一文弄懂使用Jmeter来进行性能测试
该文章是基于上一次文章的 软件测试漫谈(web测试,自动化测试,Jmeter) 的续篇, 主要是详细讲解 Jmeter 的入门教程。
因为上次的文章只是简单地讲解了 Jmeter 的使用和一些概念,所以很多初学者像按照原来的文章操作 Jmeter 进行测试是比较麻烦的,所有才有了这篇后续,以帮助开发者能快速使用 Jmeter 来进行测试。如果还没看过之前那个文章,建议先看一下,学习一下Jmeter的基本概念,以便熟悉该文章操作的一些概念。该文章基于 Jmeter 版本 5.1.1 和 Windows 10。
测试需求
模拟20个 谷歌浏览器类型 用户 同时 访问 http://www.baidu.com/ 和 https://www.csdn.net/api/articles (该链接是获取 csdn 上的文章,如果正确会返回状态 "status": "true",) 在负载达到30 QPS 时的平均响应时间 和 结果准确度。
操作步骤
- 在 Jmeter 官网上下载 Jmeter 安装包,下载地址: https://apache.osuosl.org//jmeter/binaries/apache-jmeter-5.2.1.zip,需要先安装了 Jdk ,解压 打开文件
apache-jmeter-5.1.1\bin\jmeter.bat
简单设置请求
- 在测试计划中选择新建线程组,重命名线程组为20个模拟用户线程组。
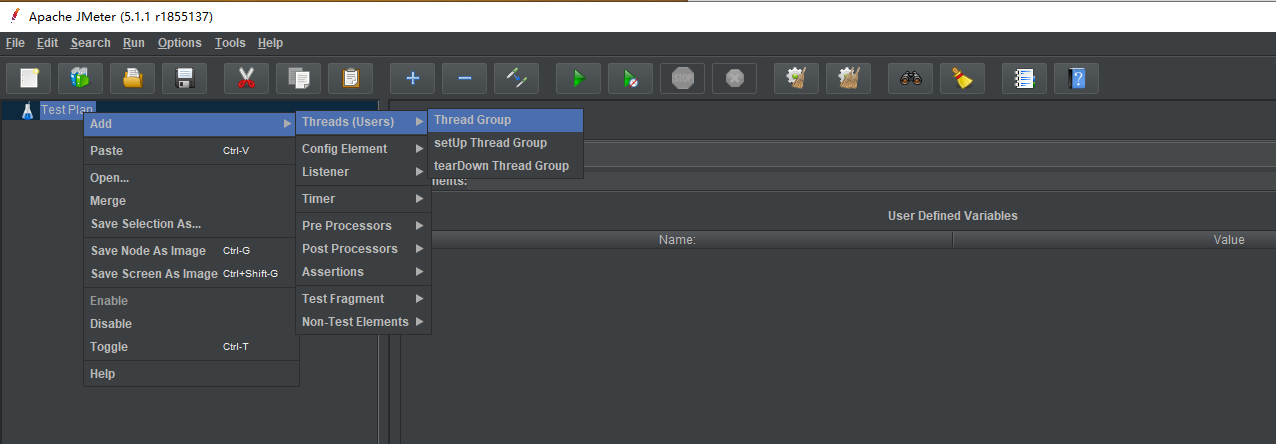
在 Number of Threads 栏 填写 20 ,设置 线程数为 20。在 Loop Count 栏填写 10000,设置 循环请求10000 次。
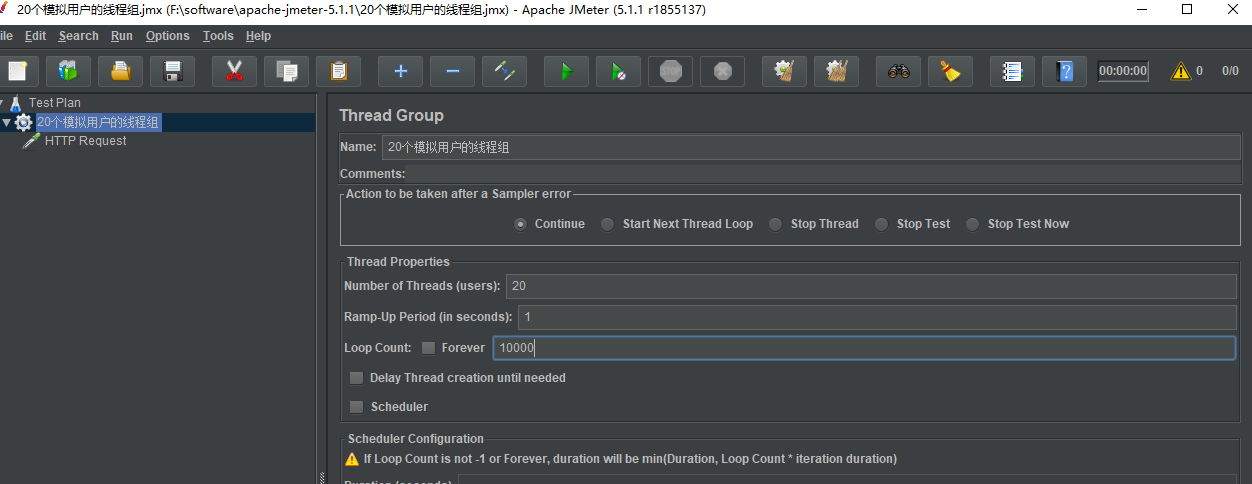
- 在线程组上右键,选择添加 Http 请求的取样器
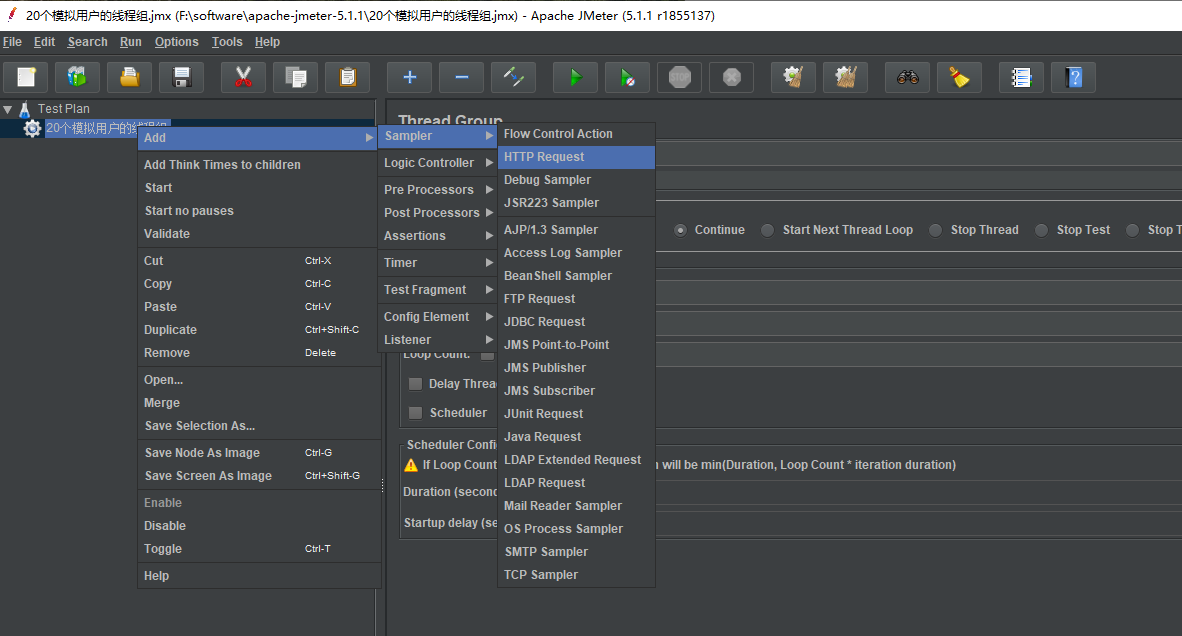
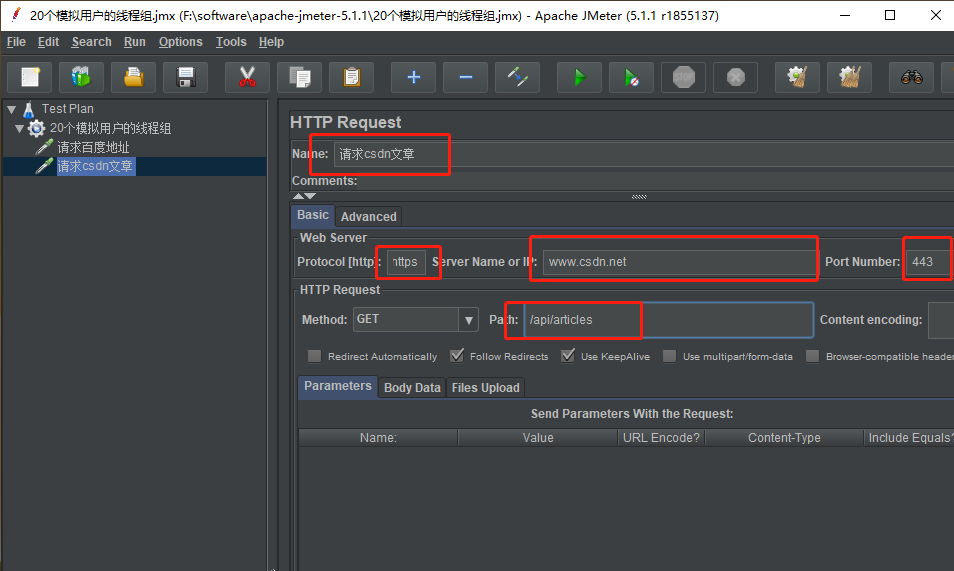
重命名该取样器为请求百度地址,在Server Name or IP栏填写www.baidu.com,Prot Number栏填写80端口,如果是https 协议,则填写443端口。
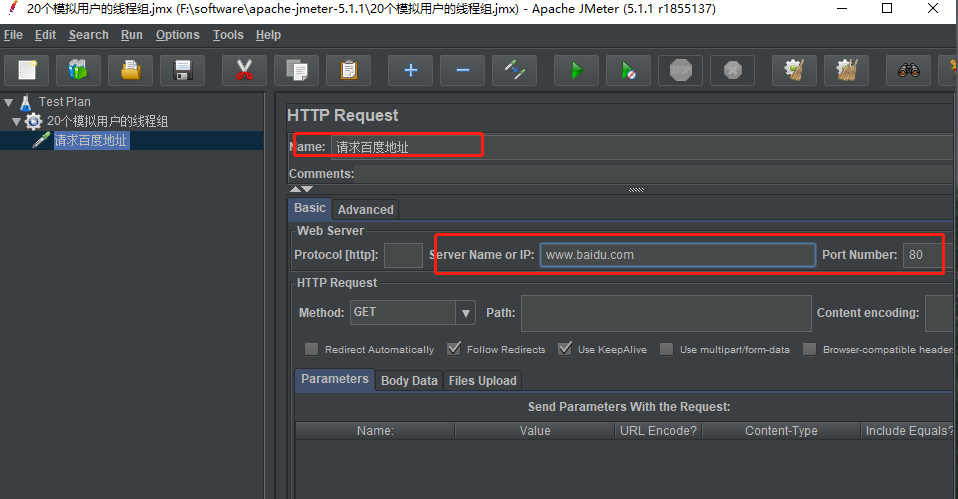
3. 再在线程组上填写 HTTP 请求取样器,并按照如下图来进行设置和重命名为 请求 csdn 文章 。
4. 设置结果查看 ,在线程组右键,添加结果树
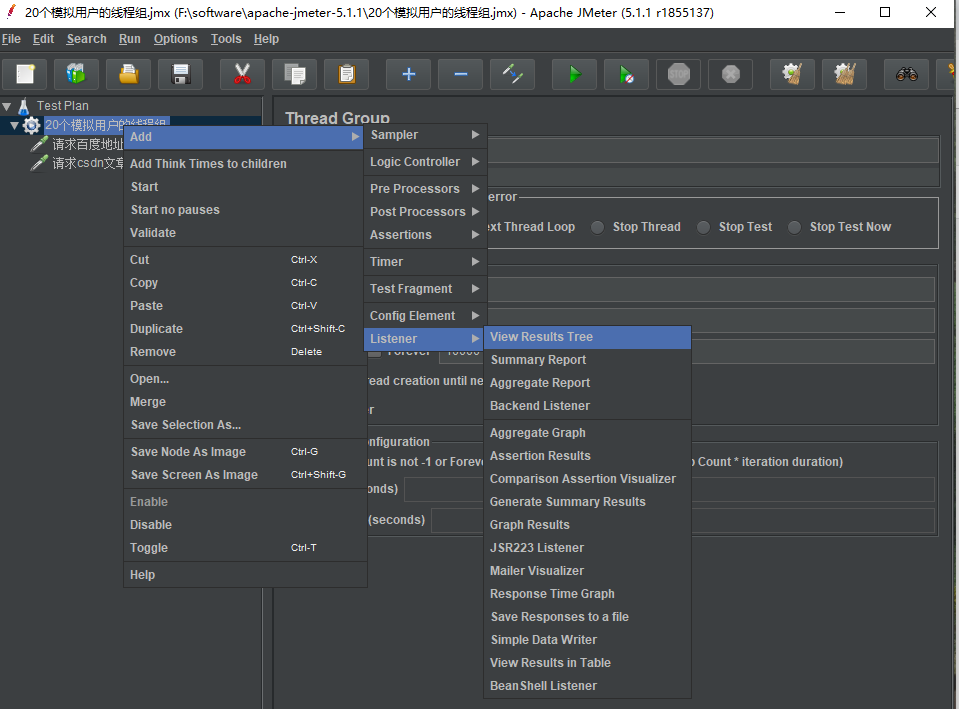
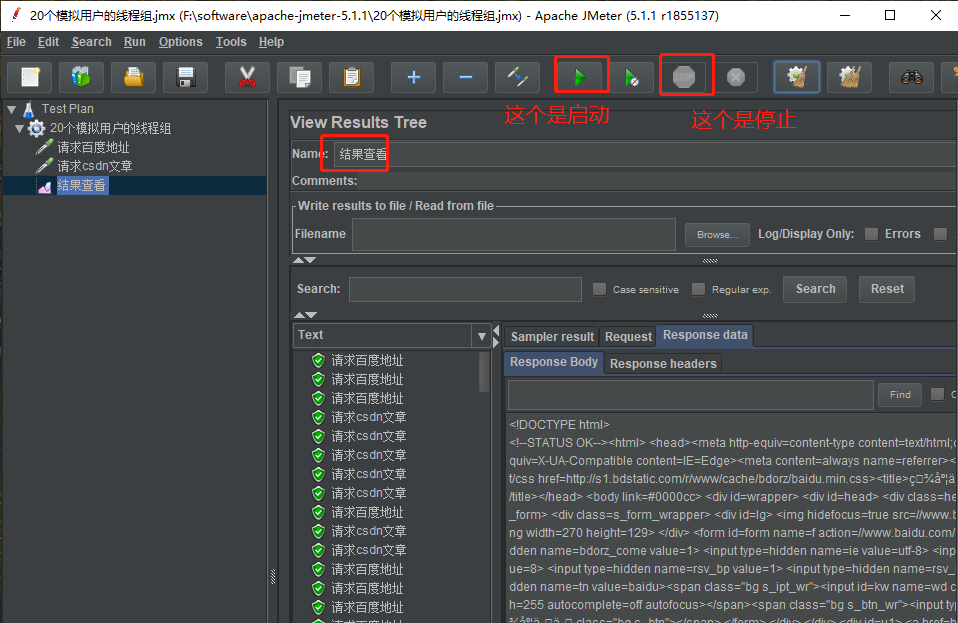
重命名为 结果查看,然后点击 上方的 绿色的运行按钮,即可,查看到发送的请求 HTTP 请求。点击结果树中的,任意一个请求可以看到请求的请求头,请求时间,响应头,响应时间等具体信息。
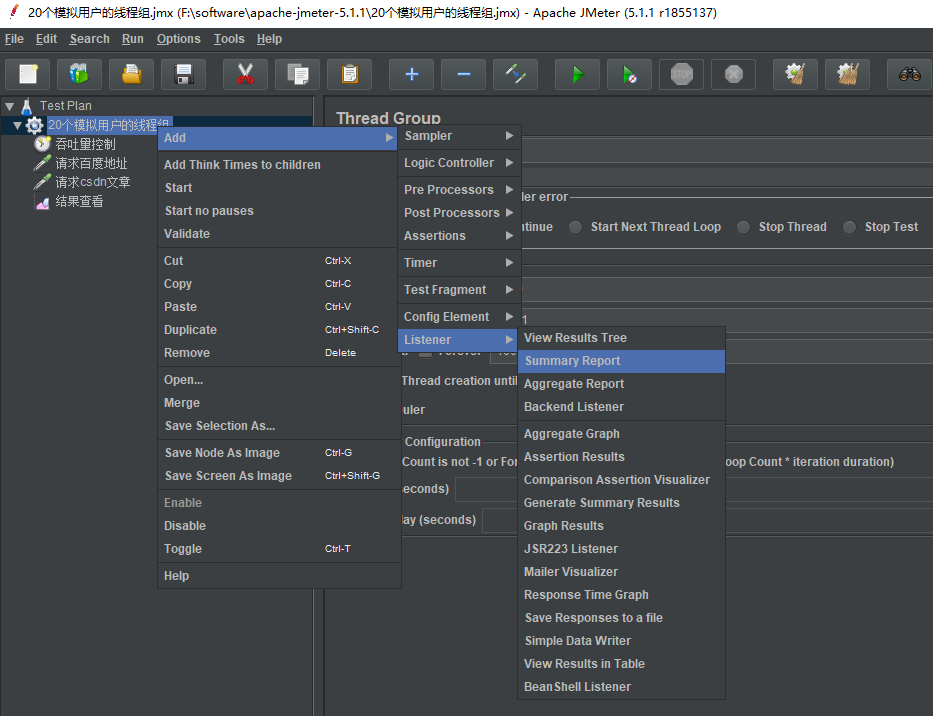
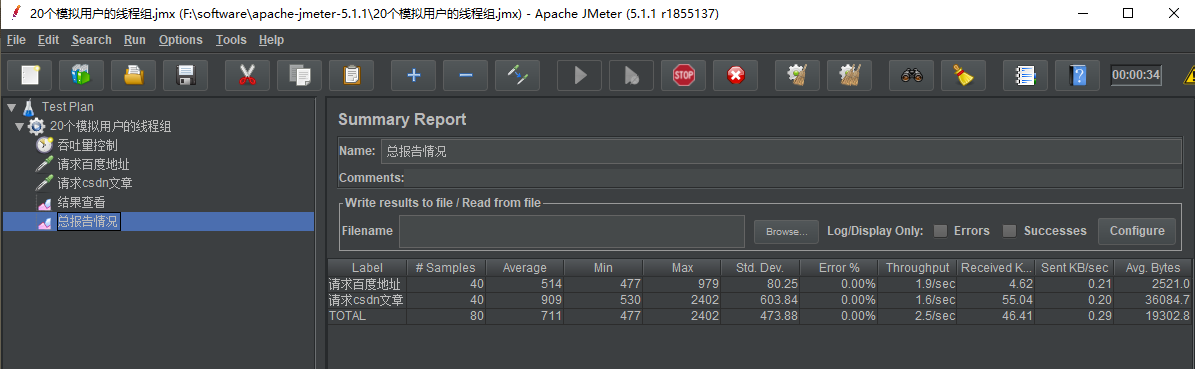
然后,我们可以通过添加 总报表 的监听器 来查看 请求的总体发送情况
一些特定参数设置
- 设置吞吐量/QPS
Jmeter 提供了一个很有用的定时器,叫做 Constant Throughput Timer (常数吞吐量定时器),该定时器可以很方便地控制给定的取样器发送请求的吞吐量。
在线程组上右键新建吞吐量定时器
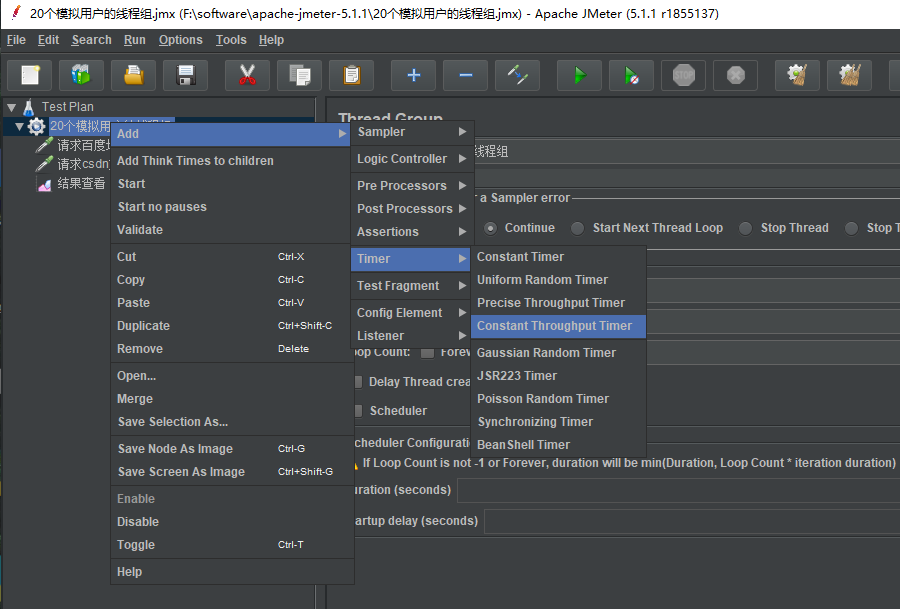
在 Target throughput( in smples per minute )(每分钟的目标吞吐量): 实际填写的数值为:60 * QPS ,所以这里我们填写1200,然后 Calculate Through based on 选择 All active threads 。
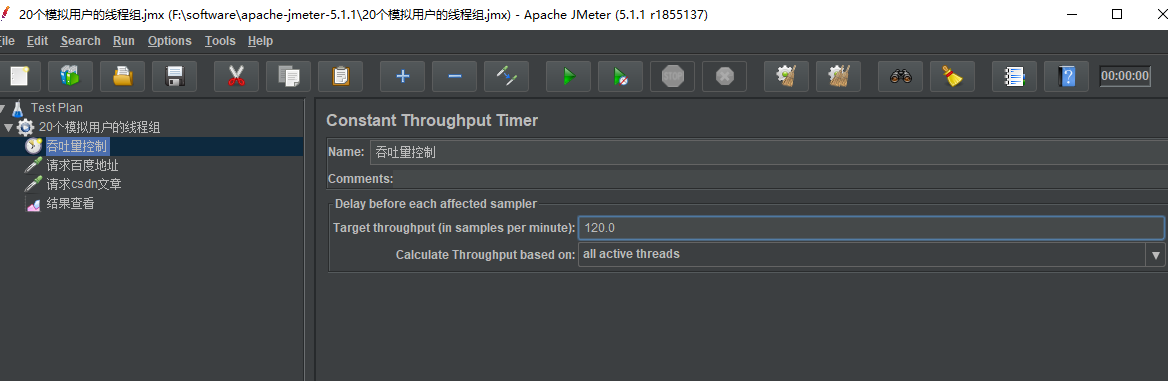
注意:这里计算的吞吐量有时候并不准确,一般进行测试的时候,我们会选择提高一些吞吐量的值以达到实际要求的 QPS
- 设置请求头的参数,设置浏览器类型
对于某些请求,有可能我们需要设置请求的请求头的信息,例如:浏览器类型,鉴权信息 token 等,这时候,我们可以通过添加 http 请求头的配置元件来完成。
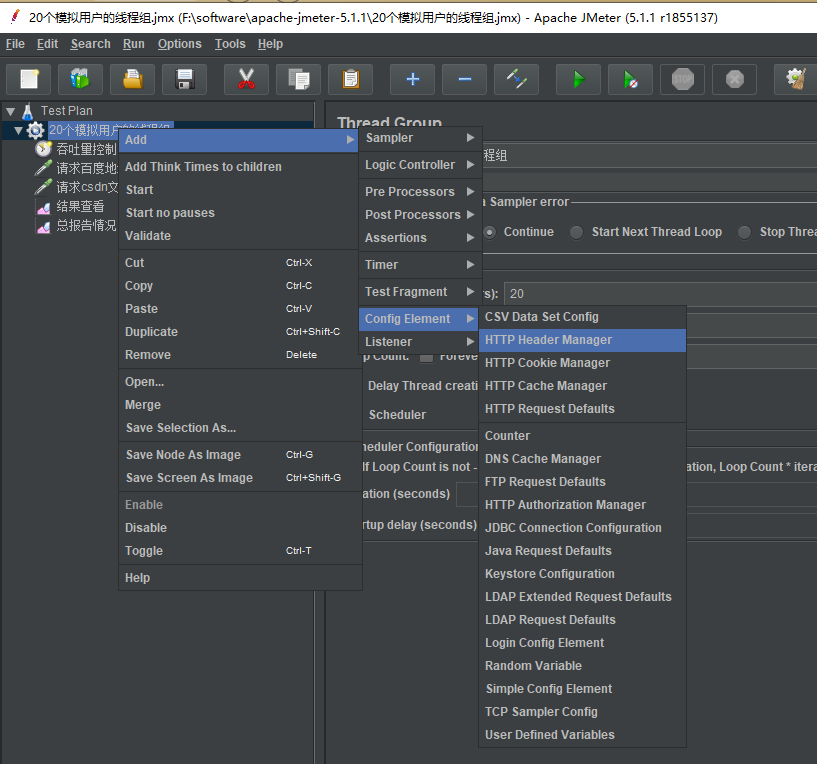
添加配置元件之后,我们添加上浏览器的请求头信息.
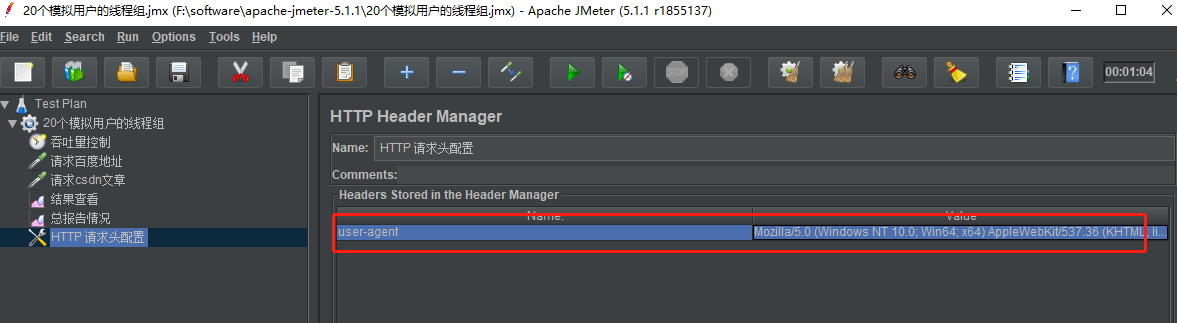
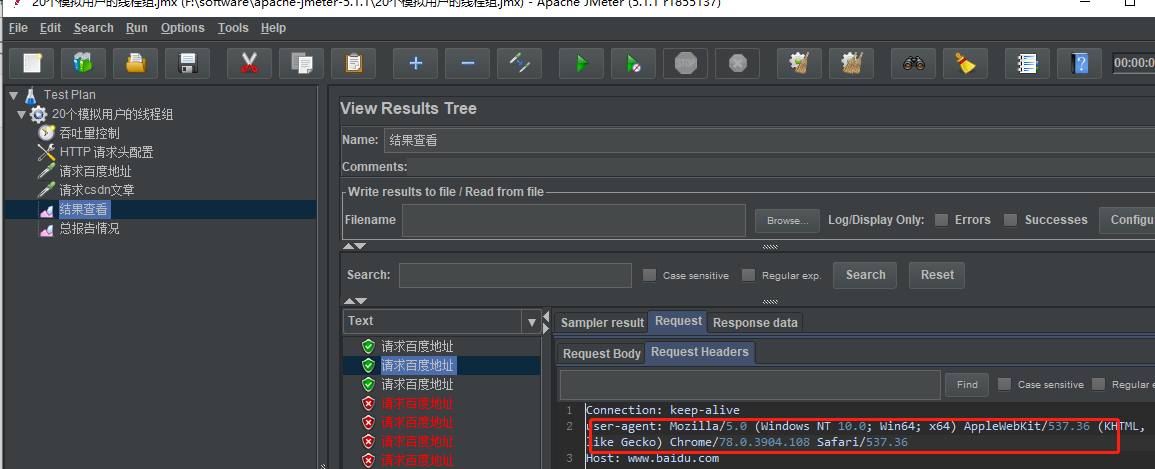
这时候再点击运行,可以看得到发送的请求中,请求头包含了我们设置的信息:
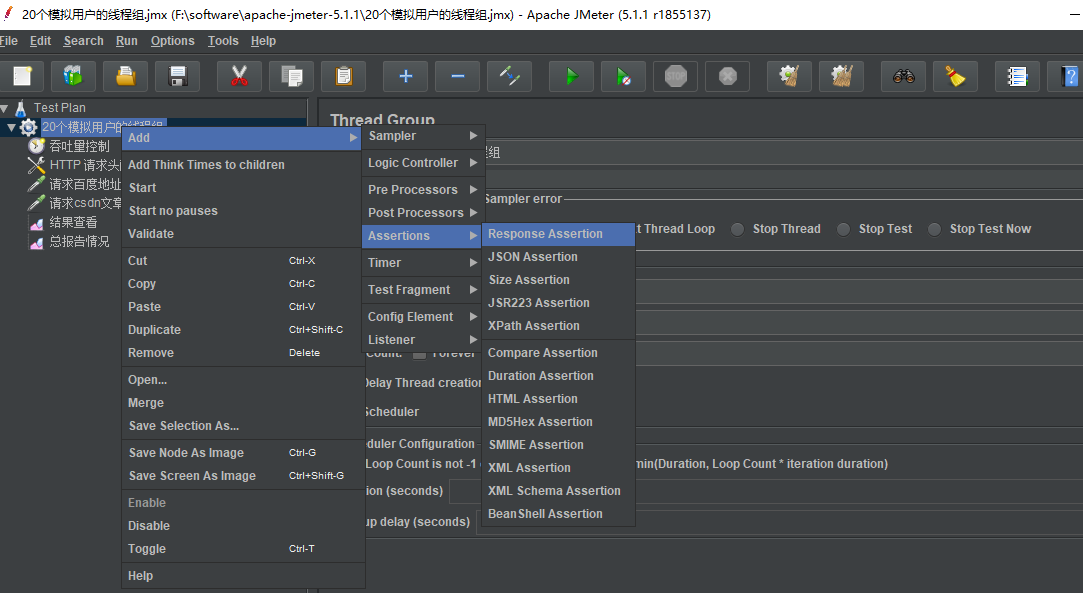
- 判断返回结果的是否成功
默认 Jmeter 是根据响应码来判断结果是否请求请求的,非200 的判断为不成功,如果我们想根据响应内容判断,则需要添加断言器,来自己判断内容包含哪些字符等,一般我们添加响应信息的断言器,即可。
我们加上如果请求响应信息中包含了字符 {"status":"true 我们则判断该请求成功,否则失败,我们可以这样来设置断言。
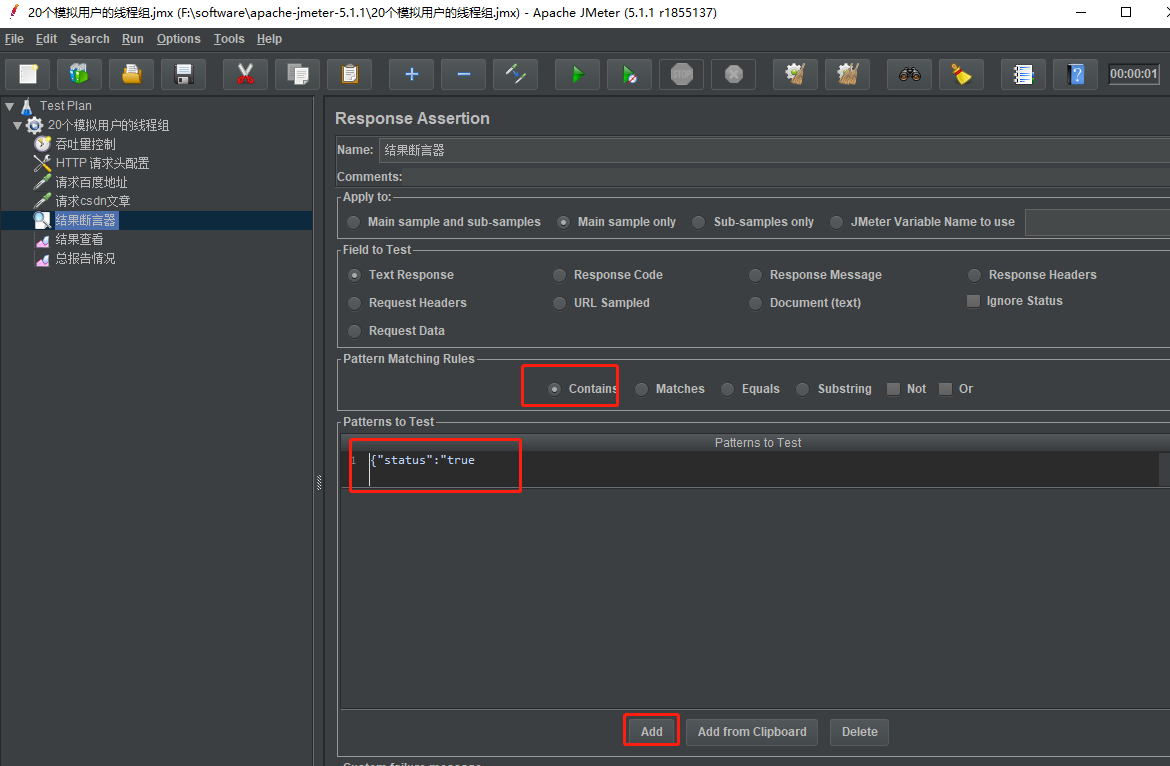
如果我们想单单针对某个请求来进行断言,我们可以,将断言放到某个请求里面,这样它就会只判断该请求。这里我们只针对 获取 csdn的文章的请求来断言。
最终的结果
我们完成以上配置之后,点击运行,等待结果运行稳定好,查看 总报告情况 可以得到以下 截图
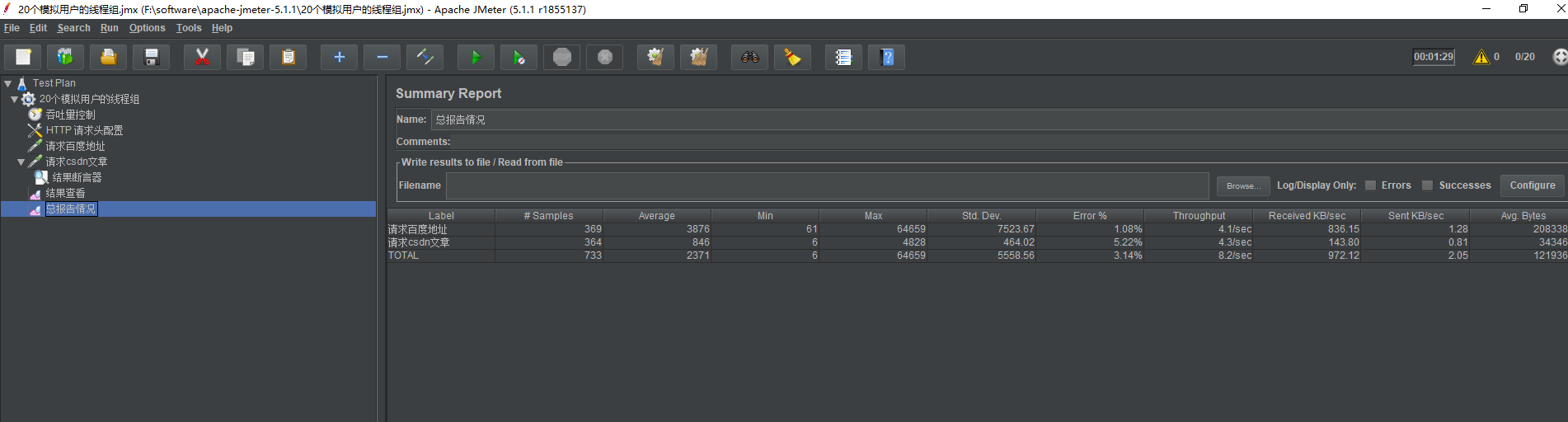
可以看到,再QPS 约为 5 的情况下,两个请求的总体的情况平均响应时间为 2.371 秒,当前总共发送了 733个请求,错误率 为 3.14%(暂定的时候,后面几个请求会断开,也算入了错误率的)。由于这两个请求的响应时间都比较慢和定义的用户数只为20个,所以QPS 比较难达到20 . 读者后面可以自己提高 线程数 或者替换请求地址来测试看看。
注意事项
- 一般而已如果需要进行很高的QPS 的性能测试,不要使用界面来测试,配置完成后,保存jmx 文件之后,再使用命令行来测试会更好,因为界面运行的话,会占用很大资源,实际发送的请求可能得不到自己想要的QPS。界面运行命令,启动 jmeter 的时候就有提示。
jmeter -n -t [jmx file] -l [results file] -e -o [Path to web report folder]
参考资源

一文弄懂使用Jmeter来进行性能测试的更多相关文章
- 一文弄懂神经网络中的反向传播法——BackPropagation【转】
本文转载自:https://www.cnblogs.com/charlotte77/p/5629865.html 一文弄懂神经网络中的反向传播法——BackPropagation 最近在看深度学习 ...
- 一文弄懂-Netty核心功能及线程模型
目录 一. Netty是什么? 二. Netty 的使用场景 三. Netty通讯示例 1. Netty的maven依赖 2. 服务端代码 3. 客户端代码 四. Netty线程模型 五. Netty ...
- 一文弄懂-《Scalable IO In Java》
目录 一. <Scalable IO In Java> 是什么? 二. IO架构的演变历程 1. Classic Service Designs 经典服务模型 2. Event-drive ...
- 一文弄懂-BIO,NIO,AIO
目录 一文弄懂-BIO,NIO,AIO 1. BIO: 同步阻塞IO模型 2. NIO: 同步非阻塞IO模型(多路复用) 3.Epoll函数详解 4.Redis线程模型 5. AIO: 异步非阻塞IO ...
- 一文弄懂CGAffineTransform和CTM
一文弄懂CGAffineTransform和CTM 一些概念 坐标空间(系):视图(View)坐标空间与绘制(draw)坐标空间 CTM:全称current transformation matrix ...
- 【TensorFlow】一文弄懂CNN中的padding参数
在深度学习的图像识别领域中,我们经常使用卷积神经网络CNN来对图像进行特征提取,当我们使用TensorFlow搭建自己的CNN时,一般会使用TensorFlow中的卷积函数和池化函数来对图像进行卷积和 ...
- 一文弄懂Pytorch的DataLoader, DataSet, Sampler之间的关系
以下内容都是针对Pytorch 1.0-1.1介绍. 很多文章都是从Dataset等对象自下往上进行介绍,但是对于初学者而言,其实这并不好理解,因为有的时候会不自觉地陷入到一些细枝末节中去,而不能把握 ...
- 一文弄懂js的执行上下文与执行上下文栈
目录 执行上下文与执行上下文栈 变量提升与函数提升 变量提升 函数提升 变量提升与函数提升的优先级 变量提升的一道题目引出var关键字与let关键字各自的特性 执行上下文 全局执行上下文 函数(局部) ...
- 一文弄懂pytorch搭建网络流程+多分类评价指标
讲在前面,本来想通过一个简单的多层感知机实验一下不同的优化方法的,结果写着写着就先研究起评价指标来了,之前也写过一篇:https://www.cnblogs.com/xiximayou/p/13700 ...
随机推荐
- 跟我一起学Redis之加个哨兵让主从复制更加高可用
前言 主从复制的实现在上一篇已经分享过,虽然主从复制本身的确让读写分离更加高效,但是对于整体高可用存在很大的劣势:当主节点宕机了之后还需要人为重新进行主从关系配置:这不是开玩笑嘛,这样人为干预,故障恢 ...
- 【Spring】Spring中的Bean - 3、Bean的作用域
Bean的作用域 简单记录-Java EE企业级应用开发教程(Spring+Spring MVC+MyBatis)-Spring中的Bean 通过Spring容器创建一个Bean的实例时,不仅可以完成 ...
- o_direct刷新方式和文件系统支持Direct i/o
若让innodb使用o_direct刷新方式,文件系统支持Direct i/o 是非常重要的.为啥
- 绝对定位上下左右都为0 margin为auto为什么能居中
老规矩,先来一段废话,我大学刚入门的时候觉得CSS很简单,记一记就会了,不就是盒模型嘛,现在想来觉得自己那时候真的很自以为是哈哈.但是随着工作沉淀,我明白了任何技术都有着它的深度和广度,正是因为不少人 ...
- 好你个C语言,原来还有这么多副面孔!
C语言可以这样比喻,是一门非常强大的内功心法,学会它可以做到一法通万法.这也是它至今不衰的原因.说了这么多C语言的优点,现在来说说它的缺点.C语言最大的优点也是它最大的缺点,拥有强大的力量时应时刻保持 ...
- scrapy-redis非多网址采集的使用
问题描述 默认RedisSpider在启动时,首先会读取redis中的spidername:start_urls,如果有值则根据url构建request对象. 现在的要求是,根据特定关键词采集. 例如 ...
- Building a high performance JSON parser
Building a high performance JSON parser https://dave.cheney.net/high-performance-json.html
- 配置HDFS的HA
配置前准备: -- 配置hadoop -- 配置ZooKeeper,传送门:https://www.cnblogs.com/zhqin/p/11906106.html 安装配置好hadoop和ZooK ...
- (011)每日SQL学习:SQL开窗函数
开窗函数:在开窗函数出现之前存在着很多用 SQL 语句很难解决的问题,很多都要通过复杂的相关子查询或者存储过程来完成.为了解决这些问题,在 2003 年 ISO SQL 标准加入了开窗函数,开窗函数的 ...
- 内存屏障 WriteBarrier 垃圾回收 屏障技术
https://baike.baidu.com/item/内存屏障 内存屏障,也称内存栅栏,内存栅障,屏障指令等, 是一类同步屏障指令,是CPU或编译器在对内存随机访问的操作中的一个同步点,使得此点之 ...