #Sql语句分为3种类型 #1.DDL语句:数据库定义语言: 数据库.表.视图.索引.存储过程,例如CREATE DROP ...
- 洛谷P2894 [USACO08FEB]酒店Hotel_区间更新_区间查询
Code: #include<cstdio> #include<algorithm> #include<cstring> using namespace std; ...
- Php+Redis队列原理
我们新建一个文件queue.php <?php while(true){ echo 1; sleep(1); } 然后中 命令行里面 执行 php queue 你会发现每秒钟输出一个1:等了很久 ...
- NTP学习路线
NTP了解路线 基础 ntp配置中的tinker参数? ntp的同步方式slew step的区别? restrict含义?restrict -6 default ignore含义? fudge 127 ...