论文阅读 ORBSLAM3
这周末ORB-SLAM3出现了.先看了看论文.IMU部分没细看,后面补上.
Abstract
- 视觉,视觉惯导,多地图SLAM系统
- 支持单目/立体/RGBD相机
- 支持pinhole/鱼眼相机
基于特征/紧耦合/视觉惯导,基于最大后验估计的SLAM系统,即使是在IMU的初始化阶段。
我们的系统更准2-5倍。
多地图系统,基于新的场景识别,提升了recall。
1. Introduction
- short-term data association 前段配
- mid-tem data assocation 后端配
- long-term data association 回环配(MGI配)
我们还提出了multi-map data association。
- ORB-SLAM Atlas: Atlas可以代表一组非连续的地图。可以用于,场景识别,相机重定位,回环检测,和地图融合。
- Abstract camera representation:感觉就是我们的mcamera。
2. Related Work
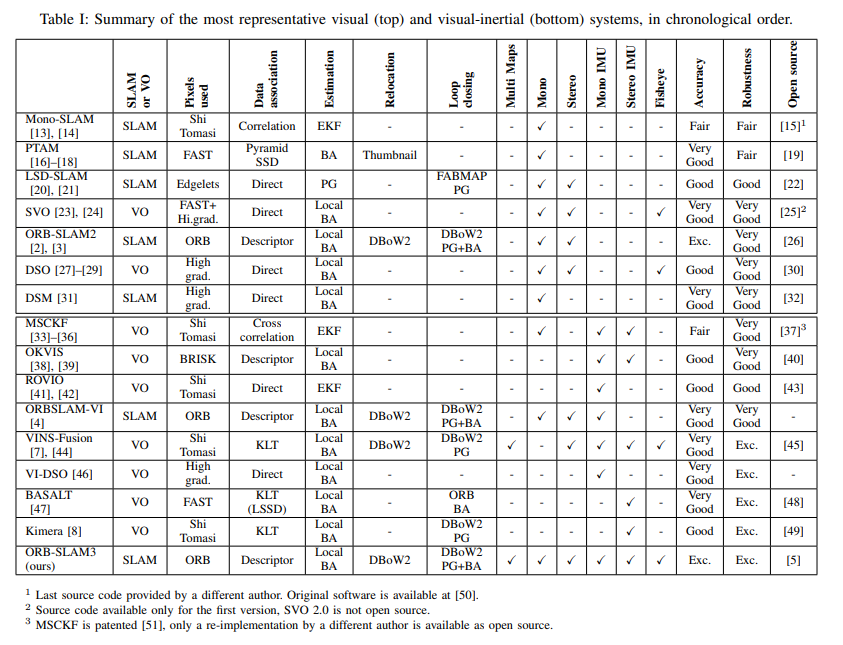
它可承认LK比描述子匹配稍微鲁邦一点。
我们的ORB-SLAM3比VINS-Mono准2.6倍,在单目VIO配置下。
3. System Overview

- Atlas
- Tracking thread
- Local Maping thread 在有IMU的时候,IMU参数是初始化,然后用MAP-estimation refine。
- Loop and map merging thread
4. Camera Model
我们的目标是抽象所有的相机模型,提取所有相机模型相关的特性/函数(投影/反投影/雅克比..)。
A. Relocalization
ORB2中用ePNP,但是需要pinhole相机模型。我们用了MLPnP【76】,和相机模型解耦了。
B. Non-recitified Stereo SLAM
立体图像都转换成pinhole,一样的焦距,共平面,而且在水平极线上。
现在不了,泛化性更强。
- 两个相机之间是SE3的关系(相机外参)
- 可选择:有共视区域
5. Visual-Inertial SLAM
A.基础
状态向量:
\]
整个优化问题:
\]
它认为inertial残差不需要huber norm,因为不存在错配。
B. IMU初始化
有一些系统比如VI-DSO[46]尝试从scratch VI BA来解决,sidestepping(回避)一个初始化阶段。
我们的insights:
- 纯单目的SLAM可以提供很准的初始地图,但是scale未知,解决视觉-only的问题会提升IMU初始化。
- 不要使用隐式的BA表达,显式的优化问题可以使得尺度更快收敛。
- 在IMU初始化阶段忽略传感器不确定性的话会产生很大的不可预测的误差。
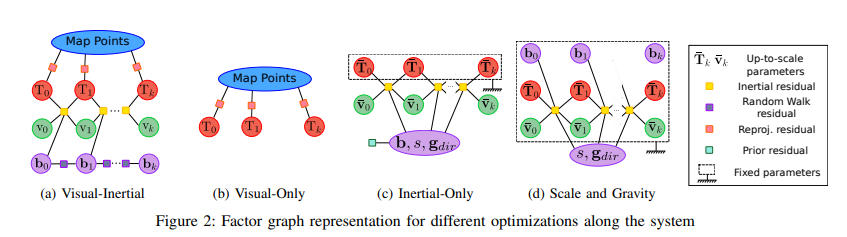
- Vision-only MAP Estimation: 在初始的2秒初始化单目SLAM,以4Hz插KF,这样有10个pose和百余个点。
- Inertial-only MAP Estimation:
inertial变量:
\]
\(s \in R^+\) 是尺度,\(R_{wg}\in SO3\) 是重力方向,用两个角度表示,重力向量在世界系中是\(g=R_{wg}g_I\),\(g_I = (0, 0, G)^T\)。\(\overline{\mathbf{v}}_{0: k} \in \mathbb{R}^{3}\) 是up-to-scale的body速度(从第一到最后的关键帧),从\(\overline{\mathbf{T}}_{0: k}\) 初始估计。
。。。
C. Tracking and Mapping
在一些特殊的case,比如缓慢的移动没有提供好的关于inertial参数的观测性,初始化可能收敛在好的结果。我们提出了一个变种的inertial-only的优化,它包含了所有插入的关键字,但是只优化尺度和重力方向。在这种情况下,biases是常量的假设就没有了,我们会给每个帧估计,然后修正。这个优化很高效,在local mapping线程里每10秒做一次,知道有100多个关键字或者跑了75秒以上。
D. Robustness to tracking loss
- 短时的丢失:用IMU来估计当前状态,然后投影匹配。
- 长时丢失:初始化一个新的visual-inertial map。
6. Map Merging and Loop Closing
A. Place Recognition
为了获得高recall,每个关键字在dbow2 database 查询。为了获得100%的准确,我们走几何验证。
如果 几个候选,我们检查最优比次优。
- 在有IMU的时候,再检查一下重力方向。
B. Visual Map Merging
当场景识别产生了multi-map的数据关联,KF \(K_a\) (当前地图\(M_a\),a表示active)- KF \(K_m\) (Atlas \(M_m\)),相对变换是\(T_{am}\)。
- Welding window assembly
- 地图融合
- Welding bundle adjustment 弄一个local BA
- Pose-graph optimization
C. Visual-Inertial Map Merging
大差不差吧。
D. Loop Closing
7. Experiment Result
- 测了 单目/单目-IMU/立体/立体-IMU
A. single-session SLAM on EuRoC
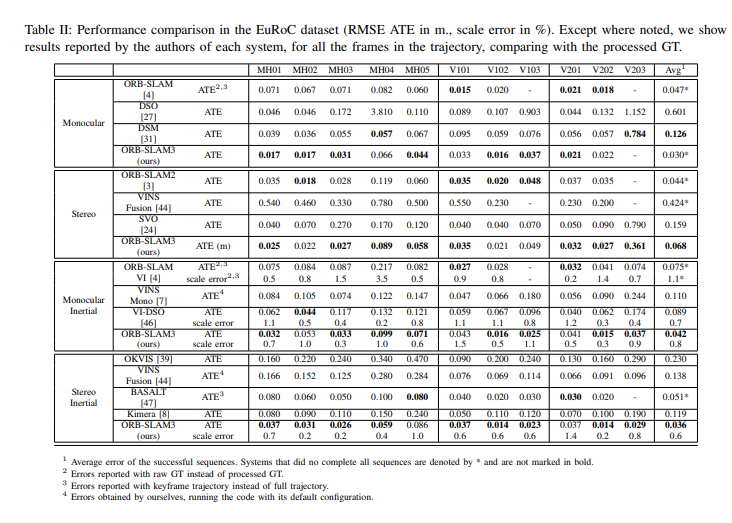
单目/立体:ORB3比2更准是因为回环算法 - 更早的回环,更多的mid-term匹配。有趣的是,DSM获得次优的表现因为使用了mid-term的匹配,即使没有回环。
单目-IMU:ORB3比VI-DSO和VINs-Mono准两倍,说明了mid-term和long-term数据关联的优势。
双目-IMU:ORB3比OKVIS,VINs-Fusion和Kimera好很多。
B. Visual-Inertial SLAM on TUM-VI
在单目提1500个点,双目是一张图1000个点。
。。。
C. Multi-session SLAM
。。。
8. Conclusions
描述子感觉可以解决mid/long term的匹配问题,但是tracking没有LK鲁邦。
一个有趣的线是研发光度技术来解决4种数据关联问题。
其他没啥。
论文阅读 ORBSLAM3的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
随机推荐
- 如何完美获得一个double值的整数部分
如果是java有float类型的向上取整:Math.ceil() //只要有小数都+1向下取整:Math.floor() //不取小数四舍五入:Math.round() //四舍五入 如果是C++:方 ...
- Web开发HTTP协议知识_常用http方法、http状态码等(前端开发和面试必备))
http请求由三部分组成,分别是:请求行.消息报头.请求正文. HTTP(超文本传输协议)是一个基于请求与响应模式的.无状态的.应用层的协议,常基于TCP的连接方式,HTTP1.1版本中给出一种持续连 ...
- (一)ELK 部署
官网地址:https://www.elastic.co/cn/ ELK是Elasticsearch.Logstash.Kibana的简称,这三者是核心套件,但并非全部. Elasticsearch ...
- Spreading the Wealth,思维
题目去洛谷 题意: 很清晰,n个人,每人有一些硬币硬币总数sum≡0(mod n),通过一些互相交换,使硬币数平均(即每人有相同个数的硬币) 分析: 还是有点思维含量的,我们这样想,我们其实就是要确定 ...
- Java面向对象—常见面试题
2. Java 面向对象 2.1. 类和对象 2.1.1. 面向对象和面向过程的区别 面向过程 :面向过程性能比面向对象高. 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量 ...
- Maven 专题(八):配置(一)常用修改配置
修改配置文件 通常我们需要修改解压目录下conf/settings.xml文件,这样可以更好的适合我们的使用. 此处注意:所有的修改一定要在注释标签外面,不然修改无效.Maven很多标签都是给的例子, ...
- 机器学习实战基础(二十七):sklearn中的降维算法PCA和SVD(八)PCA对手写数字数据集的降维
PCA对手写数字数据集的降维 1. 导入需要的模块和库 from sklearn.decomposition import PCA from sklearn.ensemble import Rando ...
- python 生成器(三):生成器基础(三)生成器表达式
生成器表达式可以理解为列表推导的惰性版本:不会迫切地构建列表,而是返回一个生成器,按需惰性生成元素.也就是说,如果列表推导是制造列表的工厂,那么生成器表达式就是制造生成器的工厂. 示例 14-8 先在 ...
- 目录(Python基础)
Python之介绍.基本语法.流程控制 Python之列表.字典.集合 Python之函数.递归.内置函数 Python之迭代器.装饰器.软件开发规范 Python之常用模块学习(一) Python之 ...
- 基于animate.css动画库的全屏滚动小插件,适用于vue.js(移动端、pc)项目
功能简介 基于animate.css动画库的全屏滚动,适用于vue.js(移动端.pc)项目. 安装 npm install vue-animate-fullpage --save 使用 main.j ...