Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
台湾作家林清玄在接受记者采访的时候,如此评价自己30多年写作生涯:“第一个十年我才华横溢,‘贼光闪现’,令周边黯然失色;第二个十年,我终于‘宝光现形’,不再去抢风头,反而与身边的美丽相得益彰;进入第三个十年,繁华落尽见真醇,我进入了‘醇光初现’的阶段,真正体味到了境界之美”。
长夜有穷,真水无香。领略过了Linux“身在江湖”的那种惊心动魄以及它那防御系统的繁花似锦,该是回过头来体味性能境界之美的时候了。毕竟仅能经得起敲打还是不能独步武林的!
《七种武器》作为古龙小说的代表作之一,共分为七个系列:长生剑、离别钩、孔雀翎、
碧玉刀、多情环、霸王枪、拳头七种非一般江湖武器,件件精美绝伦。七种令人闻风丧胆、不可思议的武器,七段完全独立的故事,令人叹为观止,不能掩卷。
恰巧Linux也拥有七种武器,分别是:fork、VFS、mmap、epoll、udev、LVS、module,同样也是七种非一般的“江湖武器”,件件精美绝伦。只不过它们是七种令人肃然起敬、不可怠慢的武器。七种武器看似完全不相干但内部却有着千丝万缕的关联,实在是令人叹为观止,不得不悉心研究一番。
本章将给你逐一地展示Linux历拥有的七种武器。但是,请你不要忘记,古龙先生的《七种武器》表面上写的是杀戮,实际上写的是人性:笑、相聚、自信心、诚实、仇恨、勇气、不放弃。那么Linux上的七种武器应该怎样去看呢?我想,答案在每一个人的心中。
15.1 长生剑:fork
古龙的《长生剑》不是写长生剑的主人白玉京,而是写弱女子袁紫霞。她一个人来清理
门户,大大小小的武林高手被她轻轻松松地置之死地。小说上说:“一个人只要懂得利用自己的长处,根本就不必用武功也一样能够将人击倒。”她的长处是笑——无论多么锋利的剑,也比不上那动人的一笑。
长生剑这个形式代表的是一种任何时候处变不惊、泰然自若的淡定。深处逆境甚至是面临死亡都能从容一笑化解愁怀。这正好对应了Linux的fork,因为fork之后就会产生一个新的进程,可以使你的程序异常稳定。为什么会这样呢?故事得从这个地方说起……
15.1.1从线程说起
话说1969年在Unix诞生之曰起,它就足以多任务而著称的,且一直独领风骚几十年。然而,从这一天起,一个无休止的争论也就开始了,那就是怎么实现多任务。观点很多,但普遍存在的主要有两种:一种是以进程为主的强调任务独立性的观点;另一种是以线程为主的强调任务协同性的观点。这两种观点争来争去到现在都没有一个结论,但这是一种极具价值的争论。
看世间事,总是此起彼伏,变幻莫测。之前,一直是以进程为代表的Unix这一派占优。但是就在人们为争论得不可开交而乐此不疲之际,以线程为代表的Windows横空出世了,并迅速占领了个人电脑这块辽阔的疆土,从此线程这一派占据了绝对的优势。十分清楚地告诉人们,多任务只有这么玩才深入人心。
1. 进程和线程的差异
那么到底什么是进程,什么又是线程呢?这个问题基本上已经快被所有面试官问烂了,很多人也在这个地方折了N多回。
从现代的意义上来看,进程就像一个大容器。在程序被运行之后,就相当于将程序装进了这个容器,然后你还可以往容器里面加其他东西,比如一些共享库。当程序被运行两次时,容器里的东西并不会被倒掉,而是再找一个新的容器来装程序。 多个程序实例
那么线程呢?普遍意义上来说,线程也属于进程的一部分,这相当于在进程这个容器中又划分出了许多的小隔间。这些小隔间将迸程这个大容器中的程序划分成了很多独立的部分。但是这些小隔间并没有将整个程序划分干净,还留下了一些,而留下的这些可以在任意的小隔间中游荡。而且往大容器里添加的东西也不会特意分给哪个小隔间,甚至还能添加新的小隔间。
游离于小隔间之外的东西很多时候是个很麻烦的角色,因为会有好多小隔间会同时需要
它们,这就必须得制定一些规矩来协调或商量着来,否则就会出乱子,把整个程序弄得四分五裂。协调或商量的方法由操作系统来提供,用纯技术的说法就是线程同步机制。作为一个合格的操作系统,一般都会提供:互斥锁、条件变量、信号量等机制,或者相似的机制。虽然方法有了,但是如何商量、协调什么这种需要智商的问题,就只能留给程序员们了。
对于进程这个大容器,如果你不是很愤青非得要将这个铁饭碗戳一个洞的话,也就没啥可要协调或商量的了。但是人在社会上混,跟其他人老死不相往来的话,估计也混不多久就被人打冷宫了。而且你也不可能一个人什么都会做,所以必须寻求帮助。要寻求帮助就得与人沟通。放在进程这个大容器里的程序也一样,不可能什么都能做得来,也需要寻求其他程序的帮助,和它们沟通。程序与程序之间的沟通方法也由操作系统来提供,用纯技术的说法孰是进程通信机制(IPC进程间通信)。那么作为一个合格的操作系统,一般都会提供:信号、管道、I/O重定向、套
接字等机制,或者类似的机制。同样的,虽然方法有了,沟通什么内容以及沟通的技巧等这些需要智商的事儿,还得由程序员自己来处理。
在操作系统层面,对进程和线程的支持是完全不同的,当然从目前来看没有谁敢不同时支持它们。以Windows为代表支持线程这一派的操作系统,往往在系统内部是以线程为调
度实体的,进程对于这类操作系统来说就是一堆数据结构罢了:以Unix为代表的支持进程这一派的操作系统,其系统内部的调度实体是进程,而线程基本上都是在耍花招了。也正因为这样,由于Windows将进程这个大容器基本上给忽略掉了,而每个线程又那么小巧精悍,调度起来远比Unix舞动那些大容器要轻松许多,从多任务的调度效率上Windows占有了很大的优势。这就相当于Windows耍的是小李飞刀,而Unix们抡的可是流星锤,谁更轻快灵活一看便明。但是谁才会是最终的赢家,这个还真不好说。
2. Linux的线程方案
有竞争才有动力。看到Windows的大红大紫,Unix们也不能甘为人下,自然也要在线程方面有所斩获。但是Unix本身并不具备对线程的支持,完全照搬Windows的设计又心有不甘,于是很多方案被提出来了。对于Linux,恐怕最有名的要数LinuxThreads方案了。
在开始时,Linux是完全的Unix克隆,在内核中并不支持线程。但是它的确可以通过clone()系统调用将进程作为调度的实体。这个调用创建了调用进程的一个拷贝,这个拷贝与调用进程共享相同的地址空间。LinuxThreads万案使用这个调用来完全在用户空间模拟对线程的支持。不幸的是,这个方案有太多缺点,让Windows总是有一种“一直被追赶从未被超越”的自豪。
首先,LinuxThreads有一个非常有名的设计就是管理线程,它要解决下面这些问题:
(1)响应终止信号并杀死整个进程;
(2)在线程执行完之后回收以堆栈形式使用的内存;
(3)等待终止的线程,防IE它们进入僵尸状态;
(4)回收线程本地数据;
(5)防止主线程过早退出或在所有线程都退出之后唤醒进入睡眠状态的主线程。
但是有这样的一个线程存在,就等于增加了整个程序的额外开销(创建、销毁、上下文切换等)。而且管理线程只能在一个CPU上运行,显然不适合现在的多核CPU。
其次,由于线程都是使用进程来模拟的,那么每个线程都会使用一个不同的进程ID,这与我们所理解的线程属于进程这个概念有强烈的冲突。而且还会导致/proc目录中充满了的进程项,而它们实际上又可能只是线程。
最后,这些问题还都只是冰山一角,更为复杂的问题我也没有兴趣去讨论,因为LinuxThreads只是记忆了。现代的Linux已经不是那个Linux了,这个时候的Windows就真的是瘟到死了。因力Linux有了NPTL。
NPTL的全称是Native POSIX Thread Library,翻译过来就是原生POSIX线程库。NTPL可以让Linux内核高效地运行那些使用POSIX风格的线程API所编写的程序。我在一个很老的32位系统( P3 800MHZ)下做了一个实验,成功地同时跑了10万个线程,启动这些线程只用了不到2秒。作为对比,在不支持NPTL的内核上,我的这个测试花了大约15分钟。在这个测试中NPTL所表现出来的性能提升让我惊诧不已。
NPTL是一种1:1的线程方案,一个线程会与内核的一个调度实体一一对应,线程的创
建和回收都由内核负责,这样就可以规避掉LinuxThreads的一切问题。这是一种最简单的合理线程实现方案。但是业界还有另外一个备选方案,就是m:n方案。这种方案中用户线程要多于调度实体。如果NPTL选择以这种方式实现的话,会使得线程上下文切换更快,因为它避免了系统调用。但是m:n的方案是以系统复杂度为代价的。既然Linux的骨子里有些“笨”,复杂性的东西是搞不来的,所以NPTL采用的依然是1:1的线程方案。
NPTL方案还引入了新的线程同步机制——futex。futex是fast userspace mutex的缩写,翻译过来就是快速用户空间互斥体。也就是说,这个互斥锁是完全在用户空间中实现的,这就规避了由用户空间到内核空间切换的代价,使得这个锁的效率更高。当然,futex只是Linux的一种底层机制,程序员要面对的那些锁并没有什么形式上的变化,因为它们是对futex的封装。
NPTL方案的引入并没有给程序员带来什么负担,或者说它对程序员是透明的。因为原有的LinuxThreads的API在NPTL万案中并没有改变,而且还更加符合POSIX标准的规定。这也是本书不打算深入介绍NPTL的根本原因,因为什么都没有变,还说它做什么呢?
NPTL是在Linux 2.6内核开始引入的。一个比较有趣的地方是,Linux内核本身的多任务调度实体被称为“内核线程”。而且经常有人会非常兴奋的说,Linux已经跟Windows 一样了,是以线程为调度实体的。的确不假,从2.6开始,线程是Linux原生支持的特性了,但是与Windows还是有很大差别的。
首先,Windows的调度实体就是线程,进程只是一堆数据结构。而Linux不是。Linux将进程和线程做了同等对待,进程和线程在内核一级没有差别,只是通过特殊的内存映射方法使得它们从用户的角度看来有了进程和线程的差别。
其次,Windows至今也没有真正的多进程概念,创建进程的开销远大于创建线程的开销。Linux则不然。Linux在内核一级并不区分进程和线程,这使得创建进程的开销与创建线程的开销差不多。
最后,Windows与Linux的任务调度策略也不尽相同。Windows会随着线程越来越多而变得越来越慢,这也是为什么Windows服务器在运行一段时间后必须萤启的原因。当然,如果你是微软的VIP客户还是有办法规避这个问题的,但是大部分用户都不是微软的VIP。反观Linux却可以持续运行很长时间,有些Linux服务器已经连续运行了几年,系统的效率也没有什么变化。而且Linux也没有VIP用户的说法,或者人人都可以是Linux的VIP。
不管怎样,自从Linux引入了NTPL机制之后,才真正成为一个可以傲视群雄的操作系统,成为一个真正意义的现代操作系统。当然,即便这样也不建议你盲从Linux,因为还有很多特性是Linux所不具备的,这也是Linux之所以没有占领整个天下的根本原因。至于哪些特性是Linux的软肋,我并不想多说,毕竟我还是Linux的死忠。
http://www.cnblogs.com/MYSQLZOUQI/p/4233630.html
GNU_LIBPTHREAD_VERSION 宏
大部分现代 Linux 发行版都预装了 LinuxThreads 和 NPTL,因此它们提供了一种机制来在二者之间进行切换。要查看您的系统上正在使用的是哪个线程库,请运行下面的命令:
$ getconf GNU_LIBPTHREAD_VERSION
这会产生类似于下面的输出结果:
NPTL 0.34
或者:
linuxthreads-0.10
15.1.2古老而充满活力的进程
有关线程方面知识还有很多,但是本书的目的不在于此。现在我们开始回到正题,说说fork了。
fork在英语中有“分叉”的含义。在Unix世界里是任务分叉的含义,一个任务分成了两个任务,它也是Unix系统的一个系统调用。我们前面将进程比喻为一个个大容器,那么当引入了fork之后,这个容器就像有了生命,变成了可以分裂的细胞,可以一代一代的繁衍下去。
那么将fork比喻为长生剑就一点都不为过。因为自从Unix诞生就拥有这个fork系统调用。如今历经了30多年的不断演进,这个系统调用依旧活力四射,而被众多类Unix操作系统所保留,这其中就包括Linux。屹立30多年而不倒,在这技术日新月异的计算机产业之中,谁能不说它长生?原本死气沉沉的犹如大容器般的进程,引入了fork之后立即拥有了“生命”,怎么能不说它是生的源泉?而如今的多进程系统看似陈旧,却依旧特点鲜明而性能突出,就像一把利剑一样协助程序员们披荆斩棘、开山扩路。进程显然已成为这一类操作系统所固有的优良本质,这又与古龙笔下的《长生剑》所暗喻的“笑”切合的是那样天衣无缝。Fork—就是Linux的饫生剑。
1. 进程的特点
不管怎么说,进程都是现代操作系统的一个最基本的概念。如果用比较学术的话语来描述进程,那么应该是:进程是一个具有独立功能的程序关于某个数据集合的一次运行活动。它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体。它不只是程序代码,还包括当前的活动,通过程序计数器的值和CPU寄存器的内容来表示。
这种学术话语往往是很难让我们这群小老百姓看懂的,那么按照我的理解,进程可以这样描述:
内存-》堆
变量/函数-》栈
(1)进程是一个实体。每一个进程都有它自己独立的地址空间。一般情况下要包括:代
码区、数据区和堆栈。代码区的内容就是CPU执行的代码;数据区存储变量和进
程执行期间使用的动态分配的内存,C程序员比较喜欢管这个叫堆;堆栈区存储过
程调用的指令和局部变量,C程序员比较喜欢管这个叫栈。
(2)进程是一个“执行中的程序”。程序是一个没有生命的实体,CPU赋予了程序有时限
的生命,这样它就成为了一个“活”的实体,我们称它为进程。
(3)虽然程序的“生命”是CPU赋予的,但是这个机会却是人给的。人往往需要使用另
外一个进程(或者执行中的程序)才能让程序执行起来。那么让程序执行的进程,我
们称它为父进程。
(4)进程会继承父进程的一些资源,这就如同孩子要继承父亲的基因一样。当一个进程
的父进程走完了它的“人生路”,那么这个进程就成了一个“孤儿”,我们称它为“孤
儿进程”。
归结起来,进程与线程相比拥有十分显著的特点,那就是:资源独立、主从分明。
2. fork干了什么?
虽然fork和fuck读音很近,但是想说明白fork干了什么可要比说明白fuck干了什么要复杂很多。那我们就从fork()系统调用发生时说起吧。
当程序,更确切的说是进程执行了fork()系统调用,子进程会复制父进程的所有内存页面,并将其载入操作系统为它所分配的那片独立内存中。不难想象,这个拷贝的动作将会非常耗时(相对于CPU来说)。但是,看似很“笨”的Linux,这个时候“精明”了起来,因为它发现这么干不划算。为什么呢?因为谁都不知道fork()之后要干什么,如果是立即退出了呢,或者是执行“exec”系统调用呢(后面会说)?这等于是之前的努力要白费,人家没用啊。于是Linux引入了一种机制——COW,根本就不干这种傻事。
COW的全称是Copy On Write,翻译过来就是“写时拷贝”。也就是当fork发生时,子进程根本不会去拷贝父进程的内存页面,而是与父进程共享。但是这就有一个麻烦,因为进
程的特点是“资源独立”,子进程跟父进程都共享内存了,那不就成了线程了吗?别说,Linux的线程就是返么干的。但是对于进程这么干不行,但是别着急,Linux有妙招。当子进程或父进程需要修改一个内存页面时,Linux就将这个内存页面复制一份给修改者,然后再去修改,这样从用户的角度看,父子进程根本就没有共享什么内存。这个花招就是COW,也就是进程要写共享的内存页面时,先复制再改写。对于线程来说,关掉COW就完事儿了。在这里你就应该能体会出Linux的线程和进程对于内核来说是一样的了吧。差别就在于用不用COW。
采用了COW技术之后,fork时,子进程还需要拷贝父进程的页面表。采用这种设计就是要模拟传统Unix系统fork时的效果。当然,这种拷贝的代价非常的小,对于CPU来说都用不了几个时钟周期,类似nginx这类的高性能服务器系统就是受益于此。
mysql技术内幕InnoDB存储引擎P375
LVM使用了写时复制(copy-on-write)技术来创建快照。当创建快照时,仅复制原始卷中数据的元数据,并不会有数据的物理操作,因此快照创建速度
非常快。当快照创建完成,原始卷上有写操作时,快照会跟踪原始卷块的变化,将要改变的数据在改变之前复制到快照预留的空间里,因此这个原理实现叫
写时复制。而对于快照的读操作,如果读取的数据块是创建快照后没有修改过的,那么会将读操作直接重定向到原始卷,
如果要读取的是创建快照后已经修改过的块,则将读取保存在快照中该块在原始卷上改变之前的数据。
自己理解
快照基于某个时间点,比如2018-4-10早上9点做快照,做快照时候,快照只会拷贝原始卷的元数据,不会拷贝实际数据
当客户端要读取9点之前的数据的时候,那么会将读请求重定向到原始卷上(2018-4-10早上9点之前的数据)
2018-4-10早上9点之后,客户端对磁盘做了写入操作,那么快照会把客户端写入的那个数据块在原始卷上拷贝过来快照,并写入数据
当客户端要读取9点之后写入的数据的时候,那么会将读请求重定向到快照(2018-4-10早上9点之后写入的数据)
缺点是:不能删除原始卷,因为原始卷的数据还没有全部拷贝到快照
COW
copy on write
copy-on-write


lvm也有COW
但是还有一种情况需要说明,就是fork()之后进行execve()调用P530。这种用法跟Windows的CreateProcess()有点像,它们的实际效果也是一样的。当然,Linux下真正的多进程编程并不这样用,大多是只使用fork()。其实从本质上看,fork()与Windows的CreateThread()类似,甚至更公平地比较是与NtCreateThread()筹价。所以Linux下的多进程编程与Windows下的多线程编程拥有同等效率。而Linux的多线程设计,由于连COW机制都省略掉了,从这点上看就已经超越Windows了。
当然,我在这里还得给Windows正名一下,不能将它一竿子打死。因为相对于Linux,Windows的设计更有弹性,它是一个多层次的而且更加组件化的一个操作系统。Windows有用许多子系统,我们通常说的Windows只是它的一个子系统,叫Win32或Win64子系统,
所以也就有了WoW( Windows on Windows)的称呼。Windows的其他子系统还包括SFU、Posi和OS2。Windows NT内核也支持COW fork,但是只为SFU (Microsoft’s UNIX envlronment for Windows)所使用。看看这种设计,不服都不行啊,难怪Windows NT之父David Cutler被人称为“操作系统天神”啊(第一次知道,大开眼界)。我们老是拿Linux与运行Win32或Win64子系统的Windows进行对比,实在是太不公平了。
3. 进程的优势
若说一项技术是否先进,从它诞生时间的新旧基本上就能判断了。但是有时候并不一定先进就是好的,有可能是激进的;也不能说原始就是笨拙的,有可能更加可靠。进程就是这样的一个典型例子。它相较于线程出现得更早,给很多人的印象也很笨拙,但是线程在很多时候有些过于激进,而进程则要可靠得多。主要体现在以下几个方面。
第一,由于进程之间完全封闭,这是一种非常典型的面向对象所追求的封装特性。封装强调隐藏,让使用者能够不必关心对象内部的细节,这样也不会导致“善意的破坏”。封装也使得对象内部产生的破坏性行为不会波及无辜。进程将这种封装特性体现得淋漓尽致。其他进程不可能通过什么方便的方法去更改一个进程内部的数据或代码,一个进程由于某些bug导致崩溃也不会对其他进程有任何影响。因为它们所在的物理内存和能访问到的物理内存是完全孤立的。而线程强调数据的共享,这从本质上看就是对封装的一种破坏。很多时候为了避免多个线裎“撕扯”共享数据,不得不使用各种同步机制来“驯服”它们。而且一旦某个线程崩溃了,其他线程也不能幸免遇难,包括它所属的进程本身。所以在大多数情况下,多线程编程都是复杂的,而多进程编程则要简单许多。进程只需要做好自己的事情,崩溃了重新来过就行了。
第二,Linux系统提供了丰富可靠的进程间通信机制。这使得进程与进程之间并不是完全独立老死不相往来的。套用到面向对象的概念就是对象向外的接口。进程也正是如此,可以利用进程间通信技术让两个进程彼此交换信息,也可以做到一个进程操作另外一个进程工作。而利用这种能力,进程之间完全可以像线程那样来交换数据或协调工作,但是完全不需要考虑复杂的同步机制,因为进程并不是通过共享数据来做到这些的。虽然直接共享数据更具效率,但是这点效率的提升并不能弥补由于需要同步而带来的复杂性的代价,而且同步做得太过火,根本就没有并行性可言了。更何况很多进程间通信机制在实现上也不见得比线程的直接内存共享方案差,这个我们在后面还会探讨。
第三,也是最重要的,就是在Linux下进程的执行效率与线程的执行效率基本相当。至于为什么是这样,我们在前面就已经分析过了。就冲着这一点,基本上就没有理白在需要并发或并行运算的情况下不优先考虑进程。而作为更为先进的线程,基本上都是在某些特殊性况下的备选方案。当然,线程也有不可替代的情况,比如完全不需要数据同步的基于UDP协议的大数据量读取应用(流式视频播放器),在这种情况下线程则更为简单、方便且高效。也正是因为如此,Linux才不遗余力地弄出NPTL来。
第四,也是进程所特有的,就是主从分明。所谓主从分明就是说进程有严格的父进程和子进程的概念,而且它们之间有很多的联系。比如父进程可以非常容易地了解到子进程出现问题退出了。利用这种机制就可以采用一种非常简单的方案来缩短系统故障的修复时间。当子进程因为有些因素不能正常继续运行的时候,干脆就直接退出,这时父进程就会感知到并重新启动这个子进程。而且进程退出的行为很多时候都可以不用交给程序来控制,操作系统能够干得很漂亮。充分利用这种机制可以获得很好的系统可靠性。而且程序员可以在很多时候不必去关心一些无关紧要的bug。因为系统会自动利用它那些与生俱来的机制帮你把故障修复时间做到最小,而很多系统只要满足这个要求就足够了。相反,对于线程则没有这样的机制。虽然线程也可以有父/主线程和子线程的概念,但是当有线程发生故障时,波及的恐怕是整个程序,即便有机制让父线程了解子线程已经不行了,也没有机会去修复了。
由此可见,进程在大多数情况下都是具有优势的。这也是它即便古老而如今又依然能够充满活力的根本所在。在需要并发处理或并行运算时,考虑一下是不是多进程能够简化你的设计。与此同时,多个不同程序利用进程间通信机制互相协作来完成一个更富创意的功能,是目前任何机制都无法替代的。而且在未来很长一段时间内都会是这样。
15.1.3多进程程序开发
不管理论说了多少,都不如来上那么一两个实例更有说服力。好,那么接下来我们就看看如何使用这个fork0来完咸多进程程序的开发。
1. Fork()的用法
pid_t >0 父进程
pid_t =0 子进程
pid_t <0 失败
fork0=()系统调用非常简单,其完整定义如下:
pid_tfork (void):
这个调用简单到连参数都没有,只有一个返回值。但是这个返回值却有大文章。因为fork之后程序就会分叉了,这种分叉就导致不同分支的返回值有差别。如果这个返回值是0,那
么则代表这是一个新的分支,也就是传说中的子进程了;如果这个返回值大于0,那么这个就在主干上,也就是传说中的父进程;那么这个返回值要是小于0呢?这个时候是没有分支产生的,也就是调用失败了。大多数的原因就是内存不够用了,或者进程太多系统不让创建了(受物理内存限制或管理员设定)。代码1对fork()系统调用的这种行为进行了很好的描述。
代码1:
#include <unistd . h>
#include <stdio . h>
int main ( int argc, char *argv[] )
{
pid_t pid;
int var = ;
pid = fork ( ) ;
if ( pid < )
printf ( "error in fork! " ) ;
else if ( == pid ) {
printf ( "This is child process, pid is %d\n", getpid() );
var = ;
} else {
printf ( "This is parent process, pid is %d\n" , getpid () ) ;
var = ;
}
printf("var is %d\n", var);
return :
}
代码1在我的电脑中执行结果是这样:
This is parent process, pid is
var is
This is child process, pid is
var is
通过var的值可以看出,最后一个printf()的输出是在两个不同的线程中的。
其实代码1已经验证了前面所说的“复制”这个事实。这首先是因为fork()不需要额外的参数去传递一个类似线程的那种主函数;其次是fork()调用之后,执行的就是后续代码,没有任何迹象表明哪些是父进程特有的,哪些是子进程特有的。至于为什么代码能够执行不同的分支,主要是因为有if语句来判断了它的返回值。此外.对于最后的那个printf(),父进程和子进程都调用,只是var的值完全不同。为了进一步验证这个“复制”的事实,可以看下代码2,它的输出结果会有更好的证明。
代码2:
#include <unistd . h>
#include <stdio . h>
int main ( int argc, char *argv[] )
{
int i = , root = ;
printf ( "r\t i\t C/P\t ppid\t pid\n" ) ;
for(i=;i<;++i) {
if ( fork()> ) {
printf( “%d\t %d\t parent\t %d\t %d\n",
root, i, getppid(),getpid() );
sleep ();
} else {
root=;
printf( “%d\t %d\t child\t %d\t %d\n",
root. i, getppid(),getpid() );
}
}
return ;
}
它在我的机器上执行结果为:
r i C/P ppid pid
parent
child
parent
child
parent
child
其中r列代表是否为根进程;i列是i的值;C/P列描述是子进程还是父进程,ppid是进程的父进程pid; pid列就是当前进程的pid。将这个结果转化成图可能会容易识别,如图

由于进程的“复制”,导致i在子进程中会继承父进程的值,这样在pid为13049中的子进程中i值依然是0而可以继续去创建新的子进程,而pid为13050和13051的子进程则没有了这种机会。而且这个程序能工作,也恰恰是因为“复制”使得for循环在所有进程中都是完整的,可以持续运行。
2. 孤儿进程与僵尸进程
在涉及多进程开发的时候,不得不谈论一下两个特殊类型的进程:孤儿进程和僵尸进程。
所谓孤儿进程,在前面已经说过了,就是没有父进程的进程。但是这样的进程似乎不存在。因为在Linux下要执行一个程序一般都得通过shell、其他进程或init进程。不管怎么样,都需要有一个进程的辅助才能启动一个新的进程。当然,有人说进程启动后作为父进程来创建一个子进程之后退出,这个子进程就是孤儿进程了。事实情况是这样吗?我们只需要稍微修改一下代码2就能验证这个说法。因为代码2中为了确保每个子进程都能有父进程,使用了sleep()系统调用让父进程等1秒再退出。我们只要将它去掉就行了。由于这个修改很简单,我就不提供代码了。况且勤动手是学习Linux的最佳途径,所以我也不想让你浪费掉这个动手的机会。修改后的代码,在我的机器上会得到下面这样的输出:
r i C/P ppid pid
parent
parent
child
parent
child
child
我们已经预想到了,有些子进程的父迸程会退出。从这个输出结果上也有所体现,因为很多子进程的ppid已经发生了变化,但是它们的ppid依然是个1,说明依然有父进程。可见并没有子进程缺少父进程。如果一定要跟这个较劲,那么可以使用“ps axjf”命令来查看系统中所有进程的关系。然后你就会发现,大多数进程的的父进程不是1就是2。如果按照没有父进程的进程才是孤儿进程的定义,那么整个Linux系统中只有两个进程是,分别是init和kthreadd,它们的pid分别是1和2,ppid都为0,也就是没有父进程(不是很严格,0这个进程实际上代表Linux内核本身)。其实这两个进程是Linux系统中最特殊的两个进程init是所有用户进程的“祖先”,而kthreadd是所有内核线程的“祖先”。这个两个进程都有一个特别的爱好,就是喜欢“收养孤儿”。换句话说,所有以这两个进程其中之一为父进程的进程,很有可能就是孤儿进程。我说很有可能,是因为很多进程是它们的亲儿子(也就是它们直接创建的子进程,比如系统守护进程)。idle进程的pid是0
从上述的分析看来,Linux系统中的孤儿进程还是很多的。但是一个世界中有这么多的孤儿却并没有让人感觉到任何凄凉,甚至还那么湍湍的温暖。困为在Linux这个世界中,有一个充满爱心的init和kthreadd,它们温暖着Linux的世界,人类世界要是也有init或kthreadd该多好啊!
守护进程都有二次fork的行为,这是应用程序决定的
例如 memcached这个程序,使用-d选项启动之后 ,在当前shell进程启动memcached进程(当前shell进程id是12356,memcached进程id是15636),这个15636进程
的父进程就是当前shell进程12356,然后15636进程会fork出一个子进程15637,然后自己退出,让init进程接收这个fork的子进程15637,这样就完成了后台进程的创建
http://v.apelearn.com/student.php?view_unit=1087
3.8 rc脚本(以daemon方式启动)
李子岩
第10章 生死与共的兄弟
http://www.cnblogs.com/MYSQLZOUQI/p/5240409.html
④由于Linux的内核是一个整体(可以认为Linux内核就是一个大的进程),在它内部产生的多任务分支都叫内核线程(大进程里产生的任务分支只能叫线程了)。内核线程在被映射到用户空间时,很多都是我们通常所认识的进程。
10.5.5 kernel init
如果你查看的是较老的内核源代码,或许找不到kemel init线程所对应的函数。没关系,这是因为较新的内核才这么叫。老的内核都叫init内核线程。不过在我看来新的称呼更加贴切。因为kemel—init内核线程实际上是Linux系统最为重要的init进程的内核部分。新的称呼更能体现它是在内核中这个特性。这个是Linux系统的第二个进程④,这也是init进程的pid -定是1的由来。而且在最新的内核代码中,由于必须在创建kemel init之前创建另外一个内核线程来做一些重要的事情,则不得不先创建kernel init,并把它锁起来。然后再创建新的内核线程,然后kemel_ init等到它执行完后解锁继续执行。如果不这么做,init进程的pid就会是2。那样的话,接下来所有的程序都可能会变的很2了。
ps axjf|grep kthreadd USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
? - S : [kthreadd]
孤儿问题在Linux世界中解决得非常好,但是还有一个可怕的东西存在,那就是僵尸进程。它时刻都在威胁着Linux系统的祥和与安宁。
僵尸进程很可怕,我提供一段代码来解释什么是僵尸进程。见代码3所示的内容。
代码3:
#include <unistd . h>
#include <stdio . h>
#include <stdlib . h>
int main ( int argc, char *argv[] )
{
pid_t pid;
while() {
pid_t pid=fork();
if(==pid) {
printf( "This is child process. pid is %d\n”, getpid() );
exit ();
} els{
sleep();
}
}
return :
}
从表面上看,这段代码并没有什么异常的地方。它只不过是循环的去创建进程,但是每个新创建的进程很快就退出了,也并不会产生什么内存或资源泄漏的问题。但是一个潜在的危机正在爆发,那就是僵尸们已经占领了你的后院,可是植物们还没有发现它们。
要想发现这有什么问题,可以借助“ps ux”命令来观察。这段程序执行一段时间后,我
的电脑中会有这样的进程信息:
Z:僵尸进程
+:前台进程 defunct 死的
......
jagen 0.0 0.0 pts/ S+ : : . /fork_zombie
jagen 0.0 0.0 pts/ z+ : : [fork_zombie] <defunct>
jagen 0.0 0.0 pts/ Z+ : : [fork_zombie] <defunct>
jagen 0.0 0.0 pts/l Z+ : : [fork_zombie] <defunct>
jagen 0.0 0.0 pts/l z+ : : [fork_zombie] <defunct>
有一个进程的状态是我之前没有介绍过得,就是“Z”这个状态。你试图使用kill命令来杀掉它们是不可能的。而且你运用上所有能查到的杀死进程的办法都对处于这种状态的进程无能为力。当上述程序运行的时间越久,这种进程会越多,如果不去管他,最后整个系统都会充满这种进程,将内存消耗殆尽之后崩溃。这就是僵尸进程。这种进程与我们所了解到的对僵尸的描述非常相似:已经死了,但是躯体在,会伤害人,因为已经死了也就不存在杀死它的说法。如果你是《生化危机》迷,一定会对僵尸恨之入骨。当然,在《生化危机》中你还可以通过爆头、火烧等方法来对付那些僵尸,但是在Linux下你却完全无能为力。
僵尸进程是进程已经死亡,但是没有人去“收尸”而导致的。按照Linux系统的设计,僵尸进程实际上几乎已经放弃了所有内存空间,没有任何可执行代码,也不能被调度,仅仅在进程列表中保留一个位置,记载该进程的退出状态等信息。也正是因为这样,没有什么好的办法杀掉这个僵尸进程。由于最关心子进程退出状态的是创建它的父进程,所以大多数情况下负责给它收尸的就是其父进程。父进程通过使用wait()或waitpid()系统调用来完成这个收尸的工作。但是无论是wait()还是waitpid()都可能导致父进程的阻塞,这样也就失去了多进程并发的意义,所以需要通过一种机制使得父进程在正常工作的时候通知父进程去为它的
某个子进程收尸。这种机制就是SIGCHLD信号。当然,如果父进程对子进程的退出状态不感兴趣,可以选择明确告知系统忽略SIGCHLD信号的方法,让系统给它的子进程收尸。此外,如果父进程退出,也就是说子进程成了孤儿,那么负责给它收尸的就变成了init进程。所以init进程的一项重要工作就是去收尸,可见它是多么的大爱无疆啊!
不管怎么样,获取子进程的退出状态是父进程的大多数需求,所以wait()或waitpid()系
统调用在多进程编程中都是非常重要的,需要掌握如何使用它们。它们的完整定义如下:
pid_t wait( int *status);
pid_t waitpid(pid_t pid, int*status. int options);
SIGCHLD-> 父进程->waitpid ->收尸 ->调用1次收1条尸
其中wait()等价于waitpid(-1,&status,0)。从waitpid()的定义不难看出,第一个参数pid就是要被收尸的子进程的pid,status就是要获取的子进程退出状态。对于options参数,它决定了waitpid()的行为。可见waitpid()要比wait()灵活很多。
虽然waitpid()的第一个参数是子进程的pid,但是我也说过wait()等价于它的一种特殊形
式,就是pid等于-1的情况。这种情况表明要等待所有子进程的退出,具体是哪个子进程可
以通过其获得返回值是不能确定的。当然,一次只能给一个子进程收尸,如果有多个子进程
退出了,则需要多次调用。顺便说一下,这个pid参数还可以是0,那么它对应的同一个进
程组的进程。甚至还可以是小于-1的值,那么它对应的是与这个值的绝对值柏同的gid所对
应的进程组(比如-1024,那么对应的gid就是1024)。有关在程序中如何操作进程组内容,
你可以通过Linux的联机帮助获得。
需要注意的是通过它们获得的status不能直接使用,因为它的内容并不是子进程exit()
调用的参数,也不是main()函数的返回值。要获得有用的信息需要通过若干个宏,比如WIFEXITED。本书不做详细阐述,你可以通过Linux的联机帮助获得这方面的信息。
此外,options参数也比较有用。它有几个可用取值,且可以使用“|”位或操作联合使用,如果不想指定,给它传0就行了。比较有用的一个选项是WNOHANG,它可以使得waitpid()
调用不会阻塞父进程,但是如果子进程没有退出,它也不会起到收尸的效果。一种可能的应用就是能够让父进程去轮训所有子进程的状态,这在很多时候比使用SIGCHLD信号要更好,程序的可读性也会比较好。当然,这个时候pid参数也最好是-1。至于其他的选项,可以通过Linux的联机帮助获得比较详细的介绍。
代码4演示了fork()的一种常规使用方式,你可以拿来将它作为一个多进程开发的框架,大多数情况下都能套来使用。
代码4:
#include <stdio .h>
#include <stdlib . h>
#include <errno . h>
#define PROC_COUNT 3
int create_process( pid_t *pid, int (*proc) ( void *arg ) , void *arg
{
pid_t fpid;
int _code;
fpid = fork ( ) ;
switch( fpid ) {
case :
exit_code = proc( arg );
exit ( exit_code ) ;
case - :
return errno;
default :
*pid = fpid;
}
return ;
}
int child_process( void *arg )
{
int i;
for(i=;i<;++i) {
printf( "process %d, i=%ld.\n", (long)arg. i );
sleep () ;
}
return ;
}
int main ( int argc, char *argv)
{
long i;
pid_t pid [PROC_COUNT] , fpid;
int status;
for ( i = ; i < PROC_COUNT; ++i )
create_process ( &pid [i ] . child_process , (void* ) i ) ;
while () {
fpid = waitpid( -, status, WNOHANG ) ;
if ( == fpid ) {
sleep () ;
continue ;
}
for ( i = ; i < PROC_COUNT; ++i ) {
if ( fpid == pid[i] ) {
create_process ( &pid [ i] , child_process , (void* ) i ) ;
}
}
}
如果不做特殊处理,这个程序将会永远运行下去,甚至对子进程执行kill,也很快会被父进程重新启动。这个程序也不会有僵尸进程产生。
3. 启动外部程序
多进程程序,其实并不仅限于程序本身是多进程的。如果能够启动外部程序而自身依然继续运行,并能够与这个新启动的程序进行合作,也是一种多进程程序开发的思路。这种类型的应用其实更为广泛,我在前面的章节就曾介绍过。
若在程序中启动一个外部程序,需要使用execve()系统调用,它的完整定义是:
int execve (const char*filename, char *const argv[],
char *const envp[] );
该系统调用会执行名称为filename的二进制程序或脚本程序。需要注意,filename必须是程序的完整路径。后面两个参数argv和envp与C的main()函数后面的两个参数相互对应,而且main()函数的完整定义应该是这样:
int main(int argc, char *argv[],char *enxrp[] );
只是这个形式不经常使用。具体的你可以查找有关C语言的权威资料。
execve()比较特别的地方是,它只有在失败的时候才有返回值。那么成功之后呢?很奇妙,新启动的程序与当前进程融为一体了。新启动的外部程序退出,当前进程也会退出。也就是说,在execve()后面有多少代码都不会被执行。代码5说明了这个问题。
代码5:
#include <unistd. h>
#include <stdio . h>
int main(int argc. char *argv[],char *envp[] )
{
char *newargv[] ={ “Is”, “一l” ,NULL};
execve( “/bin/ls”, newargv, envp);
printf("execve calledl \n" );
return :
}
这段代码的执行效果与直接执行“Is—l”命令没有任何两样,而且也不会输出“execvecalled”这个字样(如果你看到了,一定是程序写错了)。
execve()会将其启动的程序与当前进程合并,绝大多数时候都不是我们所期望的结果。最起码执行完外部程序之后我们还希望我们的程序继续执行下去。要解决这个问题,可以使用fork(),在新建的子进程中执行execve()。然后我们的程序就可以继续做别的事情了。如果没什么可干的,也可以使用wait()等待子进程的结束。按照execve()的行为,新建的子进程就是这个新启动程序的进程,所以其退出状态也能通过wait()获得。
顺便说一下,execve()是一个比较原始的系统调用,使用起来还是比较麻烦的,尤其是envp这个参数如果设置不好还会出现一些莫名奇妙的错误。其实Linux的API层还提供了另外5个接口,分别是:execl()、execlp()、execle()、execv()和execvp(),它们都是对execve()的封装,使用上更为简单。你可以通过Linux的联机帮助掌握它们的使用方法。
这么简单的执行一下外部程序,顶多也就是获得一下它的退出状态,显然没有什么实际
用途。但是当引入进程间通信之后,马上就变得有用得多了。虽然在命令行下如何做进程间通信你已经能够熟记于心了,但是如何在程序中进行进程间通信恐怕大多数人还不甚了解。那么我接下来就讲述这个话题。
15.1.4进程间通信的实现
新浪 TimYang http://www.cnblogs.com/MYSQLZOUQI/p/4234005.html
进程接收信号有两种:同步和异步。同步信号比如SIGILL(非法访问), SIGSEGV(segmentation fault)等。发生此类信号之后,系统会立即转到内核陷阱处理程序trap命令,因此同步信号也称为陷阱。异步信号如kill, lwp_kill, sigsend等调用产生的都是,异步信号也称为中断。
其实Linux所提供的进程间通信机制有很多,受篇幅所限不能一一列举。我仅列举一些重要且十分常用的。它们是:信号、管道、I/O重定向、套接字。其他一些同样重要且常用的机制在其他章节也有所涉双,本节将不做复述。
1. 信号
信号是Linux系统中最为原始的一种进程间通信机制,是硬件的中断机制在软件层次上的一种模拟。那么在行为上,一个进程收到一个信号与CPU收到一个中断请求就是一模一样的了。而且也是通过一个数字来区分不同事件的,中断管这个叫中断请求号(IRQ),那么信号就是信号请求号了。
信号是各种进程间通信机制中唯一的异步通信机制。一个进程不必通过任何操作来等待信号的到达,而且进程也不可能知道信号在什么时候会到达。掌握并能理解好信号机制,可以为学习Linux内核模块编程打下良好的基础。
信号的发生主要有两个来源:硬件来源和软件来源。对于硬件来源,一般是按下键盘特殊按键组合或某些硬件故障;对于软件来源,最常见的就是那些发送信号的系统调用:kill()、raise()、alarm()和setitimer(),以及比较新的sigqueue()。
信号有可靠与不可靠的分别。
在早期Unix系统中的信号机制比较简单和原始,如果进程不及时处理就会出现丢失的
情况。此外,进程每次处理完一个信号后,这个信号的处理函数将被系统复位,即之前设置的信号处理函数会失效。为了能够反复处理这个信号,就不得不在信号处理函数的末尼重新向系统申明使用该函数来处理信号。Linux对信号的这种处理机制做了改进,使得信号处理函数始终能用。
随着时间的发展,实践证明信号会丢不是什么好事儿。但是Unix的历史太过悠久,要改变这种现状已经不太可能了,毕竟无数多的应用已经这么用了。但是增加一下新的信号,让它们是可靠的就很好办了,也就是那些信号请求号介于SIGRTMIN和SIGRTMAX之间的信号。需要注意,只有在这之间的信号是可靠的,而且无论采用什么方法都是可靠的。除此之外的都是不可靠的,无论采用什么方法都是不可靠的。可靠信号是通过引入信号队列来实现的,即没有处理过的信号会在队列中,因此不会丢失。
人们还给可靠信号和不可靠信号各起了一个文绉绉的名字:实时信号和非实时信号。毕竟把信号说成可靠或不可靠,在外行眼里还以为是什么不靠谱的东西呢。这名字改得多“实在”啊!
前面说过,信号的软件来源是一些系统调用,那么我们就来认识一下它们。它们的完整定义如下:
int kill (pid_t pid, int sig) ;
int raise (int sig) ;
unsigned int alarm (unsigned int seconds) ;
int setitimer (int which, const struct itimerval *new_value)
struct itimerval *old_value) ;
int sigqueue (pit_t pid, int sig, const union sigval value) ;
Kill()可以向任意进程发送任意信号,pid参数就是目标进程的pid,而sig参数就是具体的信号请求号。之所以使用kill这么可怕的名称,是因为进程在接到大多数信号的默认处理方式都是自毁。kill()的pid参数与waitpid0的pid参数类似,只是前者的范围扩大到整个系统范围,而后者仅是调用者本身的子进程。需要注意的是,当pid等于-1的时候,不会对init进程有任何影响。此外,kill()所能影响的进程也是它有权限访问的进程(root权限可以向任何进程发送信号,非root权限只向相同拥有者的进程发送信号)。
raisel()与killl()十分类似,其实完全等价于kill(getpidl(),sig)。所以不难看出它是向进程本身发送信号。
alarml()只会向进程本身发送SIGALRM信号。这个信号又称为闹钟信号,所以alarm()唯一的参数就是要说明多久以后发送这个信号,时间按秒计。比较有意思的是它的返回值,也是一个按秒计的值。这个值是上一次还没有发出的SIGALRM信号与本次调用的剩余时间间隔。需要注意,如果上次的信号没有发出去,本次的调用会使它永远都发不出去了。
setitimerl()育点类似于alarml()的封装,即当进程收到一个SIGALRM信号之后继续调用alarml()来完成一个定时器的操作。setitimerl()实际上按照不同的需求提供了3种类型的计时器:ITIMER_ REAL、ITIMER_ VIRTUAL、ITIMER_ PROF。ITIMER_REAL类型的定时器采用绝对时间来计时,即只要经过指定的时间就会向进程发出SIGALRM信号;ITIMER- VIRTUAL类型的定时器采用程序运行时间来计时,必须等程序实际运行了指定的时间才会向进程发出SIGALRM信号;ITIMER_PROF介乎于前两种计数器之间,它按照系统处理这个进程的整体时间计时(包含程序本身和操作系统调度它所消耗的时间)。
给setitimerl()设置时间间隔是其第二个参数,第三个参数没什么实际的用途。这是一个有点怪异的结构体,定义如下:
struct timeval {
long tv_sec;
long tv_userc;
};
struct itimerval {
struct timeval it_interval;
struct timeval it_value;
};
怪异就怪异在需要设定一个第一次发出SIGALRM信号酌时间,再设定一个间隔时间。按照大多数人的经验,只需要设置一个间隔时间就满足需要了。所以大多数情况都会将这两个值设置为相同的值。
Sigqueue()是新引入的一个系统调用,也是功能最强大的。前面所介绍的这些仅能发出信号,但是sigqueue()不但能发出信号请求,还会给这个信号附带一份数据。其第三个参数就是干这个的。它是一个联合体,定义如下:
union sigval {
int sival_int;
void *sival_ptr;
};
所以可以附带一个整数或一个指针。如果需要传递复杂的数据结构了,显然需要使用指针了。
发出信号的系统调用基本上算是介绍完了,接下来要看一下如何去处理收到的信号。有两个系统调用来干这事儿,它们是:signal()和sigaction()。
对任何收到的信号,其实进程都会有默认的处理方式,只是这个默认的处理方式有些悲壮,大多都会导致进程退出,看来进程有一些日本的武士道精神。使用signal()和sigaction() kill命令为什麽叫kill
能够改变进程的这种武士道精神。它们的完整定义如下:
sighandler_t signal (int signum, sighandler_t handler) ;
int sigaction( int signum, const struct sigaction *act.
struct sigaction *oldact) ;
2. 管道
在Linux系统中,管道是一种使用非常频繁的进程间通信机制。从本质上说,管道也是一种文件,只是它和普通文件有很大的不同。管道不能像普通文件可似无限大(相对而言),因为管道实际上只是内存中的一个固定大小的缓冲区。在Linux系统中,这个缓存区大小为1个内存页面,即4K字节(32位系统,在64位系统下是1M字节)。当这个缓冲区满的时候,再向管道中写入数据就会被阻塞,直到缓冲区中的内容被读取出来有了空闲的地方,写操作才继续进行。与此相反,如果这个缓冲区空的时候,从管道中读取数据也会被阻塞,直到缓冲区有内容之后,读操作才能继续进行。需要注意的是,管道是单向的,即只能向一端写,从另一端读;管道中的数据也是一次性的,即一旦有人读取,其他人就读不到了。也正式因为这些特点,数据就象水在水管中流淌一样,从水管流向水龙头,水龙头关上了,水管的水也就不流了。管道也因此而得名。
在命令行下如何使用管道在本书开头的章节中就已经介绍了。在这里我将向大家介绍如何在程序中使用管道。在程序中是通过pipe0系统调用来创建管道的,它的完整定义如下:
int pipe (int pipefd[]);
Pipe()调用成功之后会返回两个文件描述符,一个用于读,另一个用于写。这两个文件描述符通过pipe()这个奇怪的参数来获得,这个参数正好是一个拥有两个元素的整形数组。pipefd[0]倮存用于读数据的文件描述符,pipefd[1]则保存用于写数据的文件描述符。
既然管道的本质是文件,就可以利用write()和read()这两个系统调用来读写数据了。代
码6演示了两个进程通过管道来传递数据。
代码6:
#include <s tdio . h>
#include <stdlib . h>
#include <unistd . h>
void child ( int fd )
{
int i = ;
For(;;) {
++i;
write ( fd. &i. sizeof ( i ) ) ;
sleep () ;
}
}
int main ( int argc, char *argv [ ] )
{
pid_t pid;
int pfd[] , i;
long data;
pipe( pfd);
pid = fork() ;
if( == pid ) {
close( pfd[] ) ;
child( pfd[] ) ;
exit () ;
}
close ( pfd[] ) ;
For (i=;i<;++i) {
read( pfd[] , &datar sizeof ( data ) );
printf ( "data: %ld\n". data ) ;
}
kill ( pid, ) ;
waitpid( pid, NULL, O );
return ;
}
这段代码能够正确执行,依然是基于进程“复制”原理的。子进程完全复制了父进程的管道文件。这个时候,无论是在父进程还是在子进程中向管道中写入数据,它们都能从管道另一端读取数据。显然,通过这种简单的机制,就可以通过创建一个管道的方法,使得子进程和父进程互相交换数据。但是根据管道的特性,谁先去读取数据,数据就归谁了,会使得父子进程需要同步读写才不至于弄丢数据。而且我们的实际需要是子进程向管道中写入数据,父进程从管道中读取数据。那么我们就在父进程中关闭管道的写入端,在子进程中关闭管道的读取端。一来是节省资源,二来避免不必要的麻烦。即便真的需要利用管道来进行父子进程的通信,也建议使用两个管道来避免逻辑上的复杂性。
3.I/O重定向
在命令行中使用管道其实还隐含了I/O重定向的应用,即将管道前端进程的标准输出重定向到管道后端进程的标准输入中。这样的机制也可以通过程序来完成。而且这种I/O重定向机制也不仅仅是只能使用管道的,利用其他方法也能完成,比如套接字。
进行I/O重定向需要使用dup20这个系统调用,它的完整定义如下:
int dup2(int oldfd. int newfd);
这介系统调用会将newfd关闭,然后将它做成oldfd的拷贝。dup2()调用成功的前提是
oldfd必须有效。因为如果oldfd无效,这种复制行为也就是无效,newfd也就白白地被关闭了。此外,如果newfd和oldfd相同,dup2()虽然不会调用失败,但是也是无意义的。
Dup2()之所以能够实现I/O重定向,就是因为这种复制机制。比如我们有两个打开的文
件A和B,对应的文件描述符分别是oldfd和newfd。当调用dup2()后,newfd被关闭且变成了oldfd的拷贝,此时再通过newfd向文件B中写入数据,实际上写的是文件A。这就相当于是将文件B的写操作重定向到文件A了。依此类推,读操作也重定向到A了。既然标准输入和标准输出也是两个文件,那么利用此方法就可以将它们重定向到任意文件,包括管道甚至网络。
代码7对代码5进行了修改,结合代码6并加入I/O重定向,使得我们能够获得”Is一l”命令的输出。
代码7:

#include <stdio . h>
#include <stdlib . h>
#include <string . h>
#include <unistd . h>
#define BUF_SIZE 1024
void child ( int fd, char *envp [ ] )
{
char *newargv [ ] = { "ls " , “ -l" , NULL } ;
dup2 ( fd, STDOUT_FILENO) ;
execve ( " /bin/ls " , newargv, envp ) ;
}
int main ( int argc, char *argv [] , char *envp [] )
{
pid_t pid;
int pfd[] ;
char *buf [BUF_SIZE+] ;
pipe ( pfd ) ;
pid = fork() ;
if( == pid ) {
close (pfd[] ) ;
child( pfd[l] . envp ) ;
exit () ;
}
close (pfd[] ) ;
for(;;) {
memset (buf, , BUF_SIZE + ) ;
if ( == (read (pfd[] , buf, BUF_SIZE))) {
break;
printf ( "%s", buf ) ;
}
waitpid( pid,NULL, );
return :
}
虽然这个例子从执行的效果上看,与代码5没什么两样。但是只要将printf()那条语句注视掉,就得不到任何输出了。这是最好的佐证。顺便说一下,使用C语言编程为了实现代码7的效果其实完全没有必要这样庥烦,使用popen()这个函数就能够搞定一切:)。
15.2 离别钩:VFS
《离别钩》是古龙晚期作品,算是《七种武器》中写得最好的。故事是在二元对立的参差之美中展开的:狄青麟是世袭一等侯、天下第一风流侠少;杨挣是江湖大盗的后人、县衙的小捕头。杨挣有力量对抗狄青麟的阴谋吗?狄青麟一身白衣如雪,用温柔多情方法杀人,他拥有一座巨宅,却没有“家”。他是大恶中的大恶、大奸中的大奸,但与《笑傲江湖》中的“君子剑”岳不群有天壤之别。岳不群坏得让人厌恶,狄青麟坏得让人欣赏,因为那是一种近乎本色的坏——他别无选择,那就是他的命运,他的生活。他杀朋友,杀情人,杀师父,因为他只爱他自己,他心中本来就没有朋友、情人和师父。杨铮昵,命贱如泥土,他有爱,有决心,面对外来的压力,他没有屈服,也没有崩溃。他拿起了离别钩——“你为什么要用如此残酷的武器?”“因为我不愿被人强迫与我所爱的人离别。”……“你用离别钩,只不过为了要相聚。”最后,杨挣的离别钩战胜了狄青麟的薄刀。
就因为要相聚,杨挣胜利了。Linux也是因为要相聚,所以它也胜利了,而且还是绝对的胜利。因为没有任何一款操作系统能够像Linux那样支持如此之多的完全不同的文件系统。Linux的武器就是VFS,而这一切的动力都是因为一句口号……
15.2.1 一切都是文件
本书在前面就介绍过,在Plan9咐代Unix就有了一句“震人心脾”的口号:一切都是文件,也就是说不管是普通的文件、硬件外设甚至是网络,在Unix中都会被当成一个文件来看待。从磁盘上读取文件数据,从鼠标、键盘等硬件外设获得输入,接收来自网络的数据等,都可以看作是从“文件”中读取数据;把数据保存在磁盘上的文件里,将文字显示在屏幕上,播放音乐和电影,通过网络给大洋彼岸的友人传递信息等,都可以看作是向“文件中”写数据。这个高度统一的接口让人与计算机打起交道来十分地爽快和便利,因为人不需要知道实际操作的是什么,只要使用系统提供的read或write接口就能搞定。这么牛B的特性,Linux哪有不去“山寨”它的道理?
但是,不管是保存在磁盘上的真文件也好,还是代表硬件外设的假文件也罢,更不用说网络这种没边儿的文件多么让人“春心荡漾”,要将它们这么高度统一地抽象在一起,可不是一件容易的事儿。更何况Linux还是一个很有“量”的操作系统呢?
你可能要问,说Linux有“量”该从何说起呢?答案应该是显而易见的,Linux本身就能支持近百种不同的文件系统这是事实,Linux支持的特种文件系统有多么千奇百怪也是本书前面讨论过的重点,而且Linux逐有尽早进入用户空间的远大抱负,你能说这不是有“量”吗?那么Linux是怎么做到这么有“量”的呢?因为Linux有一颗能够不断生长的“树”……
15.2.2一棵有生命的“树”
如果你没有跨章节看书的习惯,那么到了这里应该已经读完了第3章一棵“树”的奥秘,那么承载着Linux操作系统及其所有软件和数据的这棵“树”长什么样应该有所了解了。如果你真的喜欢跨章节看书的话,那么就请你现在转到第3章,这里我们还要继续看一看这棵“树”,因为这是一颗能够不断生长的树。
最近这几年磁盘技术发展得快,100G、200G、500G、IT、2T这样地翻着翻儿地涨容量,但是说Linux有一棵能够不断生长的“树”跟这事儿没关系。因为换了磁盘就等于这颗“树”就死了,顶多是换成了一棵更大的“树”,跟生长没有关系。但是为了保持Linux这棵“树”活着,没人拦着不让你再添加新的磁盘。要使用这个新添加的硬盘怎么办呢?显然很好办啊,mount嘛,你早就知道了。是不是mount之后,Linux这棵“树”上就长出了新的“枝叶”了?答案显然是肯定的。看,生长了吧!
可以让Linux这棵“树”生长的方法不止是添加新的磁盘。在“一切都是文件”这个口号的驱使下,您添加一个声卡Linux的这棵“树”会长一点,您插入一个U盘Linux这棵“树”会长一点,甚至你执行一个程序Linux的这棵“树”都会长一点……这个现象在第9章也详细地探讨过了,没看的现在就看看吧。
可以说Linux的这棵“树”是随时随地都在生长的,当然也有“死掉”的枝叶,那么更为确切的描述就应该足有新陈代谢了。有新陈代谢不就是生命了吗?这时,Linux的这棵树是“活”的,有生命的。这一切都是因为VFS。那么接下来我们就看看VFS如何工作的吧。
15.2.3 VFS简介
VFS是一种软件机制,它的全称并不是大多数人想象的Virtual File System,而是Virtual Filesystem Switch,翻译过来就是虚拟文件交换系统。VFS负责Linux的文件系统的管理,所以更为正式的叫法应该是Linux的文件管理子系统。
Linux的这种文件管理子系统比较特别,它是虚拟的,也就意味着它并不直接跟真正的磁盘文件有任何关系,或者说与VFS有关的数据结构只存在于物理内存中。这并不是我在忽悠,这是事实。这些数据结构在使用的时候就建立,不用的时候就删除。也就是因为这样,才能让Linux的这颗“树”拥有生命,让人们看起来它是“活”的。
当然,如果只有VFS,Linux系统是无法工作的。因为它的这些数据结构不能凭空捏造出来,必须与具体的文件系统相结合,如ext4、btrfs、procfs等,才能够开始实际的工作。为了与VFS这种“虚拟”的文件系统相对应,我们将ext4、btrfs、procfs等称作实体文件系统。
在Linux内核的运行过程中,在执行具体文件操作的时候,所有其他子系统只会与VFS打交道,都是由VFS转交给具体的实体文件系统完成的。从这个角度上看,VFS是所有实体文件系统的管理者,也是内核其他子系统的通用文件处理接口。图15.2清晰地描述了VFS在Linux内核中的逻辑关系。



VFS既然要作为一个通用的文件处理接口,那么它就必须制定一个统一的规范来要求所有实体文件系统去遵循。做这种规范的一个最简单的做法就是面向对象的多态机制——VFS提供接口定义,实体文件系统去实现具体的接口。VFS就是采用这种方式,只是多态机制被C++这类面向对象的语言做了内在支持,而Linux内核使用C语言开发就需要使用一些技巧了。
具体的技巧我们这里就不说了,大家可以从很多地方了解到。接下来我们结合一个实际例子来展示VFS在Linux内核中所处的位置。而这个例子并不是那些常规的文件系统,而是网络应用中的非常重要的socket。在开始讲述之前,我们先来了解VFS的一些基本数据结构。
15.2.4基本数据结构
VFS中有4种主要的数据结构,它们是:
1. 超级块( superblock)对象
用于保存系统中已安装的文件系统信息。对于基于磁盘的实体文件系统,超级块对象一般对应于存放在磁盘上的文件系统控制块。也就是说每个实体文件系统都应该有一个超级块对象。
2. 索引节点(inode)对象
用于保存具体文件韵一般信息。对于基于磁盘的文件系统,索引节点对象一般对应于保存在磁盘中的文件控制块(FCB)。也就是说每个文件都应该有一个索引节点对象。每个索引节点对象都有一个索引节点号,用于唯一标识某个实体文件系统中的一个具体文件。
3. 目录项(dentry)对象
用于保存文件名、上级目录等信息,正是它形成了我们所看到的Linux这棵“树”。目录项对象完全是在内存中的,会根据实际需要动态建立。
清空缓存:
echo >/proc/sys/vm/drop_caches
4. 文件(file)对象 文件描述符/句柄
用于保存已打开的文件与进程之间进行交互的信息。这类信息也是完全保存在内存中的,且仅当进程访问文件期间才有效。也就是说,当进程打开文件就会创建一个文件对象,当进程关闭文件,对应的文件对象就会被释放。
其中每种对象都包含一个操作对象,依次为super_operations、inode_operations、dentry_operations,以及file_operations。我们的文件系统只需要实现对应四个对象的操作方法,然后把它们注册到内核就可以了。
15.2.5 sockfs
这部分理解上有点难度,还需要分析几个数据结构。
第一个就是file_system_type结构:
struct file_system_type{
const char *name;
int fs_flags;
//get_sb最关键的函数,用来得到文件系统的超级块。
int (*get_sb) (struct file_system_type*,int, const char*,void*,struct
Vfsmount*);
void (*kill_sb) (struct super_block*);
......
};
这个结构表示了一个文件系统。
然后就是vfsmount结构:
struct vfsmount {
struct list_head mnt_hash;
struct vf smount*mnt_parent; /* fs we are mounted on */
struct dentry *mnt_mountpoint; /*dentry of mountpoint*/
Struct dentry *mnt_root; /*root of the mounted tree*/
Struct super_block *mnt_sb; /*pointer to superblock*/
Struct list_head mnt_mounts; /*list of children. anchored 锚点 抛锚here*/
Struct list_head mnt_child; /*and going through their mnt_child*/
int mnt_flags; /* bytes hole on 64bits arches*/
Const char *mnt_devname; /*Name of device e.g. /dev/dsk/hdal*/
Struct list_head mntlist;
Struct list_head mnt_expire; ,*link in fs-specific expiry list*/
Struct list_head mnt_share; /*circular listof shared mounts*/
Struct list_head mnt_slave_list;/* list of slave mountS*/
struct list_head mnt_slave; /* slave list entry */
struct vfsmount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace */
atomic_t ___ mnt_writers ;
......
};
它描述的是一个独立文件系统的挂载信息,表示了一个安装点,换句话说也就是一个文
件系统的实例。每个不同挂载点对应一个独立的vfsmount结构,sockfs文件系统的所有目录和文件隶属于同一个vfsmount,该vfsmount结构对应于该文件系统顶层目录,即挂载目录。如果文件系统是sockfs文件系统,type->get_sb实际上就是sockfs_get_sb,它就是把sockfs_ops所属的super_block结构挂接到全局链表super_blocks中,通过这么一个操作,形成了<super_block,sock_fs_type,sockfs_ops>三元组,这样协议栈与用户层的连接关系就基本确定了,Linux酌socket文件系统就建立起来了。
第三个是files struct结构:
struct files_struct {
//大部分只读
atomic_t count;
struct fdtable *fdt;
struct fdtable fdtab;
//SMP独立cache上可写部分
spinlock_tfile_lock____cacheline_aligned_in_smp;
int next_fd;
struct embedded_fd_set cloSe_on_exec_init;
struct embedded_fd_set open_fds_init;
//文件结构体代表一个打开的文件,
//系统中的每个打开的文件在内核空间都有一个关联的struct file
struct file*fd_array [NR_OPEN_DEFAULT];
};
它主要是为每个进程来维护它所打开的句柄。需要注意的是fd_array和fstable中的fd的区别。当进程数比较少也就是小于NR_OPEN_ DEFAULT(32)时,句柄就会存放在fd_array中,而当句柄数超过32时就会重新分配数组,然后将fd指针指向它。我们通过fd就可以取得相虚的file结构。提醒一下,files_struct是每个进程只有一个的。
file_structs里面使用到fdtable结构如下:
struct fdtable {
unsigned int max_fds;
struct file**fd; /*current fd array*/
fd_set *close_on_exec;
fd_set *open_fds;
struct rcu_head rcu;
struct fdtable *next;
};
通过以上四个结构我们大致了解了Linux文件系统的组成。Linux的文件无处不在,设备有设备文件,网络有网络文件……Linux以文件的形式实现套接字,与套接字相应的文件属于sockfs特殊文件系统,创建一个套接字就是在sockfs中创建一个特殊文件,并建立起为实现套接字功能的相关数据结构。换句话说,对每一个新创建的BSD套接字,linux内核都将在sockfs特殊文件系统中创建一个新的inode。
[root@steven ~]# df -iTH
Filesystem Type Inodes IUsed IFree IUse% Mounted on
/dev/mapper/VolGroup-lv_root
ext4 1.2M 199k 961k % /
tmpfs tmpfs 128k 128k % /dev/shm
/dev/sda1 ext4 129k 128k % /boot
从df -iTH看,所有文件系统都有inode,包括tmpfs和sockfs,所有文件系统都有superblock,因为执行df命令都能很快出结果无论当前系统挂载了多少种文件系统
http://www.cnblogs.com/MYSQLZOUQI/p/5252245.html
[root@localhost /]#ls –id /
2 /
[root@steven ~]# ls -id /boot
2 /boot
由此可知,根目录的inode值为2。
利用ext3grep恢复文件时并不依赖特定文件格式。首先ext3grep通过文件系统的root inode(根目录的inode一般为2)来获得当前文件系统下所有文件的信息
15.3孔雀翎:mmap(内存映射)
古龙笔下的《孔雀翎》是一种早已不存在的暗器,高立向朋友秋风梧借来孔雀翎,信心十足地杀了强敌之后才发现孔雀翎已经丢失。而秋风梧告诉他,其实孔雀翎早就没有了,他借给高立的只是“信心”。“真正的胜利,并不是你用武器争取的,那一定要用你的信心。无论多可怕的武器,也比不上人的信心。”
我将Linux的mmap对应为孑L雀翎,因为它似有似无,小巧而“致命”。很多时候你并不知道它到底能干什么,但是只要你有足够白信的理念,一切事情忠于自己的内心、洒脱面对一切,或许会有你意想不到的事情发生。
真的是这样吗?那我们就看看mmap是否真跟你想象的一样……
15.3.1 理解mmap
提起mmap,大多数了解它的程序员马上就会想起一个很牛X的名词——内存映射文件。为什么会这样呢?因为在这个还是由Windows主宰的桌面电脑世界里,Windows已经向程序员们传达了足够丰富的知识,这其中就包括内存映射文件,而且还说这种方法能够加速文件的读写。当这些程序员转向Linux开发的时候自然就会去对号入座,发现Linux也有内存映射文件这个东西,而且就是通过mmap0这个系统调用来实现的。那么按照在Windows下养成的惯性思维,自然就会认为mmap0只是用来干这个的,因为Windows就提供了一个专用API-CreateFileMapping()来做这事儿。而且mmap()系统的一个参数也是文件描述符,这就更加肯定了这种想法。
如果大家都持有这种想法那将是很悲剧的事情,因为这等于没有真正掌握Linux到底怎么用,也就无法真正发挥Linux的威力了。
实际上,mmap是一种机制,是Linux进行虚拟内存管理的核心机制。表面上看mmap
能够让用户将某个文件映射到自己程序地址空间的某个部分,使用简单的内存访问指令就能对这个文件进行读写。实际上,这就是Linux内核本身的组织模式。换句话说,Linux内核将其整个内存地址空间看作是一系列不同“文件”的映射,只是在这里它们有另外的名字——内核对象。再进一步说,Linux加载内核的过程,就是做内存映射的过程。甚至加载可执行文件也是利用内存映射完成的。根据这个事实,有人应该可以推论出:Linux的内核文件以及可执行文件的结构,应该与它们在内存中的结构是一样的。
Linux为什么要这么做呢?
先来看看读写文件的传统方法有什么毛病吧!如果按照传统的方式来读写文件,首先必须使用open()系统调用打开这个文件,然后使用read()、write()以及lseek()等系统调用进行顺序或随机的读写。这种方式的效率是极其低下的,因为每一次读写都要进行一次系统调用,
毕竟浪费掉这么多无用的CPU时钟还是说不过去的。另外,如果有许多进程访问同一个文件,
那么每个进程都需要在自己的地址空间维护一个副本,这又是一种极大的资源浪费,即
使内存已经是白菜价了浪费掉也很可惜。当然,举这个例子有点牵强,毕竟不同的进程读写
一个文件,如果不想有“灵异事件”发生,还真得搞几个副本出宋。那么作为一个进程肯定
是要有一个程序文件与它对应的这种事儿前面已经说过了。Linux作为一个支持多进程的操
作系统,一个程序文件搞出几个甚至几十个进程出来也不是什么难事儿。作为进程,除了数
据会变化外,代码肯定是不会变的,否则就中毒了。那么每个进程在内存中都有这么一个程
序文件的副本,就真的太浪费了。
用mmap读写文件就没有传统方法的那些毛病!因为它把文件当作内存来看待。利用
mmap,对一个文件做普通的读写,跟读写内存没什么两样,都是一些指针的操作,根本不
需要管什么系统调用,自然就不浪费CPU的时钟了。另外,由于mmap玩的是虚拟内存,虽然不同的进程看到的内存区域可能不同,但那毕竟是虚的,实际的物理内存区域可以是一
个,这可就是实在的了。不但多个进程访问同一个文件可以不用维护多个副本,多个进程本
身也不需要多个副本,自然就不浪费“宝贵”的内存了。此外,由于Linux 一直都秉承着一
切皆文件的方针来做事情,那么将设备文件做内存映射,就使得对设备的控制像访问内存那样简单,也避免了I/O操作,从而提高了系统的整体效率。
有些人可能会疑惑,mmap怎么能把文件当作内存使呢?要回答这个问题,就要搞清楚
什么是虚拟内存。接下来我们就看看虚拟内存是个什么玩意儿。
15.3.2虚拟内存技术
虚拟内存应该是大多数程序员们所耳熟能详的计算机科学中的一个基本概念。但是真要较起真儿来,还真没有几个人能说清楚这个虚拟内存到底是怎么回事儿。很多人还很奇怪,为什么Linux进程的起始地址都是一样的,它们怎么就不互相“打架”呢?电脑的内存只有2G,可是每个进程都有4G的虚拟内存,而且有好几十个进程一起跑,2G怎么够用呢?原因就是虚拟内存是“假”的,跟实际的物理内存不是一回事儿。
大部分人是在学习操作系统原理的时候了解到虚拟内存这个概念的,但是虚拟内存与操作系统本身并没有多大关系。虚拟内存是CPU的硬件特性,而操作系统要负责的是对它的管理。如果某个CPU不具备虚拟内存的特性,操作系统即便支持对虚拟内存的管理也是白搭,它管谁呢?
虚拟内存是能够开发出多任务操作系统的关键特性,所以对于一个不支持虚拟内存的
CPU来说,是很难在它上面运行多任务操作系统的。但是有人会说:现在都是21世纪了,还有不支持虚拟内存的CPU?是的,就是有不支持的。不要说还是8位的C51单片机了,就连32位的ARM7都不支持虚拟内存。之所以还有这样“落后”的东西存在,是因为不管技术有多么进步,基本的经济学原理几千年都没变,成本决定一切!无论实现虚拟内存的硬件有多么简单,总是需要成本,更何况实现虚拟内存并不是简单的事情。对于一个支持虚拟内存的CPU,往往都是利用一个独立的模块来完成的。按照行业术语,提供虚拟内存支持的CPU模块叫内存管理单元,即Memory Management Unit,简称MMU。
那么MMU都做了什么事呢?我们拿最常见的x86 CPU做介绍。出于简单起见,这部分内容我不淮备介绍64位的情况。如果有人对64位的虚拟内存管理感兴趣,可以参考Intel
的技术手册。
在历史上,实现虚拟内存技术主要有两种方案:段式内存管理和页式内存管理。这两种方案只有一个目的,就是让多任务操作系统能够将多个进程的地址空间保护起来,让它们相互隔离,使得它们不会互相“打架”。我们耳熟能详的“保护模式”这种叫法也就是来源于此。
段式内存管理就是将整个内存划分成大小不同的段,每个进程的地址空间处于不同的独立的段中,这样就可以实现进程地址空间的相互隔离。页式内存管理则将整个内存划分成许多大小相等的页面,每个进程的地址空间可以由多个页面构成,同样可以实现进程地址空间的相互隔离。至于段式内存管理和页式内存管理孰好孰坏,本书不做讨论。但目前主流的CPU和操作系统,都不约而同的采用了页式内存管理,这其中的好坏也就不言自明了。
从大的方向上看,主流的操作系统支持的都是页式内存管理,那么CPU也就势必要支
持页式内存管理。至于段式内存管理则是可选的。但是x86系列CPU在这方面一直很坑爹,因为它采用了一种非主流设计:页式内存管理是构筑在段式内存管理之上的。也就是先要对内存进行分段,然后在分段的基础上再分页,话说段式内存管理和页式内存管理是完全独立的方案,弄在一起实在是不伦不类。唯一合理的解释就是x86系列CPU需要向前兼容,但是我就是想死也想不通有谁会用i7去跑DOS。
x86系列CPU的段式内存管理在其页式内存管理上横插这么一刀,实在是多余也可恨。
但上有政策,咱下有对策。当前所有主流的操作系统都采用了一个小窍门,将它的段式内存管理给“废掉”了。方法就是将整个内存划分成一个段,然后再进行页式映射。这样该死的段式内存管理就是透明的了。当然,这也就有了“线性地址”这个新名词。内存的真实地址叫物理地址,直接做段式内存管理或页式内存管理所使用的内存地址叫虚拟地址,而这种将
整个内存划分成一个大段的段式内存管理所使用的地址则叫线性地址。虽然线性地址跟物理
地址是等值的,但是为了加以区分,给它起个新名词还是有好处的。
线性地址是个中间概念,基本没谁使用。但是虚拟地址和物理地址则是最为常用的。若
要让一个程序能够成为进程,虚拟地址和物理地址必须有关联。下面我们就看看在页式内存
管理下它们是怎么关联的。
一个32位的x86系列CPU的虚拟地址,在二进制层面被划分成三个不同的区域:页面目录、页面表和页内偏移。
具体见图15.3所示:

页面目录和页面表都是数组,页面目录的元素就是页面表,而页面表的元素就是页面了。
由于页面目录和页面表都是使用10位二进制来表示的,那么也就代表数组的元素最多只有
1024个。页面偏移使用12位二进制,则说明一个页面最多可以有4096个字节,而实际上
一个页面就是固定的4096字节,也就是4K。
页面表是页面目录的元素,那么只要知道页面目录在哪儿就行了。可是页面目录在哪儿
呢?答案是在CR3寄存器中。当然,作为32位的CPU,寄存器不可能太大,也是个32位的。所以CR3寄存器中保存的内容并不是整个页面目录,而是页面目录的指针,页面目录实际上是在内存中。页面目录在保存页面表的时候也不可能每项都保存一个完整的页面表,采用的也是指针。那么页面目录也就需要4096个字节来保存了,正好一个页面。
按照这种推理,页面表的元素是不是就是页面的指针了呢?答案是否定的,因为如果这样,页内偏移就有些多余了。实际上页面表中的元素是一个复杂的结构。当然,这个结构一共占有32位,整个页面表也是4096字节,正好是一个页面。更进一步说,对于页面目录,
由于每个页表必须是页面对齐的,那么只需要20位的地址就能够确认页表地址了(低位都为0即可),那么也可以利用剩下的位来做点事情。Intel真就这样干了,而且页面目录与页面表的结构基本完全相同。具体的可参考图15.4所示:
 虚拟内存中的页表项结构
虚拟内存中的页表项结构
P位是存在( Present)标志,用于指明页面是否在内存中。1则表示在内存中;0表示
不在内存中。当这个标志为0的时候,要访问这个页面就会引发缺页异常,利用这个异常就可以将页面从磁盘中换入内存,然后置该位为1。这实际上就是页面交换的实现原理,mmap能够将文件映射到内存也是基于此。该位对于页面目录有类似的效果,当它为0时,则表明页面表不在内存中。通过页面交换,可以将这个页面表从磁盘中交换到内存中。
R/W位是读/写(Read/Write)标志位。如果该位为1,则表示页面可以读、写或执行。如果为0,表示页面只读或可执行。当CPU运行于特权级(ring0、1、3)时,该位不起作用。页面目录中的RJW位对其所管辖的所有页面都起作用。
U/S位是用户,特权(User/Supervisor)标志。如果该位为1,那么任何程序都可以访问该页。如果该位为O,那么这个页面就只有运行在特权级上的程序才能访问,这样的程序通常都是内核或驱动程序。页面目录中的U/S位对其所管辖的所有页面都起怍用。
A位是已访问( Accessed)标志位。当处理器访问页表项映射的页面时,该标志位就会被置1。当处理器访问页面目录所管辖的任意页面时,对应的页面目录项的这个标志就会被置1。CPU只负责设置该标志,操作系统可通过定期地复位该标志来统计页面的使用情况。
D位是脏(Dirty)页面标志位。所谓的脏页面就是被修改过的页面。当处理器对一个页面执行写操作时,就会设置该标志位。CPU不会修改页面目录中的D位。对于缓存式I/O,操作系统可以利用该位将被修改过的内容同步回磁盘。
AVL字段则保留给专用程序使用。CPU不会修改这几个位,以后的CPU也不会。但是我还真不知道哪个程序用了这几个位。如果有知道的请联系我。
那么CPU的MMU是如何将程序发出的虚拟地址,最终落实到物理地址上的呢?操作系统在组织进程的时候,就会为其准备好页面目录和页面表。在调度到这个进程的时候,会将它的页面目录地址装入CR3寄存器。这样,当程序给出一个虚拟地址,MMU就会从CR3中找到这个进程专有的页面目录,利用虚拟地址中的页面目录位找到页面表的地址。然后MMU继续利用虚拟地址中的页面表位,找到具体的一个页面。最后,MMU就按照虚拟地址中的页面偏移位,定位到具体物理内存的一个地址上了。是读、是写还是执行,就看程序怎么要求了。为了更形象地展示这个过程,我准备了图15.5。正所谓一幅好图顶上一万字,是不是这样,留给大家去品味吧。

虚拟地址《=》物理地址
Windows虚拟内存




16G物理内存+4G虚拟内存刚好20G虚拟内存

那么根据这种虚拟地址到物理地址的转换方式,就可以玩出很多花样了。进程与进程之
间可以让虚拟地址相同,但是物理地址不同而达到了空间上的真正分离;进程自己并不能看
到自己的真实物理地址,而且即便物理地址不存在,也可以通过页面交互技术让它存在,那
么操作系统就可以欺骗进程它拥有很多的内存可用;同样利用页面交换技术,可以将一个文
件映射到内存中,使得mmap这样的系统调用得以实现;将相同的虚拟地址转换成相同的物理地址,就可以做到数据的共享,线程就是这么干的;将硬件设备的控制存储区域反映到虚拟内存上,就可以实现通过内存访问就达到控制硬件的目的;等等这些……
将物理地址伪装成虚拟地址的这个过程,或将虚拟内存转换成物理内存的这个过程,统
称为内存映射,也就是Memory Map,简写为mmap。所以mmap是一种机制,只是Linux有一个系统调用恰好与这种机制同名了。不过没关系,本身这个系统调用就可以代表整个Linux的内存管理过程了。只是我们需要了解它背后的秘密,才能真正让其为我所用,进一步达到唯我所用的高度。
15.3.3应用mmap
好了,我只是在这里瞎吹mmap()这个系统调用有多牛,你也是不可能信服的。正所谓:
光说不练假把式,光练不说傻把式,有说有练才是真把式。那么接下来我就列举几个mmap
的典型应用,让你瞧瞧什么才是mmap的真把式吧!当然,在开始之前,我们得搞清楚mmap()这个系统调用得怎么使才行。
1. mmap0系统调用的使用
void *mmap(void *addr,size_t len,int prot, int flag, int filedes, off_t off);
int munmap (void *addr, size_t len);
通过前面对虚拟内存技术的讲述想必你已经深入理解了内存映射机制。mmap()函数把文件的一部分直接映射到内存,这样文件中的位置直接就有对应的内存地址,对文件的读写就直接用指针来做而不需要read/write函数。这样做避免了对内存映射后的文件进行读写操作使用read()和write()系统调用而产生的额外拷贝。除了有潜在的页错误,读写内存映射文件不会有系统调用或上下文切换的损耗。定位文件也不需要用lseek0系统调用,用指针操作就能轻松搞定。munmap()函数用来取消参数start所指的映射内存起始地址,参数length则是将要取消的内存大小。
实现共享内存是mmap0主要应用之一,它使得进程之间通过映射同一个普通文件实现共享内存。MAP_SHARED选项意味着允许与其他所有映射这个对象的进程共享映射空间。对共享区的写入,相当于输出到丈件。直到msync()或者munmap()被调用文件才会被更新。
MAP_PRIVATE是指建立一个写入时拷贝的私有映射。内存区域的写入不会影响到原文件。
mmap优点很明显,但也不是包治百病的万能解药。在文件和内存映射的页数之间会有浪费的闲置空间。就拿小文件来说,例如相对4k -页,8字节映射就浪费了4088个字节。在32位地址空间中,大量不同大小的映射会导致地址空间分片,使系统很难找到一大片连续的区域。当然这个问题在64位地址空间上表现得不明显。所以在映射的文件比较大(浪费的空间与映射文件的比例相对来说就很小)或者映射文件大小正好被一页大小整除(太妙了,地址空间零浪费)的情况下,mmap的好处才能得到充分体现。
举个例子说说mmap:
先创建一个文件:
$ echo 'mmap ! ' > mmaptest
$ od -txl -tc mmaptest
6d 6d 0a
m m a p ! \n
用下面的代码8操作这个文件:
代码8:
#include <stdlib . h>
#include <sys/mman. h>
#include < fcntl . h>
int main (void) {
Int *p
Int fd=open(“mmaptest”,O_RLWR);
If (fd<) {
perror(“open mmaptest”);
exit ();
}
p= mmap (NULL, ,PROT_WRITE, MAP_SHARED, fd.);
if (p==MAP_FAILED) {
perror( "mmap”);
exit ();
}
//关闭文件不影响已建立的映射,仍然可以对文件进行读写
close (fd);
p[]=Ox30313233;
munmap (p,);
return ;
}
然后检查执行结果:
$ od -txl -tc mmaptest
6f Oa
! \n
2. mmap在内核空间
当用户空间呼叫mmap()系统调用包装函数后,内核会在进程地址空间里建立新的虚拟
地址区域,并在回调mmap驱动函数时将该虚拟地址区域传递给我们的驱动函数。在驱动函数里,我们只需要利用remap_page_range()将内核空间的内存:
● I/O memory
● RAM(保留页)
● Virtual address space(保留页)
对应到该虚拟地址区域,然后使用它从内核里读取数据就更快了。
mmap在驱动程序里是一个函数指针,我们需要在写驱动程序时实现这个功能。我们可以拿一个简单的字符设备举个例子。如果你不知道如何写一个简单的char设备驱动,下面
的流程会对你有所帮助。
首先在file_operations结构里定义mmap函数,这个结构会帮助我们在内核里注册一个
驱动。
......
struct file_operations mmap_fops ={
open : mmap_open ,
read: mmap_read,
write: mmap_write,
llseek : NULL.
ioctl : NULL ,
release : mmap_release .
mmap : mmap_mmap ,
};
......
当用户空间调用mmap系统调用,file_operations->mmap()将被调用。
file_operations->mmap调用remap_page_range()在用户空间和内核空间映射内存。
......
static int mmap_mmap (struct file*file, struct vm_area_struct *vma)
{
Struct mmap_state*state= (struct mmap_s tate*)file->private_data;
unsigned long size;
Int ret=-EINVAL:
if (vma->vm_pgoff ! = O)
{
printk ( " vm_pgoff ! = O\n" ) ;
goto error;
}
/* Don' t try to swap out physical pages.. */
vma->vm_flags |= VM_RESERVED;
size = vma->vm_end - vma->vm_start;
if (size>state->size)
goto error;
if (remap_page_range(vma - >vm_start,
virt_to_phys( state->data),
size,
vma - >vm_page_prot))
return -EAGAIN;
return ;
error :
return ret;
}
......
remap_page_range()的工作是去修改page table,但要不要以“page”为最小单位做page table的修改,还要具体问题具体分析。
在编写完驱动程序后把它编译成mmap.ko文件,然后用insmod/modprobe方式加载此驱动模块。由于这是一个字符设备驱动,我们还需要用mknod /dev/mmapo c Major Minor建立一个目录项和一个特殊文件的对应索引节点。Major和Minor表示主设备号和次设备号,一般来说主设备号用来区分设备的种类,而次设备号是为了作唯一性区分用来标明不同属性。驱动程序是根据主、次设备号来定位设备的。主、次设备号可在内核源代码的./Documentation/devices.txt里查到。当然节点的位置不是一定要在/dev下,但是为了便于管理一般都是指定/dev。 c 字符设备
用户空间调用mmap后得到一个void指针。现在如果用户空间修改指针所指的内容的话,内核空间的内容也会同时修改。
3. mmap在用户空间
现在我们从内核空间穿越回到用户空间。在用户空间我们首先打开设备获取文件描述符,记住在Unix世界中设备也被当作文件来对待。成功得到描述符后再调用mmap做内存映射,把一个文件的内容在内存里面做一个映像,对这段内存做存取时,其实就是对这个档案做存取。说白了,内存映射就是一种快速file I/O,使用上和存取内存一样方便,只不过会占掉你的虚拟内存。
紧接前面mmap字符设备的例子。下面的代码9对你理解mmap在用户空间的使用会有所帮助。
代码9:
#include <sys/mman . h>
#include <stdio . h>
#include <sys/types . h>
#include <sys/stat . h>
#include <fcntl .h>
#include <errno . h>
int main ( )
{
char *ptr = NULL;
int fd = open ( " /dev/mmap0 " , O_RDWR) ;
if (fd <= )
{
printf ( "open fail\n" ) ;
return ;
}
ptr=mmap (, , PROT_WRITE | PROT_READ, MAP_SHARED, fd, );
printf( "ptr= [%s]\n”,ptr);
Ptr[]= ‘c’;
printf( "ptr= [%s]\n”,ptr);
}
在《这里也是鼓乐笙箫》一章中提及Framebuffer的用法时,我们谈到/dev/fb是一种字符型设备,在用户空间使用ioctl、mmap等文件系统接口进行操作,ioctl用于获得和设置信息,mmap可以将Framebuffer的内存映射到用户空间。如果你有兴趣,可以翻到那一章对比着读一读。
15.4碧玉刀:epoll(增强I/O复用)
《碧玉刀》在古龙的描写下引伸出一个恒古真理,尽管每个人都说自己诚实,但是很多时候这就是一句谎话。但是Linux的epoll却是一个例外,它永远都会说真话,它所告诉你发生的那些事情就一定发生了。只是有时候它会絮絮叨叨,有时候又干净利落。
这是怎么回事?因为故事从这里开始……
15.4.1 C10K问题(c10k == connection 1w,最早是由Dan Kegel进行归纳和总结的,并且他也系统的分析和提出解决方案) IO事件模型 select-》poll-》epoll
https://www.jianshu.com/p/ba7fa25d3590
从网络编程技术的角度来说,主要思路:
1.每个连接分配一个独立的线程/进程
2.同一个线程/进程同时处理多个连接(I/O多路复用)
(1)每个进程/线程处理一个连接
该思路最为直接,但是申请进程/线程是需要系统资源的,且系统需要管理这些进程/线程,所以会使资源占用过多,可扩展性差
(2)每个进程/线程同时处理 多个连接(I/O多路复用)
.select方式:使用fd_set结构体告诉内核同时监控那些文件句柄,使用逐个排查方式去检查是否有文件句柄就绪或者超时。该方式有以下缺点:文件句柄数量是有上线的,逐个检查吞吐量低,每次调用都要重复初始化fd_set。
.poll方式:该方式主要解决了select方式的2个缺点,文件句柄上限问题(链表方式存储)以及重复初始化问题(不同字段标注关注事件和发生事件),但是逐个去检查文件句柄是否就绪的问题仍然没有解决。
.epoll方式:该方式可以说是C10K问题的killer,他不去轮询监听所有文件句柄是否已经就绪。epoll只对发生变化的文件句柄感兴趣。其工作机制是,使用"事件"的就绪通知方式,通过epoll_ctl注册文件描述符fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd, epoll_wait便可以收到通知, 并通知应用程序。而且epoll使用一个文件描述符管理多个描述符,将用户进程的文件描述符的事件存放到内核的一个事件表中, 这样数据只需要从内核缓存空间拷贝一次到用户进程地址空间。而且epoll是通过内核与用户空间共享内存方式来实现事件就绪消息传递的,其效率非常高。但是epoll是依赖系统的(Linux)。
.异步I/O以及Windows,该方式在windows上支持很好,这里就不具体介绍啦。sqlserver里的IOCP等待 全称 IO_COMPLETION(https://www.cnblogs.com/lyhabc/articles/3974828.html)
自从世上第一台计算机诞生到今天,计算机的本质——输入和输出,简称I/O——就从来没有改变过。因为,没有输入,讣算机就不知道要计算什么;没有输出,再快的计算也没有意义。如何处理I/O,也就成了计算机界亘古不变的话题。
随着技术的日新月异,计算机的速度越快,对高效的处理I/O的需求就越紧迫,在人们的不断探索中,时至今日已经发明了很多种处理I/O问题的方式,从形式上划分的话,可归类为4大模型:阻塞、非阻塞、多路复用和异步。
阻塞式I/O就不必多说了,非阻塞式I/O就是在I/O请求时加上O_NONBLOCK 一类的标志,立刻返回,I/O没有就绪就会返回错误,需要请求者主动轮询不断发I/O请求直到返回正确;I/O多路复用同非阻塞式I/O本质是一样的,不过利用新的select、poll、epoll等系统调用,由操作系统来负责轮询操作;异步I/O也不会因为I/O操作而阻塞,但不需要轮询,待I/O操作完成后通知请求者。作为网络服务器应用,到目前为止I/O多路复用依然是最为有效的解决方案,异步I/O在处理大量网络请求时,相较于I/O多路复用需要更多的系统资源,因此更适用于量少但对性能要求较高的文件处理和网络传输。所以我们总是要聚焦I/O多路复用。
I/O多路复用是随着网络的发展和网络服务器需要处理大量客户请求的历史背景下被发明的。大家耳熟能详的,也是最为著名的select调用,就是这个背景下的产物。I/O多路复
用实际上是一种复合I/O模型,即利用类似于select的调用对阻塞或非阻塞式I/O的一个集
合进行监控,找出那些调用者所感兴趣的I/O事件。
经典的select处理方式是这样的:调用者将需要监控的I/O句柄放入一个数组中,将这
个数组传递给select调用,并设定监控何种事件(一般是可读或可写);这时select会阻塞调用进程(当前多数使用线程):当有I/O事件发生时,select就在数组中给发生了事件的那些I/O句柄做一个标记后返回;之后,调用者便轮训这个数组,发现被打了标记的便进行相应处理,并去掉这个标记以备下次使用。这样,对于服务器程序来说,一个进程或线程就可以处理很多客户端的读写请求了。不过select有一个限制,就是传递给它的I/O句柄数最多不能超过1024个,在今天看来这显然是不够用的。于是人们就引入了poll这个调用。它与select基本相同,只是I/O句柄数理论上没有上限了。
事情看似解决得不错,但人是不甘寂寞的动物,地球上基本没有任何东西可以满足人的
贪欲,于是问题兢来了。
互联网越来越发达了,上网的人也越来越多了。网络服务器在处理数以万计的客户端连
接时,经常会出现效率低下甚至完全瘫痪的局面,这就是非常著名的C10K问题。C10K问
题的特点是:一个设计不良好的程序,其性能和连接数,以及机器性能的关系往往是非线性
的。换句话说,如果没有考虑C10K问题,一个经典的基于select或poll的程序在旧机器上
能很好地处理1000并发,它在2倍性能的新机器上往往处理不了2000并发。这是因为大量操作的消耗与当前连接数n成线性相关,从而导致单个任务的资源消耗和当前任务的关系会是O(n)。那么服务器程序同时对数以万计的网络I/O事件进行处理所积累下来的资源消耗会相当可观,结果就是系统吞吐量不能和机器性能匹配。为了解决这个问题,必须改变I/O复用的策略。
为了解决上述这些问题,人类世界的一些大神们发明了epoll、kqueue和/dev/poll这3套利器。其中epoll是Linux的方案,kqueue是FreeBSD的方案,/dev/poll是最为古老的Solaris
的方案,使用难度依次递增。这些方案几乎是不约而同地做了两件事:一是避免了每次调用
select或poll时内核用于分析参数建立事件等待结构的开销,取而代之的是维护一个长期的
事件关注表,应用程序通过句柄修改这个列表和捕获I/O事件;二是避免了select或poll返回后,应用程序扫描整个句柄表的开销,取而代之的是直接返回具体的事件列表。这样,就彻底摆脱了具体操作的消耗与当前连接数n的线性关系,从而极大地提高了服务器的处理能力。
由于本书是针对Linux的,因此我们就不会涉及与Linux无关的其他内容,所以我们只关心epoll。
15.4.2 epoll的优点
首先,epoll与poll 一样,理论上没有任何I/O句柄数量上的限制。不过这是理论上的原因就是一个进程所能创建的,或者说能够使用的I/O句柄数是有限制的。默认情况,Linux允许一个进程最多拥有1024个I/O句柄。不过不用担心,可以通过系统命令或系统调用来修改这个限制(ulimit命令)。尽管可以设置为无限制方式,但是这个是不建议的。如果要处理上万并发连
接的话,最好采用多进程模式,这样不但可以充分利用CPU资源,还可以保证系统的整体
稳定性。
其次,epoll的I/O效率,如前所述,与I/O句柄的数量没有多大关系。因为每次返回的,只是一个具体事件的列表。一次epoll_wait调用返回全部I/O句柄的可能性完全可以忽略不
计,如果真有这种情况发生,那么也就说明你已经将机器的性能发挥到了极致,或者你有什
么地方弄错了,再或者就是有人给你故意捣乱了(你不能抬杠说只有1个或几个网络连接的
情况)。
再次,epoll使用mmap来加速内核与用户空间的消息传递。这有点涉及epoll的实现过程了。不过不管是什么方案,都是避免不了内核向用户空间传递消息,那么避免不必要的数据拷贝就不失为一个绝妙的办法。mmap就能够做到。因为mmap可以使得内核空间和用户空间的虚拟内存块映射为同一个物理内存块,从而不需要数据拷贝,内核空间和用户空间就可以访问到相同的数据。
最后,epoll可以支持内核微调。不过不能把这个优点完全归epoll所有,这是整个Linux系统的优点。你可以怀疑Linux这个平台,但是你绝对无法回避Linux平台赋予你的微调内核的能力。因为我们前面章节所讲述的procfs文件系统,就是对内核进行微调的一个开放接口。
15.4.3 epoll的工作模式
ET:手动档汽车
LT:自动档汽车 默认工作模式
但凡对epoll有一点点了解的人,都听说过epoll有两种工作模式,即ET( Edge Trigger)和LT( Level Trigger)模式。这两种工作模式的中文翻译分别是边沿触发和电平触发,还可以称为事件触发和条件触发。我倒是觉得后者的翻译更能清楚地描述这两种工作模式的特点和差别。
不过边沿触发和电平触发更为专业一些。这两个名词源自电子工程学,见图15.6所示。

数字电路的电流一般是图15.6中所示的巨型波电流。电压的高低随着时钟周期不断变化。在电子工程学中,低电压被称之为“低电平”,高电压被称之为“高电平”,可以将高低电平理解为1和0。电平高低的变化被称之为“边沿”或简称“沿”,从低到高是“上升沿”,从高到低是“下降沿”,可以将边沿理解为0-1或1-0的变化过程。
那么以此来推论:所谓的边沿触发就是当状态有变化,也就是发生了某种事件就发出通
知:而电平触发就是当处于某种状态,也可以说是具备某种条件就发出通知。因此,我觉得
Edge Trigger翻译成事件触发,Level Trigger翻译成条件触发更加贴切。
当epoll工作在LT模式下,只要其监控的I/O句柄具备调用者所要捕获的条件-------一般
是可读或可写——就会通知给调用者。如果调用者不理会这个通知,它将一直通知下去,直
到这个状态发生变化。当采用多进程模式编写服务器软件时,根据系统任务调度特性,采用
LT模式可以使得所有连接均匀的分布于每个用于处理网络请求的进程。有汽车驾驶经验的童鞋可以将LT模式理解为驾驶自动档的汽车,只要设置好你感兴趣的I/O句柄和事件类型,在具备条件的时候epoll兢会通知你,只需要做相关的处理就可以了,非常轻松惬意,代价就是稍微多出的那么一点点油耗。
当epoll工作在ET模式下,情况有些变得复杂了。原因就是这种基于事件的通知是事件发生后,只会产生一次通知。如果你不去理会它,它也不会再理会你,直到下一次事件发生。这会导致一个严重的后果就是当一个编写不够良好的程序,在获得事件通知后并没有将缓冲区的数据全部读取干净,epoll也不会有任何通知,没有读取到的数据可能永远都不会被读取,或者使得那部分数据超时。另外,ET模式只允许非阻塞式l/O,这就进一步加剧了上述问题的恶化。解决的方法就是反复读取缓冲区,直到返回错误。所以,如果说LT模式是自动挡,那么ET模式就是手动挡,所有情况都得自己处理,处理不好就可能熄火,好处就是经济实惠。另外,ET模式在多进程服务器软件中,会导致连接在处理进程之间的不均匀分布,不过也只是相对的,当发现问题严重时,可适当暂停某个进程接受新的连接。
15.4.4正确使用epoll
epoll最为复杂,也是争论最多的地方——工作模式——介绍完了。但是对于epoll的争论还远不止于此,所以接下来就通过如何正确使用epoll来给大家晨示出epoll真实的一面。
乍一看epoll的几个接口,还是非常简单的。只需要掌握三个接口:epoll_create、epoll_ctl
和epoll_wait。实际上epoll也只是提供了这三个接口。需要引用的头文件是:
#include <sys/epoll.h>
int epoll_create( int size),创建一个epoll对象,返回epoll对象句柄。对于它的唯一参数size,争论很多,实际上早就作废了,存在的意义就是向下兼容。一是API的兼容,毕竟有大量的老程序也使用了epoll;二是对老版本系统的兼容,因为即便你在开发的时候使用的系统很新,但是实际上运行在什么版本的系统上就不一定了。早期需要提供这个参数也只是参考值,它并不像好多人所理解的那样限制连接数量,所以在任何时候这个值都是任意的。
推荐值是256,其实这仅是个习惯问题,并不会对程序性能有多大影响。
int epoll_ctl( int epfd,int op,int fd,struct epoll_event *event),epoll的控制接口,用于向epoll中添加、修改或删除要监控的I/O句柄以及所关心的事件类型。参数epfd是epoll的对象句柄,由epoll_create创建。op即指明了要进行的操作,EPOLL_CTL_ADD、EPOLL_CTL_MOD和EPOLL_ CTL_DEL,分别对应添加、修改和删除操作。fd是要增删改的I/O句柄。最后一个event是一个结构体。这个结构体定义如下:
typedef union epoll_data {
void *ptr;
int fd;
___ uint3 2_t u32;
___ uint6 4_t u64;
} epoll_data_t;
struct epoll_event {
__uint32_t events j /*epoll事件集合*/
epoll_data_t data; /*用户私有数据 */
};
这个结构体申,我们最关心的是events字段,它用于设置关心哪些I/O事件,以及采用
何种工作模式。一次可以设置多种I/O事件和工作模式,使用“l”运算符进行组合。表15-1
列出了所有可以监控的事件:
表15-1 EPOLL可监控的事件
|
事 件 |
说 明 |
|
EPOLLIN |
所监控的I/O句柄可读,即有数据可以读取 |
|
EPOLLOUT |
所监控的I/O句柄可写。多数处于这种状态,除非缓冲区满 |
|
EPOLLRDHUP |
远端关闭连接 |
|
EPOLLPRI |
有紧急数据可读,最典型的就是TCP的带外数据 |
|
EPOLLERR |
所监控的I/O句柄发生错误 |
|
EPOLLHUP |
连接关闭。实际上epoll始终会监控这个事件,不需指明 |
|
EPOLLET |
ET工作模式 |
|
EPOLLONESHOT |
只做一次监控 |
这里以EPOLLIN、EPOLLOUT和EPOLLET最为常用,其他事件这里仅供参考。我们在这里看到了ET工作模式,但是没有看到LT,原因是当不设置为ET模式,就采用LT模式,即LT是epoll的默认工作模式。结构体中的data字段为用户私有字段,这是一个联合体。从其定义上看,可以放置任何类型的数据,而且epoll也不会操作这些数据。其作用就是可以设置一些私有数据,使得在处理相关事件时更容易组织数据。绝大多数情况将要监控的I/O句柄保存在这里,后面我们会看到这样使用的好处。
int epoll_wait( int epfd,struct epoll_event *events,int maxevents,int to),等待epoll所监控的I/O句柄有事件发生。参数epfd同上。events是一个数组,为一个己发生的事件列表。调用者一般都是迭代这个数组,依次处理所有事件。这个数组需要事先分配好,具体大小(严
格意义上是元素个数)根据实际情况而定,多采用动态分配策略。maxevents是一次最多能
够返回的事件数,必须大于0且小于或等于events的大小,否则会出现内存越界。最后一个to是超时值,单位是百万分之一秒。因为epoll_wait会阻塞调用线程,所以很多时候必须设置超时值使得线程还可以做一些其他事情。如果单独创建了一个epoll专有线程,可以将to设置为-1,即永不超时。epoll_wait返回后,会返回发生事件的I/O句柄教量,如果返回0则表明超时。前面说过的events参数如果采用动态分配策略,就可以根据这个返回值来处理。比如:当返回值等于events大小时,可以适当扩大events,比如扩大一倍;当返回值远小于events大小时,适当缩小events,比如减小一半。
三个接口已经分别介绍完毕了,那么如何利用这三个接口处理数据的收发呢?我们需要分别讨论收和发的情况,因为这本身也是困扰很多人的问题,我想分开说明能更加明晰。
接收请求是作为网络服务器软件的必备功能,也是最容易处理的。不用过多的语言表达,
我们直接看代码10:
代码10:
struct epoll_event ev, events [MAX_EVENTS] ;
int listen_sock, conn_sock, rtfds, epollfd;
......
/* Set up listening socket, ' listen_sock ' ( socket ( ) , bind ( ) . listen ()) */
epollfd = epoll_create () ;
ev . events = EPOLLIN;
ev . data . fd = listen_sock;
epoll_ctl (epollfd, EPOLL_CTL_ADD, listen_sock, &ev)
For(;;){
nfds = epoll_wait (epollfd, events, MAX_EVENTS, -) ;
for (n = ; n < nfds; ++n) {
if (events [n] . evnets & EPOLLIN && events [n] .data. fd == listen_sock) {
conn_sock = accept (listen_sock, (struct sockaddr *) &local, &addrlen) ;
setnonblocking ( conn_sock) ;
ev. events = EPOLLIN;
ev.data . fd = conn_sock;
epoll_ctl1(epollfd, EPOLL_CTL_ADD, conn_sock, &ev)
}
if (events [n]. events&EPOLLIN) {
do_use_fd( events [n]. data. fd);
} else {
/* error*/
}
}
}
代码10省略了错误处理和基本套接字的创建过程,并且由于排版的因素并没有优化,不过基本描述清楚了epoll在处理读数据时的工作方式。前面说过,在epoll_ctl的event参数中会将要监控的I/O句柄放在data字段中,这里就可以看到最直接的效果——明确了到底是谁产生了何种事件。如果采用ET工作模式,accept的调用和do_ use_fd的内部处理需要注
意:必须反复调用accept,直到其返回EAGAIN错误;do_use_fd中必须反复调用recv,直
到其返回EAGAIN错误。
至于发送,问题并没有我们想象的简单。原因就在于如果像接收一样,设置了EPOLLOUT,如果采用LT模式的话,基本上每次调用epoll_wait都会立即返回,并通知调用者所有I/O句柄可写。因为在一个不是输出数据非常庞大的系统中,写缓存始终都是处于未满状态,基于LT这种条件触发的工作模式,写条件就会一直满足,所以就epoll_wait就会立即返回。那么改成ET模式呢?问题又变了。只有在第一次调用epoll_wait后立即返回所有I/O句柄可写,之后几乎就会很少有机会获得I/O可写通知了,因为这需要首先写缓存满到未满的这个变化过程。这些显然不是任何人想要的了,应该怎么办呢?
答案就是:如果要发送数据,大多数直接调用send或wirte就可以了,直到他们返回EAGAIN错误,才需要将它们交给epoll去监控。一旦epoll_wait返回某个被监控的I/O句柄可写,则应该立即利用epoll_ctl将它删除,直到下次再出现EAGAIN错误。不过虽然说起来简单,但是真正到具体的操作还是比较麻烦。要完整可靠的发送数据:必须记录每次实际发送的数据量来统计剩余量;当发生EAGAIN错误后,必须将剩余的数据保存在一个地方,一般放在epoll_event结构的data字段中即可;当epoll通知可写后,将剩余数据发送出去;但是当遇到压力较大时,可能在发送剩余数据的时候还会发生EAGAIN错误,必须始终记录剩余数据才行。由于篇幅问题,我就不提供有关发送数据昀代码,留给大家自己研究实现。
基本流程可参考图15.7:

epoll就是这样使用的。不过有关epoll到底如何使用的讨论并不是最多的,最多的是到底应该采用LT模式还是ET模式。有人说:LT模式简单易用,但效率一般:ET模式虽然复杂难用,但效率惊人。实际情况是这样的吗?由于篇幅关系我不想过多地谈论它们的实现方式,在这里只做简单说明。首先在内核中它们的处理逻辑是完全相同的,只是由于LT模式每次都要通知,需要多一些的内核空间来保存没有处理完的I/O句柄;其次,ET模式需要调用者自行处理完I/O事件,由于处理方式千奇百怪,经常发生的是ET比LT需要更大的内存开销;再次,一般号称ET模式的优势在于减少系统调用,但是循环读写并不见得相较于LT模式能减少多少次系统调用;最后,由于epoll_wait是O(m)(m是有事件发生的I/O句柄数)级的,因此ET的真正优势是减少了每次需要返回的I/O句柄数量,在并发量极多的时候能加快epoll_wait的处理。不过这也仅仅是针对epoll自身体系的性能提升,但是别忘了还需要增加额外的处理逻辑,总体收益如何只有经过实际测量才能知晓。所以,为了降低处理逻辑的复杂度,常用的I/O事件处理库,如libevent,boost::aio等都采用了LT模式。
总体来说,epoll是一个即简单又复杂的I/O复用方案。说它简单,是因为只需要掌握个接口创建、控制和等待;说它复杂,因为LT和ET两种工作模式,尤其是ET模式让很多人感到困惑,另外在处理数据发送的问题上也需要进行全面考虑才不至于有所闪失。
memcached使用libevent I/O事件处理库
15.4.5用epoll解决C100K问题,connection 10w
其实就Linux系统而言,只是简单地使用epoll并不能突破C10K问题。因为系统中还有很多限制。同时单个机器拥有数万连接,稳定性和可靠性也是必须要关心的问题。因此我将详细讲解如何在Linux系统下,真正稳定可靠地突破C10K问题,乃至设计出更具性能素质的服务器系统,甚至突破C100K。
1. 阻力 nginx.conf -》worker_rlimit_nofile 51200 打开文件描述符的个数
很多同学在掌握了epoll这个神兵利器之后,就迫不及待地开始用它来设计自己的系统,
但是到了实际测试时,程序的连接数怎么也超不过1024个,且系统报错:“Too many open files.”这是怎么回事?原来Linux系统对于每个进程所能打开的文件数量做了限制。至于为
什么要做这个限制,由于时间关系,我只能告诉大家这是出于稳定性考虑的。默认情况下,这个限制值是1024,这就是产生上述问题的原因。
幸运的是,Linux是一个非常灵活的系统,灵活到任何东西都可以进行微调,一个进程所能打开的文件教量自然也是可调的。方法有三:一是使用命令ulimit,这个命令可以对具
体某个shell所创建的所有进程有效,使用_n选项即对文件数量限制进行修改,并且可以设置为unlimited;二是使用getrlimit和setrlimit系统调用来设置,仅对调用进程及它的子进程有效,作用与ulimit命令相同。它们具体如何使用大家可使用man工具阅读linux的联机帮助。这里需要说明的是,不能将打开文件数量设置得过大,会引起稳定问题。一般考虑设置为4096或8192即可,当然这是一个参考值,更大一点也不会出什么问题,比如102400。
nginx使用epoll
worker_rlimit_nofile ;
events
{
use epoll;
worker_connections ;
}
还有第三种方法
修改/etc/security/limits.conf文件里面的limit值,永久生效
http://www.cnblogs.com/MYSQLZOUQI/p/5054559.html
cat /proc/sys/fs/file-max
98763
将文件数量限制开到最大,有时候也并不能解决问题,原因就是Linux系统还有另外一
个限制系统最大允许打开文件数。这个值依然是可调的,就是通过procfs文件系统的/proc/sys/fs/file-max来调整。要注意的是,系统默认给出的值,是一个折中方案,即整个系
统内如果打开了那么多文件是不会影响到系统其他功能的(比如创建新的进程)。虽然很多发布版会做得保守一些,但是如果不是很极端的话,还是尽量不要修改,除非你真的对你的机器上所运行的所有软件都了如指掌。换句话说,如杲要评估一个机器到底能够处理多少客户连接,这个值就可以充分说明问题。
前面所说的是系统上的一些限制,但是还有一个限制很重要,就是内存。每当创建一个
TCP连接,都至少要分配8K的内存给它。那么一个具有IG内存的机器,将这些内存全部分配用于建立TCP连接,最多也只能达到13万多了。而且如果是32位系统的话,内存再多也无济于事,因为TCP连接所占用的内存要分配在内核空间,可是Linux的内核空间在32位模式,最多使用1G的虚拟内存空间。如果要想系统能够正常工作,肯定无法超过10万连接。这种情况突破C10K是没有问题,但是对于C100k来说,总是有一堵难以逾越的墙。看似无计可施了,但是这仅限于是32位系统的时候,现在显然已经是64位时代了(没听说哪个服务器不是64位了),只要采用64位版本的Linux就不再有这种问题了。因为不管是用户空间还是内核空间,几乎具有在现在看来是取之不尽用之不竭的虚拟内存空间,只要你
拥有足够大的物理内存,突破C100K是完全没有问题的。
好了,文件数量的限制解决了,机器的限制也解决了,那么就开始动手吧。我说,还不
行。最开始就说过,不但要有足够的性能,还需要良好的可靠性和稳定性。一个处理上万连
接的系统的稳定性和可靠性要比性能重要得多。
2. 动力
Linux系统就是以稳定可靠而著称的,但是这并不代表你在它上面写的程序就会稳定可
靠。虽然要突破C10K问题,修改文件数量限制可以做到,但是这会稍微引起稳定性问题。不过问题并不是无解,虽然单个进程不能打开太多文件,多个进程不就没问题了吗?如果你能想到这里,就说明你在思想上就已经跟上了Linux的步伐。
fork的复制特性是我们需要谨记的。当在父进程创建一个用于监听网络连接的套接字,在子进程中同样可以使用。而且之前所绑定的端口,如80等,依然有效,这正是我们可以利用的关键所在。至于多进程的稳定性,我们之前已经做了很深入的讨论了。
3. 模型
我们要突破C100K问题的系统支持特性基本上介绍完毕了,接下来我们就开始搭建这
个系统模型。
其实采用多进程策略,不单单是因为减少了单个进程最多打开的文件数量而带来的稳定
性。更为重要的是,我们可以搭建出一个攻守同盟,极具伸缩性且易于实现的系统模型。图
15.8展示了这个模型:
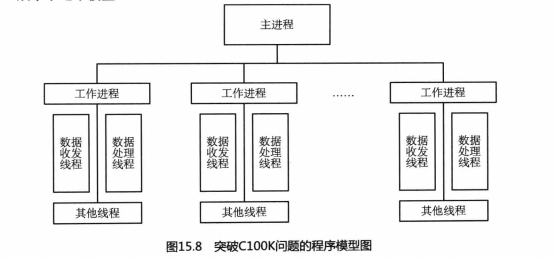
在这个模型下,主进程即所有工作进程的父进程,它只负责两件事:一是创建和回收工作进程;二是监控所有工作进程。工作进程完成所有业务逻辑,是否引入线程,可根据具体
业务来考虑。
为什么说这是一个攻守同盟的系统模型呢?因为工作进程相当于去攻,执行具体任务,主进程待在家里负责防守。因为主进程几乎没有复杂的业务逻辑,实现起来非常容易。这样主进程就会非常稳定。工作进程自然会非常复杂,稳定性会极大降低。但是不要紧,主进程在监控它,发现有任何风吹草动就可以不让它继续做过多的事情。或者某个工作进程崩溃了,主进程由于是它的父进程,可以立即感知到,可以立即将它重新启动。而且之前说过,一个进程出现错误,不会对它的父进程乃至兄弟进程产生任何影响,那么即便某个工作进程崩溃,其他进程还会继续工作。对于一个具备数万乃至数十万连接的服务器程序,一个进程崩溃所影响到的不过是几千个连接,而且如果客户端处理得好,完全可以在用户不知情的情况下,重新与服务器建立新的连接。对于这样一个攻守同盟的系统模型,稳定性就可见一斑了。
说它极具伸缩性,是因为主进程不但负责防守,还会调兵遣将。当主进程发现现有工作
已经很难应对当前的业努量了,可以立即创建一批新的工作进程来迎接挑战。当业务量降低
到已经不再需要这么多工作进程时,还可以逐渐地回收它们。这样不但可以充分利用机器的
处理能力,还可以节省很大的资源。如果再进一步,将这种分配和回收策略写入配置文件,
根据不同的机器性能进行配置,那么这个系统的适用范围将会更加广阔。一个系统可以这样
灵活,怎能不说它极具伸缩性呢?
说它容易实现,是因为这个模型将问题分治了。将原来一个进程需要处理的连接数量分
配给多个进程了,这样对于开发者来说,实际所面对的问题量就显著减少了很多。问题少了,
自然实现起来就简单了。根据简单即稳定的原则,就进一步提升了工作进程的稳定性,系统
的整体稳定性也就不言而喻了。
至于在图中所展示的几类线程,是考虑到不同业务而做的一个简单概括。每一类甚至所
有类型的线程都是可选的。比如采用epoll来处理TCP连接时,使用收发线程+处理线程会
极大的增加系统复杂度并降低稳定性,所以应该考虑将它们合并为一类线程。但是对于处理
UDP协议的时候这又是一种非常高效的模型。而且记住一点,使用UDP就要离epoll远一
点,因为直接利用多个收发线程+更多的处理线程的效率远比用epoll高得多。至干其他线程,
主要是考虑有一些如输出日志、远程请求之类的操作,这样整体系统的响应效率会很高。
现代的机器加之现代的Linux突破CIOOK是没有任何问题的。或许大家想让我再提供
一些代码来参考,但是我说不了。原因是大家只要充分理解并运用我前面讲的系统机制就能
够完成这一模型的搭建,并能很容易地突破C100K。我不是很喜欢讲填鸭式的课程,那样会
束缚所有人的创造力。所谓:“师者,传道授业解惑者也。”我想我在讲述这一部分的内容时
已经全部做到了,具体的实现,就留给大家去发挥吧。
TCP用epoll
UDP不用epoll
15.5多情环:udev
《多情环》写的诡奇急促、丝丝入扣、泣鬼神、惊风雨。但多情之意乃处事能力之强,做人之最高境界。Linux的udev正是如此,愣就是将原本需要在内核空间去完成的工作交给了用户空间去完成,任谁不觉得这是多么惊天地泣鬼神的壮举呢?它怎么做到的?下面开始分解……
15.5.1设计理念
可以说udev在本书中已经不是什么新鲜玩意儿了,因为在前面的《特种文件系统》一
章已经介绍过了。而且还讲述了udev是如何将devfs赶出Linux世界的故事。我们现在还要继续这个故事。并不是因为这个故事有多么曲折离奇,而是因为udev作为Linux的设备管理子系统的重要组成部分,创造了一段惊人的传奇。它给人们展示了Linux在设备管理方面那种独具特色、标新立异的,而又精彩绝伦的设计理念。
早在前面介绍Linux启动过程的时候,就谈论过Linux的一个设计理念——Early Userspace。目的是让Linux尽早地进入用户空间,属于极其新颖和相对较为“激进”的理念。我这样说的原因是这种理念到目前为止还没有看到它有什么强大的威力,给用户带来的方便只是制作initramfs更方使了,但是普通用户有谁去碰这个东西呢?或许能够在稳定性上有所提升,可是在没有提出Early Userspace之前,Linux的稳定性也不见得比今天的差。udev则不同,虽然同样是强调userspace,但是它掀起的风浪着实不小,直接将devfs踢了出局。因为没有哪个用户不去关心设备管理。即便不怎么直接跟用户打交道的硬件厂商都不能回避这个问题,需要让用户通过最简单的途径管理设备。使用过Windows 95或Windows NT 4.0的用户都有过刻骨铭心的记忆,如果搞不清中断是个什么东西,遇到设备中断号冲突①的时候,肯定是一脑门子官司。可是自从Windows 98、2000之后,还会有谁为这种事儿发愁呢②?在没有udev之前的Linux,用户同样会遇到类似问题,但是有了udev之后,就都成历史了。
①这个是Windows早期版本在安装新硬件时经常会遇到的问题。由于中断资源冲突,新安装的设备不会工作,原来工作好好的设备也会因为新设备的冲突而罢工。擅自修改设备的中断号还有可能引起Windows95的蓝屏或Windows
NT 4.0“没有权限执行”的警告。
②Windows98和2000之后,微软加强了Windows系统对“即插即用”设备的支持,中断号冲突问题成为了历史。
可以说Windows 98、2000是真正现代意义的操作系统,那么有了udev之后的Linux也是真正现代意义的操作系统了。这种转折对Windows极其重要,对Linux同样重要。况且udev并没有强调early,所以是否early,从目前来看不具有划时代意义。
刚刚说到了在系统中添加新硬件这个问题,这就不待不再说一下另外一个贴心于普通用
户的新型硬件设计-hotplug,也就是热插拔!传统的PCI、AGP等接口标准有一个好听的名字——“即插即用”。但是如果你真的相信这种鬼话,在你的电脑还在运行的时候就将使
用这种接口的硬件插到电脑中,有什么后果我想你懂的。因为这些接口标准都不具备hotplug的能力,“即插即用”那就是忽悠人的。真正的“即插即用”就应该在电脑还在运行的时候插上去就能用,可是这个名字已经被人占了坑,那就只能改名hotplug了。USB就是真正的hotplug了,因为你从来没想过要断电之后才能把U盘插到电脑上不是吗?
hotplug技术跟udev又有什么关系呢?答案是没有什么直接的关系。但是hotplug狠推
了一把udev。原因是当hotplug开始流行之后,人们往自己电脑里添加新硬件的行为就像吃饭睡觉一样,平时不鼓捣鼓捣可能会感觉浑身都不舒服(笔记本的鼠标不是经常插来插去的吗?)。也正是因为这种技术的变革,给操作系统的设备管理带来了翻天覆地的变化。devfs已经不适合hotplug了,因为它会把用户弄得晕头转向。于是Linux的开发者们在hotplug的
逼迫下,请来了sysfs,也带来了udev。虽然devfs因搞不定hotplug而该死,但是也并不代表udev就一定是它的后继者。之所以udev做成了这个坚强的后继,是因为udev在设计理念上拥有更大的气度。它已不再甘心做一个设备文件的生产者,而是要做一个设备信息的监视者。自古以来做监工的要比做劳工的地位高很多,这可是不争的事实!udev会随时监视是否有新的硬件加入系统,然后作出相应的处理决定。
udev绝对是一个聪明的“监工”,智商很高,它从来不自己做具体的事情。那么由谁
做具体的事情呢?sysfs、HAL、inotify、netlink、dbus等很多“劳工”。需要调动这么多的系统机制,udev显然已经超出了工具的范畴。实际情况也是如此,udev实际上是一个框架,一个与硬件平台无关的管理硬件的一个框架。虽然我和Linux的KISS文化在很多时候都会去反对框架这个东西,但是udev是个特例。因为它的目的很明确,就是为了管理硬件,而且这种管理方式不会导致被误用。虽然udev需要与这么多的系统机制打交道,体现出了它“多情”的一面,但是它的“多情”实际上又是因为“痴情”。为了管理好不同的硬件设备这个它唯一需要关心的事情,它采用“多情”策略。
多情并不等于滥情。udev的每一份多情都有它最终的目的,也就是它的唯一使命。它要处理好与系统中那么多相关机制的关系,这并不是一件容易的事情。甚至很多机制都是因它丽来,并从此造福一方,inotify、netlink、dbus等就是典型的例子。
udev将众多新颖的设计理念汇集于一身。热爱userpace,而又不激进地去强调early;气度宽宏而扭转乾坤,又不失才气而在众多机制之间游刃有余;绝地谋新创造激情,又兼顾大局引领潮流……这就是它强大之处,这就是系统设计的最高境界!并不因为“多情”而伤及无辜,反要去授益四方,怎能不被人们所折服呢?
15.5.2基本构成
一个完整的udev系统只有两个程序文件:udevd和udevadm,其他的能够在系统中找到的与udev有关的程序,比如udevtrigger等,都只是udevadm的一个符号连接。udevd是udev的主程序文件,也就是所谓的udev文件系统守护进程:udevadm是udev的管理程序,比如创建内建的一些设备节点等工作。
系统在启动udev文件系统守护进程之前,要做如下保证:
1. 挂接了sysfs文件系统;
2. /dev目录下挂接一个ramfs文件系统(实际上只要可写就行);
3. /dev目录下已经创建好了console节点和null节点;
4. /dev目录可写;
5. 设置好PATH环境变量。
之后系统执行udevd—d命令就可以了。实际上这些操作由init启动脚本来完成。
/dev/console
/dev/null
15.5.3配置文件
udev的主要配置文件是/etc/udev/udev.conf。这个文件短小精悍,主要有以下几行:
udev_root=”/dev/”
udev_rules=”/etc/udev/rules. d/”
udev_log=”err”
我建议最好不要改动上面的配置,因为硬件厂商习惯把自己的设备放在默认的目录下面。还有,如果不是设备调试阶段运行日志的级别也最好定为err。配置文件的第二行很重要,它表示udev规则文件的存储目录,这个目录存储的是以“.rules”结束的文件。每一个文件处理一系列规则来帮助udev分配名字给设备文件以保证能被内核识别。
udev文件
cat /etc/udev/udev.conf
# The initial syslog(3) priority: "err", "info", "debug" or its
# numerical equivalent. For runtime debugging, the daemons internal
# state can be changed with: "udevadm control --log-priority=<value>".
udev_log="err"
cat 60-raw.rules
# Enter raw device bindings here.
#
# An example would be:
# ACTION=="add", KERNEL=="sda", RUN+="/bin/raw /dev/raw/raw1 %N"
# to bind /dev/raw/raw1 to /dev/sda, or
# ACTION=="add", ENV{MAJOR}=="8", ENV{MINOR}=="1", RUN+="/bin/raw /dev/raw/raw2 %M %m"
# to bind /dev/raw/raw2 to the device with major 8, minor 1.
cat 70-persistent-net.rules
# PCI device 0x1af4:0x1000 (virtio-pci)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="52:54:00:de:ed:8b", ATTR{type}=="1", KERNEL=="eth*", NAME="eth0"
cat 90-alsa.rules
ACTION=="add", SUBSYSTEM=="sound", KERNEL=="controlC*", \
RUN+="/sbin/alsactl -E ALSA_CONFIG_PATH=/etc/alsa/alsactl.conf --initfile=/lib/alsa/init/00main restore /dev/$name"
ACTION=="remove", SUBSYSTEM=="sound", KERNEL=="controlC*", \
RUN+="/sbin/alsactl -E ALSA_CONFIG_PATH=/etc/alsa/alsactl.conf store /dev/$name"
15.5.4规则
默认的udev规则文件稃在/etc/udev/rules.d/50-udev.rules下。udev规则文件的文件名通常以两个数字开头,它们表示系统应用该规则的顺序。在有些情况下,规则启动顺序还是非常重要的。一般你希望系统在默认规则前先解析你制定的规则,所以我建议你创建/etc/udev/rules.d/lO-local.rules文件,在这个文件中编写你的所有规则。
udev规则文件的一行就是一条规则。规则采用流行的key-value形式,由多个键值对( key-value pairs)组成,由逗号隔开。键值对分为条件匹配键值对和赋值键值对,一条规则可以有多条匹配键和多条赋值键。udev规则虽然很简单,但是实现的功能一点也不弱,它可以实现下面这些功能:
● 重命名设备节点
● 通过符号连接的方式为设备节点提供一个临时/永久的名字
● 在程序输出的基础上命名设备节点
● 改变设备节点的权限和所属权
● 当新建或删除一个设备节点时启动脚本
● 重命名网络接口
我们看个简单的例子:
KERNEL==”hd[a—z]”,
BUS==”ide”,
SYSFS( removable)==”1”,
SYSFS( device/media)==”floppy”.
SYMLINK+=”floppy floppy-%k",
OPTIONS+=”ignore_remove, all_partitions”
匹配键是匹配一个设备属性的所有条件,在这个例子中匹配键是:
KERNEL==”hd[ a-z]”,
BUS==”ide”,
SYSFS( removable)==”1”,
SYSFS( device/media)==”floppy”。
如果一个设备的属性匹配了这条规则里所有的匹配键,就认为这条规则生效。然后系统
按照赋值键的内容进行赋值。这个例子中的赋值键是:
SYMLINK+=”floppy floppy-%k”,
OPTIONS+=”ignore—remove, all_partitions”
表示为设备文件hda、hdb…hdz产生符号链接floppy-hda、floppy-hdb…floppy-hdz,并且执行OPTIONS列表中的操作。all_partitions为一个块设备刨建所有可能的分区,而不是初始检测到的那些分区:ignore_remove完全忽略事件。由于符号连接不会覆盖系统默认的udev规则所产生的文件,所以推荐使用符号链接。
有了规则文件,我们就有法可依了。udev在没有找到匹配原则的情况下,UDEV就会使用内核提供的默认名字产生设备节点。如果你想你查寻匹配键信息还可以通过键入udevinfo—a—p$(udevinfo —q path.n/dev/xxx)命令来实现。
15.6 霸王枪:LVS
“一个人只要有勇气去冒险,天下就绝没有不能解决的事情。”这就是《霸王枪》给我
们讲述的故事。Linux的LVS就有这种勇气,去挑战性能无比强悍的久负盛名的F5,结果LVS胜利在望了…
15.6.1负载均衡
对于大多数互联网工作者来说,负载均衡这个概念应该并不陌生。但是你要说负载均衡是计算机集群技术中的一种,有人就会开始犯嘀咕。我在一次面试某个公司职位的时候就有过这样的经历。当时面试官问我:集群有哪些方案?我很干脆地回答:负载均衡、并行运算和主从互备。但是面试官并不同意我的答案,而当我追问为什么时,得到的回答是:负载均衡不是集群……至于面试结果你们都懂的。
曾经有很长一段时间我对那次面试中自己的表现懊恼不已,恨自己学艺不精。但也正是因为有了这种面试经历,才让我能够更加精准地搞清楚负载均衡和集群到底是个什么关系。其实集群是一个统称,可以分为好多种,比较典型的是以分布式计算为代表的高性能科学计算集群,比如Hadoop集群。但是更为常用的一种集群则是负载均衡集群,常用到人们甚至会忘记它是一种集群。现在炒得火热的是另外一种集群,典型的代表就是HBase这种NoSQL数据库,它能够将数据分布在多个集群节点中,即便某个节点发生了故障也不会导致数据丢失,所以这类集群也叫高可用性集群。但是不管怎样分类,采取何种方案,集群的一个显著特点是:无论集群中有多少个节点,它们都是为了一个共同的目标而工作。如果节点们各干各的,互不影响,这叫分布式。但是分布式有时候很难跟集群掰扯清楚,因为很多时候分布式也是由多个不同的集群构成的。
集群这个东西总算是弄明白了,而且也明确了负载均衡就是集群的一种。看来水平太凹
的面试官有时候是很坑人的,幸亏我一直都有一颗无比强大的自信心,否则很可能就被这种人给带到沟里去,也就不可能有这本书了。感谢“自信”!
闲扯的话就到此为止,我们回过头来看看这个负载均衡到底是怎么回事儿吧。负载均衡大多数应用于Web服务和数据库服务。客服端在向服务器发起连接请求时,负载均衡服务器会检查当前请求较少、不是很繁忙的服务节点,并将这个连接请求转到这些实际的服务节点上。这样就可以提供更为高效的、更多吞吐量的乃至更大用户群的Web服务或数据库服务。当前所有较具规模的网站都会采用负载均衡,以便给更多的用户提供高质量服务。
在负载均衡的实现上也有很多种方案。对于需要提供广阔地域性访问的网站首先要采用DNS负载均衡,这样可以让不同地区的用户访问相应地区的服务(不同地区的用户域名解析的地址不同)。而针对地区性服务的节点,则会采用IP负载均衡或反向代理负载均衡,从而满足这一地区用户的访问能力。
环看当今的互联网环境,可谓群雄并起、逐鹿全球,遍地都是互联网公司。大大小小的
网站也是俯拾皆是、让人目不暇接。因此,自从WWW诞生的那一天起,负载均衡就注定
会成为最为流行的一种集群方案,甚至可以畅想遥远的未来也将会是这样的状态。很多会司就瞄准了这个市场,很快就成为了这个行业的暴发户,最具代表的当属F5公司了,在竞争如此激烈的环境下,居然占据了全球负载均衡产品市场的半壁江山。
几乎所有互联网行业的技术从业人员都知道F5的名号,知道它的原因就是这玩意是出了名的贵。要是听说谁用上了F5,没有不竖起大拇指并赞叹一句:“有钱人”的。贵到什么地步呢?20~30万那个是起步价,100~200万的也解决不了太大的问题。要想武装到位,没个千八百万的您就别有啥指望了。这个价码即便是slna、alibaba这样的公认的互联网业巨头也很难吃得下去。
虽然大多数人知道F5价格不菲,但是真正知道它是什么的人却不多。这的确是个很奇怪的事。大多数人说起LV就知道是个包包,说起玛莎拉蒂就知道是辆汽车,说起劳力士就知道是块手表……,可是当说起F5,还真的很少有人知道它是个负载均衡器,更不知道这还是一个NB公司的名号。个中的原因可能是由于负载均衡器在互联行业是一种极其普遍的设备,以至于让人们都快忽略了它的存在,这就是物极必反的道理罢。也正是因为负载均衡器在互联网行业的地位如此重要,使得F5即便价格不菲也并没有让人们对其敬而远之,反倒占据了这个市场的半壁江山。所谓一分价钱一分货,谁不想将自己的服务做到完美呢?经济学的问题咱们就不掰扯了。
F5负载均衡器高效、稳定、耐用、好用等这些优点是毋庸质疑的,这是专有硬件设备应该必备的基本素质。可是总是披着“高贵”的外衣自然就会有人看它不顺眼,同样高效、稳定、耐用、好用又免费的软件负载均衡器就出来挑战了。但是要进行这种挑战是需要勇气的,毕竟软件是要运行在通用硬件设备上的,要跟专用硬件设备抗衡可是有点班门弄斧的感觉的。好在这个世界上从来不缺乏勇敢的人……
15.6.2 一个中国人的勇气
敢于用软件负载约衡来挑战F5这种硬件负载均衡的人有很多,最为著名有:俄罗斯人Igor Sysoev弄出了著名的反向代理服务器Nginx;法国人Willy Tarreau搞出了著名的TCP/HTTP负载均衡器HAProxy;中国人章文嵩在Linux内核中实现了基于地址转换技术的负载均衡器LVS,也就是Linux Virtual Server。
不管从哪个角度去品评,上述三种软负载均衡的实现都非常的棒,极具实用价值。但是要论勇气,我必须力挺章文嵩。这并不是因为他跟我是同事,而且关系还不错而护短,更不是因为他是我的领导而去拍马屁。实在的原因是章文嵩在开发LVS的时候是Linux还大多运行在Pentium II的处理器上的1998年,核心频率最高也就是450Mhz,根本没法跟F5这种专用硬件相抗衡。章文嵩手上的电脑可能还不如PentiumII,但是他下手了,毫不犹豫的下手了,眼中充满了信心。而Nginx和HAProxy都是21世纪的产物,这个时候已经是“笨死”和“扣肉”的天下(奔腾4 酷睿),有谁不敢向F5下手呢?“F10”都没人怕!所以我认为,章文嵩是最有勇气的。因为他的勇气来源于他的自信,其他人的勇气只是源自更加高效平台的支撑,这可是完全不同的概念。而且LVS是基于地址转换技术的,相较于Ngnix和HAProxy更为通用,这也给LVS在这种比较中增加了更多的砝码。所以不管你服不服气,反正我是很服气的。
光有勇气是不够的,因为有勇无谋的只是莽夫之力。艺高人胆大也是不行的,天外有天鹿死谁手是不好说的。LVS之所以能够拥有如此成就并且成为Linux内核的一部分,最主要的是章文嵩拥有能够坚持不懈的勇气,还要耐得住寂寞。而这正是我们大多数人所缺乏的。很多人在一个项目的开始阶段总是雄心勃勃的,但是没过多久就会有一种曲高寡和的凄凉感。因为一个项目的好坏是需要历经实践的考证和时间的洗礼才能够被人们所认同的。而这个阶段是漫长而又凄凉的,没有人理睬你,你必须有足够的勇气去面对,这与你有多么精湛的技术没有任何关系。很多人做不到,章文嵩做到了,所以他成功了。
另外一个比较重要的就是不要被胜利冲昏头脑。名噪一时的Borland不是倒下了吗?曾经不可一世的Nokia不也开始喘不过气来了吗?曾经誉满天下几乎霸占全人类电脑桌面的IE不也开始阳萎了吗?被胜利冲昏头脑,不思进取就是它们落得这份田地的根本所在。这样的例子在计算机行业数不胜数。而在LVS开始被众多用户关注的时候,章文嵩并没有被这突如其来的胜利所冲昏头脑。他意识到LVS还有很多地方需要完善、提高和优化。依然持续不断地花费大把时间将这个并不会给他带来任何“实际利益”的系统做得更好、更完善。到了现在,自然就有了他该有的地位和应得的利益。中国有句俗话:凡事最怕认真二字。态度决定一切,否则就是粗制滥造,即便红极一时,也会被历史所淘汰。
如今章文嵩在阿里巴巴的一个重要工作就是用他的LVS取代F5,而且进展得十分顺利。很多公司也开始了这种尝试,比如sina。我相倍,在LVS和F5之间会有更多的企业倾向LVS。因为章文嵩这种源于自信和坚持不懈的勇气让人们看到了希望。LVS是免费的,而高效性、稳定性、易用性等方面并不输于F5。这又是一个简单的经济学问题,不用掰扯,地球人也都懂。与此同时,勇气这种东西也是会传染的,章文嵩敢做、敢坚持,就会有人敢用。有人敢用,章文嵩就敢继续做得更好,敢继续去坚持自己的梦想。这就像滚雪球一样越滚越大,用的人越来越多。
这是一个中国人的勇气,这种勇气已经散播开来,开始改变了我们的世界。你还等什么呢?
你还等什么呢?这是一本介绍Linux技术书,不是散文集,更不是故事会,刚鼓起来的勇气先抛一边去吧!下面的内容我们得回到正题上来……
15.6.3 LVS的特点 用户态(HAProxy nginx)
LVS与Nginx或HAProxy不同,它是在Linux内核中实现的,是Linux专享的高性能、高可用的负载均衡系统,它具有很好的可伸缩性、可靠性和可管理性。所以,千万别犯傻四处询问在FreeBSD上如何使用LVS。
在Linux内核代码中也找不到LVS这个名称,这是因为LVS只是一种约定俗成的名称。在Linux内核中采用了更为专业化的名称-IP virtual server,简称IPVS,它的源代码在net/netflter/ipvs目录下。所以当有人说Linux的IPVS很牛的时候,也不要犯傻反驳说LVS更牛,它们其实是一个东西。也正是因为这样,用于管理和配置LVS的软件叫ipvsadm。
由于LVS是工作在传输层(七层协议中的第四层,TCP、UDP等)上仅作分发之用,所以没有流量的产生。相较于Ngnix和HAProxy这种工作在应用层的负载均衡系统,具有更强的抗负载能力。也正因为LVS工作在传输层,它的应用范围也比Nginx和HAProxy要广泛,只要是基于TCP/IP协议的应用,它都能做负载均衡。当然,这也使得LVS在某些需要在应用层做处理的场景下不适用,比如Web应用中最常用的动静分离(动态页面和静态页面使用不同的服务器群)方案就不能使用LVS实现。
LVS在使用上是非常简单的,因为没有什么特别需要去配置的东西。有人说这是一个缺点。但是我反倒认为这是优点,因为没有东西可配置,也就减少了人工干预的机会,那么犯错的机会也就降低了。还有什么比不犯错更重要的呢?犯错机率下降了,系统的稳定性也就有了保证。作为服务器系统的最低要求不就是稳定吗?
上述这些内容就是LVS的主要特点。那么LVS的工作原理是什么呢?要弄清楚这个问题,请继续往下看,看看LVS的具体工作模式。
15.6.4 LVS的工作模式
基于LVS的集群在部署的时候需要由前端的负载均衡器(Load Balancer,以下简称LB)和后端真正的提供服务的服务器(Real Server,以下简称RS)群构成,LB和RS之间可以通过广域网或局域网连接。这种部署结构对用户是完全透明的。用户只能看见LB而看不到RS。就好像LB在为用户提供RS的服务一样,所以LB就被称为虚拟服努器(Virutal Server)了。
当用户的请求发往LB的时候,LB会根据预先定义好的包转发策略和负载均衡调度算法将用户的请求转发给某个RS。RS再将用户的请求结果返回给用户。与请求包一样,应答包的返回方式也跟预先定义好的包转发策略有关。
LVS的包转发策略主要有三种:NAT (Network Address Translation)模式、IP隧道(IP Tunneling)模式和直接路由(Direct Routing)模式。
1. NAT模式
NAT模式就是将一个IP地址转换为另一个IP地址的工作方式。当用户向LB发出请求后,LB接收到的数据包所携带的目标IP地址就是LB的IP。LB根据负载均衡调度算法选出一个RS,将这个包的目标IP地址转换成目标RS的IP,并转发给这个RS。在RS看来,这个包就是直接来自用户的,不会意识到有LB的存在。但是需要注意,LB需要被配置成RS的网关,这样当RS向用户发送应答数据时会先发送给LB。LB在接到RS的应答包后,将这个包的源IP转换成LB自己的IP,并转发给用户。用户收到应答后,会认为这个应答就是LB发来的。如果觉得上面的描述不是很清楚,可以参考图15.9所展示昀内容。至于采用NAT模式的LVS集群的部署结构可参考图15.10所示的内容。

你可能会意识到一个问题,就是无论是无连接面向消息的UDP协议还是有连接的TCP协议,其最底层都是采用无连接的IP协议来完成。但是LB会根据负载均衡调度算法来选择一个RS出来,会不会出现同一个TCP连接的不同IP报文转发给了不同RS的情况呢?答案是否定的。LB中有一个Hash表,每次有IP报文到达的时候都会查询一下这个表,找到了就直接做转换操作,只有找不到才执行负载均衡算法选出一个RS,并计入Hash表中。这样就保证了在同一个TCP连接的不同IP报文只会转发给一个RS,对于UDP会话也是同理。可是如果只是简单的这样处理,LB的功能很快就失效了。因为只要在Hash表中有过记录的就不再使用负载均衡算法了。一个折中的方法就是设置超时机制。只要Hash表中的某个记录有一段时间没有被查询过,就将它删除。为了更有效地完成负载均衡任务,LVS还引入了一个状态机,不同的报文会使得状态机处于不同状态,不同的状态可以设置不同的超时值。对于有连接的TCP,这个状态机跟TCP的标准有限状态机一致;对于无连接的UDP,则只设置了一个UDP状态。默认情况下,SYN状态的超时值为1分钟,ESTABLISHED状态的超时值为15分钟,FIN状态的超时值为1分钟,UDP状态的超时值为5分钟。
NAT模式的优点是简单易用且成本低廉。作为RS,可以使用任何支持TCP/IP的操作系统,只要将它的lP地址告诉LB,并将LB作为它的网关即可。但是在NAT模式下,不管是用户的请求还是RS的应答,都要经过LB,这给LB带来了很大的负担。当RS达到一定数量时,LB将会成为整个集群系统的瓶颈。为了解决这种问题,需要采用另外两种工作模式——IP隧道模式和直接路由模式,我们先来看看IP隧道模式。
session保持,不会丢失session导致已经登录变为未登录
2. IP隧道模式 TUN
纵观整个互联网行业,那些面向个人用户的业务,大多都会具有这样一个特点:用户请求的数据量远远低于服务端返回的业务量。比如查看新闻、下载电影等,甚至以用户产生内容UGC为核心的BBS、SNS、微博等业务也是如此,毕竟单个用户所关心的内容量要远高于其所能产生的内容。按照行业上的术语就是非对称式服务。也正因为这样,现今流行的ADSL技术也都会采用这种非对称式模式以期达到降低成本的目的,以ITU-T G992.1标准为例,ADSL在一对铜线上支持上行(用户请求)速率512kbps~1Mbps,下行(服务应答)速率1Mbps~8Mbps,甚至现在刚刚起步的光宽带也是这样设计的,所以想在自己家里搭建一套服务器系统提供对外服务是很幼稚的想法。
根据互联网业务的这种不对称特性,LVS为了降低LB的负载也采用了类似的设计,IP隧道模式就是其中一种。在这种模式下,LB负责接收用户的请求,并将这个请求通过负载均衡算法转发到某个RS,而这个RS则直接将应答发回用户。具体部署图见图15.11所示的内容。
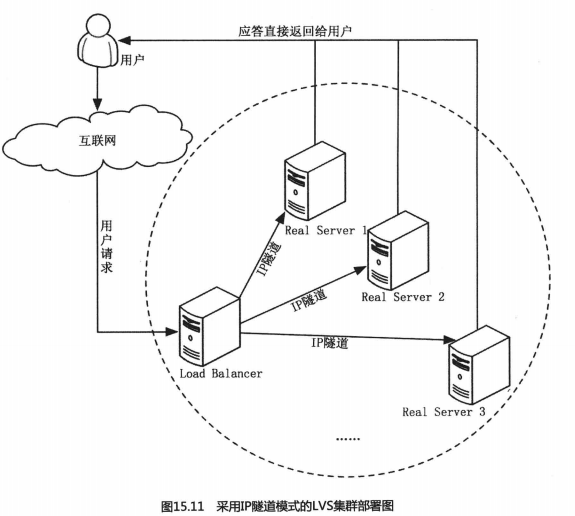
但是你看过这个之后可能会有一些困惑:怎么可能是一个设备接收请求,而由另外的设备返回应答,毕竟它们的IP地址是不同的,对于采用TCP协议的客户端来说根本不在一个连接上啊?
这就是TCP/IP协议妙不可言之处。因为不管是TCP还是UDP,都是建立在IP协议基础之上的,IP地址也只是一个软件特性,并没有说一个机器只能有一个唯一的IP地址。两个机器可以共用一个IP地址,甚至一群机器也可以共用一个IP地址。但是话说回来,如果要通过IP地址访问某个特定机器,那么它的这个IP地址就必须与它唯一确定,而这是通过网卡的物理地址与这个IP地址进行映射而做到的。如果不建立这种映射关系,那么n多个机器使用同一个IP地址向外发送数据,没有谁说过不行。按照行业术语,这种IP地址被称为VIP,也就是Virtual IP Address。喜欢关心国际时事的人肯定对VPN (VIrtual PrivateNetwork)这个名词很熟悉,用它来干什么我想你懂的。对于喜爱追究技术细节的人可能会意识,当接入VPN之后,会发现自己的电脑里会多出一个新的IP地址,比如我的就是10.121.73.48。这个地址对于我的电脑来说,它是一个VIP,同一个局域网内的其他电脑无法直接访问。但是这个IP地址却可以让我了解好多事情的真相。对于TCP连接来说,只要客户端请求的IP地址与应答的IP地址一致,就可以建立一个连接,它可不管这背后有多少个设备。如果想了解更多,可以参考W.Richard Stevens的《TCP/IP详解》。
VPN就是利用IP隧道技术实现的。所谓IP隧道,就是一种将IP报文封装在另一个IP报文的技术。这可以使得目标IP地址为A的数据报文能被封装和转发到IP地址为B的设备上,所以IP隧道技术也被称为IP封装技术。这个IP封包的过程见图15.12所示。VPN所建立的IP隧道是静态的,即隧道的一端有一个固定的IP地址,另一端也有一个固定的IP地址。但是在LVS中所采用韵IP隧道不能这样,因为要将报文转发给一群RS,静态的IP隧道显然不能满足要求。所以只能采用动态策略,选中一个RS就建立一个隧道。LVS与VPN更大的不同之处是,用户向服务器发起请求时所使用的是真实IP,也就是可以直接定位的。那么,RS在应答用户请求的时候,获得的来源IP是真实可访问的。如果RS的VIP与LB所使用的真实IP相同,那么RS利用这个VIP直接向用户发送应答数据,在用户看来这个应答与LB发回的就没有什么区别。实际上,LVS的IP隧道模式也就是这样工作的,RS的应答包并不会通过LB,而是直接发回给用户。
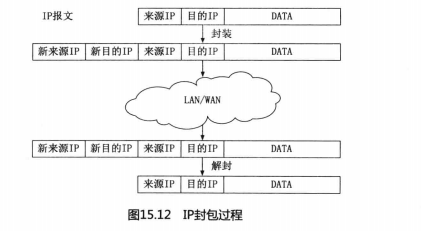
由于在这种模式下,只有请求数据通过LB,而数据量又远低于应答数据,所以整个LVS的集群在吞吐量上就会有很大的提升。在实际测试中,IP隧道模式的吞吐量要比NAT模式提高至少10倍以上,单个LB可以轻松地应对数百台RS的负载均衡调度。但是IP隧道模式对服务器有要求,即所有服努器都必须支持IP隧道协议。不过现在有一个好消息,那就是IP隧道已经成为各种操作系统的标准协议,所以只要你的系统不是很另类,IP隧道模式肯定能玩转。那么口隧道模式就剩下一个缺点了,对IP报文进行二次封包和解包是需要工作量的,这会增加LB和RS的CPU负载。有没有不做IP封包的方法呢?有,那就是直接路由模式。
3. 直接路由模式 DR
经过前面的分析,我们知道IP隧道模式可以提高LVS集群的吞吐量,但是代价是需要对IP报文进行二次封包和解包。而直接路由模式则比较直接而且更为底层,通过修改网络底层的数据帧中的MAC地址来完成包转发的目的。这样LB就不用管IP报文的内容了,只需要负载均衡调度算法,将接收到的网路数据帧中的MAC地址修改成选中的RS的MAC地址,这个包就转发出去了。而RS所收到的就是原始IP报文。余下的工作就与IP隧道模式相同了。所以直接路由模式的LVS集群部署方式与IP隧道模式基本相同,可以参考图15.11所示的内容。
虽然直接路由模式在包转发的过程没有IP隧道模式的那种封包解包负担,但是它有一个十分致命的缺陷。由于是直接修改的网络底层的数据帧中的MAC地址,这就要求LB和RS必须各有一块网卡连接在同一个物理网段上。而IP隧道模式则没有这种限制。
那么在实际应用中,如果需要部署的LVS集群能够保证LB和RS在统一物理网段,那么选择直接路由模式将会拥有更高的执行效率。但是如果需要跨越物理网络,那么IP隧道模式将是首要选择。当然,出于方便,如果集群规模不是很庞大,NAT模式也是一种选择。
15.6.5 LVS的负载均衡调度算法
LVS的三种工作模式已经介绍完了,同时这也是它做负载均衡的基本原理。原理说通了就该说说算法了。也就是LVS是如何选中一个RS的,即负载均衡调度算法。
出于中国人对十全十美的向往,LVS也提供了十种不同的负载均衡调度算法,同时也是目前大多数负载均衡器所采用的调度算法。不管你是否选择使用LVS,即便是只想要F5也会用到这些算法,所以掌握一下还是很有帮助的。那我们就看看这十种算法都是什么吧:
1. 轮询( Round Robin)
LB将外部请求按顺序轮流分配到集群中的各个RS上。这种算法会均等地对待每一
个RS,而不管这个RS上实际的连接数和系统负载情况。
2. 加权轮询(Weighted Round Robin)
LB会根据RS的不同处理能力来调度访问请求。这样可以保证处理能力强的RS处
理更多的访问流量。LB可以自动询问RS的负载情况,并动态地调整其权值。
3. 最少链接( Least Connections)
LB劫态地将网络请求分配给活动链接数最少的RS上。如果集群中的RS具有相似
的性能,采用“最少链接”算法可以获得较好的负载均衡效果。
4. 加权最少链接( Weighted Least Connections)
在集群系统中RS性能差异较大的情况下,LB采用“加权最少链接”调度算法能 够
优化负载均衡的性能。具有较高权值的RS将承受较大比例的活动链接负载。LB可
以自动询问RS的负载情况,并动态地调整其权值。
5. 最小期待延迟( Shortest Expected Delay)
该调度算法基于前述的WLC调度算法,但是会对WLC遇到的一种特殊情形做处理。
比如有A、B、C三个RS的权重分别是1、2、3,而活动链接数也是1、2、3,那
么根据WLC算法计算则三个RS都是备选对象,这时WLC会利用随机数来做任意
选择。而SED则会选择C,因为它所使用的公式是(Ci+l)/Ui,其中Ci代表活动链接
数,Ui代表权值。这个算法可以在这种情形下判断出实际能力更强的RS,那么将
请求分配给它则代表拥有最小的延迟。
6. 最少队列(Never Queue)
该算法是对SED算法的一个调整。当LB发现有RS已经没有活动链接了,则立即
将用户请求转发给它,而除此之外,则运用SED算法。如果不采用NQ算法,那
么SED算法很可能导致某些性能较差的RS永远都得不到用户的请求,这就破坏了
负载均衡的均衡性。
7. 基于局部性的最少链接( Locality-Based Least Connections)
这种调度算法是钟对目标IP地址的负载均衡,目前主要用于缓存(比如Memcache、
Redis等)集群系统中。该算法根据请求的目标IP地址找出该目标IP地址最近使
用的RS,若该RS是可用的且没有超载,则将请求转发到该RS上:若这样的RS
不存在,或该RS超载且有RS处于50%的工作负载,则采用“最少链接”原则选
出一个可用的RS,并将该请求发送到这个RS。对于缓存类集群,这样的调度算法
可以尽最大可能的满足缓存命中或一致性的需求。
8. 带复制的基于局部性的最少链接(Locality-Based Least Connections with Replication)
这种调度算法与前述的LBLC算法差不多,也主要是用于缓存集群中。不同之处在
于,该调度算法要维护一个目标IP地址到一组RS的映射,而LBLC则是一对一的
映射。该算法根据请求的目标IP地址找出目标IP地址对应的RS组,然后再按照
“最小链接”原则从这组RS中选出一个来,若没有超载则将请求转发;若超载了,
则继续按照“最小链接”原则从整个集群中选出一个RS,并将这个RS加入到组
中:与此同时,当该RS组有一段时间没有被修改,则会将最忙的RS从RS组中删
除,以降低“复制”昀程度。这种算法在做到尽最大可能满足缓存命中或一致性需
求的同时,也提高了负载均衡的均衡性。
9. 目标地址散列( Destination Hashing) nginx反代 ip_hash
该调度算法会根据用户请求的目标IP进行Hash运算而得到一个唯一的RS。如果
这个RS当前可用且未超载,那么就将请求转发给它,否则会告诉用户这个请求失
败。大家可能很困惑这种负载均衡调度算法的意义所在,因为它相当于静态绑定了
某个RS,破坏了均衡性。但是一味地追求“均衡”则属于狭义的负载均衡。从广
义上来讲,保证服务的唯一入口也是一种负载均衡。尤其是当使用LVS做防火墙
负载均衡的时候,防火墙需要保持入口的统一,才能更好地对整个链接进行跟踪。
另外,把相同的请求转发给相同的缓存服务器,也可以做到最高的缓存命中率。
10. 来源地址散列(Source Hashing)
该调度算法与DH算法一样,不同的是会根据用户请求的来源IP进行Hash运算而
得到一个唯一的RS。它的通途也是针对防火墙集群的,只不过与DH算法相反,SH
强调的是对内控制。
15.7拳头:module
七种武器最后一种居然是极具争议的拳头,而且是人人都拥有之物。至于是否能上升为强而有利的武器,归根结底还是要看人的造化。
Linux内核的module就是像拳头这样的一种武器,虽然它会跟Linux内核紧紧绑定在一起,似乎只是用来跟硬件打交道。但是你还记得SELinux吗?还记得netfilter吗?还记得LVS吗?这些跟硬件都没有什么直接的关系。这些应用的成功,不断地刺激着人们的眼球。原本“底层”的东西做着完全不“底层”的事情,使得操作系统内核达样一个在大多数人眼中原本都十分神秘的物件儿变得更加光怪陆离,让人难以想像它到底是做什么的!我先在这里介绍一种更为“离奇”的应用,看看是否能够激发一下你的想像空间……
15.7.1 内核中的Web服务
在操作系统的发展历史上,就从来不缺乏偏门的应用,内核中的Web服务就是其中之一。所谓内核中的Web服务,就是运行于操作系统内核空间的HTTP服务,更为好听的名字是:Web加速器。
这类应用的优点是显而易见的,就是速度快并发强。因为数据的到达十分直接,不需要经过复杂的从内核空间到用户空间的传递过程。网络事件的通知也不需要这样的传导过程,用户空间永远都做不到。
这类应用的缺点也十分要命。首先,稳定性将要经受到最严厉的考验,因为一旦出现问题,很可能导致内核崩溃。另外,由于运行于内核上的代码拥有“至高无上”的特权,一旦这类应用存在安全漏洞,将没有任何安全机制能够阻挡系统大门被洞开。更进一步,这种设计根本没有移植性。操作系统有千万种,实现方式就有千万种,你只能去钟爱一两种。
但是人们这种追求性能极致的欲望如同瘾君子们追求毒品所产生的快感一样,明知走下去就是万丈深渊但依1日义无反顾。内核中的Web服务,Solaris宥NCAKmod,Windows有http.sys(IIS的一部分),HP-UX有NSAhttp。Linux也从来不甘寂寞,kHTTPd和TUX就是出头之鸟。
从Linux 2.4.13开始,在Networking options中出现了一个实验性的选项——“[]Kemelhttpd acceleration(EXI’ERIMENTAL)”,这就是kHTTPd。kHTTPd以一个内核module形式存在,只能处理静态的Web页面。对于所有的非静态内容的请求则传递给诸如Apache这样的用户空间Web服务器来处理。静态Web页面对于HTTP服务器来说是一件相当小儿科的功能,但却是Web服务中最为重要的部分。因为至少网站中大多数图片数据都是静态的,对于以新闻为主的门户型网站其整个新闻页面甚至全部都是静态Web页面。所以通过内核来完成静态Web页面的处理,就能够在很大程度上加速网站的Web服务。不过很可惜的是,kHTTPd并没有得到Linus和大多数内核开发者的支持,2.6内核之后,kHTTPd消失在人们的视线中了。
比kHTTPd稍微幸运一点的是TUX。一是TUX系出名门RedHat,一般人不敢不给它点面子;二是在TUX诞生之初就获得了Dell的大力支持。这两方面的因素使得TUX 一直坚持到了Linux 2.6的内核。最新版本是TUX3.支持的最高版本内核是2.6.18。TUX与kHTTPd的设计思路是相同的,只是加速静态Web页面的访问。但是TUX最终还是没有逃脱掉与kHTTPd相同的命运,已经淡出了人们的视线。
之所以kHTTPd和TUX最终的命运都是相同的,这恐怕与Linux所继承自Unix的KISS文化有关吧。随着计算机技术的不断进步,执行效率已经不再是优先考虑的因素。取而代之的则是正确性、稳定性乃至安全性。利用在内核空间所获得的效率加速,远远无法弥补因此带来的稳定性和安全性等方面的损失。这种得不偿失的做法,还有谁会赞同呢?
虽然Linux下的这两个内核中的Web服务产品都是以失败告终的,但这种尝试的意义却是深远的。它使得人们可以从另外的角度去理解操作系统内核,面对冰冷枯燥的硬件已成为过去,迎接的应该是激情火热的实际应用。人们这种观念上的转变,使得无论kHTTPd和TUX的最终结局如何,我都认为它们是不朽的。原因就是新型的与它们类似的应用已经开始不断地涌现了。
15.7.2 编写你的第一个module
作为程序员,在介绍一个新型编程语言或编程技术的时候,不免需要有一种比较俗套的开端,这就是“Hello World”,尽管本书一直在想尽办法脱离这种俗套,但我的能力实在有限,始终做不到脱俗。或许这是你人生第一次编写Linux的内核module,足够简单才是硬道理。所幸就继续俗一次也没什么大不了的,是不是?好,那么我先介绍一下这个模块生成之后你要做些什么事情。
首先,这个模块的名称叫frrst- time.ko,代表这是你第一次编写内核模块。你需要使用这样的命令:
#insmod first_time.ko
来安装这个module。这会使得你的屏幕上立即显示出“Hello,world!”这个信息,它代表着你的模块来到这个世界上发出的一声叹息。当然,这个module并没有实际上的作用,所以你很快就要卸载它。你需要使用这样的命令:
# rmmod first_time.ko
这时,你的模块将向你发出它心中最后的呼唤:“Goodbye my lover!”虽然这个过程似乎那么迅速又那么无比的伤感,但是它足以向你表明内核module是个什么样子,是如何与内核“纠缠”的,“大师们”是如何编写它们的。顺便说一下,你得在root权限下才能操作成功。
接下来,就选择一个你十分偏爱的编辑器,vim、emacs,抑或是其他别的什么,写下这些代码吧!见代码11。
代码11:
#include <linux/init . h>
#include <linux/module . h>
MODULE_LICENSE ( " GPL " ) ;
MODULE_AUTHOR ( " Jagen " ) ;
MODULE_DESCRIPTION ( " first_time " ) ; modinfo
MODULE_VERSION ( " I1. 0 " ) ;
static int __init first_time_init {void)
{
printk ( KERN_ ALERT " Hello , world ! \n " ) ;dmesg
return ;
}
static void __exit first_time_exit ( void)
{
printk ( KERN_ALERT " Goodbye my lover ! \n" ) ;
}
module_init(first_time_init);
module_exit(first_time_exit);
这段代码足够简单,你也会发现它与普通的C程序有很大的不同,那就是没有main()
函数。没有main()函数并不代表没有入口函数,只是module的入口函数名称不固定,需要使用module_init()宏来定义。另外,C语言程序有一个不常用的atexit0函数,是在main()函数正常返回之后自动被调用的一个“程序出口函数”。这样的函数在module中也有,就是由module_exit()宏指定的函数。可能比较熟悉C语言的程序员会认为我在胡诌,因为module_init()和module_exit()从命名上看应该是函数而不是宏。但事实上它们的确是宏,而
且定义在linux/init.h文件中,不相信你可以去看(宏一般定义在头文件中)。至于为什么这么命名,或许是因为Linux
内核开发者们不希望大家将它们看作是宏吧!
程序中用到的比较明显的宏是MODULE_ LICENSE、MODULE_AUTHOR、MODULE_DESCRIPTION和MODULE_VERSION,它们是在linux/module.h文件中被定义的,主要用于产生module的描述信息。可以通过命令modinfo来查看。作为这个例子,执行命令:
# modinfo first time . ko
之后,应该能看到类似这样的信息:
filename : first_time . ko
version : I1.
description : first_time
author : Jagen
license : GPL
srcversion : 8F7 6F4FIADIEB4783 9BB
对于printk()这个函数就没啥可说的了,跟C的printf()库函数没啥太大区别。只是需要注意的是前面的那个日志级别,这个是printf0所没有的。printk0会根据日志级别来决定是否把消息打印到当前控制台上。决定的因素是日志级别是否小于console_loglevel值。往控制台输出日志不一定是大多数人所希望的,所以就有了另外的选择——dmesg。无论这个日志级别是否低于console_loglevel的值,使用dmesg都能够查看到。
这个module的代码介绍完了,接下来就该去编译它了,需要用到Makefile。如果你现在还没有将第8章的知识就饭吃了的话,现在就有了用武之地了(就饭吃了也不要紧,回头看看便是)。别忘了先将代码保存为first time.c。具体Makefile文件的内容见代码12所示,这是一个通用的Makefile文件:
代码12:
ifeq ( $ (KERNELRELEASE) , )
KERNELDIR ?= /lib/modules/$ (shell uname -r) /build
PWD := $(shell pwd)
modules :
$ (MAKE) -C $ (KERNELDIR) M=$ ( PWD) modules
modules_install :
$ (MAKE) -C $ (KERNELDIR) M=$ ( PWD) modules_install
clean :
rm -rf k. t_ core .depend.*.cmd *.ko *mod.c .tmp_versions
. PHONY : modules modules_install clean
else
obj -m : = first_time . o
endif
这是一个通用的编译module的Makefile文件,只需要根据实际情况去修改obj-m这个变量的值就行了。至于这段Makefile代码是什么含义,我不准备解释,原因是有第8章的内容,那里面已经说得很清楚了。可以额外提醒一下的是这是一个递归式的Makefile,“M=$(PWD)”这个命令行参数起到了决定性作用。
余下的需要做的事情就是将这个Makefile和first_time.c放在任意的路径下,然后执行make命令即可。如果你发现编译失败了,请安装kernel-devel这个包(在RedHat/CentOS上
是这样的)。编译成功了就会生成firsttime.ko这个module。实验一下,看看是不是跟我们之前描述的一模一样(注意是控制台,伪终端请使用dmesg查看printk()的输出)。
15.7.3 module与普通程序的不同
虽熬module与普通程序一样,它们都是程序。但是不管怎么样,module都与普通程序有很大的不同,因为它是内核程序。
1. 请求驱动执行
作为内核程序,不能像普通程序那样从头至尾地处理一个任务,只能是向内核申明(注册)自己将来能够服务于特定的请求。换句话说,所谓的module入口函数,实际上就是为以后内核回调module的函数做准备工作。这就表明,module入口函数不像普通程序的main()
函数那样伴随程序的整个生命周期,而是完成初始化工作后会立即终止。我们称这样的程序
执行模式叫——请求驱动执行。
module之所以是请求驱动执行,与内核的并发执行环境有关。大多数的普通应用程序都是过程驱动按顺序执行,拥有多个进程或线程是一个明显的例外。而作为操作系统内核没有多个进程或线程才是奇怪的事情。而且进程或线程所产生的并发都属于少数情况,更多的则是各种设备所产生的中断。负责某个任务的module要随时应对这样的情况,其执行条件完全是无序的,甚至是混乱的。那么这种情况就需要根据不同的请求来执行相关的代码才能有效应对。
更进一步,对于请求驱动执行的module程序,要时刻保持对并发问题的警醒,因为谁
都无法预计诸求什么时间来,从什么地方来。这就要求module程序的代码必须是可重入的
它必须能够同时在多个上下文中运行:数据结构必须小心设计以保持多个执行线程分开;代
码必须小心存取共享数据,避免数据的破坏或本身的Crash。不要以为这是个简单的事情,当遇到多CPU的情况将会更麻烦,调试起来也不容易。
2. C库函数和API的使用
其实我非常不忍心提到这个话题,原因就是对大多数C语言高手或Linux应用程序编程
专家非常不公平。在遇到module编程之后,他/她们历经数年刻苦修炼所掌握的“武功”全都给废了。也就是说C库函数和API都没法用了。
如果还想抱有一丝希望的话,也就是C库函数还能剩下几个,不过也不多。除了几个用
于字符串处理的函数能用外,其他的都不行。这主要的原因是module运行在内核中,我们
所熟知的API都不存在,或者说都是它们本身的实现。既然API都不存在,那些使用API的C库函数自然也就没法工作。之所以处理字符串的函数能存在,就是因为它们不调用API。所以判断的依据就是跟API无关的能不能用不一定,跟API有关的肯定不能用。
那既然C库函数和API都不能用,该怎么写module程序呢?不要紧,Linux内核本身提供了一部分C库函数,同时也为module提供了一整套API。但是也有一个不幸的消息得跟你说一下,Linux的内核API就从来没稳定过,经常的变来变去。唯一的方法就是紧紧跟随内核脚步,很多时候你还真未必跟得上。所以作为Linux的module程序员,那才是真正的“苦逼”。相反,Linux的应用程序员,真的可以是“酷毙”了。
3. 没有4G内存空间可以用
内核只有IG的虚拟内存空间,而且还是针对整个内核的,对于module来说,它们只能是共享这IG,自己能够分到的基本上都少得可怜。当然,这部分是针对32位的Linux系统而言,但是同样适用于64位系统。需要记住的就是module能使用的内存跟普通应用程序不在一个数量级上。
一个最好的例子就是普通应用程序可以有一个非常大的堆栈区间。堆栈,就是用来保存函数调用历史以及所有当前有效的局部变量。对于module,堆栈将非常小,很有可能只有一个内存页面,也就是4096字节。所以module的函数调用层级应该受到严格控制,而且局部变量也应该尽可能的少。对于使用堆栈的数组类型,就别使用了。
4. 其他细节问题
在翻开Linux内核代码的时候,经常会遇到带有双下划线“___”做前缀的函数名。这表明这个函数是一个底层的接口,尽量不要直接使用。因为它比API还不稳定,随时都会有变化。
另外,module代码不能做浮点运算。因为使用浮点运算将要求内核在每次进出内核空
间的时候保存和恢复淳点处理器的状态——至少在某些CPU体系上是这样的。而且module真没有需要做浮点运算的地方,如果你有这方面需求,那就考虑换种思路吧,走下去就是
深渊。
对于module与普通程序的不同,本书就介绍到这里。有兴趣的可以参考其他方面的书
籍,优秀的有很多,我就不列举了。同时也希望这些内容不至于打击到那些希望进入Linux内核开发领域的人,因为对于有一颗火热而又坚强的心脏的人,这些什么都不是!
15.7.4 module与用户通信
作为一个module不能与用户进行有效的沟通,将是极其郁闷的事情。可以说不管什么类型的module,都需要与用户沟通,因为有人用才有存在的价值。Linux已经为module与用户的沟通铺好了路、搭好了桥。我接下来就要介绍几种,至于想成为module开发者的你,是“走阳关道还是过独木桥”就悉听尊便罢!
1. ioctl方式
ioctl是作用于文件描述符的系统调用,可以作为使用/proc文件系统的另外一种选择吧。ioctl获取信息的使用方法比使用/proc稍微麻烦一些,除了需要从驱动程序拷贝相关的数据结构到用户空间,你还需要另一段程序调用ioctl并显示结果。驱动程序的编写和编译要与
你的用户空间程序保持同步。
种瓜得瓜,种豆得豆,虽然前期准备工作化费了点功夫,但ioctl方式比读取/proc更加
快速。如果在数据写到屏幕之前必须对它进行处理,以二进制形式获取数据比读取一个文本文件更加高效。此外,驱动程序里可以潜伏未公开的ioctl命令,而/proc文件是对查看该目录的所育人都可见的,所以有时候我们会产生疑问“这些奇怪的文件到底是做什么用的?”。
看来了解ioctl方式是值得的,下面我们介绍它在用户空间和内核空间的实现方法。
ioctl在用户空间使用时函数定义是这样的:
#include<unistd.h>
int ioctl( int fd, int request, …/*void *arg*/ );
第一个参数就是文件句柄,你要操作哪个设备就得打开哪个文件,别忘了一切皆文件这
回事儿。
第二个参数是请求,请求由以下字段组成:
● 类型
魔数magic number,8bits宽(_IOC _TYPEBITS)。在选择数字前先阅读一下内核源码所带的
《ioctl-number.txt》这个文档,避免重复定义。
● 序列号
8bits宽(_IOC _TYPEBITS),序列数字。
● 方向
数据传输方向。有四种定义,无数据方向(_ IOC_NONE),数据从设备读到用户空间
(_IOC__ READ),数据从用户空间传给设备(_IOC_WRITE),双向数据
(_IOC_READ_UOC_WRITE)。
● 长度
用户数据的长度。一般13或14bits(_IOC_SIZEBITS)。使用这个参数可以帮助检查用
户空间的编程错误。但是如果你有更多的数据要传怎么办?不要紧张,内核并不检
查size这项,你可以忽略它。
为什么要将请求参数定义得如此复杂呢?在定义序列号的时候,很多编程人员第一个本能就是选择一系列小数字,从1开始往下算。但是Linus大叔不那么做,自然有他的原因。如果命令请求的数值不唯一的话,就有可能把一个命令发送到错误的设备上。例如由于一个程序员的疏忽向一个音频设备上发送波特率修改的指令。但是如果请求参数的数值是唯一的话,应用程序就不会执行这种不可预测的操作,而是返回EINVAL错误值。那么怎样才能保证请求参数是唯一的呢?上面讲述的组合方法就可以保证,就像中国身份证号码是由省市地区与出生年月等字段组合而成来保证唯一性一样。
第三个参数总是一个指针,但指针的类型依赖于request参数。省略号表示这个函数有多个参数。但是在实际的系统里,参数个数不可能是不确定的。系统调用是用户访问硬件的“门”,必须有预先定义好的原型。因此这些点实际上并不代表有可变数量的参数,而是一个选择性的变量,传统定义为char *arg。这些点的目的仅仅是为了避免在编译过程中做类型检查。
在驱动程序中实现的ioctl函数体内,实际上是有一个switch {case} 结构,每一个case对应一个命令码,做出一些相应的操作。当走到default选项时,就有一个有争议的问题。一些内核函数返回不合法的变量EINVAL,感觉上是对的,确实是不合法的变量。但是在POSIX标准中要求不合适的ioctl命令要返回ENOTTY这个错误值。这个错误值由C库翻译成“对设备来说不合适的ioctl”,这个表达才是编程人员想要用户知道的。但是对于不合法的ioctl命令操作,函数返回EINVAL很普遍,这就是习惯的力量吧。在定义返回数值这个小小的问题上反复推敲,也体现编程人员的一种精益求精的态度。
因为命令码非常的不直观,所以Linux Kemel中提供了一些宏,这些宏可根据便于理解的字符串生成命令码,或者是从命令码得到一些用户可以理解的字符串以标明这个命令对应的设备类型、设备序列号、数据传送方向和数据传输尺寸。
内核实现ioctl0函数的是sys_ioctl(),执行的路线图是:
sys_ioctl==> vfs_ioctl==> file_ioctl==>unlocked_ioctl
ioctl搡作最终执行f_op->unlocked ioctl,如果没有unlocked_ioctl那就返回ENOTTY错误。我们可以从vfs_ioctl的函数实现中找到证据。
static long vfs_ioctl (struct file *filp, unsigned int cmd, unsigned long arg)
{
int error = -ENOTTY;
if ( ! filp->f_op || ! filp->f_op->unlocked_ioctl)
goto out;
error = filp->f_op->unlocked_ioctl ( filp, cmd, arg) ;
If ( error == -ENOIOCTLCMD)
error = -ENOTTY;
out
return error;
}
在kernel 2.6.36版本中unlocked_ ioctl取代了用了很久的ioctl。unlocked _ioctl与ioctl相比做了什么改动?为什么要这么改?主要的改进就是不再需要上大内核锁,即调用之前不再先调用lock_kernel(),处理完以后再unlock_kernel()。别看这不起眼的大内核锁,去掉它还是需要一定的魄力的。这里面涉及一个辛酸的故事。
早期Linux版本对对称多处理器(SMP)的支持非常有限,为了保证可靠性,对处理器之间的互斥采取了“宁可错杀三千,不可放过一个”的方式:在内核入口处安装一把“巨大”的锁Big Kernel Lock (BKL),一旦一个处理器进入内核态就立刻上锁,其他将要进入内核态的进程只能在门口等待,以此保证每次只有一个进程处于内核态运行。这把锁就是大内核锁。但是这样粗鲁地加锁缺点是显而易见的:多处理器对性能的提升只能体现在用户态的并行处理上,而在内核态下还是单线程执行,完全无法发挥多处理器的威力。
ioctl处的BKL的命被革掉以后,还有不少内核函数会依赖大内核锁,革它们的命可不是一件容易的事。这是一场艰苦卓绝的斗争,因为铲除大内核锁的难度和风险巨大,一步一步解决才能将大内核锁替换为新的互斥机制。终于在2.6.39版本中,随着Amd Bergmann的一个补丁,BLK被彻底地赶出了内核。
当然你的应用程序里面不用关心unlocked_ ioctl,因为系统调用ioctl是没有改变的,还是原来的系统调用接口,只是系统调用的实现中,vfs_ioctl()变成了unlocked _ioctl,应用层根本不用关注内核中的这些实现上的改变,你只需要按照原有的系统调用方法使用就可以了。
2.syscall方式 进程和内核打交道和硬件打交道要通过系统调用

进程与内核通信很多时候是通过系统调用完成的。当一个进程向内核请求服务时,例如打开文件、fork 一个新进程或申请更多的内存空间等,如果你想看程序使用了哪些系统调用,使用strace命令一看便知。
系统调用处理程序和其他异常处理程序的结构类似。在进程的内核态堆栈中保存大多数寄存器的内容,这么做是为了保存恢复进程到用户态执行所需要的上下文,然后调用相应的系统调用服务例程sys_xxx处理系统调用。内核利用了一个叫系统调用分派表(dispatch table)的东东把系统调用号与相应的服务例程关联起来。关联的方法也十分简单,就是把这个表存放在sys_call_table数组中,里面有若干个表项,第n个表项对应了系统调用号为n的服务例程的入口地址的指针。最后通过ret_from_sys_call()从系统调用返回。代码13是使用syscall方式的模块编程的一个演示代码。
代码13:
#define _NR_syscalldemo 240
static int (*demo_func) (void) ;
static int sys_syscalldemo ( struct timeval *tv)
{
struct timeval ktv;
MOD_INC_USE_COUNT ;
do_gettimeofday ( &ktv) ;
if (copy_to_user ( tv, &ktv. sizeof (ktv)) ) {
MOD_DEC_USE_COUNT ;
return -EFAULT;
}
MOD_DEC_US E_COUNT ;
return ;
}
int _init init_addsyscall (void)
{
extern long sys_call_table [ ] ;
demo_func = (int (*) (void) ( sys_call_table [_NR_syscalldemo] ) ;
sys_call_table [_NR_syscalldemo] = (unsigned long) sys_syscalldemo;
return ;
}
int _exit exit_addsyscall (void)
{
extern long sys_call_table [ ] ;
sys_call_table [_NR_syscalldemo ] = ( unsigned long) demo_func;
}
moudle_init ( init_addsyscall) ;
moudle _exit ( exit_adsyscall) ;
代码14是一个应用这个系统调用的程序。
代码14:
#include<linux/unistd . h>
#include<sys/time . h>
#define _NR_ syscalldem0 240
_syscalll( int, syscalldemo, struct timeval*,thetime)
struct timeval tv;
int main ( )
{
syscalldemo (&tv) ;
printf ( " tv_sec : %ld\n" , tv* tv_sec) ;
printf ( " tv_nsec : %ld\n" . tv . tv_usec) ;
printf( “ secs passed. \n”);
sleep ();
sysc alldemo (&tv);
printf(“tv_sec: %ld\n", tv.tv_sec);
printf(“tv_nsec:%ld\n",tv.tv_usec)j
}
在Intel CPU下,系统调用使用中断0x80来触发。一旦你跳到内核的领地,你就可以随意做任何事情。编写内核module代码时切记认真仔细,否则有可能引起kemel panic。
3.procfs方式
在“一切皆文件”的Unix/Linux哲学思想指导下,可以将对procfs的读写作为与内核中实体进行通信的一种手段,但是与普通文仵不同的是,这些虚拟文件的内容都是动态创建的。procfs与块设备无关,它只存在内存里。需要特别声明的是/proc/sys是sysctl文件,它们不属于procfs,而是被一套完全不同的内核API所统治。
监控系统运行状态的top工具就是通过从/proc目录来获取相应的信息的。看懂top源代码还是需要下一番功夫的,我举个简单的例子帮助你理解procfs的工作方式。在内核中我们开辟一个缓冲区,然后在用户态下对它进行读写。代码15是module中procfs的初始化函数。
代码15:
int init_demo_module ( void )
{
int ret = ;
DEMO_buffer = ( char *) vmalloc ( MAX_DEMO_LENGTH ) ;
if ( ! DEMO_buf fer) {
ret=-ENOMEM;
} else {
memset( DEMO_buffer, ,MAX_DEMO_LENGTH);
proc_entry=create_proc_entry( “demo”, , NULL);
if (proc_entry==NULL){
ret=-ENOMEM;
vfree (DEMO_buf fer);
printk (KERN_INFO “demo: Couldn't create proc entry\n”);
} else {
DEMO_index=;
Next_demo=O;
proc_entry->read_proc=demo_read;
proc_entry->write_proc=demo_write;
proc_entry->owner=THIS_MODULE;
printk( KERN_INFO “demo: Module loaded. \n”);
}
}
return ret;
}
在模块的初始化程序中我们用vmalloc分配内存,然后用create_proc_entry(“demo”,0644,NULL)创建一个名字叫demo、父目录文件模式为644的文件,NULL意味着在procfs根曰录下产生文件。如果调用成功,函数会返回一个指向新产生的proc_dir_entry结构的指针,否则返回NULL。接下来我们注册读写函数、方式和所有权。procfs是通过回调函数来实现特殊文件的读写。你需要根据实际情况实现自己的proc文件的读写函数。
模块编写和编译成功后,我们就可以执行下面的命令读写测试:
# cat /proc/demo
# echo "Hello world! " > /proc/demo
4. netlink方式
netlink通过为内核模块提供一组特殊的API,并为用户程序提供了一组标准的socket接口的方式,实现了一种全双工的通信连接。类似于TCP/IP中使用AF_INET地址族一样,netlink使用地址族AF_NETLINK。这种通信机制相对于系统调用、ioctl以及/proc文件系统而言具有以下优点:
(1) netlink使用标准的socket API,易用性好。用户仅需要在flinux/netlink.h中增加一
个新类型的netlink协议定义即可,如#defrne NETLINK_MYTEST 17。然后,内核和用
户态应用就可以立即通过socket API使用该netlink协议类型进衍数据交换。但用其
他方法增加新的特性可不是一件容易的事情,因为我们要冒着污染内核代码并且可
能破坏系统稳定性的风险去完成这件事情。系统调用需要增加新的系统调用,ioctl
则需要增加设备或文件,那需要不少代码,proc文件系统则需要在/proc下添加新的
文件或目录,那将使本来就混乱的/proc更加混乱。
(2) netlink是一种异步通信机制,在内核与用户态应用之间传递的消息保存在socket
缓存队列中,发送消息只是把消息保存在接收者的socket的接收队列,而不需要等
待接收者收到消息,但系统调用与ioctl则是同步通信机制,如果传递的数据太长,
将影响调度粒度。
(3)使用netlink的内核部分可以采用模块的方式实现,使用netlink的应用部分和内核部
分没有编译时依赖,但系统调用就有依赖,而且新的系统调用的实现必须静态地连
接到内核中,它无法在模块中实现,使用新系统调用的应用在编译时需要依赖内核。
(4) netlink支持多播,内核模块或应用可以把消息多播给一个netlink组,属于该netlink
组的任何内核模块或应用都能接收到该消息,内核事件向用户态的通知机制就使用
了这一特性,任何对内核事件感兴趣的应用都能收到该子系统发送的内核事件。
(5)内核可以使用netlink首先发起会话,但系统调用和ioctl只能由用户应用发起调用。
不仅如此,对于我这种钟爱BSD风格的开发者来讲,使用这种socket API函数有一种亲切感,相对于系统调用或者ioctl方式而言上手更快一些。
netlink的由来:net+link netlink地址族 连接内核态和用户态
15.7.5 内核加载module的原理
当我在想如何讲清楚Linux模块加载时,我制作的乐高机器人乐乐突然浮现在我脑海里。前一段时间我用可编程控制器、颜色传感器、触动传感器、方梁、薄连杆、厚连杆、连接销、轴、轴套和电池等多种零部件组装了一个能够行走和识别颜色的机器人。当然你也可以根据需要设计选取不同的零部件组装自己的机器人。它可以为你提供开饮料瓶、打印文档和破解魔方等不同服务,如果你是玩摄影的,还可以做一个全景云台。除了零部件,乐高公司还提供了图形化编程工具帮助你开发机器人的控制软件。Linux module的加载机制与机器人这种组装理念很类似,要加载的内核模块可以使用别的模块提供的变量或函数,内核管理工具可以帮我们把整个依赖关系梳理好并组装起来。
kmod是一套用来处理与Linux内核模块相关的任务的工具,例如实现模块的插入、删除、列表、特性检查、解析依赖和别名等,比早年的module-init-tools工具更强大。有了这个工具,我们再来看看内核是如何加载我们的moudle,让它在系统中安营扎寨的。隐藏在内核模块管理守护进程kmod背后的机制十分简单但很实用。一旦内核试图访问某种资源并发现该资源不可用时,它会向kmod子系统寻求帮助,会对kmod进行一次特殊的调用。kmod就会执行modprobe去加载相关的模块以获取该资源,如果它成功则内核继续工作,否则将返回错误。module的具体加载过程如图15.13所示:
P552 mmap在内核空间 在编写完驱动程序后把它编译成mmap.ko文件,然后用insmod/modprobe方式加载此驱动模块。由于这是一个字符设备驱动,我们还需要用mknod /dev/mmapo c Major Minor建立一个目录项和一个特殊文件的对应索引节点。Major和Minor表示主设备号和次设备号 ll /lib/modules/2.6.-.el6.x86_64/kernel/
total
drwxr-xr-x. root root Jul arch
drwxr-xr-x. root root Jul crypto
drwxr-xr-x. root root Jul drivers
drwxr-xr-x. root root Jul fs
drwxr-xr-x. root root Jul kernel
drwxr-xr-x. root root Jul lib
drwxr-xr-x. root root Jul mm
drwxr-xr-x. root root Jul net
drwxr-xr-x. root root Jul sound
ll /etc/modprobe.d/ #配置内核可加载模块的加载顺序 Linux就这个范儿 P627
total 32
-rw-r--r--. 1 root root 52 Jul 10 2015 anaconda.conf
-rw-r--r--. 1 root root 884 Oct 16 2014 blacklist.conf #黑名单不加载
-rw-r--r--. 1 root root 382 Oct 15 2014 dist-alsa.conf
-rw-r--r--. 1 root root 473 Oct 15 2014 dist-oss.conf
-rw-r--r--. 1 root root 5596 Oct 15 2014 dist.conf
-rw-r--r--. 1 root root 49 Jul 10 2015 ipv6.conf
-rw-r--r--. 1 root root 30 Oct 10 2009 openfwwf.conf
ll /lib/modules/2.6.-.el6.x86_64/
total
lrwxrwxrwx. root root Jul build -> ../../../usr/src/kernels/2.6.-.el6.x86_64
drwxr-xr-x. root root Oct extra
drwxr-xr-x. root root Jul kernel
-rw-r--r--. root root Jul modules.alias
-rw-r--r--. root root Jul modules.alias.bin
-rw-r--r--. root root Oct modules.block
-rw-r--r--. root root Jul modules.ccwmap
-rw-r--r--. root root Jul modules.dep
-rw-r--r--. root root Jul modules.dep.bin
-rw-r--r--. root root Oct modules.drm
-rw-r--r--. root root Jul modules.ieee1394map
-rw-r--r--. root root Jul modules.inputmap
-rw-r--r--. root root Jul modules.isapnpmap
-rw-r--r--. root root Oct modules.modesetting
-rw-r--r--. root root Oct modules.networking
-rw-r--r--. root root Jul modules.ofmap
-rw-r--r--. root root Oct modules.order
-rw-r--r--. root root Jul modules.pcimap
-rw-r--r--. root root Jul modules.seriomap
-rw-r--r--. root root Jul modules.softdep
-rw-r--r--. root root Jul modules.symbols
-rw-r--r--. root root Jul modules.symbols.bin
-rw-r--r--. root root Jul modules.usbmap
lrwxrwxrwx. root root Jul source -> build
drwxr-xr-x. root root Oct updates
drwxr-xr-x. root root Jul vdso
drwxr-xr-x. root root Oct weak-updates 输入参数,包括内核模块名或通用标识符 (内核模块名:比如e1000; 标识符 char-major-- mknod /dev/mmapo c Major Minor)
modprobe接受,它支持两种参数的传递
通用标识符
在文件/etc/modprobe.conf或/etc/modules.conf中通过别名找出通用标识符所对应的模块名 (modprobe.conf常用选项:alias:方便我们使用更易懂的名字alias eth0 bnx2 options指定模块选项)
/etc/modprobe.d/ #配置内核可加载模块的加载顺序 Linux就这个范儿 P627
遍历文件/lib/modules/内核版本/modules.dep (模块依赖关系 该文件由depmod -a 命令建立的,保存了内核模块的依赖关系,使得在装入指定模块前装入那些事先需要装入的模块)
调用insmod先加载被依赖模块然后加载被该内核要求的模块 (模块加载路径: /lib/modules/内核版本/kernel为默认标准存放内核模块的目录。insmod要求加上模块所在目录的绝对路径,并且要带模块文件的后缀.o或.ko)
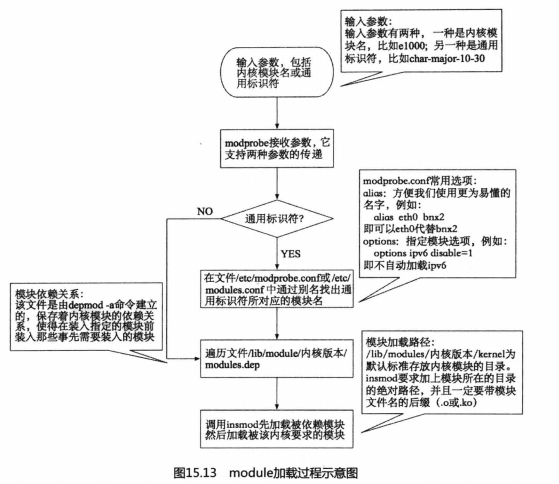

modprobe、insmod和depmod包含在一个名为modutils或mod-utils的工具包内。这些工具帮助你自动或手动地装载模块。有的时候你想人为控制一个模块什么时候被装入,例如当装入某个模块会导致问题时,你不想让某个模块被kerneld自动装入,你可以把这个模块列到黑名单中不让它跨进内核的大门。其中一个方法是通过在GRUB、LILO或Syslinux使用内核命令行禁用该模块。例如如果我们想禁用ipv6模块的话,就当GRUB启动时在/boot/grub/menu.lst中加入kernel /vmlinuz-linux root_/dev/sdal ipv6.disable=1 ro来达到此目
的。当然禁止模块自动载入的方法不少,我这里就不再赘述了。
还有一点需要说明,内核模块和内核版本有密切关系。如果遇到某个版本下编译的内核不能被另一个版本的内核加载,你需要在这个版本的内核下重新编译一下模块,或者关闭CONFIG_MODVERSIONS内核选项重新编译一个新内核。随着内核的不断发展,模块的运行机制也在改进。在Linux 2.6的开发历程中,为了使系统更稳定和更透明,许多代码被重写。我们最直接感觉到的是Linux 2.6中内核驱动程序的文件扩展名改变了,“.ko”取代了“.o”。
这表明模块不是真正的中间文件,而是内核目标文件。除了这个明显的表层的变化之外,还
有隐藏在背后更深层次的改进。
在Linux 2.6之前,驱动模块是智能型的,它的加载是通过扫描总线寻找它识别的设备
ID号来实现。Linux 2.6把这部分功能做了梳理,化复杂为简单,硬件检测外部化。利用外部程序以及模块加载器来判断模块支持哪些设备。除了insmod与rmmod外,Linux2.6加载命令还有modprobe。modprobe同时会加载当前模块所依赖的其他模块。在Red Hat Linux中,还可以使用PnP设备的检测程序kudzu来检测和配置硬件。例如使用:
kudzu --probe --class=network
命令用来检测网卡等信息。
调试module的技术主要有以下几种:
1. 用printk打印调试,是最简单有效的方法之一;
2. 使用日志文件保存调试信息;
3. 使用truss、strace和ltrace命令输幽信息来调试;
4. 使用调试器调试。
15.8结束语
终于将Linux的七种武器全部展现在你的面前了。笑、相聚、自信心、诚实、仇恨、勇气、不放弃……你心中有答案了吗?
David Cutler
http://baike.baidu.com/link?url=BN6X5L_0XRQDPXDkuDq4K_Dd-PSZN6-bCWErAG44s0_Ld32RJX3EHaVMzwu3R4vDsxqRL5J_BJ9k9hgIEkGCN_
大卫·卡特勒(David Cutler),书中又叫做戴夫·卡特勒(Dave Cutler),戴夫是他的昵称。他是一位传奇程序员,是VMS和Windows NT的首席设计师,被人们称为“操作系统天神”。他曾供职于杜邦、DEC等公司,1988年,由比尔 ·盖茨招募到微软,他用了5年时间花费了1.5亿美金,负责组织NT的开发。
个人简介
David Cutler,VMS和Windows NT的首席设计师,1988年去微软前硅谷最牛的内核开发人员,在操作系统领域摸爬滚打几十年,其间的经历就像一部标准的外省青年奋斗记。
主要成果
与许多计算机界的前辈牛人们一样,David Cutler并不是计算机科班出生,他在大学拿的是数学学士,主攻物理,满怀热情地想成为一位建造事物的工程师。所以,毕业后他进入杜邦公司从事材料测试。一次偶然的机会,David被指派负责在DEC的计算机上运行模拟程序,还为多台单机实时系统编写中央控制程序,调度各种任务、监控系统运作。这个经历不仅丰富了David的软件知识,还让他做出了一个重大的决定:去一家真正从事计算机业务的公司,开发操作系统。
1971年,David Cutler离开杜邦公司来到DEC。他的第一项任务就是为DEC的PDP-11微处理器开发操作系统——RSX-11M。PDP-11是为工业控制和制造控制而设计的16位微处理器。David结合总体概念和设计原则,利用汇编语言在非常有限的内存空间内实现了多项系统功能,如:树型文件系统、交换应用程序、实时调度和一整套开发工具等。据David回忆,当时连他的橡皮图章上都刻着开发这个操作系统的目标——“容量就是一切!”后来,这些概念和原则也体现在了NT上。
70年代后期,DEC公司在PDP-11的基础上开发出32位的VAX处理器。与之相应,也要开发基于VAX的操作系统VMS,要能兼容 RSX-11M,可以在不同大小的机器上运行。David Cutler成为这个项目主要负责人,设计VMS的架构。1977年,VMS 1.0问世。David唯一的遗憾是,因为迎合商业进度,因此VMS也是用汇编语言写的,尽管当时完全可以用高级语言。所以,技术上正确的事并不见得是商业上的最佳选择。随后,David继续研制 VMS 的后续版本,不过他有些不耐烦了。1981年,David威胁要离开DEC。为了挽留它的明星开发者,DEC给了David大约 200 位软硬件工程师。David把他的小组搬到西雅图,并建立了一个开发中心。这个精英小组的目标是设计一个新的CPU 体系结构和操作系统,可以把DEC带到九十年代。DEC把这个小组的硬件项目称为Prism,操作系统为Mica。
很不幸,Prism项目于1988年被DEC撤销,很多项目成员也被解雇。因此David Cutler萌生了去意。此时,为了未来能够与Unix抗争、开发新的操作系统,Bill Gates见缝插针,竭力劝说David加入微软。David去了,还带去了许多与他一同开发VMS和Mica的程序员。进入微软,David领导一个工程小组,负责设计一种能提供文件服务、打印服务和应用服务的对称多处理。操作系统,起名为Windows New Technology(NT)。这就是Bill Gates想用来对抗Unix的新型武器。
经过近4年的开发工作,在1993年6月发布的第一版Windows NT 3.1,已经具备了现代操作系统的雏形——抢先式多任务、虚拟内存、对称多处理器、图形界面、C2安全级、坚固而稳定的内核、内置网络支持、完全的32位代码等。而1994年推出的Windows NT 3.51和1996年推出的Windows NT 4.0,在性能上有了更进一步提高;NT4.0甚至提供了当时最先进的Windows 95风格界面。David Cutler在自己的天梯上继续攀升,Bill Gates也在销售数字面前笑得合不拢嘴。
毫无疑问,NT操作系统有一个优秀的内核,David Cutler成功地引入了硬件抽象层、内核对象这些天才的思想。虽然我们没能得见它的源代码,但在钻研NT DDK的过程中、在埋头可能就是由David亲笔撰写的文档中时,总能有那些闪光点,让我们可以在不同的时空与大师对话。
如今,Built On NT Technology的Windows 2000和XP的成绩有目共睹,而针对64位处理器的XP也即将推出。回顾开发操作系统的历程,David情不自禁地感叹道:“我也不知道,自己竟是那么的幸运,能够在有生之年开发好几个操作系统,而对于任何一个人来说,哪怕只开发一个都是非常难得的机会。”
是的,David Cutler做到了,在操作系统领域中纵横了几十年,缔造了许多传奇和神话。然而,又有谁会去看他几十年的专注、寂寞、付出与艰辛呢?可能每个人在开始自己的职业生涯时都会设定一个目标。然而只有那么一些人会抓住目标紧紧不放、全心投入,最后这些人成了我们眼中的成功者、技术天才。也许,这就是成就天才与普通人的不同之处。
相关事迹
David Cutler,VMS和Windows NT的首席设计师,去微软前号称硅谷最牛的kernel开发员。当初他和他的手下在微软一周内把一个具备基本功能的bootable kernel写出来,然后说:“who can't write an OS in a week?",也是牛气冲天的说。顺便说一句,D爷爷到NT3.5时,管理1500名开发员,自己还兼做设计和编程,不改coder本色啊。D爷爷天生脾气火爆,和人争论时喜欢双手猛击桌子以壮声势。:-) 日常交谈F-word不离口。他面试秘书时必问:"what do you think of the word 'fuck'?" ,让无数美女铩羽而归。终于有一天,一个同样火爆的女面对这个问题脱口而出:"That's my favorite word"。于是她被录取了,为D爷爷工作到NT3.5发布。

Linux中的内存大页面
作者介绍 魏兴华
沃趣科技高级技术专家
http://mp.weixin.qq.com/s?__biz=MzI4NTA1MDEwNg==&mid=403265328&idx=1&sn=b852e6ba4669c787de352c9823d05139&scene=0#wechat_redirect
大页
对于类Linux系统,CPU必须把虚拟地址转换程物理内存地址才能真正访问内存。为了提高这个转换效率,CPU会缓存最近的虚拟内存地址和物理内存地址的映射关系,并保存在一个由CPU维护的映射表中,为了尽量提高内存的访问速度,需要在映射表中保存尽量多的映射关系。这个映射表在Linux中每个进程都要持有一份,如果映射表太大,就会大大降低CPU的TLB命中率,主流的Linux操作系统,默认页的大小是4K,对于大内存来说,这会产生非常多的page table entries,上面已经提到,Linux下页表不是共享的,每个进程都有自己的页表,现在随便一个主机的内存都配置的是几十个G,几百个G,甚至上T,如果在上面跑Oracle不使用大页,基本上是找死,因为Oracle是多进程架构的,每一个连接都是一个独占的进程,大内存+多进程+不使用大页=灾难,肉丝在8年的DBA生涯里,至少帮助不下5个客户处理过由于没有使用大页而导致的系统故障,而这5个客户都是近三四年遇到的,为什么大页这个词提前个三五年并没有被频繁提起,而当下,大页这个词在各种技术大会,最佳实践中成为热门词汇?
这是因为最近几年是Linux系统被大量普及应用的几年,也是大内存遍地开花的几年,而且现在一个数据库系统动不动就是几百上千个连接,这些都促成了大页被越来越多的被关注到。
大页的好处
我们来看一下使用了大页的好处:
少的page table entries,减少页表内存
pin住SGA,没有page out
提高TLB命中率,减少内核cpu消耗(CPU维护了一块缓存叫做:Translation Look-Aside Buffer (TLB)
TLB的工作方式类似于SQLSERVER的执行计划缓存,只要一个入口曾经被转译过下次就不需要再次转译。
)
在没有使用大页的系统上,经常可能会发现几十上百G的页表,严重情况下,系统CPU的sys部分的消耗非常大,这些都是没使用大页的情况下的一些症状。
大页的特点/缺点
要预先分配
不够灵活,甚至需要重启主机
如果分配过多,会造成浪费,不能被其他程序使用。
大页的分配方法
通过在文件
/etc/sysctl.cnf
中增加vm.nr_hugepages参数来为大页设定一个合理的值,值的单位为2MB。或者通过echo 一个值到/proc/sys/vm/nr_hugepages中也可以临时性的对大页进行设定。 至于应该为大页设定多大的值,这个要根据系统SGA的配置来定,一般建议大页的总占用量大于系统上所有SGA总和+2GB。
HugePages on Oracle Linux 64-bit (文档 ID 361468.1),AIX页表共享,一般不用设置大页。
大页的原理
以下的内容是基于32位的系统,4K的内存页大小做出的计算:
1)目录表,用来存放页表的位置,共包含1024个目录entry,每个目录entry指向一个页表位置,每个目录entry,4b大小,目录表共4b*1024=4K大小
2)页表,用来存放物理地址页的起始地址,每个页表entry也是4b大小,每个页表共1024个页表entry,因此一个页表的大小也是4K,共1024个页表,因此页表的最大大小是1024*4K=4M大小
3)每个页表entry指向的是4K的物理内存页,因此页表一共可以指向的物理内存大小为:1024(页表数)*1024(每个页表的entry数)*4K(一个页表entry代表的页大小)=4G
4)操作系统将虚拟地址映射为物理地址时,将虚拟地址的31-22这10位用于从目录表中索引到1024个页表中的一个,将虚拟地址的12-21这10位用于从页表中索引到1024个页表entry中的一个。从这个页表entry中获得物理内存页的起始地址,然后将虚拟地址的0-12位用作4KB内存页中的偏移量,那么物理内存页起始地址加上偏移量就是进出所需要访问的物理内存地址。
由于32位操作系统不会出现4M的页表,因为一个进程不能使用到4GB的内存空间,有些空间被保留使用,比如用来做操作系统内核的内存。而且页表entry的创建出现在进程访问到一块内存的时候,而不是一开始就创建。
页表内存计算
在32位系统下,一个进程访问1GB的内存,会产生1MB的页表,如果是在64位系统,将会增大到2MB。 很容易推算,如果一个SGA设置为60G,有1500个Oracle用户进程(Windows 当一个进程的虚拟地址空间(VirtualAddressSpace,VAS)(每个进程只有一个虚拟地址空间,
虚拟地址空间=一个进程使用的内存)是由小的内存页面构成的),64位Linux的系统上,最大的页表占用内存为:60*2*1500/1024=175G,是的,你没看错,是175G!但是实际情况看到的页表占用可能没有这么大,打个百分之四五十的折扣,这是因为只有Oracle服务器进程访问到SGA的特定区域后,进程才需要把这一块对应的页表项加入到自己的页表中
1048576KB/4K/1024=256*4KB=1024KB
4K(一个页表entry代表的页大小
1024(每个页表的entry数
256个页表
每个页表是4K
256*4=1024KB=1MB
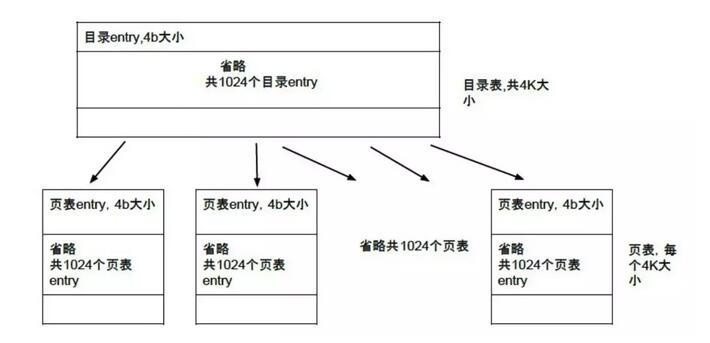
11.2.0.3版本
11.2.0.3版本之前,如果分配的大页数量不足,那么Oracle启动过程中不会使用大页,转而使用小页,但是在11.2.0.3版本后,Oracle在启动时同样会尝试使用大页,
如果大页的数量不够,那么会把当前配置的大页使用完,不够的部分再从小页中去获取,这一行为实际上是通过Oracle的一个参数来控制USE_LARGE_PAGES,后面会对这个参数做详细解释。
通过数据库实例的alert文件可以清楚的看到这一情况的发生:
配置SQL Server去使用 Windows的 Large-Page/Huge-Page allocations
http://www.cnblogs.com/lyhabc/p/3633452.html
linux 同步IO: sync、fsync与fdatasync
--http://blog.csdn.net/cywosp/article/details/8767327
传统的UNIX实现在内核中设有缓冲区高速缓存或页面高速缓存,大多数磁盘I/O都通过缓冲进行。当将数据写入文件时,内核通常先将该数据复制到其中一个缓冲区中,如果该缓冲区尚未写满,则并不将其放入输出队列,而是等待其写满或者当内核需要重用该缓冲区以便存放其他磁盘块数据时,再将该缓冲放入输出队列,然后待其到达队首时,才进行实际的I/O操作。这种输出方式被称为延迟写(delayed write)(Bach [1986]第3章详细讨论了缓冲区高速缓存)。
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,使得写到文件中的数据在一段时间内并没有写到磁盘上。当系统发生故障时,这种延迟可能造成文件更新内容的丢失。
为了保证磁盘上实际文件系统与缓冲区高速缓存中内容的一致性,UNIX系统提供了sync、fsync和fdatasync三个系统调用。
sync系统调用只是将所有修改过的块缓冲区放入写队列,然后就返回,它并不等待实际写磁盘操作结束。
通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync系统调用。这就保证了定期flush内核的块缓冲区到磁盘。sync命令也调用sync系统调用。
fsync系统调用只对由文件描述符file descriptor指定的单一文件起作用,并且等待写磁盘操作结束,然后返回。fsync可用于数据库这样的应用程序,这种应用程序需要确保将修改过的块立即写到磁盘上。
fdatasync函数类似于fsync,但它只影响文件的数据部分data。而除数据外,fsync还会同步更新文件的属性 inode。
内核缓冲区和磁盘文件同步的系统调用
sync:异步,针对整个块缓冲区,系统的sync命令
fsync:同步阻塞 传入文件描述符针对单个文件 刷盘
fdatasync:跟fsync一样,只是他只同步data,而不同步inode 刷盘
msync:mmap方式 需要指定地址空间
fopen函数:打开文件
fread函数:用来读一个数据块
fwrite函数:用来写一个数据块 写盘
对于提供事务支持的数据库,在事务提交时,都要确保事务日志(包含该事务所有的修改操作以及一个提交记录)完全写到硬盘上,才认定事务提交成功并返回给应用层。
一个简单的问题:在类Unix操作系统上,怎样保证对文件的更新内容成功持久化到硬盘?
1. write不够,需要fsync
一般情况下,对硬盘(或者其他持久存储设备)文件的write操作,更新的只是内存中的页缓存(page cache),而脏页面不会立即更新到硬盘中,而是由操作系统统一调度,如由专门的flusher内核线程在满足一定条件时(如一定时间间隔、内存中的脏页达到一定比例)内将脏页面同步到硬盘上(放入设备的IO请求队列)。
因为write调用不会等到硬盘IO完成之后才返回,因此如果OS在write调用之后、硬盘同步之前崩溃,则数据可能丢失。虽然这样的时间窗口很小,但是对于需要保证事务的持久化(durability)和一致性(consistency)的数据库程序来说,write()所提供的“松散的异步语义”是不够的,通常需要OS提供的同步IO(synchronized-IO)原语来保证:
1 #include <unistd.h>
2 int fsync(int fd);
fsync的功能是确保文件fd所有已修改的内容已经正确同步到硬盘上,该调用会阻塞等待直到设备报告IO完成。
PS:如果采用内存映射文件的方式进行文件IO(使用mmap,将文件的page cache直接映射到进程的内存地址空间,通过写内存的方式修改文件),也有类似的系统调用来确保修改的内容完全同步到硬盘之上:
1 #incude <sys/mman.h>
2 int msync(void *addr, size_t length, int flags)
msync需要指定同步的地址区间,如此细粒度的控制似乎比fsync更加高效(因为应用程序通常知道自己的脏页位置),但实际上(Linux)kernel中有着十分高效的数据结构,能够很快地找出文件的脏页,使得fsync只会同步文件的修改内容。
2. fsync的性能问题,与fdatasync
除了同步文件的修改内容(脏页),fsync还会同步文件的描述信息(metadata,包括size、访问时间st_atime & st_mtime等等),因为文件的数据和metadata通常存在硬盘的不同地方,因此fsync至少需要两次IO写操作,fsync的man page这样说:
"Unfortunately fsync() will always initialize two write operations : one for the newly written data and another one in order to update the modification time stored in the inode. If the modification time is not a part of the transaction concept fdatasync() can be used to avoid unnecessary inode disk write operations."
多余的一次IO操作,有多么昂贵呢?根据Wikipedia的数据,当前硬盘驱动的平均寻道时间(Average seek time)大约是3~15ms,7200RPM硬盘的平均旋转延迟(Average rotational latency)大约为4ms,因此一次IO操作的耗时大约为10ms左右。这个数字意味着什么?下文还会提到。
POSIX标准同样定义了fdatasync,放宽了同步的语义以提高性能:
1 #include <unistd.h>
2 int fdatasync(int fd);
fdatasync的功能与fsync类似,但是仅仅在必要的情况下才会同步metadata,因此可以减少一次IO写操作。那么,什么是“必要的情况”呢?根据man page中的解释:
"fdatasync does not flush modified metadata unless that metadata is needed in order to allow a subsequent data retrieval to be corretly handled."
举例来说,文件的尺寸(st_size)如果变化,是需要立即同步的,否则OS一旦崩溃,即使文件的数据部分已同步,由于metadata没有同步,依然读不到修改的内容。而最后访问时间(atime)/修改时间(mtime)是不需要每次都同步的,只要应用程序对这两个时间戳没有苛刻的要求,基本无伤大雅。
PS:open一个file时的参数O_SYNC/O_DSYNC有着和fsync/fdatasync类似的语义:使每次write都会阻塞等待硬盘IO完成。(实际上,Linux没有满足POSIX标准的要求,而是都实现了fdatasync的语义)相对于fsync/fdatasync,这样的设置不够灵活,应该很少使用。
3. 使用fdatasync优化日志同步
文章开头时已提到,为了满足事务要求,数据库的日志文件是常常需要同步IO的。由于需要同步等待硬盘IO完成,所以事务的提交操作常常十分耗时,成为性能的瓶颈。
在Berkeley DB下,如果开启了AUTO_COMMIT(所有独立的写操作自动具有事务语义)并使用默认的同步级别(日志完全同步到硬盘才返回),写一条记录的耗时大约为5~10ms级别,基本和一次IO操作(10ms)的耗时相同。
我们已经知道,在同步上fsync是低效的。但是如果需要使用fdatasync减少对metadata的更新,则需要确保文件的尺寸在write前后没有发生变化。日志文件天生是追加型(append-only)的,总是在不断增大,似乎很难利用好fdatasync。
且看Berkeley DB是怎样处理日志文件的:
1.每个log文件固定为10MB大小,从1开始编号,名称格式为“log.%010d"
2.每次log文件创建时,先写文件的最后1个page,将log文件扩展为10MB大小
3.向log文件中追加记录时,由于文件的尺寸不发生变化,使用fdatasync可以大大优化写log的效率
4.如果一个log文件写满了,则新建一个log文件,也只有一次同步metadata的开销
IO事件模型 select-》poll-》epoll
首先,epoll与poll 一样,理论上没有任何I/O句柄数量上的限制。默认情况,Linux允许一个进程最多拥有1024个I/O句柄
第18章节 这里也是鼓乐笙箫
P703
Linux读写内存数据的三种方式
1、read ,write方式会在用户空间和内核空间不断拷贝数据,占用大量用户内存空间,效率不高
2、内存映射方式把设备文件的内存映射到应用程序中的内存空间,直接处理设备内存,这是一种高效的方式。mmap函数就是这种方式
如果程序中使用了mmap方法,需要使用munmap方法删除内存映射
3、 用户指针方式,是内存片段由应用程序自己分配。
f
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式的更多相关文章
- Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式
Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式 P703 Linux读写内存数据的三种方式 1.read ,write方式会在用户空间和内核空间不断拷贝数据, ...
- Linux就这个范儿 第19章 团结就是力量 LSB是Linux标准化基地(Linux Standards Base)的简称
Linux就这个范儿 第19章 团结就是力量 LSB是Linux标准化基地(Linux Standards Base)的简称 这个图片好可爱,它是LSB组织的图标.你肯定会问:“图标这么设计一定有说 ...
- Linux就这个范儿 第16章 谁都可以从头再来--从头开始编译一套Linux系统 nsswitch.conf配置文件
Linux就这个范儿 第16章 谁都可以从头再来--从头开始编译一套Linux系统 nsswitch.conf配置文件 朋友们,今天我对你们说,在此时此刻,我们虽然遭受种种困难和挫折,我仍然有一个梦 ...
- Linux就这个范儿 第14章 身在江湖
Linux就这个范儿 第14章 身在江湖 “有人的地方就有江湖”,如今的计算机世界就像一个“江湖”.且不说冠希哥有多么无奈,把微博当QQ的局长有多么失败,就说如此平凡的你我什么时候就成了任人摆布的羔羊 ...
- Linux就这个范儿 第13章 打通任督二脉
Linux就这个范儿 第13章 打通任督二脉 0111010110……你有没有想过,数据从看得见或看不见的线缆上飞来飞去,是怎么实现的呢?数据传输业务的未来又在哪里?在前面两章中我们学习了Linux网 ...
- Linux就这个范儿 第10章 生死与共的兄弟
Linux就这个范儿 第10章 生死与共的兄弟 就说Linux系统的开机.必须经过加载BIOS.读取MBR.Boot Loader.加载内核.启动init进程并确定运行等级.执行初始化脚本.启动内核模 ...
- Linux就这个范儿 第9章 特种文件系统
Linux就这个范儿 第9章 特种文件系统 http://book.douban.com/reading/32081222/ P326 有一种文件系统,根本不在磁盘上.这种文件系统就是大名顶顶的ram ...
- Linux就这个范儿 第12章 一个网络一个世界
Linux就这个范儿 第12章 一个网络一个世界 与Linux有缘相识还得从一项开发任务说起.十八年前,我在Nucleus OS上开发无线网桥AP,需要加入STP生成树协议(SpanningTree ...
- Linux就这个范儿 第11章 独霸网络的蜘蛛神功
Linux就这个范儿 第11章 独霸网络的蜘蛛神功 第11章 应用层 (Application):网络服务与最终用户的一个接口.协议有:HTTP FTP TFTP SMTP SNMP DNS表示层 ...
随机推荐
- python 面向对象的三大特征之 封装
封装:私有化 class Person(object): def __init__(self): self.__gender = "man" #在类的属性名称前面加__ self. ...
- hdu Line belt
这道题是一道3分搜索的题.其实这种题很多时候都出现在高中的解析几何上,思路很简单,从图中可以看到,肯定在AB线段和CD线段上各存在一点x和y使得所花时间最少 因为AB和CD上的时间与x和y点的坐标都存 ...
- SQL Server 收缩数据库
//删除大量数据 /*** * * BEGIN TRANSACTION; * SELECT * INTO #keep FROM Original WHERE CreateDate > '2011 ...
- .NET中资料库的设计与SQL
.NET中资料库的设计与SQL ADO.NET设计 先来说说资料库的设计 主要涉及 关联式资料库 资料库系统管理(DBMS) 结构化查询(SQL) 预储程序 一个资料库包含一个以上的资料表,每个资料表 ...
- /etc/named/named.conf.options中的Options参数
listen-on port 53 { any; }; 监听在这部主机系统上面的哪个网路介面.预设是监听在localhost,亦即只有本机可以对DNS 服务进行查询,那当然是很不合理啊!所以这里要将大 ...
- 【iCore双核心组合是开发板例程】【12个 verilog 中级实验例程发布】
_____________________________________ 深入交流QQ群: A: 204255896(1000人超级群,可加入) B: 165201798(500人超级群,满员) C ...
- css 细节收集
细节1……………………………………………………………………………… 一.当文字与图片在一行,需要将文字与图片底对齐,需要这样写: <li>记住密码<img src="&qu ...
- JS页面跳转 神器! window.href window.open
window.open 打开页面, 网址为新的网址 window.href 为打开本网址的链接, 为网站URL+传入的URL
- js 模拟ajax方式提交数据
html页面 <script>function LocaluploadCallback(msg) { document.getElementById("f_localup ...
- ExtJS笔记5 Components
参考 :http://blog.csdn.net/zhangxin09/article/details/6914882 An Ext JS application's UI is made up of ...