confluent kafka connect remote debugging
1. Deep inside of kafka-connect start up
To begin with, let's take a look at how kafka connect start.
1.1 start command
# background running mode
cd /home/lenmom/workspace/software/confluent-community-5.1.-2.11/ &&./bin/connect-distributed -daemon ./etc/schema-registry/connect-avro-distributed.properties # or console running mode
cd /home/lenmom/workspace/software/confluent-community-5.1.-2.11/ &&./bin/connect-distributed ./etc/schema-registry/connect-avro-distributed.properties
we saw the start command is connect-distributed, then take a look at content of this file
#!/bin/sh
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License. if [ $# -lt ];
then
echo "USAGE: $0 [-daemon] connect-distributed.properties"
exit
fi base_dir=$(dirname $) ###
### Classpath additions for Confluent Platform releases (LSB-style layout)
###
#cd -P deals with symlink from /bin to /usr/bin
java_base_dir=$( cd -P "$base_dir/../share/java" && pwd ) # confluent-common: required by kafka-serde-tools
# kafka-serde-tools (e.g. Avro serializer): bundled with confluent-schema-registry package
for library in "kafka" "confluent-common" "kafka-serde-tools" "monitoring-interceptors"; do
dir="$java_base_dir/$library"
if [ -d "$dir" ]; then
classpath_prefix="$CLASSPATH:"
if [ "x$CLASSPATH" = "x" ]; then
classpath_prefix=""
fi
CLASSPATH="$classpath_prefix$dir/*"
fi
done if [ "x$KAFKA_LOG4J_OPTS" = "x" ]; then
LOG4J_CONFIG_NORMAL_INSTALL="/etc/kafka/connect-log4j.properties"
LOG4J_CONFIG_ZIP_INSTALL="$base_dir/../etc/kafka/connect-log4j.properties"
if [ -e "$LOG4J_CONFIG_NORMAL_INSTALL" ]; then # Normal install layout
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:${LOG4J_CONFIG_NORMAL_INSTALL}"
elif [ -e "${LOG4J_CONFIG_ZIP_INSTALL}" ]; then # Simple zip file layout
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:${LOG4J_CONFIG_ZIP_INSTALL}"
else # Fallback to normal default
KAFKA_LOG4J_OPTS="-Dlog4j.configuration=file:$base_dir/../config/connect-log4j.properties"
fi
fi
export KAFKA_LOG4J_OPTS if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xms256M -Xmx2G"
fi EXTRA_ARGS=${EXTRA_ARGS-'-name connectDistributed'} COMMAND=$
case $COMMAND in
-daemon)
EXTRA_ARGS="-daemon "$EXTRA_ARGS
shift
;;
*)
;;
esac export CLASSPATH
exec $(dirname $)/kafka-run-class $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectDistributed "$@"
we found that to start the kafka connect process, it called another file kafka-run-class,so let's goto kafka-run-class.
1.2 kafka-run-class
.
.
.
.
# Launch mode
if [ "x$DAEMON_MODE" = "xtrue" ]; then
nohup $JAVA $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" >& < /dev/null &
else
exec $JAVA $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS "$@"
fi
at the end of this file, it launched the connect process by invoking java command, and this is the location where we can add logic to remote debugging.
2. copy kafka-run-class and rename the copy to kafka-connect-debugging
cp bin/kafka-run-class bin/kafka-connect-debugging
modify the invoke command in kafka-connect-debugging to add java remote debugging support.
vim bin/kafka-connect-debugging
the invoke command as follows:
.
.
.
export JPDA_OPTS="-agentlib:jdwp=transport=dt_socket,address=8888,server=y,suspend=y"
#export JPDA_OPTS="" # Launch mode
if [ "x$DAEMON_MODE" = "xtrue" ]; then
nohup $JAVA $JPDA_OPTS $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS "$@" > "$CONSOLE_OUTPUT_FILE" >& < /dev/null &
else
exec $JAVA $JPDA_OPTS $KAFKA_HEAP_OPTS $KAFKA_JVM_PERFORMANCE_OPTS $KAFKA_GC_LOG_OPTS $KAFKA_JMX_OPTS $KAFKA_LOG4J_OPTS -cp $CLASSPATH $KAFKA_OPTS "$@"
fi
The added command means to start the kafka-connect as server and listen at port number 8888, and paused for the debugging client to connect.
if we don't want to run in debug mode, just uncomment the line
#export JPDA_OPTS=""
which means remote the # symbol in this line.
3. edit connect-distributed file
cd /home/lenmom/workspace/software/confluent-community-5.1.-2.11/
vim ./bin/connect-distributed
replace last line from
exec $(dirname $)/kafka-run-class $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectDistributed "$@"
to
exec $(dirname $)/kafka-connect-debugging $EXTRA_ARGS org.apache.kafka.connect.cli.ConnectDistributed "$@"
4. debugging
4.1 start kafka-connect
lenmom@M1701:~/workspace/software/confluent-community-5.1.-2.11$ bin/connect-distributed ./etc/schema-registry/connect-avro-distributed.properties
Listening for transport dt_socket at address:
we see the process is paused and listening on port 8888, until the debugging client attached on.

4.2 attach the kafka-connect using idea
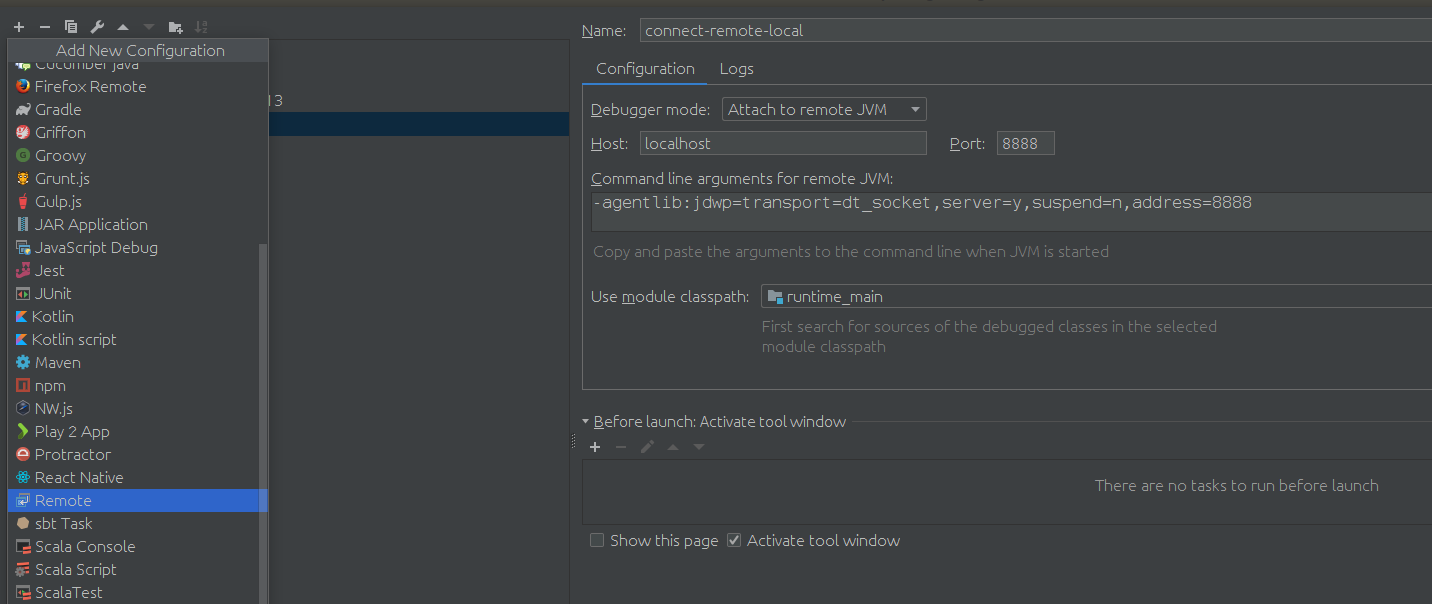
after setup the debugg setting, just client debugging, is ok now. show a screenshot of my scenario.
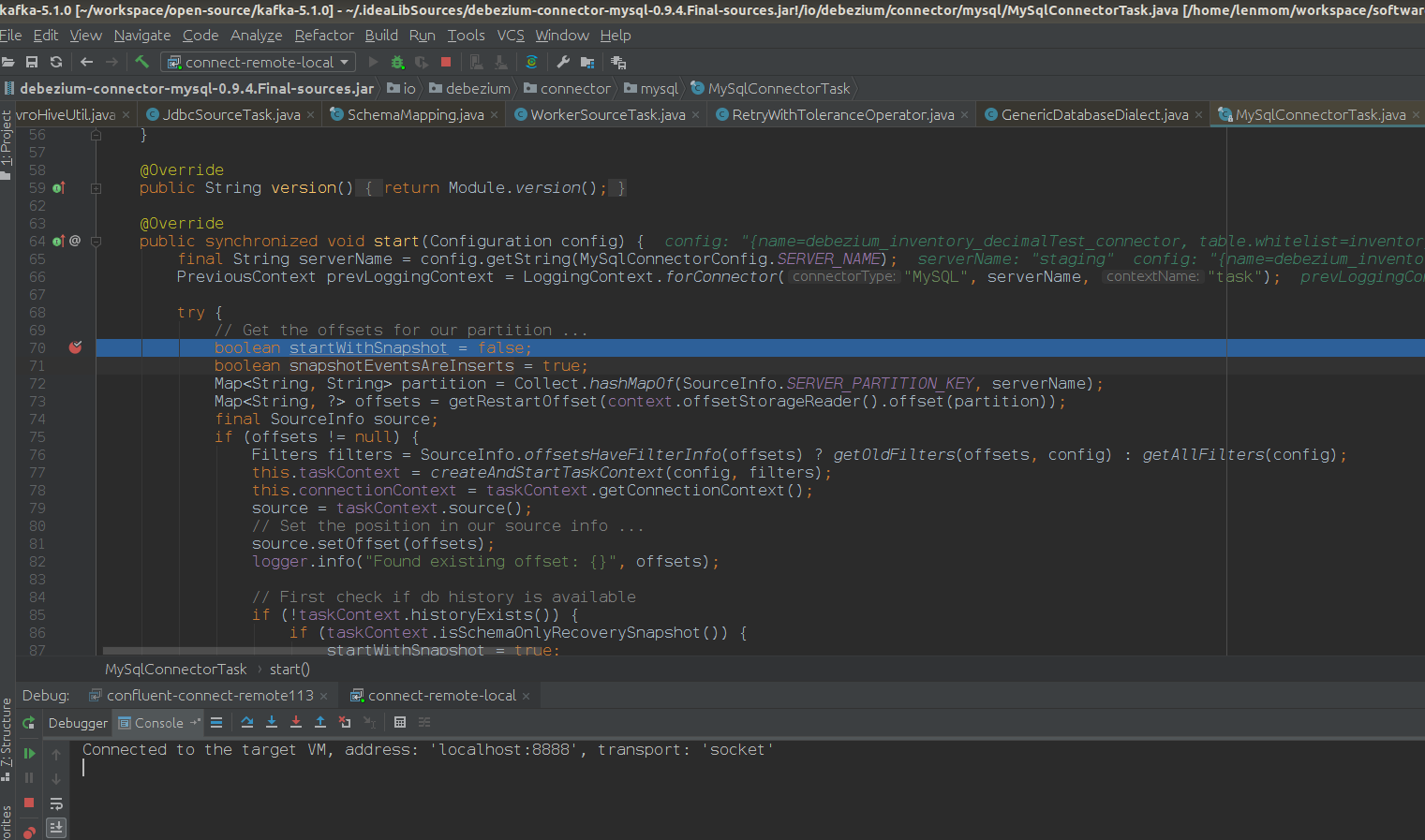
Have fun!
confluent kafka connect remote debugging的更多相关文章
- Oracle GoldenGate to Confluent with Kafka Connect
Confluent is a company founded by the team that built Apache Kafka. It builds a platform around Kafk ...
- Debugging Kafka connect
1. setup debug configuration mainClass: org.apache.kafka.connect.cli.ConnectDistributed VMOption: -D ...
- Streaming data from Oracle using Oracle GoldenGate and Kafka Connect
This is a guest blog from Robin Moffatt. Robin Moffatt is Head of R&D (Europe) at Rittman Mead, ...
- Kafka connect in practice(3): distributed mode mysql binlog ->kafka->hive
In the previous post Kafka connect in practice(1): standalone, I have introduced about the basics of ...
- Build an ETL Pipeline With Kafka Connect via JDBC Connectors
This article is an in-depth tutorial for using Kafka to move data from PostgreSQL to Hadoop HDFS via ...
- Kafka connect快速构建数据ETL通道
摘要: 作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 业余时间调研了一下Kafka connect的配置和使用,记录一些自己的理解和心得,欢迎 ...
- 以Kafka Connect作为实时数据集成平台的基础架构有什么优势?
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的.可靠的流式传输数据的工具,可以更快捷和简单地将大量数据集合移入和移出Kafka的连接器.Kafka Connect为DataPi ...
- DataPipeline联合Confluent Kafka Meetup上海站
Confluent作为国际数据“流”处理技术领先者,提供实时数据处理解决方案,在市场上拥有大量企业客户,帮助企业轻松访问各类数据.DataPipeline作为国内首家原生支持Kafka解决方案的“iP ...
- 打造实时数据集成平台——DataPipeline基于Kafka Connect的应用实践
导读:传统ETL方案让企业难以承受数据集成之重,基于Kafka Connect构建的新型实时数据集成平台被寄予厚望. 在4月21日的Kafka Beijing Meetup第四场活动上,DataPip ...
随机推荐
- Jmeter性能测试NoHttpResponseException (the target server failed to respond)
采用JMeter做Http性能测试时,在高并发请求的情况下,服务器端并无异常,但是Jmeter端报错NoHttpResponseException (the target server failed ...
- matlab(2) Logistic Regression: 画出样本数据点plotData
画出data数据 data数据 34.62365962451697,78.0246928153624,030.28671076822607,43.89499752400101,035.84740876 ...
- prometheus-alertmanager告警推送到钉钉
1. Prometheus告警简介 告警能力在Prometheus的架构中被划分成两个独立的部分.如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性 ...
- js事件冒泡/捕获
- stm32 HardFault_Handler调试及问题查找方法——飞思卡尔
看到有朋友遇到Hard Fault 异常错误,特地找到一篇飞思卡尔工程师写的一片经验帖,定位Hard Fault 异常. Kinetis MCU 采用 Cortex-M4 的内核,该内核的 Fault ...
- unordered_map初用
unordered_map,顾名思义,就是无序map,STL内部实现了Hash 所以使用时可以当做STL的Hash表使用,时间复杂度可做到O(1)查询 在C++11前,使用unordered_map要 ...
- The 2019 China Collegiate Programming Contest Harbin Site K. Keeping Rabbits
链接: https://codeforces.com/gym/102394/problem/K 题意: DreamGrid is the keeper of n rabbits. Initially, ...
- 53、servlet3.0-简介&测试
53.servlet3.0-简介&测试 Servlet 4.0 : https://www.jcp.org/en/jsr/summary?id=servlet+4.0
- Hive中的数据库、表、数据与HDFS的对应关系
1.hive数据库 我们在hive终端,查看数据库信息,可以看出hive有一个默认的数据库default,而且我们还知道hive数据库对应的是hdfs上面的一个目录,那么默认的数据库default到底 ...
- 浅谈"$fake$树"——虚树
树形$dp$利器——"$fake$"树(虚树$qwq$) 前置知识: $1.$$dfs$序 $2.$倍增法或者树链剖分求$lca$ 问题引入: 在许多的树形动规中,很多时候点特 ...