第四篇:python基础之杂货铺
在这一篇中我们将对上几篇的Python零碎的知识进行补充,即字符串的格式化输出,以及深浅拷贝,接下来我们将对这两种进行一一介绍。
一、字符串格式化输出
关于字符串的格式化输出,我们需要了解为什么需要字符串的格式化,同时掌握格式化输出的两种用法:百分号方式、format方式。接下来我们就这两种方式进行介绍:
字符串的格式化的两种用法:
#百分号方式
info1 ="My name is %s,I'm %d years old."%("little-five",22)
print(info1) #format方式
n=input("name-->:")
a=int(input("age-->:"))
info2 ="My name is {name},I'm {age} years old.".format(name=n,age=a)
print(info2)
通过以上例子我们可以看出,字符串的格式化输出使得字符串的使用更加灵活、且格式输出一致。
1、百分号方式
从上述例子我们可以看到%s、%d等这些占位符,而这些占位符不但为真实值预留位置,同时也规定了真实值输入的数据类型,例如:%s-->表示接收字符串,%d-->表示接收整数。接下来我们看一下这些常用的占位符分别代表的含义:
|
s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置 r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置 c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置 o,将整数转换成 八 进制表示,并将其格式化到指定位置 x,将整数转换成十六进制表示,并将其格式化到指定位置 d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置 e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e) E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E) f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位) g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;) G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;) %,当字符串中存在格式化标志时,需要用 %%表示一个百分号 |
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式。
常见的格式化输出:
占位符的接收方式有两种,当然其格式也不一样,两种分别是:元组、字典。
#1、字符串
st1="My name is %s"%"little-five"
#2、以字典的方式传入
st2="My name is %(name)s,I'm %(adj)s."%{"name":"little-five","adj":"greater"}
#3、浮点数,并且指定小数点后的位数,四舍五入
st3="The number is %.2f"%68.68888
#4、百分之几
st4="The tax rate is %.2f%%"%12.366566
#5、科学计数法
st5 ="scientific notation-->:%e"%11000012
st6="The tax rate is %(rate).2f%%"%{"rate":12.366566}
2、format方式
format()为字符串的内置方法,从上述例子中也可以看出,以{}为占位符,同时可以以元组和字典的方式传入。
其常见的格式化输出:
# format方式
#三种方式-->真实值传入的三种方式
#1、占位符为{},以元组的方式传入
# info1="My name is {},I'm {} years old.".format("little-five",22)
info1="My name is {},I'm {} years old.".format(*["little-five",22])#等同于上式 #2、占位符为{int},以元组的方式传入
# info2="My name is {1},I'm {0} years old.".format(22,"little-five")
info2="My name is {1},I'm {0} years old.".format(*[22,"little-five"])#等同于上式 #3、占位符为{key},以字典的方式传入
# info3="My name is {name},I'm {age} years old.".format(name="little-five",age=22)
info3="My name is {name},I'm {age} years old.".format(**{"name":"little-five","age":22})
其他的format应用方式:
#传入列表中的元素
info1="My name is {0[0]},I'm {1[0]} years old.".format(["little-five","amanda"],[22,23])
#规定传入的参数的格式
info2="My name is {:s},I'm {:d} years old.".format("little-five",22)
#规定传入的参数格式,并且以字典的形式传入
info3="My name is {name:s},I'm {age:d} years old.".format(name="little-five",age=22)
#占位符->s:字符串,d:十进制,b:二进制,0:八进制,x:十六进制,X:大写十六进制,e:科学计数法,.2f:浮点数,保留两位小数
data = "numbers -->{:s},{:d},{:b},{:o},{:x},{:X},{:e},{:.2f}"
print(data.format("hello",15,15,15,15,15,16.6666,16.3333))
同时这里忍不住提一下如何将文本高亮显示:
#\33[42;1m xxx \033[0m’,其中42为背景颜色
name ="\033[42;1m little-five \033[0m"
print(name)
二、深浅拷贝
1、浅拷贝:
在了解深浅拷贝时,我们先看一个拷贝列表的例子:
ls1=["little-five","amanda",[1,2,3]]
ls2=ls1.copy() #浅拷贝
# print(ls2)
#修改列表中的不可变数据类型,ls2变,ls1不变
ls2[0]="xiaowu"
print(ls1,ls2)
#输出为:['little-five', 'amanda', [1, 2, 3]] ['xiaowu', 'amanda', [1, 2, 3]] #修改列表中的可变数据类型,ls2变,ls1也变
ls2[2][0]=6666
print(ls1,ls2)
#输出为:['little-five', 'amanda', [6666, 2, 3]] ['xiaowu', 'amanda', [6666, 2, 3]]
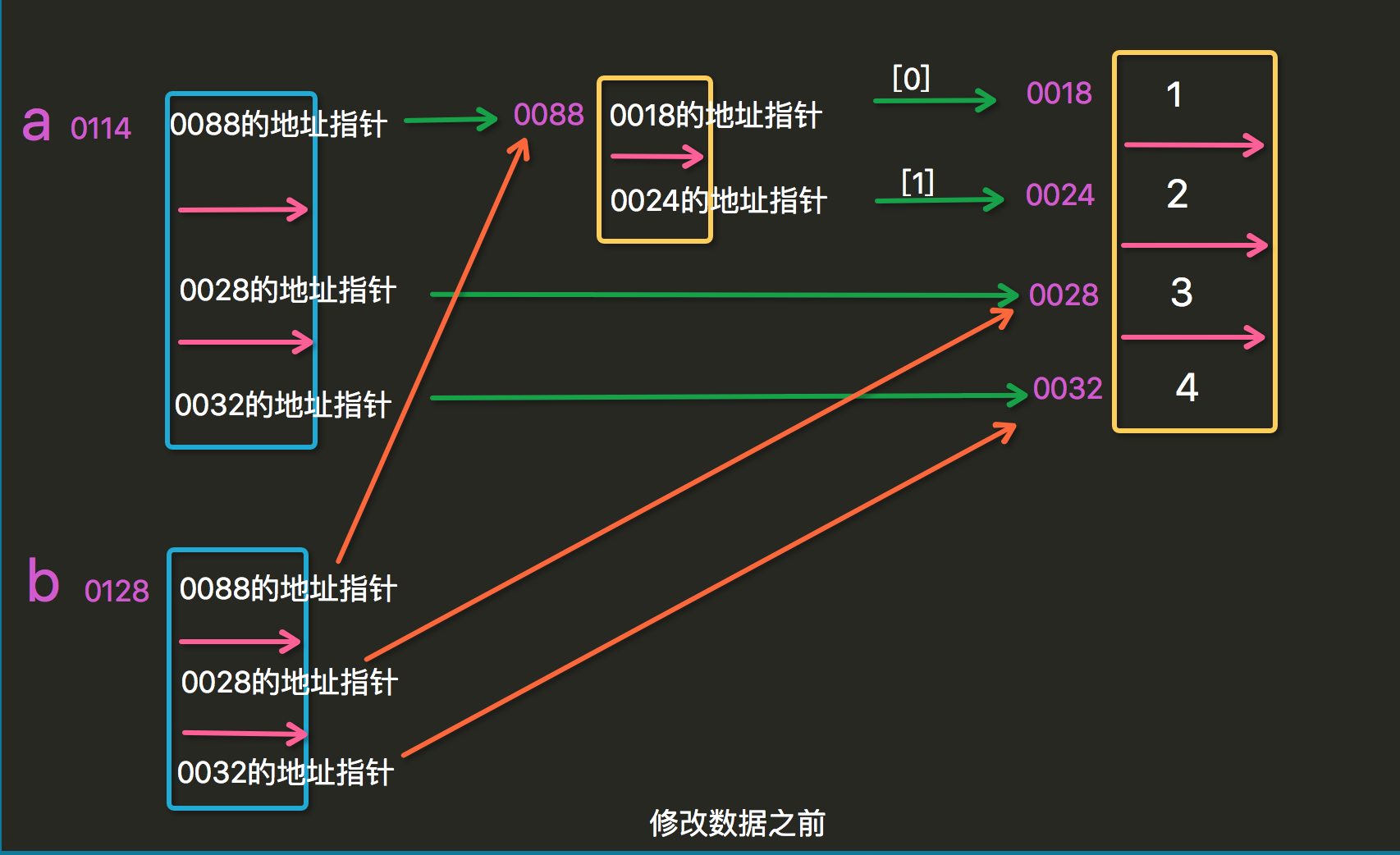
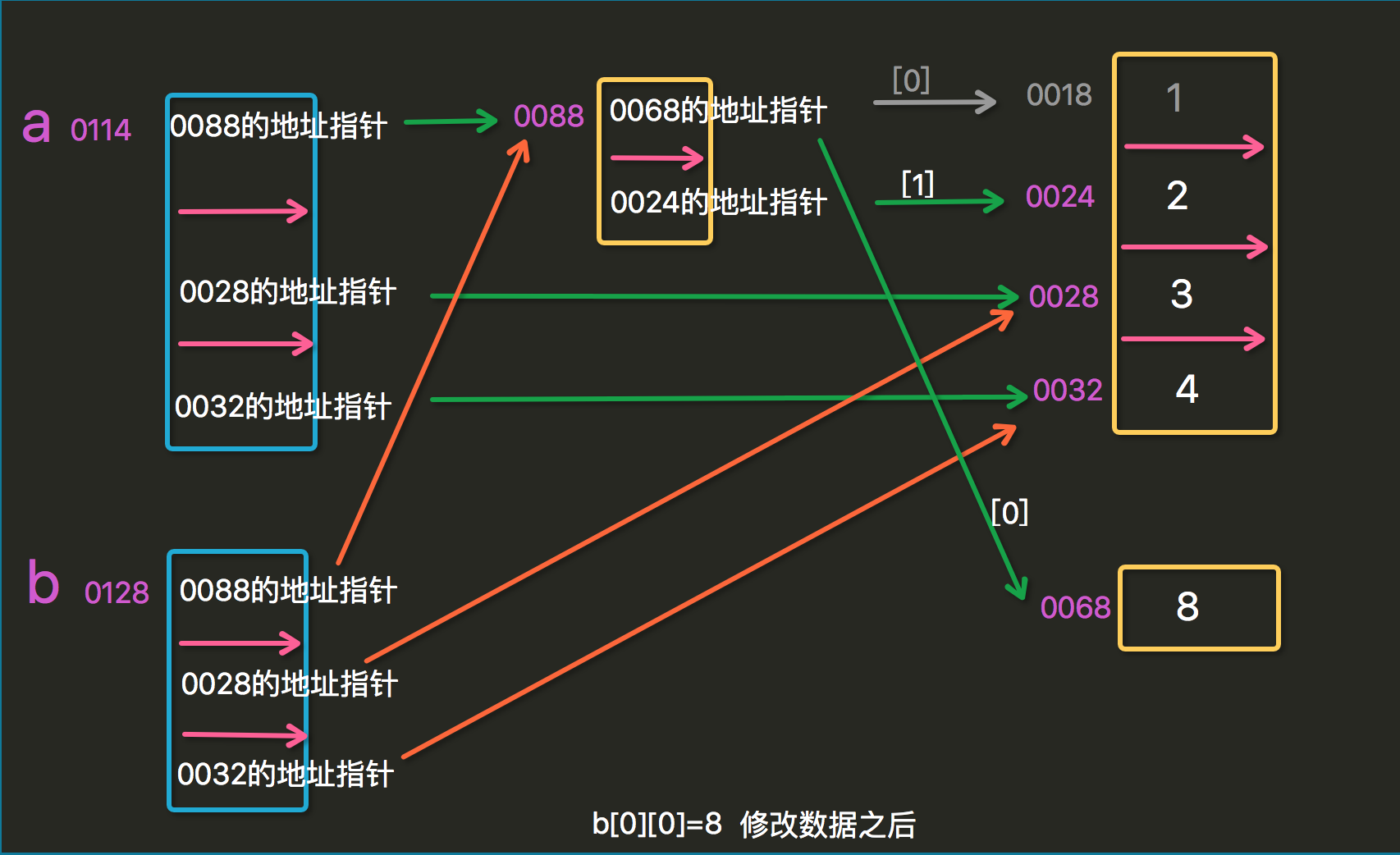
从上述例子中我们可以知道,对于浅拷贝,由ls1拷贝成ls2,当修改ls2中的不可变数据类型时,s1不发生变化;而当修改ls2中的可变数据类型是,s2则发生改变。
这是由于:浅拷贝-->拷贝的仅仅是原列表以及原列表元素中内存指针,故ls2中的不可变数据类型发生改变时,其内存指针也发生了改变,则当ls2[0]发生改变时,其内存指针发生改变,指向的不再存储"little-five"的内存空间,而是存放"xiaowu"的内存空间。故ls1不受影响。而当修改ls2中可变数据类型时,修改列表[1,2,3]中的元素时,该列表[1,2,3]的内存地址并不发生改变,故ls1和ls2的内存指针均指向该列表[1,2,3],故ls2发生该表,ls1也跟着改变。从下面例子可以看出可变数据类型和不可变数据类型的区别:
#当修改不可变数据类型时,其内存指针发生改变
name="alex"
print(id(name)) #
name="little-five"
print(id(name)) # #当修改可变数据类型,其内存指针不发生改变
lis=["zhangsan","lisi","wangwu"]
print(id(lis)) #
lis[2]="wangmazi"
print(id(lis)) #
我们也可以从下图更好的理解浅拷贝:
修改数据前:
修改数据后:
2、深拷贝
首先我们也先从拷贝一个例子可以来了解深拷贝:
import copy #导入拷贝模块
ls3=["zhangsan","lis","wnagwu",[1,2,3]]
#ls5=copy.copy(li3) #浅拷贝
ls4=copy.deepcopy(ls3) #深拷贝
print(ls4) ls4[0]="little-five"
print(ls3,ls4) #输出为:['zhangsan', 'lis', 'wnagwu', [1, 2, 3]] ['little-five', 'lis', 'wnagwu', [1, 2, 3]]
ls4[3][0]=666
print(ls3,ls4) #输出为:['zhangsan', 'lis', 'wnagwu', [1, 2, 3]] ['little-five', 'lis', 'wnagwu', [666, 2, 3]]
从上述例子可以看出,ls3与ls4再无任何关联,这是由于ls4拷贝过来时,其拷贝的不止内存指针,同时还创建新的内存空间,并将数据拷贝至新的内存空间。故新的内存指针指向新的内存空间。
第四篇:python基础之杂货铺的更多相关文章
- 【Python之路】第四篇--Python基础之函数
三元运算 三元运算(三目运算),是对简单的条件语句的缩写 # 书写格式 result = 值1 if 条件 else 值2 # 如果条件成立,那么将 “值1” 赋值给result变量,否则,将“值2” ...
- 【Python之路】第五篇--Python基础之杂货铺
字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存. 1.百分号方式 ...
- 第四篇.python的基础
目录 第四篇.python基础01 1. 变量 2. 常量 3. python变量内存管理 4. 变量的三个特征 5. 花式赋值 6. 注释 7. 数据类型基础 8. 数字类型 9. 字符串类型 10 ...
- Pyhton开发【第五篇】:Python基础之杂货铺
Python开发[第五篇]:Python基础之杂货铺 字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进 ...
- 【0728 | 预习】第三篇 Python基础
第三篇 Python基础预习 Part 1 变量 一.什么是变量? 二.为什么要有变量? 三.定义变量 四.变量的组成 五.变量名的命名规范 六.变量名的两种风格 Part 2 常量 Part 3 P ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- 0003.5-20180422-自动化第四章-python基础学习笔记--脚本
0003.5-20180422-自动化第四章-python基础学习笔记--脚本 1-shopping """ v = [ {"name": " ...
- 四、Python基础(1)
目录 四.Python基础(1) 四.Python基础(1) 1.什么是变量? 一种变化的量,量是记录世界上的状态,变指得是这些状态是会变化的. 2.为什么有变量? 因为计算机程序的运行就是一系列状态 ...
- 前端第四篇---前端基础之jQuery
前端第四篇---前端基础之jQuery 一.jQuery介绍 二.jQuery对象 三.jQuery基础语法 四.事件 五.动画效果 六.补充each 一.jQuery简介 1.jQuery介绍 jQ ...
- spring cloud系列教程第四篇-Eureka基础知识
通过前三篇文章学习,我们搭建好了两个微服务工程.即:order80和payment8001这两个服务.有了这两个基础的框架之后,我们将要开始往里面添加东西了.还记得分布式架构的几个维度吗?我们要通过一 ...
随机推荐
- 在tomcat下context.xml中配置各种数据库连接池
作者:郑文亮 Tomcat6的服务器配置文件放在 ${tomcat6}/conf 目录底下.我们可以在这里找到 server.xml 和 context.xml.当然,还有其他一些资源文件.但是在在本 ...
- 转 mysql 文件系统空间满了
#######################sample [OIP - 互联网开放平台]在2019-07-28 21:30:11发生10.194.42.19 - - Linux上的监控项[磁盘空间] ...
- ThreadLocal Memory Leak in Java web application - Tomcat
ThreadLocal variables are infamous for creating memory leaks. A memory leak in Java is amount of mem ...
- 与TypeScript的一场美丽邂逅
TypeScript(一)前言:当你点开这篇文章时,我相信你已经在很多地方都已经听说过或者见过TypeScript了.但是可能对TypeScript依然有很多问号:TypeScript到底是什么?为什 ...
- 021 Android 查询已经导入到工程中的数据库+抖动效果
1.将数据库(.db)文件放入工程中 在project状态下,新建assets文件夹,并将数据库文件放入assets目录下. 注意:assets目录.java目录.res目录是同级的 new---&g ...
- Quartz.Net—IJob特性
IJob默认情况下是无状态的,和其他系统没有关系 特别是job里面的jobdata每次都是新的.可以无限扩展. PersistJobDataAfterExecution JobData持久化 Job ...
- docker 实践十一:docker 跨主机通讯
在上一篇了解了关于 docker 的网络模型后,本篇就基于上一篇的基础来实现 docker 的跨主机通信. 注:环境为 CentOS7,docker 19.03. 本篇会尝试使用几种不同的方式来实现跨 ...
- Java CountDownLatch应用
Java的concurrent包里面的CountDownLatch其实可以把它看作一个计数器,只不过这个计数器的操作是原子操作,同时只能有一个线程去操作这个计数器,也就是同时只能有一个线程去减这个计数 ...
- redis主从中断异常处理
线上预警主从中断: 查看线上复制信息: # Replication role:slave master_host:master_host master_port:6379 master_link_st ...
- 常用算法之排序(Java)
一.常用算法(Java实现) 1.选择排序(初级算法) 原理:有N个数据则外循环就遍历N次并进行N次交换.内循环实现将外循环当前的索引i元素与索引大于i的所有元素进行比较找到最小元素索引,然后外循环进 ...