python分布式进程(windows下)
分布式进程:
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。
Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上。一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信。由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序。
举个例子:如果我们已经有一个通过Queue通信的多进程程序在同一台机器上运行,现在,由于处理任务的进程任务繁重,希望把发送任务的进程和处理任务的进程分布到两台机器上。怎么用分布式进程实现?
原有的Queue可以继续使用,但是,通过managers模块把Queue通过网络暴露出去,就可以让其他机器的进程访问Queue了。
我们先看服务进程,服务进程负责启动Queue,把Queue注册到网络上,然后往Queue里面写入任务:
# coding=utf-8
import random, time, Queue
from multiprocessing.managers import BaseManager # 发送任务的队列:
task_queue =Queue.Queue()
# 接收结果的队列:
result_queue = Queue.Queue() # 从BaseManager继承的QueueManager:
class QueueManager(BaseManager):
pass # 把两个Queue都注册到网络上, callable参数关联了Queue对象:
QueueManager.register('get_task_queue', callable=lambda: task_queue)
QueueManager.register('get_result_queue', callable=lambda: result_queue)
# 绑定端口5000, 设置验证码'abc':
manager = QueueManager(address=('', 5000), authkey=b'abc')
# 启动Queue:
manager.start()
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
# 放几个任务进去:
for i in range(10):
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
r = result.get(timeout=10)
print('Result: %s' % r)
# 关闭:
manager.shutdown()
print('master exit.')
在windows命令行终端的运行结果:
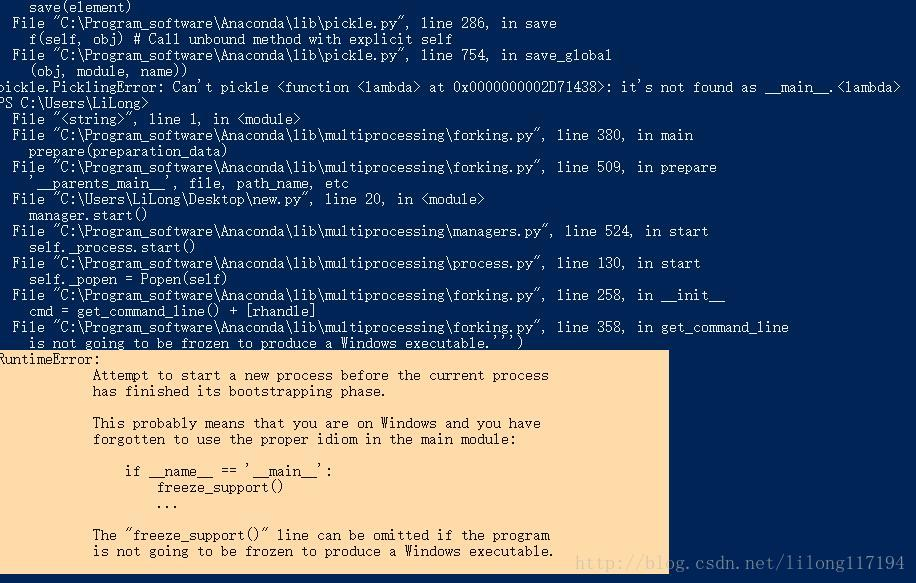

由错误信息改代码:
# coding=utf-8 import random,time, Queue
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support task_queue = Queue.Queue() # 发送任务的队列:
result_queue = Queue.Queue() # 接收结果的队列:
class QueueManager(BaseManager): # 从BaseManager继承的QueueManager:
pass
# windows下运行
def return_task_queue():
global task_queue
return task_queue # 返回发送任务队列
def return_result_queue ():
global result_queue
return result_queue # 返回接收结果队列 def test():
# 把两个Queue都注册到网络上, callable参数关联了Queue对象,它们用来进行进程间通信,交换对象
#QueueManager.register('get_task_queue', callable=lambda: task_queue)
#QueueManager.register('get_result_queue', callable=lambda: result_queue)
QueueManager.register('get_task_queue', callable=return_task_queue)
QueueManager.register('get_result_queue', callable=return_result_queue)
# 绑定端口5000, 设置验证码'abc':
#manager = QueueManager(address=('', 5000), authkey=b'abc')
# windows需要写ip地址
manager = QueueManager(address=('127.0.0.1', 5000), authkey=b'abc')
manager.start() # 启动Queue:
# 获得通过网络访问的Queue对象:
task = manager.get_task_queue()
result = manager.get_result_queue()
for i in range(10): # 放几个任务进去:
n = random.randint(0, 10000)
print('Put task %d...' % n)
task.put(n)
# 从result队列读取结果:
print('Try get results...')
for i in range(10):
# 这里加了异常捕获
try:
r = result.get(timeout=5)
print('Result: %s' % r)
except Queue.Empty:
print('result queue is empty.')
# 关闭:
manager.shutdown()
print('master exit.')
if __name__=='__main__':
freeze_support()
print('start!')
test()
运行结果:
start!
Put task 968...
Put task 6566...
Put task 711...
Put task 1686...
Put task 4962...
Put task 8514...
Put task 9725...
Put task 4985...
Put task 3896...
Put task 317...
Try get results...
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
result queue is empty.
master exit.
对比上段代码改变的地方有:
# 把两个Queue都注册到网络上, callable参数关联了Queue对象
QueueManager.register('get_task_queue',callable=return_task_queue)
QueueManager.register('get_result_queue',callable=return_result_queue)
其中task_queue和result_queue是两个队列,分别存放任务和结果。它们用来进行进程间通信,交换对象。
官网上有如下例子。
# coding=utf-8
from multiprocessing import Process, Queue
def f(queue):
queue.put([42, None, 'hello']) if __name__ == '__main__':
q = Queue() # 创建队列q
p = Process(target=f, args=(q,)) # 创建一个进程
p.start()
print(q.get()) # 打印列表[42, None, 'hello']
p.join()
其中列表[42, None, ‘hello’]从新建p进程传到了主进程中。
因为是分布式的环境,放入queue中的数据需要等待Workers机器运算处理后再进行读取,这样就需要对queue用QueueManager进行封装放到网络中。这是通过下面这句
QueueManager.register('get_task_queue',callable=return_task_queue)
实现的,我们给return_task_queue的网络调用接口取了一个名get_task_queue,而return_result_queue的名字是get_result_queue,方便区分对哪个queue进行操作。
task.put(n)即是对task_queue进行写入数据,相当于分配任务。而result.get()即是等待workers处理后返回的结果
# windows需要写ip地址
manager = QueueManager(address=('127.0.0.1', 5000), authkey=b'abc')
这点不同于linux操作系统,必须写ip地址
if __name__=='__main__':
freeze_support()
print('start!')
test()
windows必须有 if name==’main‘: 这点从报错的信息可以看出
中间加入了捕获异常,使代码运行完整,运行结果更容易看懂,在运行的时候最好用cmd终端。
下面是Worker的代码:
# coding=utf-8
import time, sys,Queue
from multiprocessing.managers import BaseManager # 创建类似的QueueManager:
class QueueManager(BaseManager):
pass # 由于这个QueueManager只从网络上获取Queue,所以注册时只提供名字:
QueueManager.register('get_task_queue')
QueueManager.register('get_result_queue') # 连接到服务器,也就是运行task_master.py的机器:
server_addr = '127.0.0.1'
print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致:
m = QueueManager(address=(server_addr, 5000), authkey=b'abc')
# 从网络连接:
try:
m.connect()
except:
print('请先启动task_master.py!')
#sys.exit("sorry, goodbye!");
# 获取Queue的对象:
task = m.get_task_queue()
result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列:
for i in range(10):
try:
n = task.get(timeout=1)
print('run task %d * %d...' % (n, n))
r = '%d * %d = %d' % (n, n, n*n)
time.sleep(1)
result.put(r)
except Queue.Empty:
print('task queue is empty.')
# 处理结束:
print('worker exit.')
这个简单的Master/Worker模型有什么用?其实这就是一个简单但真正的分布式计算,把代码稍加改造,启动多个worker,就可以把任务分布到几台甚至几十台机器上,比如把计算n*n的代码换成发送邮件,就实现了邮件队列的异步发送。
Queue对象存储在哪?注意到task_worker.py中根本没有创建Queue的代码,所以,Queue对象存储在task_master.py进程中: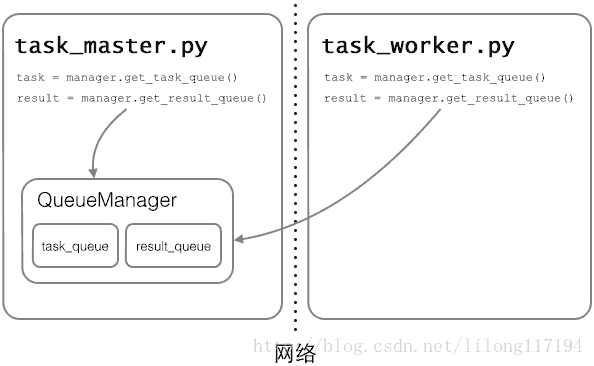
task_worker这里的QueueManager注册的名字必须和task_manager中的一样。对比上面的例子,可以看出Queue对象从另一个进程通过网络传递了过来。只不过这里的传递和网络通信由QueueManager完成。
运行结果:
运行task_master.py 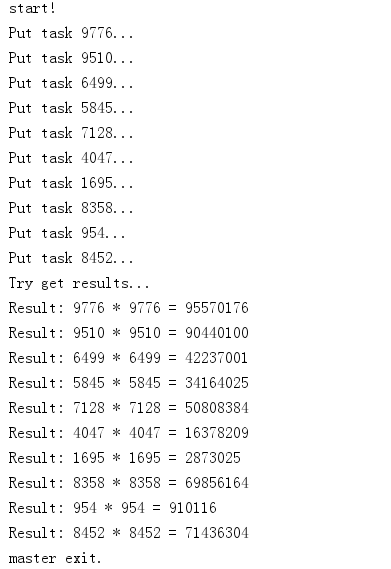
运行task_worker.py

https://blog.csdn.net/lilong117194/article/details/76051843
https://www.liaoxuefeng.com/wiki/897692888725344/923057623066752
python分布式进程(windows下)的更多相关文章
- Python之进程 进阶 下
在python程序中的进程操作 之前我们已经了解了很多进程相关的理论知识,了解进程是什么应该不再困难了,刚刚我们已经了解了,运行中的程序就是一个进程.所有的进程都是通过它的父进程来创建的.因此,运行起 ...
- python分布式进程
分布式进程指的是将Process进程分布到多台机器上,充分利用多态机器的性能完成复杂的任务 分布式进程在python 中依然要用到multiprocessing 模块.multiprocessing模 ...
- Python 分布式进程
#-*-coding:utf-8-*- '''分布式进程指的是将Process进程分不到多台机器上,充分利用多台机器的性能完成复杂的任务''' #服务器端 #--------------------- ...
- python 分布式进程体验
抽了点时间体验了一把python 分布式进程,有点像分布式计算的意思,不过我现在还没有这个需求,先把简单体验的脚本发出来,供路过的各位高手指教 注:需要先下载multiprocessing 的pyth ...
- 转 windows下安装pycharm并连接Linux的python环境 以及 windows 下notepad ++编辑 linux 的文件
######sample 1:windows下安装pycharm并连接Linux的python环境 https://www.cnblogs.com/junxun/p/8287998.html wind ...
- Python分布式进程报错:pickle模块不能序列化lambda函数
今天在学习到廖老师Python教程的分布式进程时,遇到了一个错误:_pickle.PicklingError: Can't pickle <function <lambda> at ...
- python 学习之Windows 下的编码处理!
问题1: Non-ASCII character '\xe9' in file 问题原因:程序编码上出现问题 解决方法:在程序头部加上代码 #-*- coding: UTF-8 -*- 设置代码编码为 ...
- python笔记:windows 下安装 python lxml
原文:http://blog.csdn.net/zhaokuo719/article/details/8209496 windows 环境下安装 lxml python 1.首先保证你的python ...
- Python写一个Windows下的android设备截图工具
界面版 利用python的wx库写个ui界面,用来把android设备的截图输出到电脑屏幕,前提需要安装adb,涉及到的python库也要安装.代码如下: import wx,subprocess,o ...
随机推荐
- Linux系统用终端打开图片
一.现在开发多数使用的系统都是linux系统,但有的时候会遇到一些比较麻烦的小问题,比如:在某个文件夹中存入大量的图片时,想要查看某张图片的时候,当你使用图形化显示的时候,就会很卡,所以在这里我针对于 ...
- IIS 自动化发布工具实现【一】
[持续更新中啦] 过去一年,有在尝试做.net 这块的开发运维工作.基于现在的开发场景,写了一套差异发布工具.后面用python重写了一套,现学现卖. 主要功能: 差异打包.自动发布.自动回滚 实现架 ...
- 读入 并查集 gcd/exgcd 高精度 快速幂
ios_base::sync_with_stdio(); cin.tie(); ], nxt[MAXM << ], Head[MAXN], ed = ; inline void added ...
- java UDP 通信:服务端与客服端
import java.io.IOException; import java.net.DatagramPacket; import java.net.DatagramSocket; import j ...
- unittest(一)IDE导出的代码分析
在 Python 语言下有诸多单元测试框架,如 unittest.Pytest.nose 等,其中 unittest 框架(原名 PyUnit 框架)为 Python 语言自带的单元测试框架,从 Py ...
- tomcat配置虛擬路徑
1.server.xml设置 打开Tomcat安装目录,在server.xml中<Host>标签中,增加<Context docBase="硬盘目录" path= ...
- 如何在C中传递二维数组作为参数?
回答: 在C语言中,有很多方法可以将2d数组作为参数传递.在下面的部分中,我描述了将2d数组作为参数传递给函数的几种方法. 使用指针传递2d数组以在c中运行 多维数组的第一个元素是另一个数组,所以在这 ...
- WEB知识补充 支付宝 支付
- Kubernetes的YAML文件
deployments: - apiVersion: apps/v1beta1 kind: Deployment metadata: labels: system_serviceUnit: bas-b ...
- MySQL-数据库三范式
数据库三范式 (1)第一范式(1NF): 定义:每一列都是不可分割的原子数据项(强调的是列的原子性): 例:一个表:[联系人](姓名,性别,电话) 如果在实际场景中,一个联系人有家庭电话和公司电话,那 ...