面试官:小伙子,你给我说一下你对MySQL索引的理解吧
一、索引是什么?
索引是帮助MySQL高效获取数据的数据结构。
二、索引能干什么?
索引非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。索引能够轻易将查询性能提高好几个数量级,总的来说就是可以明显的提高查询效率。
三、索引的分类?
1、从存储结构上来划分:BTree索引(B-Tree或B+Tree索引),Hash索引,full-index全文索引,R-Tree索引。这里所描述的是索引存储时保存的形式,
2、从应用层次来分:普通索引,唯一索引,复合索引
3、根据中数据的物理顺序与键值的逻辑(索引)顺序关系:聚集索引,非聚集索引。
平时讲的索引类型一般是指在应用层次的划分。
就像手机分类:安卓手机,IOS手机 与 华为手机,苹果手机,OPPO手机一样。
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
四、索引的底层实现
mysql默认存储引擎innodb只显式支持B-Tree( 从技术上来说是B+Tree)索引,对于频繁访问的表,innodb会透明建立自适应hash索引,即在B树索引基础上建立hash索引,可以显著提高查找效率,对于客户端是透明的,不可控制的,隐式的。
不谈存储引擎,只讨论实现(抽象)
4.1、Hash索引
基于哈希表实现,只有精确匹配索引所有列的查询才有效,对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码(hash code),并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针。

4.2、B-Tree索引(MySQL使用B+Tree)
B-Tree能加快数据的访问速度,因为存储引擎不再需要进行全表扫描来获取数据,数据分布在各个节点之中。
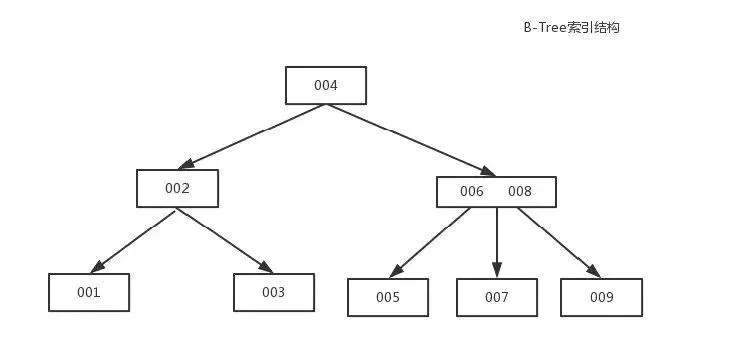
4.3、B+Tree索引
是B-Tree的改进版本,同时也是数据库索引索引所采用的存储结构。数据都在叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比B-Tree来说,进行范围查找时只需要查找两个节点,进行遍历即可。而B-Tree需要获取所有节点,相比之下B+Tree效率更高。
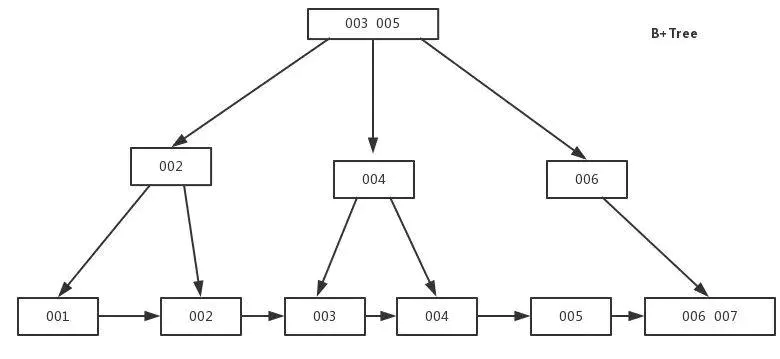
结合存储引擎来讨论(一般默认使用B+Tree)
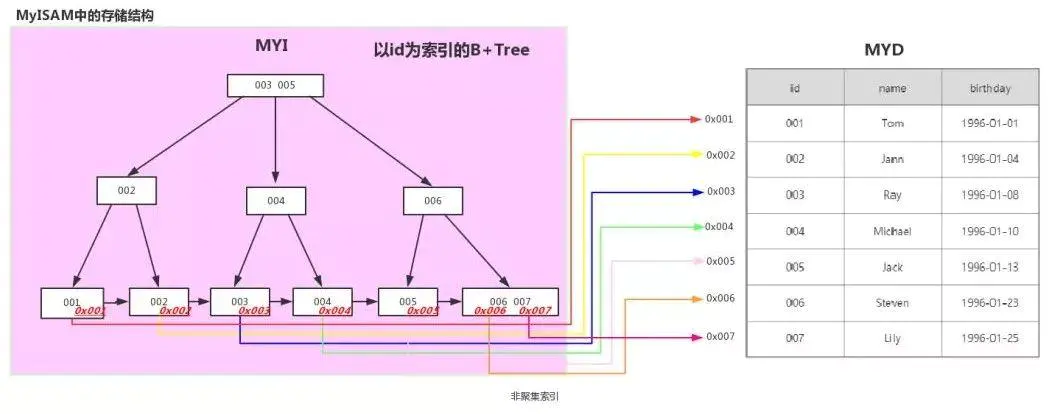
案例:假设有一张学生表,id为主键
| id | name | birthday |
|---|---|---|
| 1 | Tom | 1996-01-01 |
| 2 | Jann | 1996-01-04 |
| 3 | Ray | 1996-01-08 |
| 4 | Michael | 1996-01-10 |
| 5 | Jack | 1996-01-13 |
| 6 | Steven | 1996-01-23 |
| 7 | Lily | 1996-01-25 |
在MyISAM引擎中的实现(二级索引也是这样实现的)
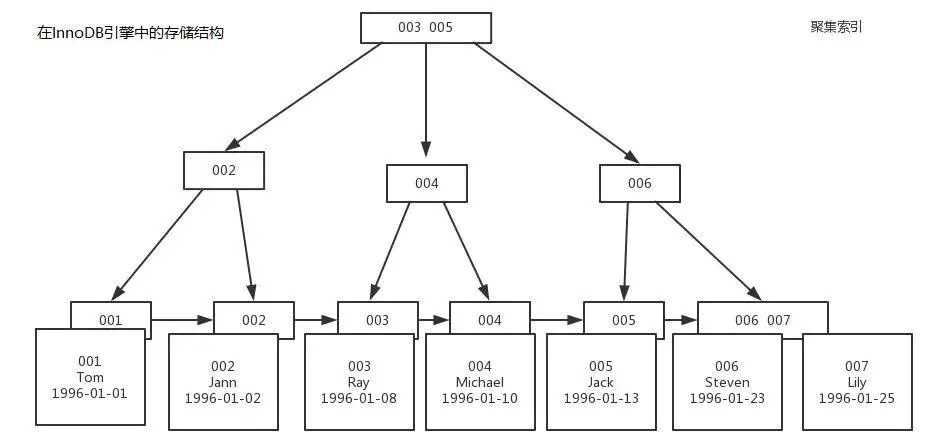
在InnoDB中的实现
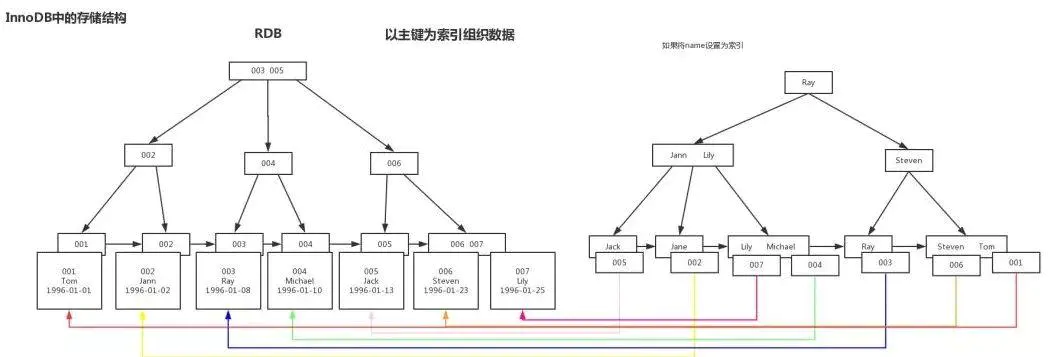
五、为什么索引结构默认使用B+Tree,而不是Hash,二叉树,红黑树?
B-tree:因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出),指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
Hash:虽然可以快速定位,但是没有顺序,IO复杂度高。
二叉树:树的高度不均匀,不能自平衡,查找效率跟数据有关(树的高度),并且IO代价高。
红黑树:树的高度随着数据量增加而增加,IO代价高。
六、为什么官方建议使用自增长主键作为索引?
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
6.1、插入连续的数据:

6.2、插入非连续的数据:

七、简单总结下
1、MySQL使用B+Tree作为索引数据结构。
2、B+Tree在新增数据时,会根据索引指定列的值对旧的B+Tree做调整。3、从物理存储结构上说,B-Tree和B+Tree都以页(4K)来划分节点的大小,但是由于B+Tree中中间节点不存储数据,因此B+Tree能够在同样大小的节点中,存储更多的key,提高查找效率。4、影响MySQL查找性能的主要还是磁盘IO次数,大部分是磁头移动到指定磁道的时间花费。5、MyISAM存储引擎下索引和数据存储是分离的,InnoDB索引和数据存储在一起。6、InnoDB存储引擎下索引的实现,(辅助索引)全部是依赖于主索引建立的(辅助索引中叶子结点存储的并不是数据的地址,还是主索引的值,因此,所有依赖于辅助索引的都是先根据辅助索引查到主索引,再根据主索引查数据的地址)。
8、由于InnoDB索引的特性,因此如果主索引不是自增的(id作主键),那么每次插入新的数据,都很可能对B+Tree的主索引进行重整,影响性能。因此,尽量以自增id作为InnoDB的主索引。
面试官:小伙子,你给我说一下你对MySQL索引的理解吧的更多相关文章
- 《吊打面试官》系列-Redis基础
你知道的越多,你不知道的越多 点赞再看,养成习惯 前言 Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行360°的刁难.作为一个在互联 ...
- [转帖]《吊打面试官》系列-Redis基础
<吊打面试官>系列-Redis基础 https://www.cnblogs.com/aobing/archive/2019/11/07/11811194.html 你知道的越多,你不知 ...
- 《吊打面试官》系列-Redis基础知识
前言Redis在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在Redis的使用和原理方面对小伙伴们进行360°的刁难.作为一个在互联网公司面一次拿一次offer的面霸(请允许我使用一下 ...
- 我以为我对Mysql索引很了解,直到我遇到了阿里的面试官
GitHub 4.8k Star 的Java工程师成神之路 ,不来了解一下吗? GitHub 4.8k Star 的Java工程师成神之路 ,真的不来了解一下吗? GitHub 4.8k Star 的 ...
- MySQL 三万字精华总结 + 面试100 问,吊打面试官绰绰有余(收藏系列)
写在之前:不建议那种上来就是各种面试题罗列,然后背书式的去记忆,对技术的提升帮助很小,对正经面试也没什么帮助,有点东西的面试官深挖下就懵逼了. 个人建议把面试题看作是费曼学习法中的回顾.简化的环节,准 ...
- 【MySQL】面试官:如何添加新数据库到MySQL主从复制环境?
写在前面 今天,一名读者反馈说:自己出去面试,被面试官一顿虐啊!为什么呢?因为这名读者面试的是某大厂的研发工程师,偏技术型的.所以,在面试过程中,面试官比较偏向于问技术型的问题.不过,技术终归还是要服 ...
- 大厂面试官竟然这么爱问Kafka,一连八个Kafka问题把我问蒙了?
本文首发于公众号:五分钟学大数据 在面试的时候,发现很多面试官特别爱问Kafka相关的问题,这也不难理解,谁让Kafka是大数据领域中消息队列的唯一王者,单机十万级别的吞吐量,毫秒级别的延迟,这种天生 ...
- 面试官:为什么Mysql中Innodb的索引结构采取B+树?
前言 如果面试官问的是,为什么Mysql中Innodb的索引结构采取B+树?这个问题时,给自己留一条后路,不要把B树喷的一文不值.因为网上有些答案是说,B树不适合做文件存储系统的索引结构.如果按照那种 ...
- 面试官问我MySQL索引,我
面试官:我看你简历上写了MySQL,对MySQL InnoDB引擎的索引了解吗? 候选者:嗯啊,使用索引可以加快查询速度,其实上就是将无序的数据变成有序(有序就能加快检索速度) 候选者:在InnoDB ...
随机推荐
- 存储系列1-openfiler开源存储管理平台实践
(一)openfiler介绍 Openfiler能把标准x86/64架构的系统变为一个更强大的NAS.SAN存储和IP存储网关,为管理员提供一个强大的管理平台,并能应付未来的存储需求.openfile ...
- 【Azure微服务 Service Fabric 】因证书过期导致Service Fabric集群挂掉(升级无法完成,节点不可用)
问题描述 创建Service Fabric时,证书在整个集群中是非常重要的部分,有着用户身份验证,节点之间通信,SF升级时的身份及授权认证等功能.如果证书过期则会导致节点受到影响集群无法正常工作. 当 ...
- Docker学习笔记之-部署.Net Core 3.1项目到Docker容器,并使用Nginx反向代理(CentOS7)(一)
上一节演示如何安装Docker,链接:Docker学习笔记之-在CentOS中安装Docker 本节演示 将.net core 3.1 部署到docker容器当中,并使用 Nginx反向代理,部署平台 ...
- Stream(三)
public class Test08 { /* * 二.中间的加工操作 * (1)filter(Predicate p):过滤 * (2)distinct():去重 * (3)limit(long ...
- 将字符串反转的 Java 方法
Java中经常会用到将字符串进行反转的时候,程序员孔乙己总结了7种反转方法,如下: //方法1 递归方法 public static String reverse1(String s) { int l ...
- SpringMVC找不到js等文件,有两种方式可以解决这个问题。
(1)当你选择不过滤任何文件时,必须去springmvc.xml去设置默认加载. (2)如果你在web.xml中设置的过滤请求那么你就不用设置默认加载,但请求的url必须符合格式.
- Luogu P4643 阿狸和桃子的游戏
题解 传送门 既然题目要求的是差值 所以对于减数和被减数同时加上一个相同的数是毫无影响的 (详情参考人教版六年级上册数学教材) 所以不妨把边权分成两半 分别加给两个顶点 然后,直接每次选最大的点就好了 ...
- eclipse配置NS3
配置环境
- Spring Security 实战干货:OAuth2第三方授权初体验
1. 前言 Spring Security实战干货系列 现在很多项目都有第三方登录或者第三方授权的需求,而最成熟的方案就是OAuth2.0授权协议.Spring Security也整合了OAuth2. ...
- 剑指offer之顺序打印数组
算法的要求为: 输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打 ...