UNION An Unreferenced Metric for Evaluating Open-ended Story Generation精读
UNION An Unreferenced Metric for Evaluating Open-ended Story Generation精读
UNION: 一种评估开放故事生成无参考文本依赖metric模型,这是一篇EMNLP 2020的论文 (Empirical Methods in Natural Language Processing 2020)
1 背景
常见的文本生成评价指标有BLEU 和MoverScore,但BLEU 和MoverScore又一个巨大的缺陷。在NLG任务中,对于相同的输入,NLG模型可以生成各种各样的文本,这些各种各样的输出在字符层面和语义层面上经常和参考文本不一致,但是这些不一致的文本也可以是合理的文本;在另一方面NLG模型生成的一些文本和参考文本字符层面上比较一致,但这些比较一致的文本又不一定是合理文本。

如表中所示, Sample2是NLG生成文本,和Reference在字符层面和语义层面上不一致,但smaple也是一个符合人类逻辑的文本。Sample3也是NLG生成文本,和Reference在字符层面和语义层面较为一致,但不是一个符合人类逻辑的文本。因为句子”Jack started drinking“是在 “The bartender told him it was already time to leave.”的后面,但从逻辑上讲是先有喝酒,才有后面的酒吧员工劝Jack下班了该撤了。
表中B表示BLEU, M表示MoverScore, U表示Union,分数越接近1.0说明文本越接近人类写作文本。 BLEU 和MoverScore对Sample2都是很低的分数,但作者提出的Union网络有最高分数1.0;BLEU 和MoverScore对Sample3都有一定的分数,但作者提出的Union网络有最低分数0.0。显然对于Sampl2和Sample3的在是否符合人类逻辑性的人物上,Union模型是最好的。
2 UNION网络的结构
UNION网络结构如图所示
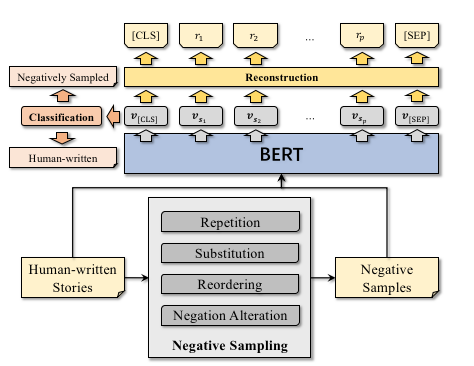
UNION的训练样本正样本是人类写的故事,负样本是通过Repetition(重复), Substitution(替代), Reordering(乱排), Negation Alteration(否定改写)等几种负样本生成方法创造。最后训练输入代入一个基于Bert的二分类模型中对文本进行判断,判断是否为人类写的故事还是负样本。
3 四种NLG错误
为什么作者认为Repetition(重复), Substitution(替代), Reordering(乱排), Negation Alteration(否定改写)可以生成与人类写的故事对应的负样本了?是因为作者统计过NLG生成故事中常见的错误有四种,而且对应上面四种负样本生成策略。
作者分析381篇根据Plan&Write和微调GTP-2生成文本,总结下述NLG错误
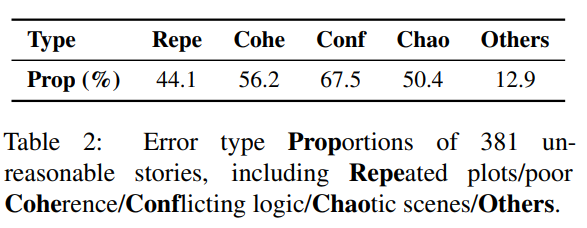
第一种错误是Repeated plots,即相同文本被重复,占总体错误的44.1%;第二种错误是Poor coherence,即生成故事和主干内容无关的关键词和事件,占总体错误的56.2%;第三种错误是Conflicting logic,即生成故事有错误的因果关系和时间顺序,占总体错误的67.5%;第四种错误是Chaotic scenes,即生成故事有很难理解的文本和前文矛盾的错误,占总体错误的50.4%。而且每两种错误类型之间Spearman相关性均小于0.15(p值> 0.01),因此作者采用这四种错误来生成负样本。
3.1 Repetition
Repetition针对Repeated plots错误,有两种具体的负样本产生策略,分别是句子级的重复和词语N-gram级的重复。
句子级的重复是随机选择n个非首句子,然后重复其中一个句子,比如一篇文章句子 有6个,比如一篇文章是[1 2 3 4 5 6],选择3个非首句子是2 3 6,这里假设重复第二句,则第3句和第6句会被第2句内容覆盖,即1 2 3 4 5 6 ==> 1 2 2 4 5 2
词语N-gram级的重复是随机选择n个非首句子, 然后每个句子中挑选一个token的n-gram重复一遍。比如句子Rome was not bulit in one day. 挑选其中一个token为was,选定2-gram重复,即选定了was not bulit重复一遍,则得到负样本为Rome was not bulit was not bulit in one day.
3.2 Substitution
Substitution针对Poor coherence错误,有两种具体的负样本产生策略,分别是句子级的替换和词语级替换。 句子级替换是随机选择n个非开头句,用语料库中其他作文的某一句进行替换。假设一篇作文是I love cat. I love dog. Beacause i love animale. 选择1个非开头句即第2句进行替换,此时从作文语料库其他作文那随便抽了一个句子Rome was not bulit in one day来替换,得到负样本为I love cat. Rome was not bulit in one day. Beacause i love animale. 词语级替换是随机选择n个非开头句,句子中15%关键词替换成反义词,否则替换成同一词性的关键词。其中关键词和反义词会使用一个叫知识图谱ConceptNet,它是一个三元组知识图谱(h, r, t), 第1个元素是头部实体,第2个元素是关系,第3个元素是尾部实体。全体h和t构造的集合就是关键词集合,如果h和t的关系是反义关系,即认为h和t互为反义词。作者采用NLTK来对英文进行词性标注。假设输入的文章是I like playing computer game.则经过本策略,可得到的一个负样本可能为I hate playing computer game.
3.3 Reordering
Reordering针对Conflicting logic错误,即打乱非开头的句子的排序。比如一篇文章是[1 2 3 4 5 6],则需要随机打乱2 3 4 5 6的顺序,即1 2 3 4 5 6 ==>1 2 3 5 6 4
3.4 Negation Alteration
Negation Alteration针对Chaotic scenes错误,即随机选择n个非首句子,否定句变成肯定句,肯定句变否定句。通过动词前加don’t, doesn’t等形式,否定词去掉not实现
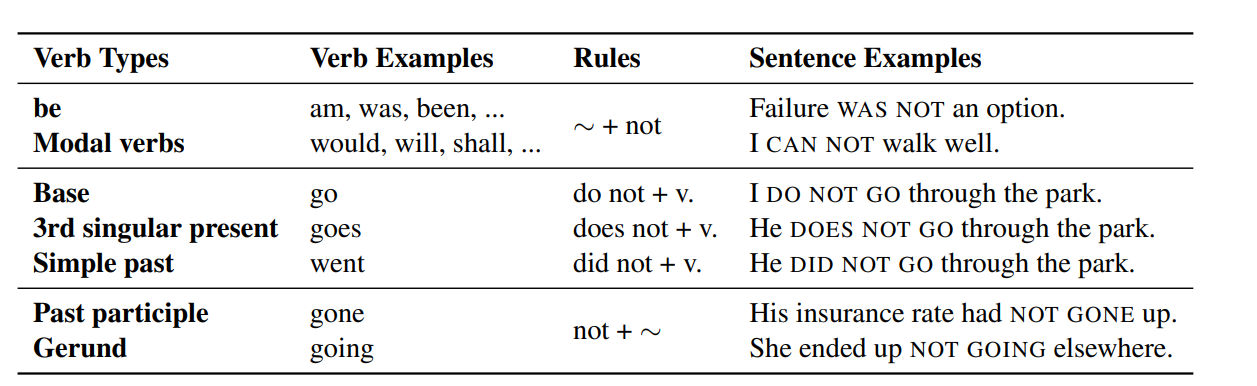
假设输入的文章是Bill love Alice .则经过本策略,可得到的一个负样本为Bill don’t love Alice.
3.5 负样本样例
正样本生成负样本有四种策略,一个正样本可以采用多个策略来生成,比如下面的负样本采用了Repetition、Reordering、Negation Alteration三种策略来生成。

4 网络结构
首先是Bert得到Hidden State,接着作者设计来两个任务来训练完了过,第一个是主任务,即预测一篇文章是否接近人类,预测输出是一个0到1的浮点数,数值越接近1说明文章越接近人类;第二个任务是还原任务,即模型要预测当前词语是否是正样本对应词语。
第一个任务是[CLS]这个token的hidden state进入一个线性层+Sigmoid函数,采用交叉熵损失
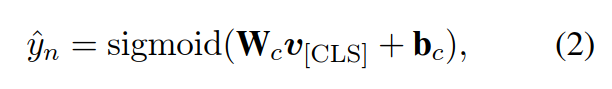
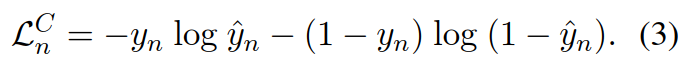
第一个任务每一个real token的hidden state进入一个线性层+Softmax函数,采用广义交叉熵损失,但只针对预测正确的token。
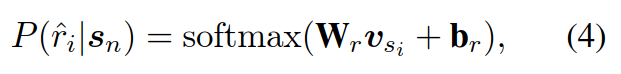
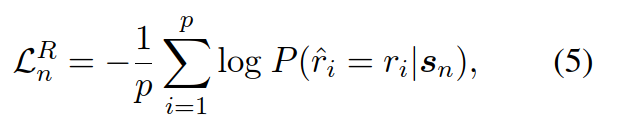
两个任务的损失函数采用权重相加来构造总体损失函数,其中lambda是一个可设置的超参数,作者在论文中取0.1
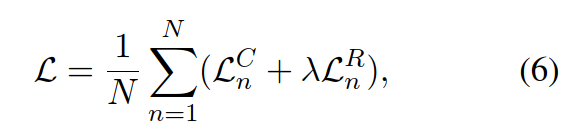
5 BaseLine
作者采用了三类BaseLine,一类是基于参考文章的Referenced metrics,一类是不基于参考文章的Unreferenced metrics,还有一类是混合度量Hybrid metrics.
Referenced metrics采用的模型有基于n-gram重合度的BLEU,和基于embeding空间中推土机距离计算和Ref的相似程度MoverScore

Unreferenced metrics采用的模型有困惑度Perplexity,和基于Bert的度量,容易对特定数据集overfit的DisScore
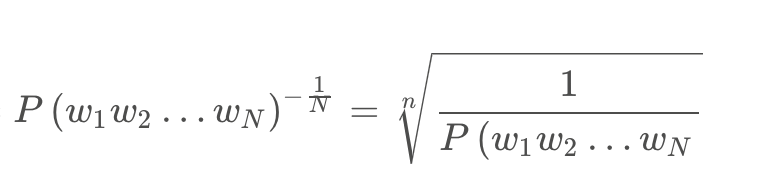
Hybrid metrics采用的BLEURT和RUBER-BERT,其中RUBER-BERT有无参考的RUBER-BERT和有参考的RUBER-BERT

BLEURT
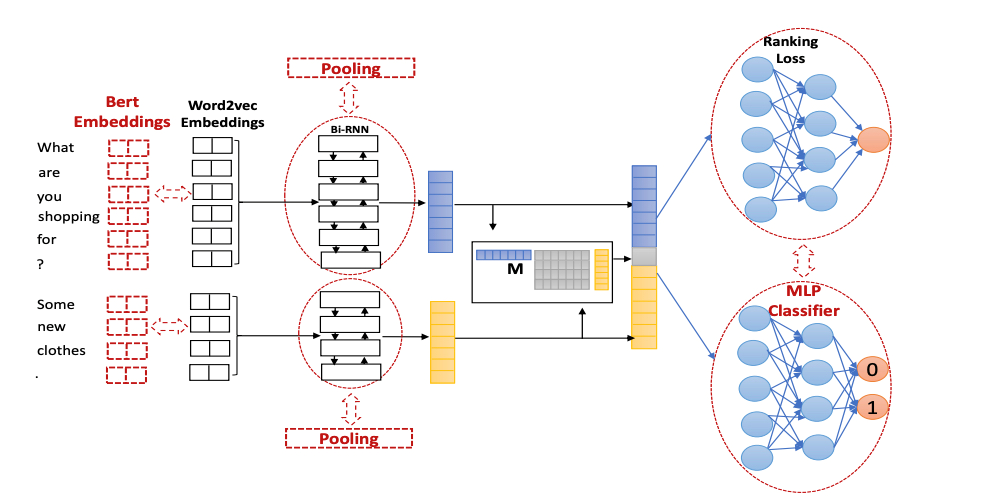
无参考的RUBER-BERT
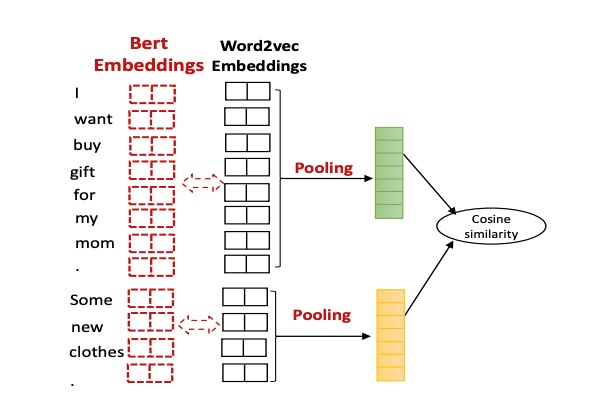
有参考的RUBER-BERT
6 数据集
作者采用了2个数据集,ROC和WP。
ROC 是一个98,161五句文本构成的故事数据集, 平均每个故事有49.4词, 使用[MALE] [FEMALE] [NEUTRAL]对名字进行mask处理。 WP 是一个有303,358篇文章的故事数据集, 平均每个故事有734.5词语, 因为这个数据集中故事太长作者对每个故事截断取200词语.
作者采用90% ,5%,5%的比例划分训练集、验证集和测试集。
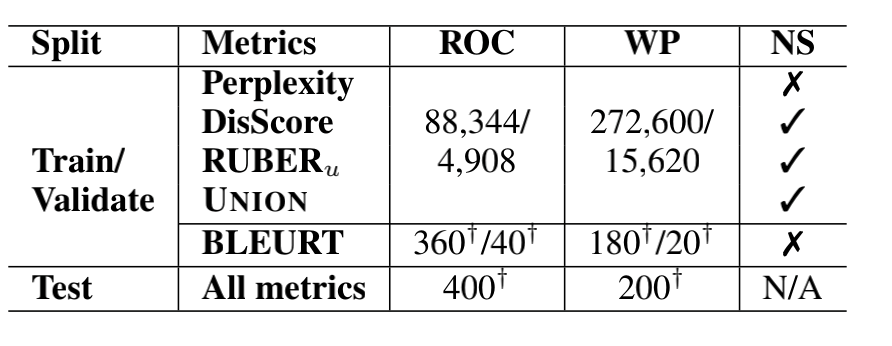
但作者针对BLEURT这个metric模型,采用seq2seq ,plan&write, 微调 GPT-2 ,基于知识库 GPT-2来创造负样本, 然后进行人工标注。所有模型使用同一个测试集,测试集是专门在外包平台让人标注的数据。
7. UNION效果
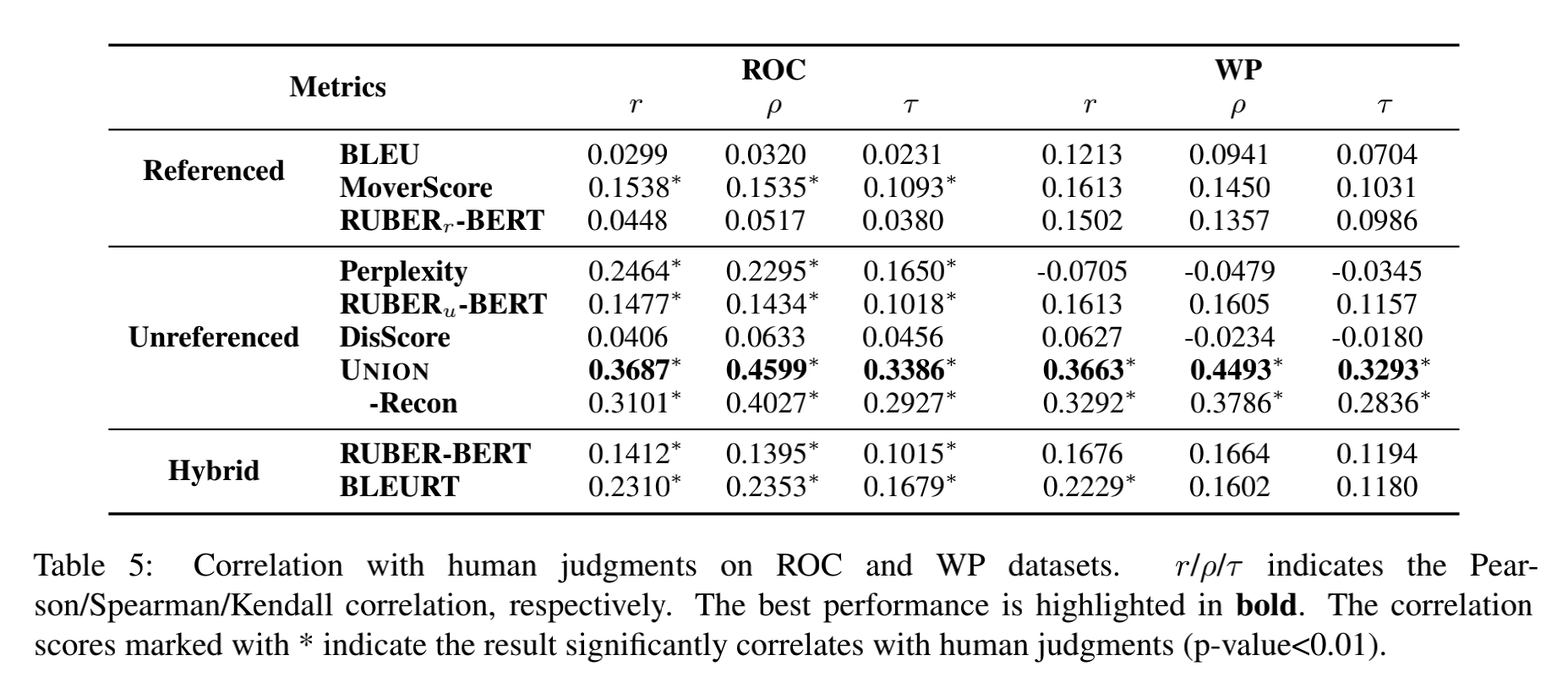
表中的相关系数计算的是模型标注分数和人类标注分数,显然这个相关系数越来高说明模型越接近人类。从上表中明显看出,UNION模型三个相关系数指标均远远高于其他度量模型,从而证明了UNION模型的优秀。
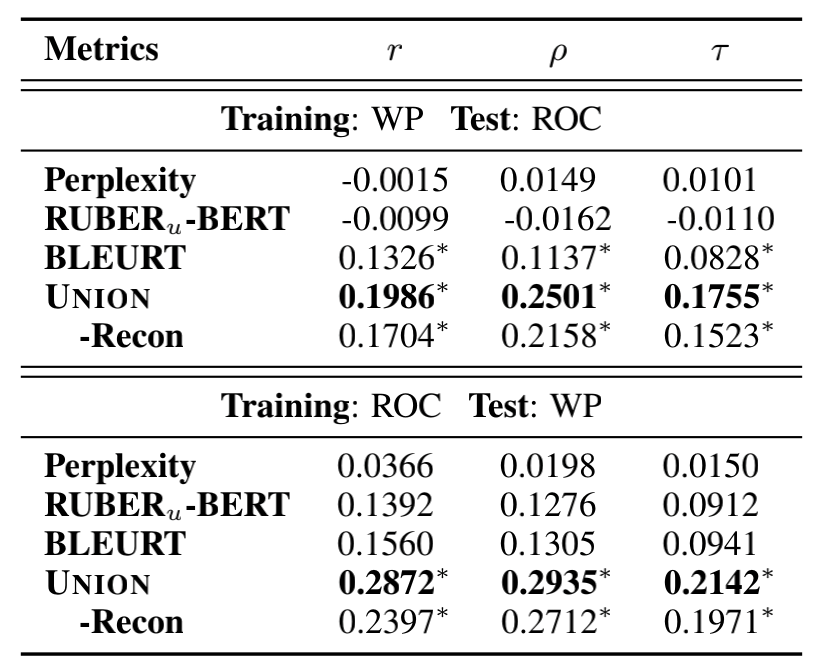
上表是验证UNION鲁棒性,看看UNION对于Dataset Drift是否也有良好的表现,实验证明在鲁棒性上UNION也是优于其他度量模型的。
UNION An Unreferenced Metric for Evaluating Open-ended Story Generation精读的更多相关文章
- {ICIP2014}{收录论文列表}
This article come from HEREARS-L1: Learning Tuesday 10:30–12:30; Oral Session; Room: Leonard de Vinc ...
- Networked Graphics: Building Networked Games and Virtual Environments (Anthony Steed / Manuel Fradinho Oliveira 著)
PART I GROUNDWORK CHAPTER 1 Introduction CHAPTER 2 One on One (101) CHAPTER 3 Overview of the Intern ...
- 学习笔记之Machine Learning Crash Course | Google Developers
Machine Learning Crash Course | Google Developers https://developers.google.com/machine-learning/c ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression 2019-05-20 19:3 ...
- 『计算机视觉』Generalized Intersection over Union: A Metric and A Loss for Bounding BoxRegression
论文地址:Generalized Intersection over Union 一.相关工作 目标检测精度标准 度量检测优劣基本基于 IOU,mAP 是典型的基于 IOU 的标准,但是 mAP 仅有 ...
- union 类型(即sum types)在golang语言中的实现
http://www.jerf.org/iri/post/2917 Sum Types in Go posted Jun 02, 2013 in Programming, Golang, Haskel ...
- SQL Server-聚焦UNIOL ALL/UNION查询(二十三)
前言 本节我们来看看有关查询中UNION和UNION ALL的问题,简短的内容,深入的理解,Always to review the basics. 初探UNION和UNION ALL 首先我们过一遍 ...
- SQL 提示介绍 hash/merge/concat union
查询提示一直是个很有争议的东西,因为他影响了sql server 自己选择执行计划.很多人在问是否应该使用查询提示的时候一般会被告知慎用或不要使用...但是个人认为善用提示在不修改语句的条件下,是常用 ...
随机推荐
- [Windows] 在 Microsoft Docs 网站中挖掘 MVVM 的各种学习资源
最近写了一些 MVVM 框架的文章,翻了一些 Microsoft Docs 的文档,顺便就对 MVVM 本身来了兴致,想看看更多当年相关的文档.在 MVVM 出现后十多年,我在不同的场合见到过多种 M ...
- JDBC(一)—— JDBC概述
Jdbc概述 Java DataBase connectivity(Java语言连接数据库) Jdbc本质是什么? 是Sun公司制定的一套接口,java.sql.* 接口都有调用者和实现者 面向接口调 ...
- 题解-FJOI2018 领导集团问题
题面 FJOI2018 领导集团问题 给一棵树 \(T(|T|=n)\),每个点有个权值 \(w_i\),从中选出一个子点集 \(P=\{x\in {\rm node}|x\in T\}\),使得 \ ...
- 【学习笔记】浅析平衡树套线段树 & 带插入区间K小值
常见的树套树 一般来说,在嵌套数据结构中,线段树多被作为外层结构使用. 但线段树毕竟是 静态 的结构,导致了一些不便. 下面是一个难以维护的例子: 带插入区间 \(k\) 小值问题 来源:Luogu ...
- Linux下基于.NET5开发CAX应用
<<.NET5下的三维应用程序开发>>一文中介绍了如何在.NET5下使用AnyCAD开发应用程序.相比.NET4.x,.NET5一大进步便是可以跨平台,即可以在Linux.Ma ...
- Android全面解析之Activity生命周期
前言 很高兴遇见你~ 欢迎阅读我的文章. 关于Activity生命周期的文章,网络上真的很多,有很多的博客也都讲得相当不错,可见Activity的重要性是非常高的.事实上,我猜测每个android开发 ...
- emca配置EM
EM DC(Enterprise Manager Database Control)是 web 界面的数据库管理工具, 可用于配置 EM DC环境的工具包括: Oracle Universal In ...
- SpringBoot异步调用--@Async详解
1. 概述 在日常开发中,为了提高主线程的效率,往往需要采用异步调用处理,例如系统日志等.在实际业务场景中,可以使用消息中间件如RabbitMQ.RocketMQ.Kafka等来解决.假如对高可用 ...
- 微信小程序 rich-text 修改照片
<view> <rich-text nodes="{{delcon}}" /> </view> data: { delcon:'' }, var ...
- jmeter处理加密接口
jmeter处理加密接口 普及知识点: 我们常见的加密方式有:(RSA .AES.MD5.secret) 如下四种情况: 1.请求加密.响应加密 2.请求不加密.响应加密 4.请求加密.响应不加密 5 ...