CKafka 架构原理
消息队列 CKafka 技术原理 - 产品简介 - 文档中心 - 腾讯云 https://cloud.tencent.com/document/product/597/10067
消息队列 CKafka 的架构图如下所示:
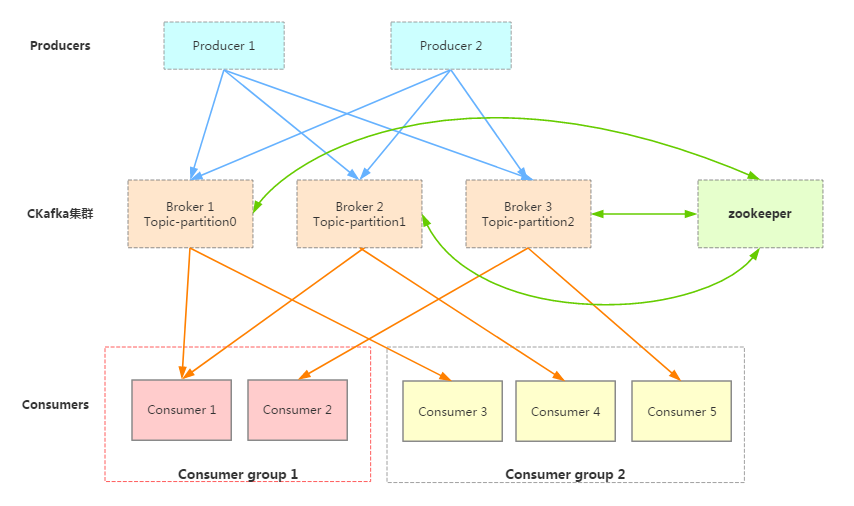
- 生产者 Producer 可能是网页活动产生的消息、服务日志等信息。生产者通过 push 模式将消息发布到 Cloud Kafka 的 Broker 集群。
- 集群通过 Zookeeper 管理集群配置,进行 leader 选举,故障容错等。
- 消费者 Consumer 被划分为若干个 Consumer Group。消费者通过 pull 模式从 Broker 中消费消息。
消息队列 CKafka 相比于自建开源 Apache Kafka 所具备的优势请参考 产品优势。
高吞吐
消息队列 CKafka 中存在大量的网络数据持久化到磁盘和磁盘文件通过网络发送的过程。这一过程的性能直接影响 Kafka 的整体吞吐量,主要通过以下几点实现:
- 高效使用磁盘:磁盘中顺序读写数据,提高磁盘利用率。
- 写 message:消息写到 page cache,由异步线程刷盘。
- 读 message:消息直接从 page cache 转入 socket 发送出去。
- 当从 page cache 没有找到相应数据时,此时会产生磁盘 IO,从磁盘加载消息到 page cache,然后直接从 socket 发出去。
- Broker 的零拷贝(Zero Copy)机制:使用 sendfile 系统调用,将数据直接从页缓存发送到网络上。
- 减少网络开销
- 数据压缩降低网络负载。
- 批处理机制:Producer 批量向 Broker 写数据、Consumer 批量从 Broker 拉数据。
数据持久化
消息队列 CKafka 的数据持久化主要通过如下原理实现:
Topic 中 Partition 存储分布
在消息队列 CKafka 文件存储中,同一 Topic 有多个不同 Partition,每个 Partition 在物理上对应一个文件夹,用户存储该 Partition 中的消息和索引文件。例如,创建两个 Topic,Topic1 中存在5个 Partition,Topic2 中存在10个 Partition,则整个集群上会相应生成5 + 10 = 15个文件夹。Partition 中文件存储方式
Partition 物理上由多个 segment 组成,每个 segment 大小相等,顺序读写,快速删除过期 segment, 提高磁盘利用率。
水平扩展(Scale Out)
- 一个 Topic 可包含多个 Partition,分布在一个或多个 Broker 上。
- 一个消费者可订阅其中一个或者多个 Partition。
- Producer 负责将消息均衡分配到对应的 Partition。
- Partition 内消息是有序的。
Consumer Group
- 消息队列 CKafka 不删除已消费的消息。
- 任何 Consumer 必须属于一个 Group。
- 同一 Consumer Group 中的多个 Consumer 不同时消费同一个 Partition。
- 不同 Group 同时消费同一条消息,多元化(队列模式、发布订阅模式)。
多副本
多副本设计可增强系统可用性、可靠性。
Replica 均匀分布到整个集群,Replica 的算法如下:
- 将所有 Broker(假设共 n 个 Broker)和待分配的 Partition 排序。
- 将第 i 个 Partition 分配到第(i mod n)个 Broker 上。
- 将第 i 个 Partition 的第 j 个 Replica 分配到第((i + j) mode n)个 Broker 上。
Leader Election 选举机制
消息队列 CKafka 在 ZooKeeper 中动态维护了一个 ISR(in-sync replicas),ISR 里的所有 Replica 都跟上了 Leader。只有 ISR 里的成员才有被选为 Leader 的可能。
- ISR 中 f + 1个 Replica,一个 Partition 能在保证不丢失已 commit 的消息的前提下
容忍 f 个 Replica 的失败。 - 共有 2f + 1个 Replica(包含 Leader 和 Follower),commit 之前必须保证有 f + 1个
Replica 复制完消息,为了保证正确选出新的 Leader,fail 的 Replica 不能超过 f 个。
CKafka 架构原理的更多相关文章
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- NET/ASP.NET Routing路由(深入解析路由系统架构原理)(转载)
NET/ASP.NET Routing路由(深入解析路由系统架构原理) 阅读目录: 1.开篇介绍 2.ASP.NET Routing 路由对象模型的位置 3.ASP.NET Routing 路由对象模 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- [Spark内核] 第38课:BlockManager架构原理、运行流程图和源码解密
本课主题 BlockManager 运行實例 BlockManager 原理流程图 BlockManager 源码解析 引言 BlockManager 是管理整个Spark运行时的数据读写的,当然也包 ...
- Istio入门实战与架构原理——使用Docker Compose搭建Service Mesh
本文将介绍如何使用Docker Compose搭建Istio.Istio号称支持多种平台(不仅仅Kubernetes).然而,官网上非基于Kubernetes的教程仿佛不是亲儿子,写得非常随便,不仅缺 ...
- Hive的配置| 架构原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hi ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- 简单理解Hadoop架构原理
一.前奏 Hadoop是目前大数据领域最主流的一套技术体系,包含了多种技术. 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 有些朋友可能 ...
- Spark集群基础概念 与 spark架构原理
一.Spark集群基础概念 将DAG划分为多个stage阶段,遵循以下原则: 1.将尽可能多的窄依赖关系的RDD划为同一个stage阶段. 2.当遇到shuffle操作,就意味着上一个stage阶段结 ...
随机推荐
- 【Tomcat】手写迷你版Tomcat
目录 源码地址 一,分析 Mini版Tomcat需要实现的功能 二,开发--准备工作 2.1 新建Maven工程 2.2 定义编译级别 2.3 新建主类编写启动入口和端口 三,开发--1.0版本 3. ...
- Redis基础篇(三)持久化:AOF日志
Redis是内存数据库,但是一旦服务器宕机,内存中的数据将会全部丢失. 最简单的恢复方式是从后端数据库恢复,但这种方式有两个问题: 频繁访问数据库,会给数据库带来巨大的压力: 从数据库中读取相比从Re ...
- sql 中 foreach 中传入多个不同的参数问题
<!--查找某用户绑定的药物不良反应报告列表--> <select id="selectSurveyListByUserProId" resultType=&qu ...
- [Machine Learning] 逻辑回归 (Logistic Regression) -分类问题-逻辑回归-正则化
在之前的问题讨论中,研究的都是连续值,即y的输出是一个连续的值.但是在分类问题中,要预测的值是离散的值,就是预测的结果是否属于某一个类.例如:判断一封电子邮件是否是垃圾邮件:判断一次金融交易是否是欺诈 ...
- Java优雅停机
Java的优雅停机通常通过注册JDK的ShootDownHook实现,当系统接受到退出指令后,首先标记系统处于退出状态,不再接受新的消息,然后将积压的消息处理完,最后调用资源回收接口将资源销毁,最后各 ...
- tabControl组件的吸顶效果
最开始,还没有使用better-scroll插件的时候,直接在class中设定了一定的position为sticky,设置一定的top达成了效果.但是,使用better-scroll组件后,这些属性就 ...
- Liunx运维(八)-LIunx磁盘与文件系统管理命令
文档目录: 一.fdisk:磁盘分区工具 二.partprobe:更新内核的硬盘分区表信息 三.tune2fs:调整ext2/ext3/ext4文件系统参数 四.parted:磁盘分区工具 五.mkf ...
- idea启动build过慢
原文链接http://zhhll.icu/2020/04/17/idea/idea%E4%B9%8B%E7%BC%96%E8%AF%91%E9%97%AE%E9%A2%98/ 之前使用idea的时候每 ...
- HP Proliant DL580 gen9 阵列卡P440AR 高速缓存 被禁用
摘录内容: IMPORTANT: This issue does NOT occur when the operating system shuts down gracefully. In addit ...
- 为什么.NET Standard 仍然有意义?
.NET Standard 是.NET 官方的API规范,可在许多.NET环境中使用.之所以存在,面向.NET Standard 2.0的库提供了最大可能的覆盖范围,并启用了几乎所有现代的.NET功能 ...