第五章、web服务器
一、web服务器
Web服务器就是整个万维网的骨干,广义上来说Web服务器既可以用来表示Web服务器的软件,也可以用来表示提供Web页面的特定设备和计算机。我们在网络上获取的所以资源,都需要有服务器来保存和提供。另外需要说明的是本篇中对于Web服务器的配置说明是基于Apache Web服务器的。
1 Web服务器的类型
Web 服务器有着不同的风格、形状和尺寸。有普通的 10 行 Perl 脚本的 Web 服务器、50MB 的安全商用引擎以及极小的卡上服务器。但不管功能有何差异,所有的 Web 服务器都能够接收请求资源的 HTTP 请求,将内容回送给客户端。
Web服务器逻辑实现了HTTP协议,负责管理其提供的资源和提供对服务器的配置、控制等功能。Web服务器会和操作系统协作共同实现TCP连接。底层的操作系统会提供TCP/IP网络支持,并向上提供TCP的相关接口给Web服务器进行调用。
要实现一个Web服务器,我们可以在标准的计算机上安装Web服务器软件,或者直接购买一台已经安装和配置了Web服务器软件的计算机。除了这些外,现在还可以在一些嵌入式设备中嵌入Web服务器。下面对着三种实现方式进行简单的说明:
- 通用软件Web服务器
通用软件 Web 服务器都运行在标准的、有网络功能的计算机系统上。可供选择的也非常多,免费的如Apache基金提供的软件,付费的如微软的Web服务器。目前来看,免费的Web服务器软件已经相当不错了,而且使用和配置也很方便,很多中小型公司都会使用免费开源的Web服务器软件。比如现在非常流行的Tomcat,如果你想搭建一个Web服务器进程试用、调试等,这个是非常不错的选择。
- Web服务器设备
Web 服务器设备(Web server appliance)是预先打包好的软硬件解决方案。厂商会在他们选择的计算机平台上预先安装好软件服务器,并将软件配置好。这个接触不多,有兴趣的可以自行了解一下。
- 嵌入式Web服务器
嵌入式服务器(embeded server)是要嵌入到消费类产品(比如打印机或家用设备)中去的小型 Web 服务器。嵌入式 Web 服务器允许用户通过便捷的 Web 浏览器接口来管理其消费者设备。
2 Web服务器需要处理的事情
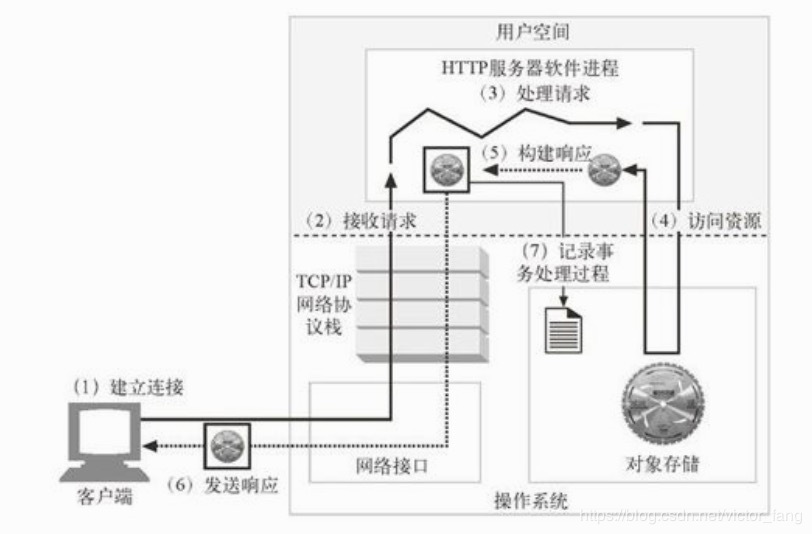
从图中我们可以看到,Web服务器主要需要处理以下几项事情:
- 建立连接——接受客户端的连接请求
- 接受请求——从连接中读取一条HTTP请求报文
- 处理请求——根据HTTP规范解析请求后,根据请求做出动作
- 访问资源——解析完请求报文后,根据报文访问指定的资源
- 构建响应——处理好资源后,根据HTTP规范构建响应
- 发送响应——将构建好的响应发送给客户端
- 记录日志——根据需要,将该次处理有关内容记录到日志文件中
2.1 接受客户端连接
一般客户端想要发起一个请求,除非已经建立持久连接,否则就会新建立一个到服务器的连接。服务器这端就需要接受客户端连接。该过程中,主要处理一下几件事情:
a). 处理新连接
当新连接请求到来的时候,服务器一般会先从TCP连接中解析出客户端IP地址。需要判断是否接受该条连接(如:判断客户端IP地址是否是认证过的),如果不接受,可以拒绝或者关闭连接。如果接受,一般就会将连接添加到连接列表,并做好该连接上数据的监听,做好传输的准备。
b). 客户端主机名识别
服务器解析数客户端IP地址后,可以通过“反向DNS”对IP地址进行解析,得到客户端的主机名。但是该过程是一个比较耗时的操作,所以如果不需要此项内容,一般会将主机名解析禁止掉,以便提高服务器处理速度。比如:可以用配置指令 HostnameLookups 来控制 Apache 的主机查找功能。
c). 通过ident确定客户端用户
有些 Web 服务器还支持 IETF 的 ident 协议。服务器可以通过 ident 协议找到发起 HTTP 连接的用户名。这些信息对 Web 服务器的日志记录特别有用——流行的通用日志格式(Common Log Format)的第二个字段中就包含了每条 HTTP 请求的 ident 用户名。
如果客户端支持ident协议,通常会在113端口上做ident监听。下图展示了ident协议是如何工作的。

虽然ident协议可以帮助我们获取客户端更多信息,但是实际操作中,一般ident都不能很好的提供服务,因为:一般客户端并不支持ident协议,很多防火墙不允许ident流量流入,同时该协议不是一个安全的协议,很容易被人伪造,同时这个也涉及到个人隐私问题。
在Apache服务器中,可以通过IdentityCheck on 指令告知 Apache Web 服务器使用 ident 查找功能。
2.2 接收请求报文
上一步的连接完成,做好连接上的数据监听工作后,待客户端将HTTP报文发送过来,服务器这边需要接收该报文;
这里接收报文的时候,效率也是很重要的,高性能的 Web 服务器能够同时支持数千条连接。不同的 Web 服务器结构会以不同的方式为请求服务(Web的访问响应模型,或者也叫连接的输入/输出处理结构)。目前来说主要有如下四种方式:
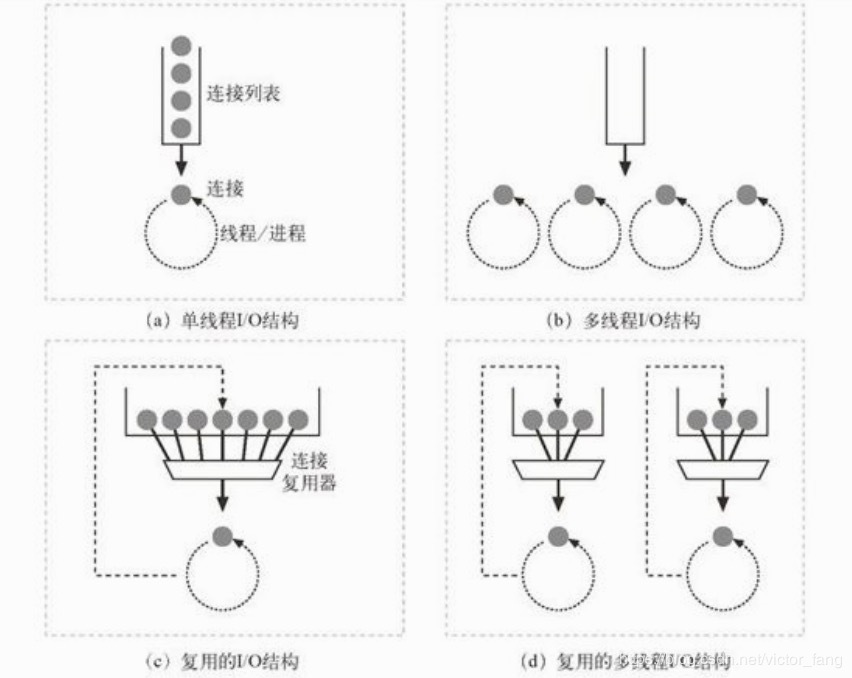
在介绍的时候,先做个说明,上图中都是以线程为单位进行说明的,个人理解此处应该以进程为单位,所以下面的描述中以进程为单位进行说明。
- 单进程I/O结构(图a)
- Web服务器使用一个进程串行的方式进行请求处理,一次只接收一个请求,这种方式几乎已经被淘汰,效率太低。
- 多进程I/O结构(图b)
- Web服务器启用多个进程对请求进行处理,同一时间,每个进程都能单独处理一个请求。但是一般服务器会对进程做一个最大数量的限制,以防止资源耗尽的情况。
- 复用I/O结构(图c)
- 原书对此处表述个人不是非常理解,目前个人理解的是利用“连接池”技术。在一个进程中,开启多个线程,每个线程处理一个请求,当一个线程的请求处理完成后,不立即销毁,而是放回到“连接池”中,等待下一个需要处理的请求。所以在实现方式上利用多线程和“线程池”技术。
- 复用的多进程I/O结构(图d)
- 这个其实也就是将多进程,多线程(线程池)技术综合使用,达到有个多进程对请求进行处理,同时每个进程里面又维护了一个“线程池”真正对请求进行处理。
2.3 处理请求
这里将原书中的报文解析放在该阶段了,所以此阶段的内容就是对报文按照HTTP规范进行解析,一般都会根据报文的三部分请求行、请求头(本书中所说的首部)、请求体进行封装处理,以便后续可以很快速的访问所需内容。解析完报文后,就会根据其内容,产生不同的动作,
2.4 对资源进行映射访问
Web服务器本质上就是个资源服务器,主要功能就是对外提供资源,在 Web 服务器将内容传送给客户端之前,要将请求报文中的 URI 映射为 Web 服务 器上适当的内容或内容生成器。
2.4.1 虚拟托管的docroot
虚拟托管的web服务器会在同一台web服务器上提供多个web站点,每个站点在服务器上都有自己独立的文档根目录。虚拟托管web服务器会根据URI或Host首部的IP地址或主机名来识别要使用的正确文档根目录。
Web服务器有多种资源映射类型,最简单的便是直接将URI中的路径映射为Web服务器文件系统中的路径。这种映射方式,通常会有一个专门用于存放资源的文件夹。这个文件夹通常被称为docroot(或者 document root)。在映射的时候,解析出URI中的路劲,将其作为相对路径附在该docroot目录路径后面。如:

上图中请求的URI中的路径为/specials/saw-blade.gif,该Web服务器的docroot目录为路径为/usr/local/httpd/files。通过映射后,最终Web服务器就会到/usr/local/httpd/files/specials/saw-blade.gif路径下去获取资源。
通常我们实际操作中还会遇到一个Web服务器有多个Web站点的情况。这个时候如果我们URI中的路径相同,如都为:/index.html,这个时候Web服务器会根据HOST或者URI中的IP来进行区别,找到不同的docroot,最终将请求资源映射到正确的路径。
docroot的配置,每个Web服务器都有自己的一套规则,这里以Apache为例,如下:
<VirtualHost www.joes-hardware.com>
ServerName www.joes-hardware.com
DocumentRoot /docs/joe
TransferLog /logs/joe.access_log
ErrorLog /logs/joe.error_log
</VirtualHost>
<VirtualHost www.marys-antiques.com>
ServerName www.marys-antiques.com
DocumentRoot /docs/mary
TransferLog /logs/mary.access_log
ErrorLog /logs/mary.error_log
</VirtualHost>
上面就在同一个Web服务器张部署了两个Web站点,并且分别设置了不同的docroot路径。
2.4.2 目录列表
Web服务器除了可以接收指向具体资源的URL请求外,还能处理指向目录的URL的请求。当Web服务器收到一个指向目录的URL请求后,一般采取如下几种方式进行处理:
- 直接返回一个错误信息
- 在当前目录下找指定的索引文件
- 扫描目录,寻找一个包含该目录的内容的HTML文件
- 大多数Web服务器默认处理方式,会在在当前目录下找一个index.html或者index.htm的文件,如果找不到会返回一个404错误。当然,大部分Web服务器都是支持我们自己对目录请求的默认寻找文件进行配置的,如Apache的DirectoryIndex指令:
- DirectoryIndex index.html index.htm home.html home.htm index.cgi
- 有了该条配置,服务器就会默认会去依次寻找上述列出的所有文件,直到找到一个并返回内容,如果搜索完毕也找不到,也会返回一个错误。
2.4.3 动态资源的映射
上面介绍的映射都是静态映射,即将URL路径映射到指定的静态文件。除了静态映射,Web服务器还支持动态映射——将URL路径映射到按需生成内容的程序上。下图展示了一个Web服务器既提供静态资源,也提供动态资源:
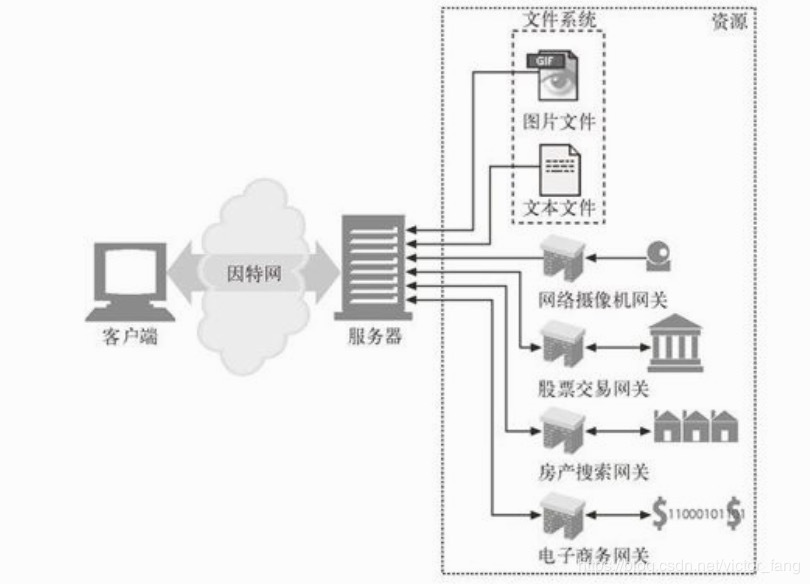
目前Web服务器大多数时候都是在提供动态资源,常用的动态动态内容支持机制有微软的Active Server Page和Java Servlet。
2.4.4 服务器端包含项
此处个人理解通常就是指我们的模板文件,比如现在比较流行的FeeMarker,Thymeleaf。都可以先提供一个HTML模板文件,然后根据动态查询到的内容,进行替换或者处理后,再将内容返回给客户端。
2.4.5 访问控制
在对资源映射的时候,还可以做访问控制。如:指定某些资源是需要登录用户才能访问,某些资源是需要付费用户才能访问等。
2.5 构建响应
一旦Web服务器已经找到需要的资源,就需要使用该资源构建响应报文(响应行,响应头,相应体)。通常来说,响应报文应该含有一下几项:
- Content-type首部——用于描述相应体内容的MIME类型
- Content-length首部——用于描述相应体内容的长度
- 响应体中的具体内容
这里MEME类型的获取一般有如下几种方式:
- 通过文件的扩展名来进行判断,这个是最常用的方式
- 通过扫描资源的内容然后和移植模板表进行对比匹配,以获取资源的MIME类型,这种方式可以用于文件没有扩展名的时候,但是效率比较低下
- 直接将某个资源强制指定为某个MIME类型,无论其内容是什么
- 可以通过Web服务器配置,使其与用户协商使用哪种MIME类型最好,该种方式后续会专门的说明。
2.5.1 重定向
有时候Web服务器并不是总是成功返回所需资源内容的报文。有时候Web服务器会返回一个重定向的报文,响应码是3XX,同时包含一个Location首部,其内容是所请求资源的新URL地址或者优选URL地址。一般重定向主要是用于以下几种情况:
- 永久搬离资源
- Web服务重新整理资源,该资源的搬离了原来的位置,或者被重新命名了。这个时候如果客户端用以前的URL地址进行访问的时候,服务器可以告诉客户端,该资源已经搬离或重名了,并且告诉客户端新的URL地址。这种情况一般使用301状态码,让客户端以后要想访问该资源都请访问的URL。
- 临时搬离资源
- 如果资源只是临时搬离或者重命名,不久的将来还会还原回去。这个时候也是通过重定向告诉客户端,我们临时调整了下新URL地址,但是后面还会还原回去,所以这次你先临时到新URL地址获取资源,后面还是按照之前的URL进行访问。这种情况一般使用303或者307状态码,至于这两者的区别,前面Http权威指南笔记(三)——HTTP报文已经分析过了,这里不在赘述。
- URL增强
- 某些时候,访问一个资源可能需要一些额外信息,但是客户的请求的URL没有这些信息,服务器这边又能够自动填充这些信息。这个时候当客户端发起请求后,服务器可以利用重定向,将需要填充的信息补充到URL中,然后将完整的URL放入Location首部。客户端收到重定向返回报文后,就会自动用填充好信息的URL进行重新访问了。同样这种情况一般也是用303或307状态码
- 负载均衡
- 如果一个超载的服务器收到一条请求,服务器可以将客户端重定向到一个负载不太重的服务器上去。这种情况一般也是使用 303 和或307 状态码。
- 服务器关联
- Web 服务器上可能会有某些用户的本地信息;服务器可以将客户端重定向到包含了那个客户端信息的服务器上去,一是一般使用303或者307状态码。
- 规范目录名称
- 客户端请求的 URI 是一个不带尾部斜线的目录名时,大多数 Web 服务器都会将客户端重定向到一个加了斜线的 URI 上,这样相对链接就可以正常工作了。
2.6 发送响应和记录日志
通过上面的步骤,将响应构建好之后,就需要将响应发送给客户端。发送响应的时候,和接收数据一样,因为同事可能存在多个到客户端的连接,某些在接收数据,某些在发送数据,某些是空闲的,我们需要记录连接的状态,对于非持久连接,发送完响应数据后,可以关闭自己这一端的连接。对于持久连接,可能需要仍然保持连接的打开状态,这种情况,特别注意Content-length字段的正确性。
发送完响应数据后,最后我们通过日志系统,往日志文件中写入日志,用于记录和描述当前事务的情况。
第五章、web服务器的更多相关文章
- 《图解HTTP》阅读笔记-第五章-web服务器
第五章.与HTTP协助的web服务器单台虚拟主机实现多个域名可以用单台物理主机运行多台虚拟主机,这些虚拟主机的IP相同,而虚拟主机有可以寄存多个不同主机名和域名的web网站,所以要保证发送HTTP ...
- 图解 HTTP 笔记(五)——Web 服务器
该章的主要内容是讲解与 HTTP 协作的 Web 服务器 一.用单台虚拟主机实现多个域名 基于虚拟主机的功能,可以只使用一台物理机实现多个域名的网站部署. 在互联网上,域名通过 DNS 域名解析系统可 ...
- HTTP权威指南阅读笔记五:Web服务器
Web服务器会做些什么: 1.建产连接:接受一个客户端连接,或者如果不希望与这个客户端建立连接,就将其关闭. 1)处理新连接 2)客户端主机名识别 3)通过ident确定客户端用户 ident在组织内 ...
- 第五章 Web应用程序状态管理
状态管理概述 Cookie Session URL重写 状态管理概述: HTTP协议使用的是无状态的连接 对容器而言,每一个请求都来自于一个新的客户 这里我们有四种方法来解决这个状态: a:表 ...
- 第五章Web应用与应用层协议
Web应用与应用层协议 本篇博文中的主要参考文献是<计算机网络高级教程>,分别是吴功宜老先生和吴英教授合著.这部教程是我研究生老师所推荐的网络必读科目,由于该教程讲解的基础知识详细,但内容 ...
- http协议(五)web服务器
1.http1.1规范允许一台http服务器搭建多个web站点... 比如提供web托管服务的供应商,可以用一台服务器为多为客户服务,也可以以每位客户持有的域名运行各自不同的网站,这里利用了虚拟服务器 ...
- 第十五章-Web开发
随着web的发展, 最开始使用的CS架构已经不适合web了, 现在web使用的架构是BS架构 如今大部分重量级的软件都以web形式提供了 web开发的四个阶段 1) 静态web页面 2) CGI: 静 ...
- 【odoo14】第五章、服务器侧开发-基础
本章包含如下内容: 定义模型方法和使用api装饰器 向用户反馈错误信息 针对不同的对象获取空数据集 创建新纪录 更新数据集数据 搜索数据 组合数据集 过滤数据集 遍历记录集 排序数据集 重写已有业务逻 ...
- 【重点突破】——使用Express创建一个web服务器
一.引言 在自学node.js的过程中有一个非常重要的框架,那就是Express.它是一个基于NodeJs http模块而编写的高层模块,弥补http模块的繁琐和不方便,能够快速开发http服务器.这 ...
- 与http协作的web服务器、http首部(第五章、第六章)
第五章 与http协作的web服务器 1.用单台虚拟主机实现多个域名 通过域名访问主机,经过DNS解析成ip地址,反向代理,可以代理多台服务器,正向代理则相反,代理客户端 2.通信数据转化程序:代理. ...
随机推荐
- hdu1171 灵活的运用背包问题咯。。。 还有!!!! 合理的计算数组的范围!! wa了好多次!
Problem Description Nowadays, we all know that Computer College is the biggest department in HDU. Bu ...
- 十年感悟之 python之路
本文由 简悦 SimpRead 转码, 原文地址 https://laisky.com/p/python-road/ Changelog: updated at 2019/9/6 一.概述 本文起源于 ...
- Android笔记(十八) 下拉列表(Spinner)
App中常用的控件——下拉列表(Spinner),提供特定选择供用户选择 Spinner每次只能选择一个部件,它的选项来自于与之相关联的适配器(apater)中. MainActivity.java ...
- 记录java+testng运行selenium(四)--- 运行代码
涉及的文件有: .\medical\BusinessFile.java :实例化excel及xml文件操作对象以及将list变成Map .\medical\manual\business\LoginB ...
- DNS服务——正向查找区 和 逆向查找区
前言 正向查找区,就是我们最熟知的DNS.即根据域名解析成IP 逆向查找区,即根据IP解析成域名. 他们之间的关系很像ARP和RARP 正向查找区 /etc/named.rfc1912.zones用于 ...
- SpringCloud2.0 概述 基础教程(一)
1.SpringCloud简介 Spring Cloud为开发人员提供了快速构建分布式系统中一些常见模式的工具(例如配置管理,服务发现,断路器,智能路由,微代理,控制总线,一次性令牌,全局锁,领导选举 ...
- Codeforces Round 585
Codeforces Round 585 浅论如何发现自己是傻子的-- 反正今天是完全蒙的,水了签到题就跑了-- A. Yellow Cards 签到题. 众所周知,CF的签到题一般是一道神神奇奇的数 ...
- 9 loader - 分析webpack调用第三方loader的过程
注意:webpack处理第三方文件类型的过程: 1.发现这个要处理的文件不是JS文件,然后就去配置文件中,查找有没有对应的第三方loader规则 2.如果能找到对应的规则,就会调用对应的loader处 ...
- 浅析Scrapy框架运行的基本流程
本篇博客将从Twisted的下载任务基本流程开始介绍,然后再一步步过渡到Scrapy框架的基本运行流程,其中还会需要我们自定义一个Low版的Scrapy框架.但内容不会涉及太多具体细节,而且需要注意的 ...
- Mac OS终端利器iTerm2(完美替代bash)
iTerm2 iTerm一个为Mac OS X编写的,功能齐全的终端仿真程序:目标是在为用户提供OS X下最佳的命令行体验,iTerm 2有很多能够提升效率的实用功能.比如说窗口分割.热键窗口.智能搜 ...