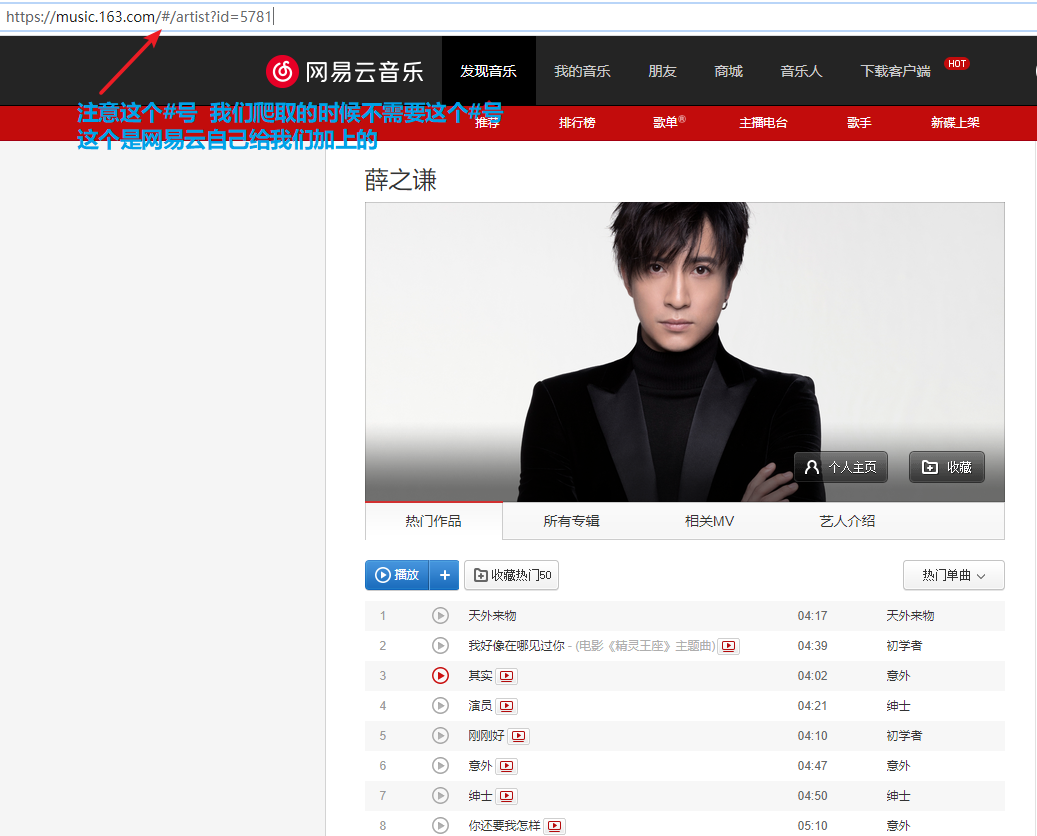
Python 爬取网易云歌手的50首热门作品
使用 requests 爬取网易云音乐
Python 代码:


import json
import os
import time from bs4 import BeautifulSoup
import requests class Music:
"""
下载网易云歌手排行前50的歌曲
""" def __init__(self, init_url, download):
self.init_url = init_url
self.download = download def mkdir(self, path):
"""
创建文件夹
:param path:
:return:
"""
path = path.strip()
if not os.path.exists(path): # 判断此文件夹存不存在
print('创建 ', path, '文件夹')
os.makedirs(path)
return True
else:
print(path, '文件夹已存在,无需创建')
return False def download_video(self, video_url, name):
"""
下载
:param video_url: 音乐的链接
:param name: 歌曲名称
:return:
"""
path = self.download + "\\" + name + '.mp3' # 拼接保存后的文件路径
# print(path)
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36",
}
header = {
"Origin": "http://music.163.com/",
"Referer": video_url, # 请求头必须添加referer
}
headers.update(header) # 更新头部信息
size = 0
start = time.time()
try:
result = requests.get(video_url, headers=headers, stream=True, verify=False)
# print('result', result)
with open(path, "wb") as f:
for chunk in result.iter_content(1024):
f.write(chunk)
f.flush() # 清空缓存
size = size + len(chunk)
print("已下载:%0.2f Mb" % (size / (1024 * 1024)))
except Exception as e:
print("url下载错误:%s" % video_url)
print(e)
stop = time.time()
print("下载完成,耗时:%0.2f秒" % (stop - start)) def spider(self):
r = requests.get(self.init_url).text
soupObj = BeautifulSoup(r, 'lxml')
song_ids = soupObj.find('textarea').text
# print(song_ids)
jobj = json.loads(song_ids)
list01 = []
for item in jobj:
dict01 = {}
# print(item['id']) # 歌曲id
# print(item['name']) # 歌曲名称
dict01['name'] = item['name']
dict01['id'] = item['id']
list01.append(dict01) print(list01)
len_list = len(list01)
print("一共", len_list, "首歌曲")
self.mkdir(self.download)
print('开始切换文件夹')
os.chdir(self.download)
for i in list01:
name = i['name']
id = i['id']
song_url = "http://music.163.com/song/media/outer/url?id=" + str(id) + ".mp3"
print(song_url) # 最终下载的音乐链接
self.download_video(song_url, name) # 下载
len_list = len_list - 1
print("还剩", len_list, "首歌曲需要下载") if __name__ == '__main__':
# init_url = 'https://music.163.com/artist?id=5781' # 薛之谦
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xzq' # 保存地址
# init_url = 'https://music.163.com/artist?id=12429072' # 隔壁老樊
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\gblf' # 保存地址
# init_url = 'https://music.163.com/artist?id=861777' # 华晨宇
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\hcy' # 保存地址
# init_url = 'https://music.163.com/artist?id=6452' # 周杰伦
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\zjl' # 保存地址
# init_url = 'https://music.163.com/artist?id=2116' # 陈奕迅
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\cyx' # 保存地址
# init_url = 'https://music.163.com/artist?id=3684' # 林俊杰
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\ljj' # 保存地址 # init_url = 'https://music.163.com/artist?id=12138269' # 毛不易
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\mby' # 保存地址 # init_url = 'https://music.163.com/artist?id=4292' # 李荣浩
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\lrh' # 保存地址
# init_url = 'https://music.163.com/artist?id=30116848' # 阿冗
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\ar' # 保存地址
# init_url = 'https://music.163.com/artist?id=5771' # 许嵩
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xs' # 保存地址
# init_url = 'https://music.163.com/artist?id=6472' # 张杰
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\zj' # 保存地址
# init_url = 'https://music.163.com/artist?id=5538' # 汪苏泷
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\wsl' # 保存地址
# init_url = 'https://music.163.com/artist?id=1197168' # 徐秉龙
# download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\xbl' # 保存地址
init_url = 'https://music.163.com/artist?id=30284835' # 枯木逢春
download = 'C:\\Users\\AIERXUAN\\Desktop\\BeautifulPicture\\Music\\kmfc' # 保存地址 s = Music(init_url, download)
s.spider()
"http://music.163.com/song/media/outer/url?id=417859631.mp3" 打开这个链接就可以直接播放音乐 后面的id代表的是歌曲在网易云里面的id
由于网易云有的音乐链接已经弃用,所以有的音乐会下载失败
网易云的许多post请求都是被加密的,如果你们破解不了可以点击这个链接去看看大佬是怎么破解的:https://blog.csdn.net/xiaoming_xiaoli/article/details/88019016
关于网易云api的其他接口可以进去这里面查看:http://www.goodpm.net/postreply/python/1010000008139311/关于网易云音乐爬虫的api接口.html
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
每天一个表情包,给生活加个油

Python 爬取网易云歌手的50首热门作品的更多相关文章
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- Python爬取网易云热歌榜所有音乐及其热评
获取特定歌曲热评: 首先,我们打开网易云网页版,击排行榜,然后点击左侧云音乐热歌榜,如图: 关于如何抓取指定的歌曲的热评,参考这篇文章,很详细,对小白很友好: 手把手教你用Python爬取网易云40万 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- Python爬取网易云歌单
目录 1. 关键点 2. 效果图 3. 源代码 1. 关键点 使用单线程爬取,未登录,爬取网易云歌单主要有三个关键点: url为https://music.163.com/discover/playl ...
- 爬虫实战(二) 用Python爬取网易云歌单
最近,博主喜欢上了听歌,但是又苦于找不到好音乐,于是就打算到网易云的歌单中逛逛 本着 "用技术改变生活" 的想法,于是便想着写一个爬虫爬取网易云的歌单,并按播放量自动进行排序 这篇 ...
- python爬取网易云周杰伦所有专辑,歌曲,评论,并完成可视化分析
---恢复内容开始--- 去年在网络上有一篇文章特别有名:我分析42万字的歌词,为搞清楚民谣歌手们在唱些什么.这篇文章的作者是我大学的室友,随后网络上出现了各种以为爬取了XXX,发现了XXX为名的文章 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- python学习之爬虫(一) ——————爬取网易云歌词
接触python也有一段时间了,一提到python,可能大部分pythoner都会想到爬虫,没错,今天我们的话题就是爬虫!作为一个小学生,关于爬虫其实本人也只是略懂,怀着"Done is b ...
随机推荐
- Linux服务器定时脚本
crontab -e 进入编辑模式,同vi编辑器操作. 用户所建立的crontab文件中,每一行都代表一项任务,每行的每个字段代表一项设置,它的格式共分为六个字段,前五段是时间设定段,第六段是要执行的 ...
- 《The Design of a Practical System for Fault-Tolerant Virtual Machines》论文研读
VM-FT 论文研读 说明:本文为论文 <The Design of a Practical System for Fault-Tolerant Virtual Machines> 的个人 ...
- 微服务框架Demo.MicroServer运行手册
一.背景说明: 之前分享过一个微服务开发框架, "享一个集成.NET Core+Swagger+Consul+Polly+Ocelot+IdentityServer4+Exceptionle ...
- 一文了解HAProxy主要特性
本文转自Rancher Labs 在Kubernetes中,Ingress对象定义了一些路由规则,这些规则规定如何将一个客户端请求路由到指定服务,该服务运行在你的集群中.这些规则可以考虑到输入的HTT ...
- JSR 303 进行后台数据校验
一.JSR 303 1.什么是 JSR 303? JSR 是 Java Specification Requests 的缩写,即 Java 规范提案. 存在各种各样的 JSR,简单的理解为 JSR 是 ...
- 核心知识点:python入门
目录 一.python入门day1-day24 day01-03 编程语言 day04 变量 day05 垃圾回收机制(GC机制) 1 引用计数 2 标记清除 3 分代回收 day05 程序交互与基本 ...
- java 数据结构(二):java常用类 二 StringBuffer、StringBuilder
1.String.StringBuffer.StringBuilder三者的对比String:不可变的字符序列:底层使用char[]存储StringBuffer:可变的字符序列:线程安全的,效率低:底 ...
- Django之重写用户模型
django——重写用户模型 Django内建的User模型可能不适合某些类型的项目.例如,在某些网站上使用邮件地址而不是用户名作为身份的标识可能更合理. 1.修改配置文件,覆盖默认的User模型 D ...
- AI芯片
课程作业,正好自己也在学深度学习,正好有所帮助,做了深度学习的AI芯片调研,时间比较短,写的比较仓促,大家随便看看 近年来,深度学习技术,如卷积神经网络(CNN).递归神经网络(RNN)等,成为计算机 ...
- Jsonp处理跨域请求
Jsonp的使用需要前端和后端共同配合来完成 服务端设置(ASP.NET MVC实现): 在将返回的Json数据包在一个方法名称的内部,如上 客户端设置: 同时要加上一个回调函数用于处理请求的数据 在 ...