孟德尔随机化(Mendelian Randomization) 统计功效(power)和样本量计算
孟德尔随机化(Mendelian Randomization) 统计功效(power)和样本量计算
1 统计功效(power)概念
统计功效(power)指的是在原假设为假的情况下,接受备择假设的概率。
用通俗的话说就是,P<0.05时,结果显著(接受备择假设); 在此结论下,我们有多大的把握坚信结果的显著性,此时需要用到power来表示这种“把握”。
统计功效(power)的计算公式为 1-β。
说到β,要提一下假设检验中的一型错误和二型错误。
一型错误,用 α 表示,全称 Type-I error;
二型错误,用 β 表示,全称 type-II error;
有个比较经典的图表示 Type-I error 和 type-II error:

(图片来源忘了,侵删)
因此,Power越大,犯第二型错误的概率越小,我们就更有把握认为结果是显著的。
下面分别从网页版和代码版讲一下怎么计算power和样本量,网页版和代码版均可完成分析,任选其一。
2 网页版计算孟德尔随机化power和样本量
网页版的见地址:https://shiny.cnsgenomics.com/mRnd/
2.1 网页版计算孟德尔随机化power
计算power需要用到7个输入参数,分别为sample size, α, βyx, βOLS, R2xz, σ2(x), σ2(y)。 见下图:
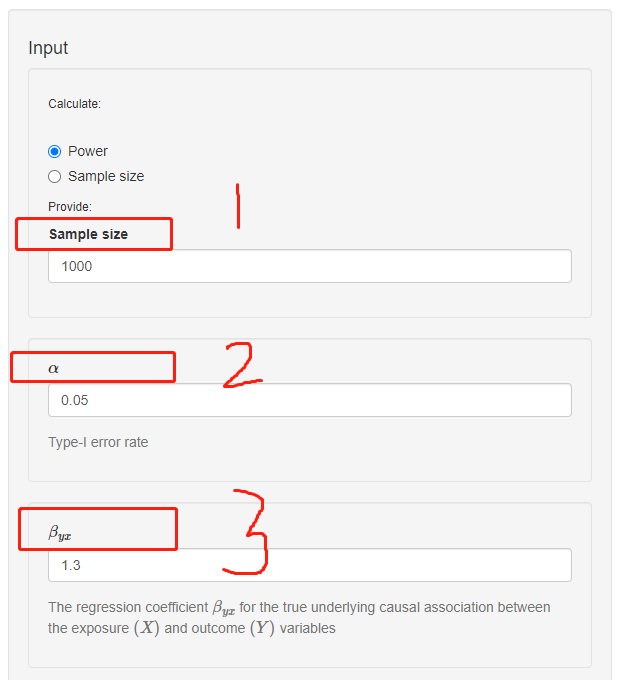
第一个参数sample size,指的是研究的样本量大小;在这里假定样本量是1000;
第二个参数是 α,指的是一型错误(Type-I error),默认0.05;
第三个参数是βyx,指的是暴露变量和结局变量之间 真实 的相关系数。如何理解 真实 呢,以大胸和不爱运动为例,在校正了性别和年龄等一系列可能会影响大胸和不爱运动的变量后得到的回归系数,称为暴露变量(不爱运动)和结局变量(大胸)真实的相关系数;
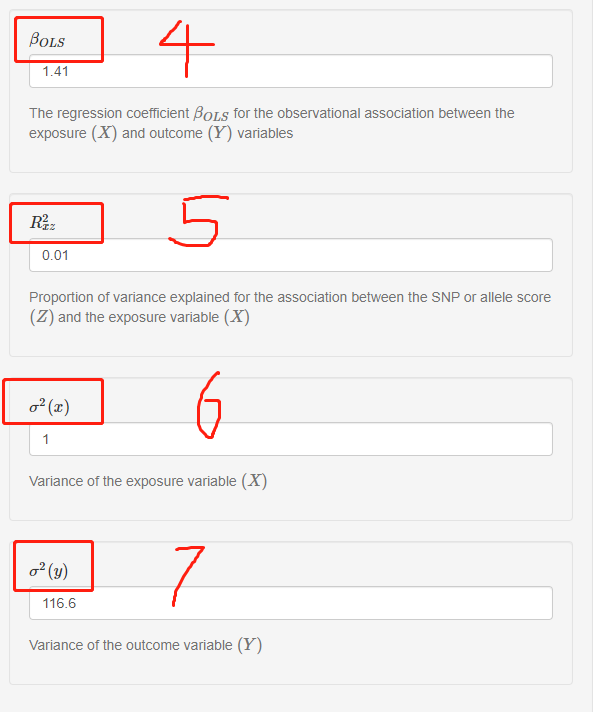
第四个参数是βOLS,指的是暴露变量(不爱运动)和结局变量(大胸)之间 观察到 的相关系数,跟βyx的区别在于,这里不校正协变量;
第五个参数是R2xz,指的是工具变量(一般指SNP)对暴露变量(不爱运动)的解释度;
第六个参数是σ2(x),指的是暴露变量(不爱运动)的方差;
第七个参数是σ2(y),指的是结局变量(大胸)的方差;
有了这7个参数以后,我们就可以计算power了。 power结果如下所示:

2.2 网页版计算孟德尔随机化样本量
这个步骤同计算power的步骤,唯一不同的是,这个步骤是通过给定power,计算该power下需要的样本量;
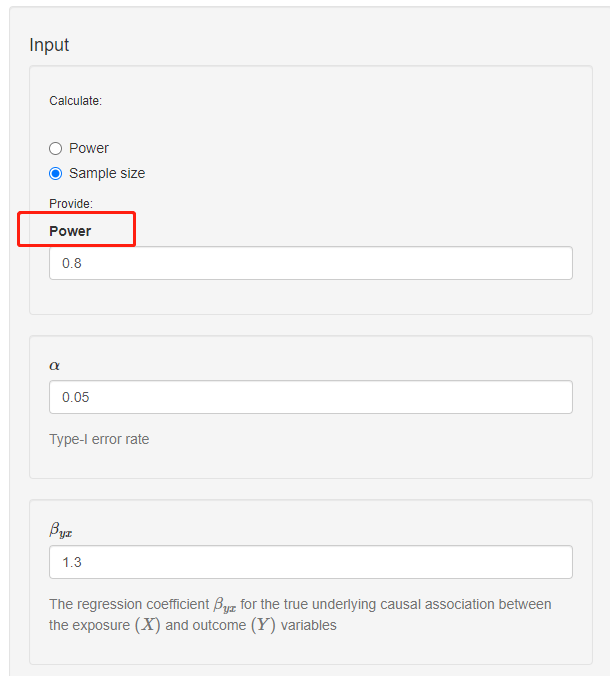
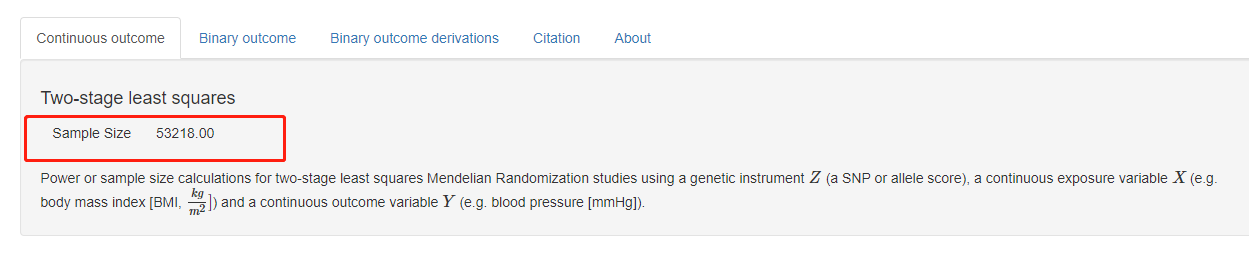
在这里,我们给定的power是0.8,其他的参数同上面的步骤,得到的样本量如下所示:
3 代码版计算孟德尔随机化power和样本量
该代码出自网站:https://github.com/kn3in/mRnd
3.1 代码版计算孟德尔随机化power
在Rscript中运行results函数(以下代码完全照搬,不要修改任何参数):
results <- function(N, alpha, byx, bOLS, R2xz, varx, vary, epower) {
threschi <- qchisq(1 - alpha, 1) # threshold chi(1) scale
f.value <- 1 + N * R2xz / (1 - R2xz) #R2xz, Proportion of variance explained for the association between the SNP or allele score (Z) and the exposure variable (X)
con <- (bOLS - byx) * varx # covariance due to YX confounding
vey <- vary - byx * varx * (2 * bOLS - byx)
if (vey < 0) {
data.frame(Error = "Error: Invalid input. The provided parameters result in a negative estimate for variance of the error term in the two-stage least squares model.")
} else {
if (is.na(epower)) {
b2sls <- byx + con / (N * R2xz)
v2sls <- vey / (N * R2xz * varx)
NCP <- b2sls^2 / v2sls
# 2-sided test
power <- 1 - pchisq(threschi, 1, NCP)
data.frame(Parameter = c("Power", "NCP", "F-statistic"), Value = c(power, NCP, f.value), Description = c("", "Non-Centrality-Parameter", "The strength of the instrument"))
} else {
# Calculation of sample size given power
z1 <- qnorm(1 - alpha / 2)
z2 <- qnorm(epower)
Z <- (z1 + z2)^2
# Solve quadratic equation in N
a <- (byx * R2xz)^2
b <- R2xz * (2 * byx * con - Z * vey / varx)
c <- con^2
N1 <- ceiling((-b + sqrt(b^2 - 4 * a * c)) / (2 * a)) #ceiling返回对应数字的'天花板'值,就是不小于该数字的最小整数
data.frame(Parameter = "Sample Size", Value = N1)
}
}
}
随后运行以下如下命令:
results(N=1000,alpha=0.05, byx=1.3, bOLS=1.41, R2xz=0.01, varx=1, vary=116.6, epower=NA)
各个参数代表的意义如下所示:
alpha=0.05 #Type-I error rate
N=1000 # Sample size
byx=1.3 #the regression coefficients for the association between exposure (X) and outcome (Y) variables (adjusted for confounders).
R2xz=0.01 # genetic instrument that explains R2xz=0.01 of variation in exposure (X)
bOLS=1.41 # the regression coefficients for the association between exposure (X) and outcome (Y) variables (no confounder-adjustment)
varx=1 # Variance of the exposure variable (X)
vary=116.6 #Variance of the outcome variable (Y)
得到的结果如下所示:

3.2 代码版计算孟德尔随机化样本量
该步骤与前面一致,运行results函数后,再运行如下命令:
results(N=NA,alpha=0.05, byx=1.3, bOLS=1.41, R2xz=0.01, varx=1, vary=116.6, epower=0.8)
各个参数代表的意义如下所示:
alpha=0.05 #Type-I error rate
epower=0.8 # 1-(type-II error rate)
byx=1.3 #the regression coefficients for the association between exposure (X) and outcome (Y) variables (adjusted for confounders).
R2xz=0.01 # genetic instrument that explains R2xz=0.01 of variation in exposure (X)
bOLS=1.41 # the regression coefficients for the association between exposure (X) and outcome (Y) variables (no confounder-adjustment)
varx=1 # Variance of the exposure variable (X)
vary=116.6 #Variance of the outcome variable (Y)
得到的结果如下所示:

原文出处:Brion M J A, Shakhbazov K, Visscher P M. Calculating statistical power in Mendelian randomization studies[J]. International journal of epidemiology, 2013, 42(5): 1497-1501.
此推文感谢彭师姐推荐~

孟德尔随机化(Mendelian Randomization) 统计功效(power)和样本量计算的更多相关文章
- 有相关性就有因果关系吗,教你玩转孟德尔随机化分析(mendelian randomization )
流行病学研究常见的分析就是相关性分析了. 相关性分析某种程度上可以为我们提供一些研究思路,比如缺乏元素A与某种癌症相关,那么我们可以通过补充元素A来减少患癌率.这个结论的大前提是缺乏元素A会导致这种癌 ...
- R数据分析:孟德尔随机化实操
好多同学询问孟德尔随机化的问题,我再来尝试着梳理一遍,希望对大家有所帮助,首先看下图1分钟,盯着看将下图印在脑海中: 上图是工具变量(不知道工具变量请翻之前的文章)的模式图,明确一个点:我们做孟德尔的 ...
- HDU 1251 统计难题(字典树计算前缀数量)
字典树应用,每个节点上对应的cnt是以它为前缀的单词的数量 #include<stdio.h> #include<string.h> struct trie { int cnt ...
- 127_Power Pivot&Power BI DAX计算订单商品在库时间(延伸订单仓储费用)
博客:www.jiaopengzi.com 焦棚子的文章目录 请点击下载附件 一.背景 前面已经写过一个先进先出的库龄案例,在业务发生又有这样一个需求:先进先出前提,需要按照订单计算每个商品在库时间, ...
- 二型错误和功效(Type II Errors and Test Power)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&am ...
- 如何计算假设检验的功效(power)和效应量(effect size)?
做完一个假设检验之后,如果结果具有统计显著性,那么还需要继续计算其效应量,如果结果不具有统计显著性,并且还需要继续进行决策的话,那么需要计算功效. 功效(power):正确拒绝原假设的概率,记作1-β ...
- R笔记 单样本t检验 功效分析
R data analysis examples 功效分析 power analysis for one-sample t-test单样本t检验 例1.一批电灯泡,标准寿命850小时,标准偏差50,4 ...
- SQL Server统计信息:问题和解决方式
在网上看到一篇介绍使用统计信息出现的问题已经解决方式,感觉写的很全面. 在自己看的过程中顺便做了翻译. 因为本人英文水平有限,可能中间有一些错误. 假设有哪里有问题欢迎大家批评指正.建议英文好的直接看 ...
- Power BI Desktop心得
我是用钉钉邮箱做账号登录Power BI Desktop的.我用Power BI Desktop,做排版和统计. Power BI由Power Query和Power Pivot组成,前者有M语言,后 ...
随机推荐
- PyQt(Python+Qt)学习随笔:Qt Designer中部件的accessibleDescription和accessibleName辅助阅读属性
accessibleDescription和accessibleName属性都是用于残疾人辅助阅读的,这两个属性都有国际化属性(关于国际化请参考<PyQt(Python+Qt)学习随笔:Qt D ...
- BUUOJ WEB(1)
[ACTF2020 新生赛]Include 开启环境之后点击tips 可以在url中看到格式为: ?file=flag.php 加上题目是include,可以猜测是文件包含漏洞 http://a291 ...
- 痞子衡嵌入式:了解i.MXRT1060系列ROM中串行NOR Flash启动初始化流程优化点
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是i.MXRT1060系列ROM中串行NOR Flash启动初始化流程优化点. 前段时间痞子衡写了一篇 <深入i.MXRT1050系 ...
- mybatis逆向工程运行
命令: mvn mybatis-generator:generate 项目结构: generatorConfig.xml内容示例 <?xml version="1.0" en ...
- springcloud gateway解决跨域问题
/** * 跨域允许 */ @Configuration public class CorsConfig { @Bean public WebFilter corsFilter() { return ...
- EditPlus各个版本的注册码,亲测可用
原文链接:https://www.cnblogs.com/shihaiming/p/6422441.html EditPlus4注册码 注册名:host1991 序列号:14F50-CD5C8- ...
- 从用SwiftUI搭建项目说起
前言 后续这个SwiftUI分类的文章全部都是针对SwiftUI的日常学习和理解写的,自己利用Swift写的第二个项目也顺利上线后续的需求也不是特着急,最近正好有空就利用这段时间补一下自己对Swift ...
- 浅析Python项目服务器部署
基础理论 关于Web服务器和应用服务器 基本概念: Web服务器主要功能就是存储.处理.传递网页,客户端和服务器之间基于HTTP协议进行通信. 应用服务器主要是处理动态请求,调用相应的对象完成对请求的 ...
- TCP 百万并发 数据连接测试 python+locust
过程笔记和总结 尝试一.locust 测试百万Tcp并发 另一种方式是使用jmeter 基础环境 服务端 虚拟机:Centos7.2 jdk 1.8 客户端 虚拟机: Centos7.2 python ...
- JavaSE18-字节缓冲流&字符流
1.字节缓冲流 1.1 字节缓冲流构造方法 字节缓冲流介绍 BufferOutputStream:该类实现缓冲输出流. 通过设置这样的输出流,应用程序可以向底层输出流写 入字节,而不必为写入的每个字节 ...