hadoop NameNode 手动HA
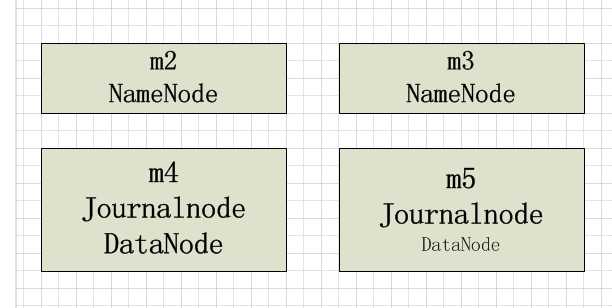
HDFS HA主要是通过Quorum Journal Manager (QJM)在Active NameNode和Standby NameNode之间共享edit logs
hdfs-site.xml的配置
dfs.nameservices - nameservice的逻辑名称,可以是任意的名称,此处配置为cluster
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
dfs.ha.namenodes.[nameservice ID] - 配置nameservice中的每一个NameNode, NameNode的个数建议不超过5个,最好是3个,此处配置两个
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
dfs.namenode.rpc-address.[nameservice ID].[name node ID] - 配置NameNode的RPC具体地址,m2和m3为主机名
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>m2:9820</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>m3:9820</value>
</property>
dfs.namenode.http-address.[nameservice ID].[name node ID] - 配置NameNode HTTP监听的地址
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>m2:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>m3:9870</value>
</property>
dfs.namenode.shared.edits.dir - 配置JournalNodes上NameNode读和写的edits文件URL地址,URL格式: qjournal://*host1:port1*;*host2:port2*;*host3:port3*/*journalId*.
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://m4:8485;m5:8485;/mycluster</value>
</property>
dfs.client.failover.proxy.provider.[nameservice ID] - HDFS客户端联系Active NameNode的java类
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyPr
ovider</value>
</property>
dfs.ha.fencing.methods - 防止脑裂,两种方法,此处使用shell 这种方法
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(shell(/bin/true))</value>
</property>
dfs.journalnode.edits.dir - JournalNode存储本地状态的路径
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/journalnode/data</value>
</property>
core-site.xml配置
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.3/tmp/data</value>
</property>
至此配置已经结束,接下来启动集群。
1、首先启动journalnode,通过./hadoop-daemon.sh start journalnode命令启动journalnode(m4, m5节点)
jps:可以发现JournalNode进程
2、通过hdfs namenode -format命令初始化集群,格式化完成后拷贝元数据到另外一个namenode节点上
3、启动hadoop集群start-dfs.sh
4、通过hdfs haadmin手动切换namenode是否为active
hadoop NameNode 手动HA的更多相关文章
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Hadoop记录-Hadoop NameNode 高可用 (High Availability) 实现解析
Hadoop NameNode 高可用 (High Availability) 实现解析 NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDF ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- Hadoop NameNode 高可用 (High Availability) 实现解析
转载自:http://reb12345reb.iteye.com/blog/2306818 在 Hadoop 的整个生态系统中,HDFS NameNode 处于核心地位,NameNode 的可用性直接 ...
- Hadoop NameNode 高可用 (High Availability) 实现解析[转]
NameNode 高可用整体架构概述 在 Hadoop 1.0 时代,Hadoop 的两大核心组件 HDFS NameNode 和 JobTracker 都存在着单点问题,这其中以 NameNode ...
- 【转载】Hadoop NameNode 高可用 (High Availability) 实现解析
转载:https://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-name-node/ NameNode 高可用整体架构概述 在 Had ...
- NameNode的HA
HDFS中的NameNode的HA怎么实现?(一言以蔽之) 在Hadoop集群中配置并启动两个NameNode进程,一个作为Active节点对外提供服务,另一个作为Standby的节点,两个NameN ...
随机推荐
- ASP.NET\ASP.NET MVC表单提交遇到的问题结论
同步提交的两种基本方式 1,用type=“submit”按钮.form没有必要runat=“server” <form method="post" action=" ...
- 每天学点GDB 15
本节重点描述两个gdb集成测试环境 有没有办法在一边调试的时候,一边显示对应的源码呢?有没有一种工具能够将gdb集成到ide中呢,本文就试图回答这些问题. emacs gdb 在linux的世界里,e ...
- json解析json字符串时候,数组必须对应jsonObjectArray,不能对应JsonObject。否则会解析错误。
json第三方解析json字符串时候,json数组必须对应jsonObjectArray,不能对应JsonObject.->只要是[]开头的都是json数组字符串,就要用jsonArray解析 ...
- 一些浏览器的USER-AGENT
115浏览器的USER-AGENT 版本号:5.1.3.55 Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like G ...
- WordPress博客教程:博客赚钱
稍有关注独立博客的人都应该知道,中文博客实现盈利非常艰难,至少对于大部分中文博客来说是这样的.但很多时候我们不得不往赚钱的方向前进,至少要交得起域名和空间的租用费吧.不过期待赚钱前,你必须思考下如何提 ...
- ARM状态和THUMB状态
ARM处理器的工作状态 在ARM的体系结构中,可以工作在三种不同的状态,一是ARM状态,二是Thumb状态及Thumb-2状态,三是调试状态. <嵌入式系统开发与应用教程(第2版)>上介绍 ...
- P1970 花匠
状态定义是dp中非常重要的,可以直接影响到效率,如此题,第一种思路是: #include <bits/stdc++.h> using namespace std; const int ma ...
- jq each 用法以及js与json互转
$(function(){ var json = '[{"id":"1","tagName":"apple"},{&qu ...
- 浮动以后父DIV包不住子DIV解决方案
转载自http://blog.sina.com.cn/s/blog_6c363acf0100v4cz.html 当DIV1里面嵌套有一个DIV2,当DIV2设置了浮动,那么DIV1是无法被撑开的,也就 ...
- windows bat常用命令积累
1.判断文件夹是否为空 dir/a/b "D:\test"|findstr . >nul&&(echo 有文件)||(echo 空) 2.多层文件夹遍历 ...