一、kafka 安装配置
Kafka是什么
Kafka最初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于ZooKeeper协调的内部基础设置,现已捐献给Apache基金会。Kafka是一个流平台,主要用来发布和订阅数据流,是流式数据处理的利器。Kafka用于构建实时数据管道和流应用程序,具有水平可伸缩性,容错性,快速性。Kafka可以处理消费者的网站中的所有动作(网页浏览,搜索和其他用户的行动)流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。对于像Hadoop的一样的日志数据和离线分析系统,但又要求实时处理的,这是一个可行的解决方案。Kafka的目的是通过并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka主要特点
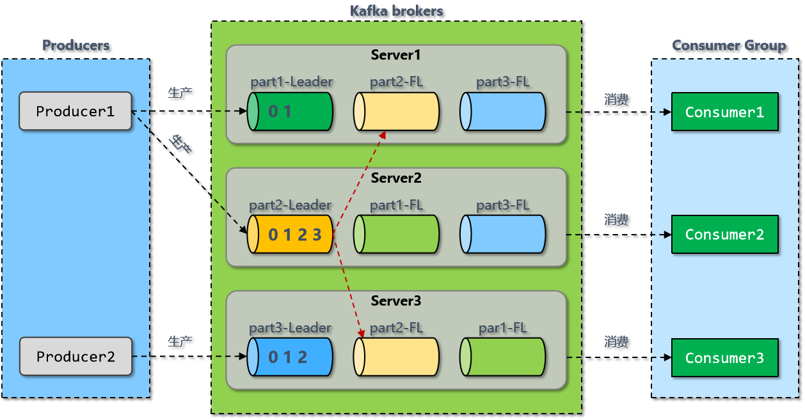
主题和日志
主题是Kafka提供的核心抽象。主题是将信息记录到的某个类别或订阅源名称。Kafka中的主题始终是多用户的,也就是说,一个主题可以有零个,一个或多个消费者来订阅写入该主题的数据。
对于每个主题,Kafka集群都会维护一个分区。每个分区都是由有序的不变的记录序列构成,这些记录连续地“append”到“commit log”中。每个分区中的记录都分配有一个称为“偏移量”的顺序ID,该ID唯一地标识分区中的每个记录。
机器:8核2Ghz,16G内存,千兆网卡,千兆网络
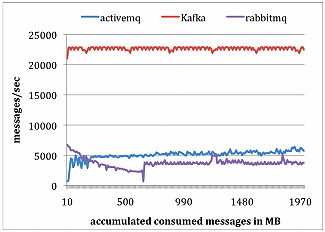
RabbitMQ、ActiveMQ和Kafka对比
生产者测试,总共发布1000万条消息,每条消息200字节。
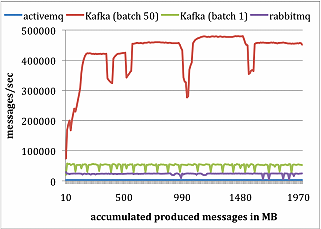
消费者测试,总共获取1000万条消息。
$ wget https://mirror.bit.edu.cn/apache/kafka/2.5./kafka_2.-2.5..tgz
配置
单机伪分布式,复制三份server.properites,但需要修改端口、broker.id、log.dirs。broker.id 不能重复,端口号如果在不同的服务器上可以重复
server.properties
# Kafka broker节点唯一标识
borker.id=
# 端口号(伪分布式不能冲突)
port=
# 对客户端提供的服务器地址和端口
advertised.listener=PLAINTEXT://192.168.56.105:
# Kafka日志存分路径
log.dirs=/home/hadoop/kafka/broker-
server1.properties
# Kafka broker节点唯一标识
borker.id=1
# 端口号(伪分布式不能冲突)
port=9093
# 对客户端提供的服务器地址和端口
advertised.listener=PLAINTEXT://192.168.56.105:9093
# Kafka日志存分路径
log.dirs=/home/hadoop/kafka/broker-1
server2.properties
# Kafka broker节点唯一标识
borker.id=2
# 端口号(伪分布式不能冲突)
port=9094
# 对客户端提供的服务器地址和端口
advertised.listener=PLAINTEXT://192.168.56.105:9094
# Kafka日志存分路径
log.dirs=/home/hadoop/kafka/broker-2
运行
运行(三种方式各选其一),这里注意路径。.sh文件在kafka的bin文件夹下面,properties文件在kafka的config文件夹下。
$ kafka-server-start.sh server.properties &
$ kafka-server-start.sh server.properties1 &
$ kafka-server-start.sh server.properties2 &
配置参数
|
参数名 |
默认值 |
描述 |
|
broker.id |
- |
该服务器的broker ID。如未设置,将生成一个唯一的broker ID。为避免Zookeeper生成的broker ID与用户配置的broker ID之间发生冲突,生成的broker ID从reserved.broker.max.id +1开始。 |
|
log.dirs |
- |
保存日志数据的目录 |
|
zookeeper.connect |
- |
Kafka连接Zookeeper的地址字符串 |
|
advertised.host.name |
- |
仅在未设置advertised.listeners或listeners时使用。使用advertised.listeners替代。 |
|
num.network.threads |
3 |
服务器用于接收请求并且发送响应的线程数 |
|
num.io.threads |
8 |
服务器用于处理请求的线程数,其中可能包括磁盘IO |
|
socket.send.buffer.bytes |
102400 |
发送缓冲区大小。不是有数据就马上发送,而是先存储到缓冲区了等到达一定的大小后再发送,以能提高性能 |
|
socket.receive.buffer.bytes |
102400 |
接收缓冲区大小,当数据到达一定大小后再序列化到磁盘 |
|
socket.request.max.bytes |
104857600 |
请求的最大字节数。这个参数是向kafka请求消息或者向kafka发送消息的请请求的最大数 |
|
num.partitions |
1 |
每个主题默认的分区数 |
|
num.recovery.threads.per.data.dir |
1 |
每个数据目录在启动时用于日志恢复以及在关机时用于刷新的线程数 |
|
offset.metadata.max.bytes |
4096 |
与提交偏移量关联的元数据最大字节数 |
|
offsets.commit.required.acks |
-1 |
提交之前所需的确认写入成功的副本数 |
|
offsets.commit.timeout.ms |
5000 |
偏移量提交超时时间 |
|
offsets.topic.num.partitions |
50 |
偏移主题的分区数 |
|
offsets.topic.replication.factor |
3 |
偏移量主题的复制因子(设置较高以确保可用性) |
|
transaction.state.log.replication.factor |
3 |
事务主题的复制因子(设置较高以确保可用性) |
|
transaction.state.log.min.isr |
2 |
事务主题的min.insync.replicas配置。 |
|
log.flush.interval.messages |
非常大 |
将消息刷新到磁盘之前,在日志分区上累积的消息数 |
|
log.flush.interval.ms |
null |
刷新到磁盘之前,主题中的消息在内存中保留的最长时间(以毫秒为单位)。如果未设置,则使用log.flush.scheduler.interval.ms中的值 |
|
log.retention.hours |
168 |
删除日志文件之前保留日志文件的小时数。此属性级别高于log.retention.ms |
|
log.retention.check.interval.ms |
300000 |
日志清除器根据保留策略检查日志是否可以将其删除的时间间隔(以毫秒为单位) |
|
log.segment.bytes |
1073741824 |
单个日志文件的最大大小。topic的分区下的所有日志会进行分段,达到该大小,会滚动出新的日志文件 |
|
group.initial.rebalance.delay.ms |
3000 |
coordinator在执行rebalance之前等待更多消费者加入新组的时间。 |
|
min.insync.replicas |
1 |
确认写入成功的最小副本数。 |
|
auto.create.topics.enable |
true |
在服务器上启用主题自动创建。 |
|
compression.type |
producer |
主题的压缩类型。此配置接受标准压缩编解码器“ gzip”,“ snappy”,“ lz4”和“ zstd”。“uncompressed”表示不进行压缩,而“producer”表示保留生产者设置的压缩编解码器。 |
|
delete.topic.enable |
true |
如果关闭此配置,则通过管理工具删除主题将无效 |
基本命令使用
创建:
# 创建一个拥有1个分区3个副本的topic
$ kafka-topics.sh --create --zookeeper master:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic
修改:
# 修改topic
$ kafka-topics.sh --alter --zookeeper master:2181 --topic my-replicated-topic --partitions 2
查看:
# 查看topic信息
$ kafka-topics.sh --describe --zookeeper master:2181 --topic my-replicated-topic
删除:
# 删除topic
$ kafka-topics.sh -delete --zookeeper master:2181 -topic my-replicated-topic
查看主题列表
$ kafka-topics.sh --list --zookeeper master:2181
$ kafka-topics.sh --list --zookeeper master:2181,master:2182,master:2183
生产消息:
# 命令方式
$ kafka-console-producer.sh --broker-list master:9092 --topic my-replicated-topic # 调用工具类方式
$ kafka-run-class.sh kafka.tools.ConsoleProducer --broker-list master:9092,master:9093,master94 --topic my-replicated-topic
消息批量生成:
$ kafka-producer-perf-test.sh --topic test --num-records 100 --record-size 1 --throughput 100 --producer-props bootstrap.servers=localhost:9092
消费消息:
# 命令方式
$ kafka-console-consumer.sh --bootstrap-server 192.168.56.105:9092 --from-beginning -topic mytopic-02 # 调用工具类方式
$ kafka-run-class.sh kafka.tools.SimpleConsumerShell --broker-list master:9092,master:9093,master:9094 --topic my-replicated-topic
一、kafka 安装配置的更多相关文章
- Kafka 安装配置 windows 下
Kafka 安装配置 windows 下 标签(空格分隔): Kafka Kafka 内核部分需要安装jdk, zookeeper. 安装JDK 安装JDK就不需要讲解了,安装完配置下JAVA_HOM ...
- 3.kafka安装配置
kafka安装配置 ### 1.集群规划 hadoop102 hadoop103 hadoop104 zk zk zk kafka kafka kafka jar包下载 http://kafka.ap ...
- Kafka安装配置
Kafka是由Apache软件基金会开发的一个高吞吐量的分布式发布订阅消息系统,由Scala和Java编写.官网地址:http://kafka.apache.org 0.基本概念 Broker:Kaf ...
- Kafka 安装配置
1. 下载安装kafka 下载地址:http://apache.fayea.com/kafka/ 解压安装包 tar zxvf kafka_版本号.tgz 2. 配置 修改kafka的config/s ...
- kafka安装配置及操作(官方文档)http://kafka.apache.org/documentation/(有单节点多代理配置)
https://www.cnblogs.com/biehongli/p/7767710.html w3school https://www.w3cschool.cn/apache_kafka/apac ...
- 消息队列集群kafka安装配置
1. 下载wget http://mirror.rise.ph/apache/kafka/0.11.0.0/kafka_2.12-0.11.0.0.tgz2. 安装tar xf kafka_2.12- ...
- Kafka 安装配置 及 简单实验记录
1. 下载二进制文件并解压,并修改 broker.id 的值 wget http://apache.fayea.com/kafka/0.10.0.0/kafka_2.10-0.10.0.0.tgz - ...
- KAFKA安装+配置详解+常用操作+监控
http://blog.csdn.net/hadas_wang/article/details/50056381 http://qiyishi.blog.51cto.com/5731577/18575 ...
- kafka系列一、kafka安装及部署、集群搭建
一.环境准备 操作系统:Cent OS 7 Kafka版本:kafka_2.10 Kafka官网下载:请点击 JDK版本:1.8.0_171 zookeeper-3.4.10 二.kafka安装配置 ...
随机推荐
- HTML 5的革新——语义化标签section和article的区别
原文地址:https://stackoverflow.com/questions/33910294/what-is-the-difference-between-article-and-section ...
- 【Spring注解驱动开发】使用@Import注解给容器中快速导入一个组件
写在前面 我们可以将一些bean组件交由Spring管理,并且Spring支持单实例bean和多实例bean.我们自己写的类,可以通过包扫描+标注注解(@Controller.@Servcie.@Re ...
- Water Testing【皮克定理,多边形面积,线段上点的数目】
Water Testing 传送门:链接 来源:UPC 9656 题目描述 You just bought a large piece of agricultural land, but you n ...
- Codeforces Round #561 (Div. 2) A Tale of Two Lands 【二分】
A Tale of Two Lands 题目链接(点击) The legend of the foundation of Vectorland talks of two integers xx and ...
- Install Centos7 on VirtualBox in mac
Step 1:准备虚拟机及镜像 下载合适的Virtual Box版本 官方下载链接:https://www.virtualbox.org/wiki/Downloads 这里选择的版本是:https:/ ...
- (十二)maven-surefire-plugin,用于自动化测试和单元测试的
原文链接:https://www.bbsmax.com/A/n2d9WPwJDv/ 1.简介 如果你执行过mvn test或者执行其他maven命令时跑了测试用例,你就已经用过maven-surefi ...
- 装cnpm
npm install -g cnpm --registry=https://registry.npm.taobao.org 然后配置环境变量
- Springboot打包放到Tomcat中报错 One or more listener fail to start
1.问题: Springboot项目直接启动不报错,打war包放到外部容器Tomcat.东方通上,在@Weblistener注解的监听器类中报错 One or more listener fail t ...
- Elasticsearch系列---生产集群的索引管理
概要 索引是我们使用Elasticsearch里最频繁的部分日常的操作都与索引有关,本篇从运维人员的视角,来玩一玩Elasticsearch的索引操作. 基本操作 在运维童鞋的视角里,索引的日常操作除 ...
- phpstorm设置xdebug调试
phpstorm设置xdebug调试# wamp开发环境安装完成以后,打开网页,输入 :localhost 检测xdebug是否开启 3.若xdebug已开启,请找到你wamp或者phpstudy的安 ...