sklearn中的pipeline实际应用
前面提到,应用sklearn中的pipeline机制的高效性;本文重点讨论pipeline与网格搜索在机器学习实践中的结合运用:
结合管道和网格搜索以调整预处理步骤以及模型参数
一般地,sklearn中经常用到网格搜索寻找应用模型的超参数;实际上,在训练数据被送入模型之前,对数据的预处理中也会有超参数的介入,比如给数据集添加多项式特征时所指定的指数大小;
而且,一般都是将数据预处理完成后再传入估计器进行拟合,此时利用网格搜索只会单独调整估计器的超参数;如若利用pipeline结合预处理步骤和模型估计器则可以同时寻找最佳的超参数配对。
实例如下:
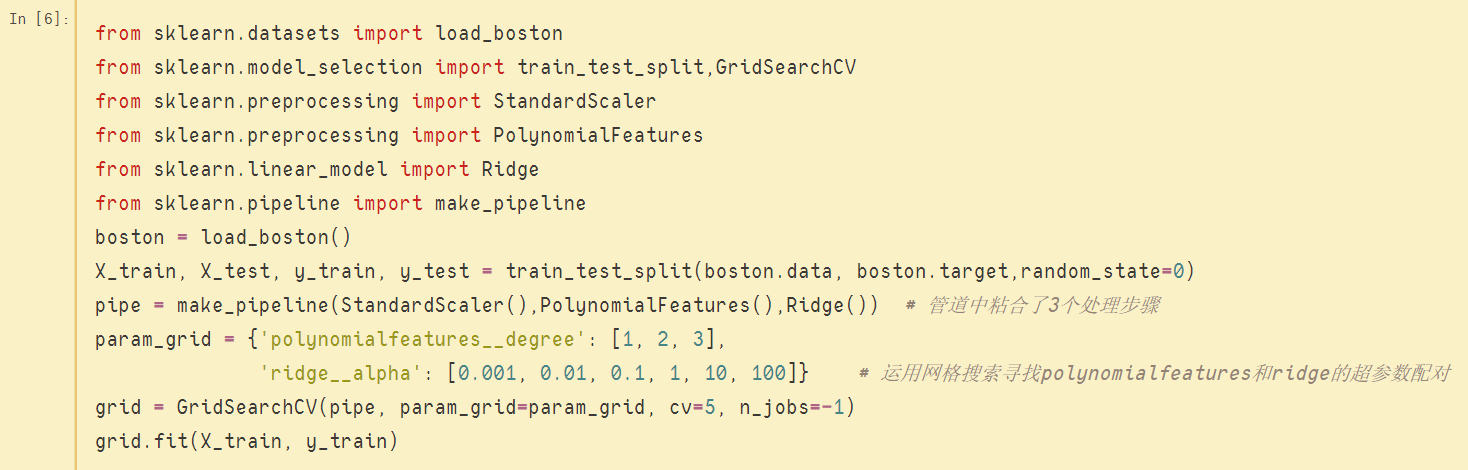
上图中,利用管道结合了3个处理步骤,并使用网格搜索机制针对其中两个步骤的超参数进行调优,一个是预处理阶段的PolynomialFeatures,另一个是模型Ridge
结合管道和网格搜索以选定模型
一般地,选用不同的模型会涉及到不同的预处理步骤,如采用随机森林进行分类训练时可以不对数据作预处理操作,而应用支持向量机时则需要对数据进行标准化;
下图中,利用管道结合预处理中的标准化步骤和分类模型,当模型采用随机森林时,预处理步骤置空,并利用网格搜索寻找随机森林的超参数;当模型采用支持向量机时,启用预处理步骤,并利用网格搜索寻找支持向量机的超参数。
通过此种结合应用,选定最适合的分类模型。

sklearn中的pipeline实际应用的更多相关文章
- sklearn中的Pipeline
在将sklearn中的模型持久化时,使用sklearn.pipeline.Pipeline(steps, memory=None)将各个步骤串联起来可以很方便地保存模型. 例如,首先对数据进行了PCA ...
- sklearn 中的 Pipeline 机制 和FeatureUnion
一.pipeline的用法 pipeline可以用于把多个estimators级联成一个estimator,这么 做的原因是考虑了数据处理过程中一系列前后相继的固定流程,比如feature selec ...
- sklearn 中的 Pipeline 机制
转载自:https://blog.csdn.net/lanchunhui/article/details/50521648 from sklearn.pipeline import Pipeline ...
- sklearn中的pipeline的创建与访问
前期博文提到管道(pipeline)在机器学习实践中的重要性以及必要性,本文则递进一步,探讨实际操作中管道的创建与访问. 已经了解到,管道本质上是一定数量的估计器连接而成的数据处理流,所以成功创建管道 ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- sklearn中的交叉验证(Cross-Validation)
这个repo 用来记录一些python技巧.书籍.学习链接等,欢迎stargithub地址sklearn是利用python进行机器学习中一个非常全面和好用的第三方库,用过的都说好.今天主要记录一下sk ...
- sklearn中的投票法
投票法(voting)是集成学习里面针对分类问题的一种结合策略.基本思想是选择所有机器学习算法当中输出最多的那个类. 分类的机器学习算法输出有两种类型:一种是直接输出类标签,另外一种是输出类概率,使用 ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
- sklearn中的多项式回归算法
sklearn中的多项式回归算法 1.多项式回归法多项式回归的思路和线性回归的思路以及优化算法是一致的,它是在线性回归的基础上在原来的数据集维度特征上增加一些另外的多项式特征,使得原始数据集的维度增加 ...
随机推荐
- 不要在nodejs中阻塞event loop
目录 简介 event loop和worker pool event loop和worker pool中的queue 阻塞event loop event loop的时间复杂度 Event Loop中 ...
- Java——入门“HelloWorld”
//Java程序的结构 //下面这个:外层框架 public class HellloWorld { // Java入口程序框架 //类名与文件名完全一样 public static void mai ...
- JavaScript(二)——在 V8 引擎中书写最优代码
概述 一个 JavaScript 引擎就是一个程序或者一个解释程序,它运行 JavaScript 代码.一个 JavaScript 引擎可以用标准解释程序或者即时编译器来实现,即时编译器即以某种形式把 ...
- (25)Vim 1
1.安装Vim CentOS 系统中,使用如下命令即可安装 Vim: yum install vim 需要注意的是,此命令运行时,有时需要手动确认 [y/n] 遇到此情况,选择 "y&quo ...
- 并发队列:ArrayBlockingQueue实际运用场景和原理
ArrayBlockingQueue实际应用场景 之前在某公司做过一款情绪识别的系统,这套系统通过调用摄像头接口采集人脸信息,将采集的人脸信息做人脸识别和情绪分析,最终经过一定的算法将个人情绪数据转化 ...
- php之魔术方法 __set(),__get(),__isset(),__unset()
__set()与__get() 当一个类里面,属性被设置为私有属性时,这个属性是不能在外部被访问的.那么当我们又想在外部访问时该怎么办呢,我们可以用方法来实现.举例如下: 1 class Test 2 ...
- C#委托的进一步学习
一.委托的说明 namespace LearningCsharp { class Program { //定义一个委托,使用delegate加上方法签名 //将委托理解为存储方法的"数组&q ...
- 南阳ccpc C题 The Battle of Chibi 树状数组+dp
题目: Cao Cao made up a big army and was going to invade the whole South China. Yu Zhou was worried ab ...
- POJ - 1654 利用叉积求三角形面积 去 间接求多边形面积
题意:在一个平面直角坐标系,一个点总是从原点出发,但是每次移动只能移动8个方向的中的一个并且每次移动距离只有1和√2这两种情况,最后一定会回到原点(以字母5结束),请你计算这个点所画出图形的面积 题解 ...
- .net面试--值类型和引用类型
注:下面的示意图主要是为了辅助理解,不代表内存真实情况. Introduction 类型基础是C#的基础概念,了解类型基础及背后的工作原理更有助于我们在编码的时候明白数据在内存中的分配与传递.C#提供 ...