1 Spark概述
第1章 Spark概述
1.1 什么是Spark
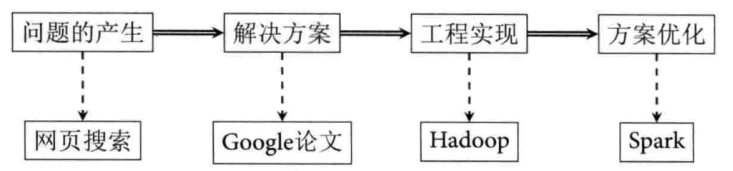
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。项目是用Scala进行编写。
目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子项目,Spark是基于内存计算的大数据并行计算框架。除了扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。Spark 适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。通过在一个统一的框架下支持这些不同的计算,Spark 使我们可以简单而低耗地把各种处理流程整合在一起。而这样的组合,在实际的数据分析 过程中是很有意义的。不仅如此,Spark 的这种特性还大大减轻了原先需要对各种平台分 别管理的负担。
大一统的软件栈,各个组件关系密切并且可以相互调用,这种设计有几个好处:1、软件栈中所有的程序库和高级组件 都可以从下层的改进中获益。2、运行整个软件栈的代价变小了。不需要运 行 5 到 10 套独立的软件系统了,一个机构只需要运行一套软件系统即可。系统的部署、维护、测试、支持等大大缩减。3、能够构建出无缝整合不同处理模型的应用。
Spark的内置项目如下:
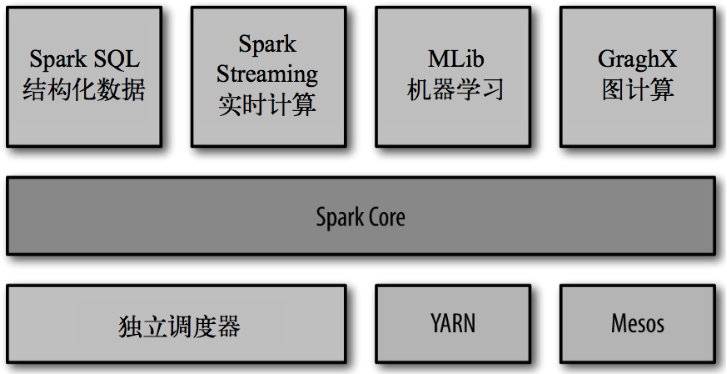
Spark Core:实现了 Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统 交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称RDD)的 API 定义。
Spark SQL:是 Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。Spark SQL 支持多种数据源,比 如 Hive 表、Parquet 以及 JSON 等。
Spark Streaming:是 Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据 导入等额外的支持功能。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计 算。为了实现这样的要求,同时获得最大灵活性,Spark 支持在各种集群管理器(cluster manager)上运行,包括 Hadoop YARN、Apache Mesos,以及 Spark 自带的一个简易调度 器,叫作独立调度器。
Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
1.2 Spark特点
1)快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中的。
2)易用:Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
3)通用:Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4)兼容性:Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
1.3 Spark的用户和用途
我们大致把Spark的用例分为两类:数据科学应用和数据处理应用。也就对应的有两种人群:数据科学家和工程师。
数据科学任务:主要是数据分析领域,数据科学家要负责分析数据并建模,具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的使用 Python、 Matlab 或 R 语言进行编程的能力。
数据处理应用:工程师定义为使用 Spark 开发 生产环境中的数据处理应用的软件开发者,通过对接Spark的API实现对处理的处理和转换等任务。
1 Spark概述的更多相关文章
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- Spark概述及集群部署
Spark概述 什么是Spark (官网:http://spark.apache.org) Spark是一种快速.通用.可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- Spark入门:第1节 Spark概述:1 - 4
2.spark概述 2.1 什么是spark Apache Spark™ is a unified analytics engine for large-scale data processing. ...
- Spark概述
背景 目前按照大数据处理类型来分大致可以分为:批量数据处理.交互式数据查询.实时数据流处理,这三种数据处理方式对应的业务场景也都不一样: 关注大数据处理的应该都知道Hadoop,而Hadoop的核心为 ...
- Hive On Spark概述
Hive现有支持的执行引擎有mr和tez,默认的执行引擎是mr,Hive On Spark的目的是添加一个spark的执行引擎,让hive能跑在spark之上: 在执行hive ql脚本之前指定执行引 ...
- Spark 概述
Spark 是什么? ● 官方文档解释:Apache Spark is a fast and general engine for large-scale data processing. 通俗的理解 ...
- 3.1 Spark概述
一.Spark简介 1.Spark的特点 特点1:运行速度快(内存计算,循环数据流.有向无环图设计机制) 把所有针对数据集的操作转换成一张有向无环图,整个执行引擎调度都是基于这个有向无环图,对这个有向 ...
- Spark学习一:Spark概述
1.1 什么是Spark Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. 一站式管理大数据的所有场景(批处理,流处理,sql) spark不涉及到数据的存储,只 ...
随机推荐
- Windows 平台做 Python 开发的最佳组合
在 Windows 上怎样做 Python 开发?是像大神那样使用纯文本编辑器,还是用更加完善的 IDE?到底是用自带的命令行工具,还是需要装新的 Terminal?本文将带你了解如何利用微软官方维护 ...
- ffmpeg获取视频封面图片
ffmpeg百度云盘下载地址:https://pan.baidu.com/s/1Am_x0abBvXTrbCFPHs5e9Q 提取码:4y2r /** * ffmpeg百度云盘下载地址:https:/ ...
- Python的条件判断与循环
1.if语句 Python中条件选择语句的关键字为:if .elif .else这三个.其基本形式如下 if condition: blockelif condition: block...else: ...
- JDK动态代理和 CGLIB 代理
JDK动态代理和 CGLIB 代理 JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期期间创建一个接口的实现类来完成对目标对象的代理. 代码示例 接口 public interface ...
- 递归-N皇后问题
// // #include <stdio.h> /*可以用回溯,但是我已经不太熟悉回溯了!!!!!!!!呜呜呜 * */ #include <iostream> #inclu ...
- Vue中数组元素被替换,页面没有动态展示
原始代码 页面没有相应goodsList替换,打印goodsList数据已经被替换: (借用https://www.cnblogs.com/belongs-to-qinghua/p/11112613. ...
- ctime使用及datetime简单使用
from time import ctime,sleep def Clock(func): def clock(): print("现在是:",ctime()) func() sl ...
- 线程_gevent自动切换CPU协程
import gevent def f(n): for i in range(n): print (gevent.getcurrent(), i) # gevent.getcurrent() 获取当前 ...
- Django学习路3
1.打开 Data Source alt insert 打开 Data Source 找到 db.sqlite3 确定 Download 下载后 TestConnection 测试是否成功 2.项目下 ...
- PHP array_diff() 函数
实例 比较两个数组的值,并返回差集: <?php $a1=array("a"=>"red","b"=>"gree ...