最简单MySQL教程详解(基础篇)之多表联合查询
在关系型数据库中,我们通常为了减少数据的冗余量将对数据表进行规范,将数据分割到不同的表中。当我们需要将这些数据重新合成一条时,就需要用到我们介绍来将要说到的表连接。
常用术语
冗余(Redundancy):存储两次数据,以便使系统更快速。
主键(Primary Key):主键是唯一的。同一张表中不允许出现同样两个键值。一个键值只对应着一行。
外键(Foreign Key):用于连接两张表。
表连接的方式
内连接
外连接
自连接
我们接下来将对这三种连接进行详细的介绍。
数据准备
我们需要创建下面的数据表来作为示例:
student表
表结构:
| 字段 | 解释 |
|---|---|
| studentId | 学号(主键) |
| name | 姓名 |
| phone | 电话 |
| collegeId | 学生所在学院ID(外键) |
SQL语句:
CREATE TABLE `student` (
`studentId` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`name` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`phone` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`collegeId` varchar(255) COLLATE utf8_unicode_ci DEFAULT NULL,
PRIMARY KEY (`studentId`),
KEY `collegeId` (`collegeId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
数据: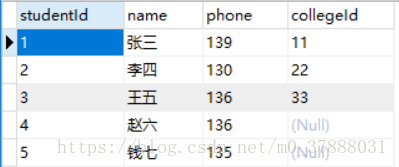
college表
表结构:
| 字段 | 解释 |
|---|---|
| collegeId | 学院ID(主键) |
| collegeName | 学院名 |
SQL语句:
CREATE TABLE `college` (
`collegeId` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
`collegeName` varchar(255) COLLATE utf8_unicode_ci NOT NULL,
PRIMARY KEY (`collegeId`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci;
数据:
内连接
内连接就是表间的主键与外键相连,只取得键值一致的,可以获取双方表中的数据连接方式。语法如下:
SELECT 列名1,列名2... FROM 表1 INNER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
运行结果:
mysql> SELECT student.name,college.collegeName FROM student INNER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
+——+————-+
3 rows in set (0.04 sec)
这样,我们就成功将【student】表中的【name】和【college】表中的【collegeName】进行了重新结合,并检索出来。
外连接
与取得双方表中数据的内连接相比,外连接只能取得其中一方存在的数据,外连接又分为左连接和右连接两种情况。接下来,我们将介绍这两种连接方式。
左外连接
左连接是以左表为标准,只查询在左边表中存在的数据,当然需要两个表中的键值一致。语法如下:
SELECT 列名1 FROM 表1 LEFT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
运行结果:
mysql> SELECT student.name,college.collegeName FROM student LEFT OUTER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
| 赵六 | NULL |
| 钱七 | NULL |
+——+————-+
5 rows in set (0.00 sec)
我们可以看出,与内连接查询结果不同的是:【赵六】、【钱七】这两个学生虽然没有学校ID但是也被查出来了,这就是我们所说的,他会以左连接中的左表的全部数据作为基准进行查询。
右外连接
同理,右连接将会以右边作为基准,进行检索。语法如下:
SELECT 列名1 FROM 表1 RIGHT OUTER JOIN 表2 ON 表1.外键=表2.主键 WhERE 条件语句;
运行结果:
mysql> SELECT student.name,college.collegeName FROM student RIGHT OUTER JOIN college ON student.collegeId = college.collegeId;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 李四 | 北大 |
| 王五 | 浙大 |
| NULL | 厦大 |
+——+————-+
4 rows in set (0.00 sec)
我们可以看出,这里就是以右边的表【college】为基准进行了检索,因为【student】中并没有【厦大】的学生,所以检索出来的为【NULL】
注意事项:
内连接是抽取两表间键值一致的数据,而外连接(左连接,右连接)时,是以其中一个表的全部记录作为基准进行检索。
左连接和右连接只有数据基准的区别,本质上是一样的,具体使用哪一种连接,根据实际的需求所决定
无论是内连接还是外连接,在查询的时候最好使用【表名.列名】的方式指定需要查询的列名,否则一旦两个表中出现了列名一致的数据时,可能会报错,养成良好的习惯很重要。
表的别名:其实我们在查询的过程中,如果遇到了特别复杂的数据表名,我们可以通过取别名的方式来实现,使用的是我们以前使用过的【AS】语句,例如,我们的内连接就可以化简为下面的语句:
SELECT s.name,c.collegeName FROM student AS s INNER JOIN college AS c ON s.collegeId = c.collegeId;查询结果一致,是不是瞬间觉得语句简洁很多呢?
自连接
自连接顾名思义就是自己跟自己连接,有人或许会问,这样的连接有意义吗?答案是肯定的。
例如,我们将【student】的数据改为下图:
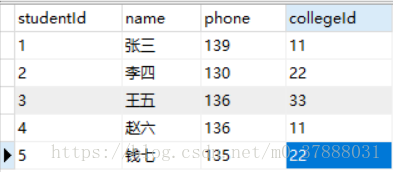
运行结果如图:
mysql> SELECT * FROM student s ,student a where a.collegeId=s.collegeId AND a.name <> s.name ORDER BY a.collegeId;
+———–+——+——-+———–+———–+——+——-+———–+
| studentId | name | phone | collegeId | studentId | name | phone | collegeId |
+———–+——+——-+———–+———–+——+——-+———–+
| 4 | 赵六 | 136 | 11 | 1 | 张三 | 139 | 11 |
| 1 | 张三 | 139 | 11 | 4 | 赵六 | 136 | 11 |
| 5 | 钱七 | 135 | 22 | 2 | 李四 | 130 | 22 |
| 2 | 李四 | 130 | 22 | 5 | 钱七 | 135 | 22 |
+———–+——+——-+———–+———–+——+——-+———–+
4 rows in set (0.00 sec)
可以看出,我们就将【student】表中在同一个学校的学生查出来了。
语句释义:
【student s】和【student a】的含义就是分别给我们的【student】表取了两个不同的别名;
【a.collegeId = s.collegeId AND a.name <> s.name 】的含义是找出【collegeId】相同,但是【name】不同的人.
【ORDER BY a.collegeId;】将结果顺序输出;
自连接的使用情况还是很多的,比如当我们找某个站点所经过的所有公交等,都可以采用自连接的方式进行检索;
子查询
通常我们在查询的SQL中嵌套查询,称为子查询。子查询通常会使复杂的查询变得简单,但是相关的子查询要对基础表的每一条数据都进行子查询的动作,所以当表单中数据过大时,一定要慎重选择。基本语法如下:
SELECT 列名1 ...FROM 表名 WHERE 列名 比较运算符 (SELECT 命令);
例如:我们利用上面的内连接的例子,在它的基础上查出学校为【清华】的学生的姓名
mysql> SELECT * FROM (SELECT student.name,college.collegeName FROM student INNER JOIN college ON student.collegeId = college.collegeId)b WHERE b.collegeName = ‘清华’;
+——+————-+
| name | collegeName |
+——+————-+
| 张三 | 清华 |
| 赵六 | 清华 |
+——+————-+
2 rows in set (0.00 sec)
查询成功。
最简单MySQL教程详解(基础篇)之多表联合查询的更多相关文章
- bt协议详解 基础篇(下)
bt协议详解 基础篇(下) 最近开发了一个免费教程的网站,产生了仔细了解bt协议的想法,所以写了这一篇文章,后续还会写一些关于搜索和索引的东西,都是在开发这个网站的过程中学习到的技术,敬请期待. 1 ...
- bt协议详解 基础篇(上)
bt协议详解 基础篇(上) 最近开发了一个免费教程的网站,产生了仔细了解bt协议的想法,所以写了这一篇文章,后续还会写一些关于搜索和索引的东西,都是在开发这个网站的过程中学习到的技术,敬请期待. 1 ...
- iOS开发 - OC - block的详解 - 基础篇
深入理解oc中的block 苹果在Mac OS X10.6 和iOS 4之后引入了block语法.这一举动对于许多OC使用者的编码风格改变很大.就我本人而言,感觉block用起来还是很爽的,但一直以来 ...
- MySQL教程详解之存储引擎介绍及默认引擎设置
什么是存储引擎? 与其他数据库例如Oracle 和SQL Server等数据库中只有一种存储引擎不同的是,MySQL有一个被称为“Pluggable Storage Engine Architectu ...
- 《MySQL必知必会》[02] 多表联合查询
1.基本连接 不同类型的数据,存储在多个表中,而所谓多表连接,就是将多个表联合返回一组输出. 1.1 等值连接 基本的连接方式非常简单,只需要在WHERE子句中规定如何关联即可,如下: SELECT ...
- 详解MongoDB中的多表关联查询($lookup)
一. 聚合框架 聚合框架是MongoDB的高级查询语言,它允许我们通过转换和合并多个文档中的数据来生成新的单个文档中不存在的信息. 聚合管道操作主要包含下面几个部分: 命令 功能描述 $projec ...
- 详解MongoDB中的多表关联查询($lookup) (转)
一. 聚合框架 聚合框架是MongoDB的高级查询语言,它允许我们通过转换和合并多个文档中的数据来生成新的单个文档中不存在的信息. 聚合管道操作主要包含下面几个部分: 命令 功能描述 $projec ...
- 经典Spring入门基础教程详解
经典Spring入门基础教程详解 https://pan.baidu.com/s/1c016cI#list/path=%2Fsharelink2319398594-201713320584085%2F ...
- 重装Windows系统 入门详解 - 基础教程
重装Windows系统 入门详解 - 基础教程 JERRY_Z. ~ 2020 / 10 / 13 转载请注明出处!️ 目录 重装Windows系统 入门详解 - 基础教程 一.说明 二.具体步骤 ( ...
随机推荐
- php+提高大文件上传速度
PHP用超级全局变量数组$_FILES来记录文件上传相关信息的. 1.file_uploads=on/off 是否允许通过http方式上传文件 2.max_execution_time=30 允许脚本 ...
- XML -- 为什么选择XML?
1.XML是什么,主要功能? XML全称(EXtensible Markup Language),是可扩展性标记语言. XML主要功能是用来传输和存储数据.它就是一种纯文本.只要程序能访问纯文本就能访 ...
- 什么是SYN Flood攻击?
SYN Flood (SYN洪水) 是种典型的DoS (Denial of Service,拒绝服务) 攻击.效果就是服务器TCP连接资源耗尽,停止响应正常的TCP连接请求. 说到原理,还得从TCP如 ...
- CDOJ 1263 The Desire of Asuna 贪心
The Desire of Asuna Time Limit: 3000/1000MS (Java/Others) Memory Limit: 65535/65535KB (Java/Othe ...
- 快速乘(O(1))
inline long long multi(long long x,long long y,long long mod) { long long tmp=(x*y-(long long)((long ...
- MySQL_(Java)使用preparestatement解决SQL注入的问题
MySQL_(Java)使用JDBC向数据库发起查询请求 传送门 MySQL_(Java)使用JDBC创建用户名和密码校验查询方法 传送门 MySQL数据库中的数据,数据库名garysql,表名gar ...
- 5 Java 插入排序
1.基本思想 将数组中的所有元素依次跟前面已经排好的元素相比较,如果选择的元素比已排序的元素小则依次交换,直到出现比选择元素小的元素或者全部元素都比较过为止. 2.算法描述 ①. 从第一个元素开始,该 ...
- SLC-Microsoft:Microsoft Lifecycle Policy
ylbtech-SLC-Microsoft:Microsoft Lifecycle Policy Microsoft Lifecycle Policy The Microsoft Lifecycle ...
- 深入学习重点分析java基础---第一章:深入理解jvm(java虚拟机) 第一节 java内存模型及gc策略
身为一个java程序员如果只会使用而不知原理称其为初级java程序员,知晓原理而升中级.融会贯通则为高级 作为有一个有技术追求的人,应当利用业余时间及零碎时间了解原理 近期在看深入理解java虚拟机 ...
- Postman系列之发送请求(一)
实验简介 Postman是一款功能强大的网页调试与发送网页HTTP请求的Chrome插件.它能提供功能强大的 Web API 和 HTTP 请求的调试,它能够发送任何类型的HTTP 请求 (GET, ...