(一)python 格式化 excel 格式
需求:
问题1、这次 放到 服务器上运行 居然 读取第一个 单元格的字段就报 编码问题。


2、内容转成 csv文件后,发现 顺序 不符合要求,想了一下,也想不出什么高端的方法,只得用最low的方法

总结:
'''
读 excel文件
'''
def read_from_excel(filepath):
data = xlrd.open_workbook(filepath)
table = data.sheets()[]
nor = table.nrows
nol = table.ncols print 'row: %d , colume: %d' % (nor, nol)
resutl = [] for i in range(, nor):
dict = {}
flag = True
# if i == :
# break
for j in range(nol):
title = table.cell_value(, j).encode('utf-8')
print(str(i) + '--' + str(j) + '---'+ title)
#print(chardet.detect(table.cell_value(i, j)))
value = (str(table.cell_value(i, j).encode('utf-8')).replace('\n', ''))
print(str(i) + '--' + str(j) + '---'+value)
# print value
if title == 'identitu_type':
if value == 'SSS':
value = 'SSS card'
elif value == 'PASSPORT':
value = 'Passport'
elif value == 'DRIVERLICENCE':
value = "Driver's license"
elif value == 'PHILHEALTH':
value = "PhilHealth"
elif value == 'UMID':
value = "UMID"
else:
flag = False
print(str(i) + '--' + str(j) + '---'+value) dict[title] = remove_emoji(value)
if flag:
resutl.append(dict) return resutl
'''
字典转 csv文件
'''
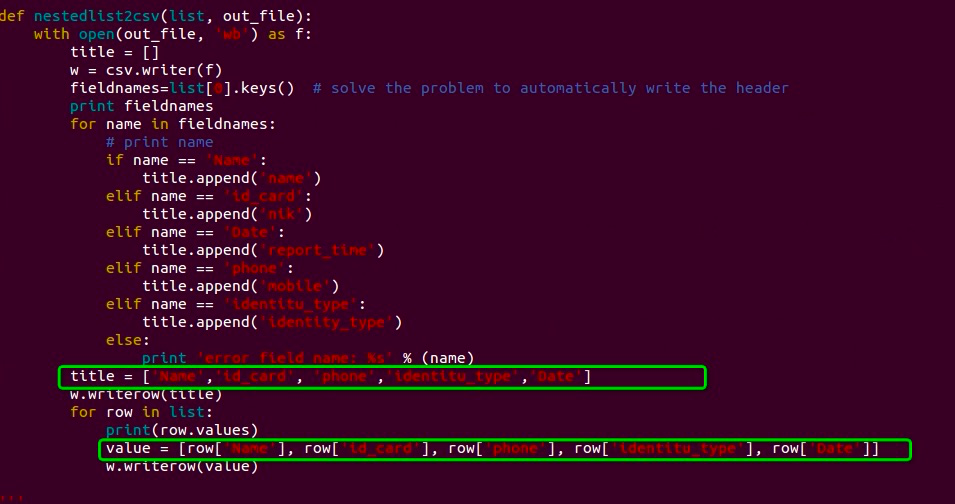
def nestedlist2csv(list, out_file):
with open(out_file, 'wb') as f:
title = []
w = csv.writer(f)
fieldnames=list[].keys() # solve the problem to automatically write the header
print fieldnames title = ['Name','id_card', 'phone','identitu_type','Date']
w.writerow(title)
for row in list:
print(row.values)
value = [row['Name'], row['id_card'], row['phone'], row['identitu_type'], row['Date']]
w.writerow(value)
(一)python 格式化 excel 格式的更多相关文章
- 小兴趣:用python生成excel格式座位表
脚本分两个文件: 1.生成二维随机列表:GenerateLocaltion.py 2.将列表导入excel文件:CreateExcel.py 先上GenerateLocaltion.py: impor ...
- python生成excel格式座位表
脚本分两个文件: 1.生成二维随机列表:GenerateLocaltion.py 2.将列表导入excel文件:CreateExcel.py 先上GenerateLocaltion.py: impor ...
- 利用python将excel数据解析成json格式
利用python将excel数据解析成json格式 转成json方便项目中用post请求推送数据自定义数据,也方便测试: import xlrdimport jsonimport requests d ...
- 分别用Excel和python进行日期格式转换成时间戳格式
最近在处理一份驾驶行为方面的数据,其中要用到时间戳,因此就在此与大家一同分享学习一下. 1.什么是时间戳? 时间戳是指格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01 ...
- 如何使用python在保留原excel格式的前提下插入/修改数据
一.需求分析: 统计的报表中需要每日查询当天数据并追加到原有的excel后面. 因为原始excel格式已经设定好,如果使用xlwt,仅仅指定设定我们要插入的单元格的格式,原始数据的格式会被初始化. 所 ...
- Python 操作Excel之通过xlutils实现在保留原格式的情况下追加写入数据
在Python操作Excel 的模块有 xlrd.xlwt.xlutils等. xlrd:读取Excel文件数据 xlwt:写入Excel 数据,缺点是Excel格式无法复用,为了方便用户,写入的话, ...
- Python生成文本格式的excel\xlwt生成文本格式的excel\Python设置excel单元格格式为文本\Python excel xlwt 文本格式
Python生成文本格式的excel\xlwt生成文本格式的excel\Python设置excel单元格格式为文本\Python excel xlwt 文本格式 解决: xlwt 中设置单元格样式主要 ...
- 第3.11节 Python强大的字符串格式化新功能:format字符串格式化的格式控制
第3.11节 format字符串格式化的格式控制 一. 引言 上节介绍了四种format进行字符串格式化的 ...
- python读取excel,数字都是浮点型,日期格式是数字的解决办法
excel文件内容: 读取excel: # coding=utf-8 import xlrd import sys reload(sys) sys.setdefaultencoding('utf-8' ...
随机推荐
- 以api文档为中心--前后端分开发离新思维
api文档编写好像很简单,其实不是.一个良好的api文档,需要就有以下内容:接口详细描述,接口参数详细描述,接口返回结果详细描述,容易理解的范例.这些内容其实是不少的,编写过程中还非常单调乏味.再加上 ...
- VS2017配置PCL1.9.1 for win10
安装链接 https://www.jianshu.com/p/463f54c91ab7 1.9.1 安装包下载 官网路径: https://github.com/PointCloudLibrary/p ...
- JSOI BZOJ4472 salesman
题目传送门 题目大意 某售货员小T要到若干城镇去推销商品,由于该地区是交通不便的山区,任意两个城镇之间都只有唯一的可能经过其它城镇的路线. 小T 可以准确地估计出在每个城镇停留的净收益.这些净收益可能 ...
- Quartz.Net 任务调度
基于ASP.NET MVC(C#)和Quartz.Net组件实现的定时执行任务调度 在之前的文章<推荐一个简单.轻量.功能非常强大的C#/ASP.NET定时任务执行管理器组件–FluentSch ...
- NPOI升级版本问题
最近做了一个导出Word的功能,需要样式与排版果断选择了NPOI,本以为支持Excel很好,支持Word应该也不会错吧,万万没想到还是挣扎了小一星期. 我的项目是一个13年项目,NPOI版本还很旧,我 ...
- day40 作业
利用线程和进程实现tcp 服务端 from multiprocessing import Process from threading import Thread import socket def ...
- shells学习
shells 脚本 Shell是在Linux内核与用户之间的解释器程序,通常指的是bash,负责向内核翻译及传达用户/程序指令 是liunx系统中的翻译管,解释器类型: ~]#cat /etc/she ...
- 如何在Linux环境下用虚拟机跑Windows!
文章目录 #0x0 Windows #0x1 安装虚拟机 #0x10 下载: #0x11 安装: #0x2 安装虚拟机windows #0x20 下载镜像 #0x21 安装镜像 #0x3 使用Wind ...
- ::before 和 :after 中双冒号和单冒号有什么区别?
在 CSS 中伪类一直用 : 表示,如 :hover, :active 等 伪元素在CSS1中已存在,当时语法是用 : 表示,如 :before 和 :after 后来在CSS3中修订,伪元素用 :: ...
- hacknos靶机实战
工具: kali 192.168.1.6 nmap 打开使用nmap -sP 192.168.1.0/24 扫描活跃的主机 发现目标ip 使用nmap 查看开启了什么服务Nmap -v -A -PN ...