Hadoop2.6.0安装—单机/伪分布
目录
作者: vincent_zh
时间:2016-10-16
出处:http://www.cnblogs.com/vincentzh/p/5967274.html
声明:本文以学习、研究和分享为主,如需转载,标明作者和出处,非商业用途!
环境准备
此处准备的环境是Virtual Box虚拟机下的Ubuntu14.04 64位系统,Hadoop版本为Hadoop2.6.0。装好Hadoop运行的基础Linux环境后,还需要做以下准备:
- 创建hadoop用户;
- 更新apt;
- 配置SSH免密登陆;
- 安装配置Java环境。
创建hadoop用户
如果安装系统时配置的并非是“hadoop”用户,就需要新增加一个“hadoop”用户。
$ sudo useradd -m hadoop -s /bin/bash
该命令创建新的“hadoop”用户,并指定 /bin/bash 作为其shell。
如需更改hadoop用户密码,可通过如下命令进行:
$ sudo passwd hadoop
同样,为避免后期安装过程中的用户权限问题,可直接给“hadoop”用户添加上管理员权限:
$ sudo adduser hadoop sudo
之后,需切换到hadoop用户下进行下面操作。
更新apt
切换到hadoop用户之后,需要先更新一下apt,后续需要通过apt安装其他软件,直接在命令行安装会方便很多,如果没有更新,一些软件可能安装不了。可参考以下命令进行更新:
$ sudo apt-get update
Linux 的编辑工具,当然非 vim 莫属了,先装上 vim 后期改参数配置文件时用的到。
$ sudo apt-get install vim
遇到命令行的 [ yes/no] 或者 [Y/N] 选项,直接yes进行安装。
配置SSH免密登陆
单点/集群都需要安装SSH。一方面是远程登陆,可一再本机通过SSH直接连接虚拟机的系统,这样也便于后期在Windows环境下使用 Eclipse 进行配置开发 MapReduce 程序;另一方面,在配置Hadoop集群时,集群工作过程中主机和从机、从机和从机之间都通过SSH进行授权登陆工作通信。Ubuntu系统默认已经安装了SSH Client,需要额外安装SSH Server。
$ sudo apt-get install openssh-server
首次登陆SSH会有首次登陆提示,键入yes,按提示输入hadoop用户密码即可登陆。

配置免密登陆。一方面,我们通过ssh登陆时比较方便,不需重新输入密码;另一方面,在集群方式工作时,主机与从机通信过程或从机与从机之间进行文件备份时是需要越过密码验证这一环节的,所以需要提前生成公钥,在集群工作时,可以直接自动登陆。
$ exit #推出刚刚登陆的 localhost
$ cd ~/.ssh #若无此目录,请先进行一次ssh 登陆
$ ssh-keygen -t rsa #会有很多提示,全部回车即可
$ cat ./id_rsa.pub >> ./authorized_keys #将公钥文件加入授权
再次通过 ssh 登陆就不需要输入密码了。
安装配置Java环境
Java环境,Oracle JDK 和 OpenJDK都可以,此处直接通过命令安装OpenJDK1.7(其中包含 jre 和 jdk):
$ sudo apt-get install openjdk--jre openjdk--jdk
配置环境变量:
安装好JDK后,需要配置Java环境变量,通过以下命令寻找Java安装路径:
$ dpkg -L openjdk--jdk | grep '/bin/javac'
该命令会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是JDK的安装路径了。

在.bashrc文件中配置环境变量:
$ vi ~/.bashrc
需要在.bashrc文件中添加如下环境变量:

生效并检验环境变量配置是否正确:
$ source ./.bashrc #生效环境变量
$ echo $JAVA_HOME #查看环境变量
$ java -version
$ $JAVA_HOME/bin/java -version #验证与java -version 输出一致
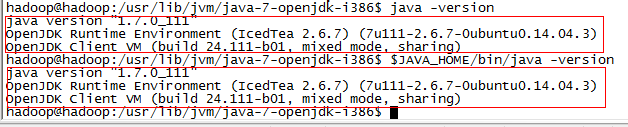
OK,Java环境安装配置完成。
安装Hadoop
通过http://mirrors.cnnic.cn/apache/hadoop/common/ 可下载Hadoop稳定版 hadoop-2.x.y.tar.gz 文件都是编译好的,建议同时下载hadoop-2.x.y.tar.gz.mds,此mds文件是为了检验在下载和移动文件过程中文件的完整性。
通过验证文件的md5值去检验文件的完整性:
$ cat ./hadoop-2.6..tar.gz.mds | grep 'MD5'
$ md5sum ./hadoop-2.6..tar.gz | tr 'a-z' 'A-Z'

文件验证无误,将文件解压到安装目录:
$ cd /usr/lcoal #切换到压缩文件所在目录
$ sudo tar -zxf ./hadoop-2.6..tar.gz ./ #解压文件
$ sudo mv ./hadoop-2.6. ./hadoop #将文件名改为较容易辨认的
$ chown -R hadoop ./hadoop #修改文件权限
在.bashrc文件中配置hadoop相关环境变量:
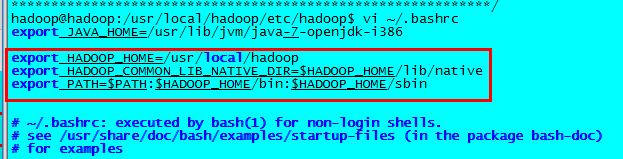
生效环境变量,并验证Hadoop安装成功。
$ source ~/.bashrc
$ hadoop version
Hadoop单机/伪分布配置
单机Hadoop
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
注:单机、伪分布、集群的区别:
单机:故名思意,Hadoop运行再单台服务器上,并且此时的Hadoop读取的是本地的文件系统,并没有使用自己的HDFS。
伪分布:单机版集群,单台服务器既是NameNode,也是DataNode,并且也只有这一个DataNode,文件是从HDFS读取。
集群:单机和伪分布说了集群就简单了。一般单独分配一台服务器作为NameNode,并且NameNode一般不会同时配置为DataNode,DataNode一般在其他服务器上,另外对大型集群,为体现Hadoop集群的高可用性,也会单独设置一台服务器作为集群的SecondaryNameNode,也就是NameNode的备份,主要用于NameNode失效时的快速恢复。
伪分布Hadoop
Hadoop 伪分布式的方式是在单节点上运行的,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件,Hadoop 进程以分离的 Java 进程来运行。
Hadoop 的配置文件位于 $HADOOP_HOME/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。另外如果要启动YARN,需要再修改 mapred-site.xml 和 yarn-site.xml 两个配置文件。
通过编辑器或 vim 对xml配置文件进行修改。
修改 core-site.xml 配置文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改 hdfs-site.xml 配置文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改 mapred-site.xml 配置文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改 yarn-site.xml 配置文件:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动Hadoop
配置完成,首次启动Hadoop时需要对NameNode格式化:
$ hdfs namenode -format
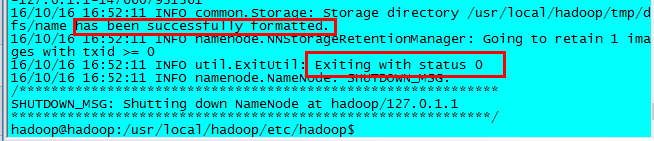
有这两个标志,则表示配置没问题,namenode已经格式化,可以启动Hadoop了。如果格式化错误,需要检查配置文件配置是否正确,最常见的问题就是配置文件里的拼写错误。
启动守护进程:
$ start-dfs.sh #启动hdfs,含NameNode、DataNode、SecondaryNameNode守护进程
$ start-yarn.sh #启动yarn,含ResourceManager、NodeManager
$ mr-jobhistory-daemon.sh start historyserver #开启历史服务器,才能在Web中查看任务运行情况
守护进程的启动情况可通过 jps 命令查看,查看所有的守护进程是否都正常启动。如果有未启动的守护进程,需要去 $HADOOP_HOME/logs 目录查看对应的守护进程启动的日志查找原因。
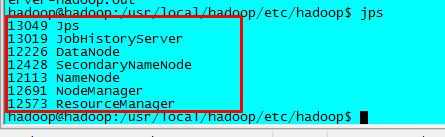
成功启动所有守护进程之后,通过Web界面 http://server_ip/50070 查看NameNode 和 DataNode 的信息,还可以在线查看HDFS文件。
YRAN启动之后(即 ResourceManager 和 NodeManager),也可以通过 http://server_ip/8088 查看管理资源调度,和查看Job的执行情况。
停止Hadoop
$ stop-dfs.sh
$ stop-yarn.shResourceManager、NodeManager
$ mr-jobhistory-daemon.sh stop historyserver
Note:Hadoop常用的服务器管理命令脚本都可以在 $HADOOP_HOME/bin 和 $HADOOP_HOME/sbin 目录中找到。
集群部署详见:http://www.cnblogs.com/vincentzh/p/6034187.html
Hadoop2.6.0安装—单机/伪分布的更多相关文章
- 在Ubuntu14.10中部署Hadoop2.6.0单节点伪分布集群
1. 环境信息如下: ubuntu:14.10 jdk:openjdk-1.7.0 hadoop:2.6.0 2. 下载hadoop2.6.0, http://apache.fayea.com/had ...
- Hadoop2.6.0安装 — 集群
文 / vincentzh 原文连接:http://www.cnblogs.com/vincentzh/p/6034187.html 这里写点 Hadoop2.6.0集群的安装和简单配置,一方面是为自 ...
- (一)Hadoop1.2.1安装——单节点方式和单机伪分布方式
Hadoop1.2.1安装——单节点方式和单机伪分布方式 一. 需求部分 在Linux上安装Hadoop之前,需要先安装两个程序: 1)JDK 1.6(或更高版本).Hadoop是用Java编写的 ...
- Greenplum/Deepgreen(单机/伪分布)安装文档
Greenplum/Deepgreen数据库安装(单机/伪分布) 首先去官网下载centos7:https://www.centos.org/download/,选择其中一个镜像下载即可,网上随意下载 ...
- Linux Hadoop2.7.3 安装(单机模式) 一
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 java环境安装 http://www.cnblogs.com/zeze/p/590 ...
- Linux Hadoop2.7.3 安装(单机模式) 二
Linux Hadoop2.7.3 安装(单机模式) 一 Linux Hadoop2.7.3 安装(单机模式) 二 YARN是Hadoop 2.0中的资源管理系统,它的基本设计思想是将MRv1中的Jo ...
- Hadoop-2.4.0安装和wordcount执行验证
Hadoop-2.4.0安装和wordcount执行验证 下面描写叙述了64位centos6.5机器下,安装32位hadoop-2.4.0,并通过执行 系统自带的WordCount样例来验证服务正确性 ...
- 一、Ubuntu14.04下安装Hadoop2.4.0 (单机模式)
一.在Ubuntu下创建hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增加hadoop用户,后续在涉及到hadoop操作时,我们使用该用户. 1.创建hadoop用户组 2.创 ...
- Ubuntu 14.04下安装Hadoop2.4.0 (单机模式)
转自 http://www.linuxidc.com/Linux/2015-01/112370.htm 一.在Ubuntu下创建Hadoop组和hadoop用户 增加hadoop用户组,同时在该组里增 ...
随机推荐
- iOS----支付(微信支付、支付宝支付、银联支付控件集成支付)(转)
资料 支付宝 //文档idk都包含了安卓.iOS版 银 联 银联官网资料 Demo Demo给了一个订单号,做测试使用,若出现支付失败什么的,可能是已经被别人给支付了,或者是服务器订单过期了 ~ 一. ...
- UIwebView 和 H5交互详情
背景: 最近公司准备上一个只有原生登录界面 + H5网页 ,并且支持ios7.0 以上系统的混合app;这可把我难住了,原生的UI界面我可以正写反写各种style把界面搭建起来.而要这个app的难点在 ...
- Laravel 5.3 auth中间件底层实现详解
1. 注册认证中间件, 在文件 app/Http/Kernel.php 内完成: protected $routeMiddleware = [ 'auth' => \Illuminate\Aut ...
- Transaction Replication6:Transaction cleanup
distribution中暂存的Transactions和Commands必须及时cleanup,否则,distribution size会一直增长,最终导致数据更新耗时增加,影响replicatio ...
- Android获取可存储文件所有路径
引言:大家在做app开发的时候,基本都会保存文件到手机,android存储文件的地方有很多,不像ios一样,只能把文件存储到当前app目录下,并且android手机由于厂家定制了rom,sdcard的 ...
- tn文本分析语言(二) 基本语法
tn是desert和tan共同开发的一种用于匹配,转写和抽取文本的语言.解释器使用Python实现,代码不超过1000行. 本文主要介绍tn的基本语法.高级内容可以参考其他篇章.使用这样的语法,是为了 ...
- cf201.div1 Number Transformation II 【贪心】
1 题目描述: 被给一系列的正整数x1,x2,x3...xn和两个非负整数a和b,通过下面两步操作将a转化为b: 1.对当前的a减1. 2.对当前a减去a % xi (i=1,2...n). 计算a转 ...
- Microsoft Build 2015 汇总
简要概括(GitHub 完成约 45%): Visual Studio Code Preview(意料之外) Visual Studio 2015 RC Visual Studio 2013 Upda ...
- Hive启动报错: Found class jline.Terminal, but interface was expected
报错: [ERROR] Terminal initialization failed; falling back to unsupported java.lang.IncompatibleClassC ...
- 详解用Navicat工具将Excel中的数据导入Mysql中
第一步:首先需要准备好有数据的excel: 第二步:选择"文件"->"另存为",保存为"CSV(逗号分隔)(*.csv)",将exce ...