27.Spark中transformation的介绍
Spark支持两种RDD操作:transformation和action。transformation操作会针对已有的RDD创建一个新的RDD;
而action则主要是对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并可以返回结果给Driver程序。
例如,map就是一种transformation操作,它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有的新元素组成一个新的RDD。
而reduce就是一种action操作,它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。
transformation的特点就是lazy特性。lazy特性指的是,如果一个spark应用中只定义了transformation操作,那么即使你执行该应用,
这些操作也不会执行。也就是说,transformation是不会触发spark程序的执行的,它们只是记录了对RDD所做的操作,但是不会自发的执行。
只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。Spark通过这种lazy特性,来进行底层的spark应用执行的优化,避免产生过多中间结果。
action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行。这是action的特性。
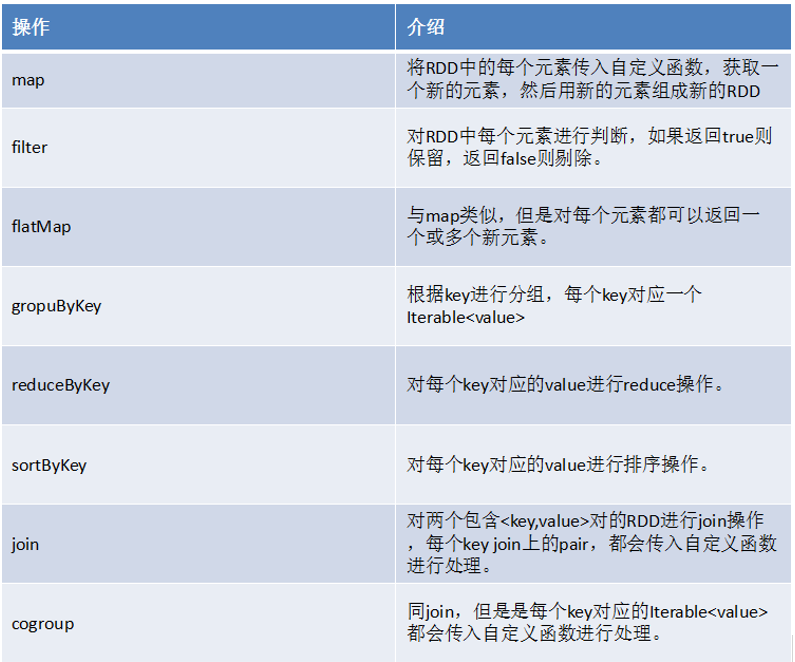
常用transformation介绍
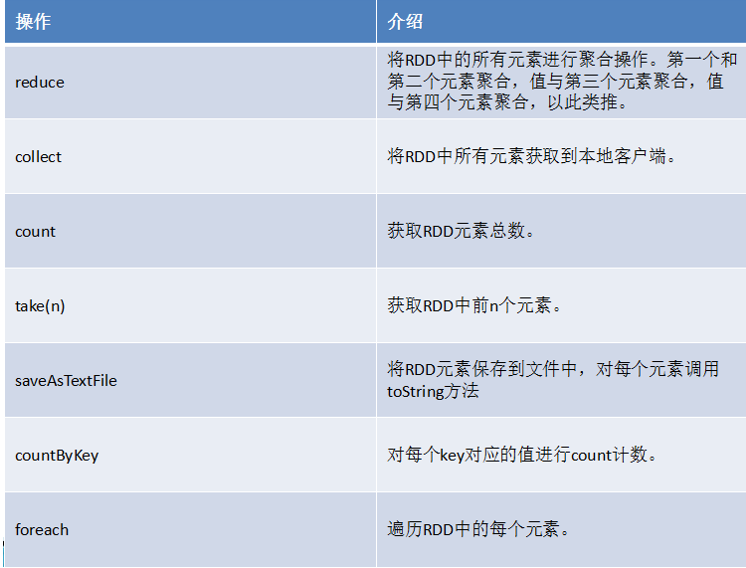
常用action介绍
transformation操作开发实战
1、map:将集合中每个元素乘以2
2、filter:过滤出集合中的偶数
3、flatMap:将行拆分为单词
4、groupByKey:将每个班级的成绩进行分组
5、reduceByKey:统计每个班级的总分
6、sortByKey:将学生分数进行排序
7、join:打印每个学生的成绩
8、cogroup:打印每个学生的成绩
map:将集合中每个元素乘以2
新建TransforDemo类

package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; public class TransforDemo { public static void main(String[] args) {
map(); } private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码

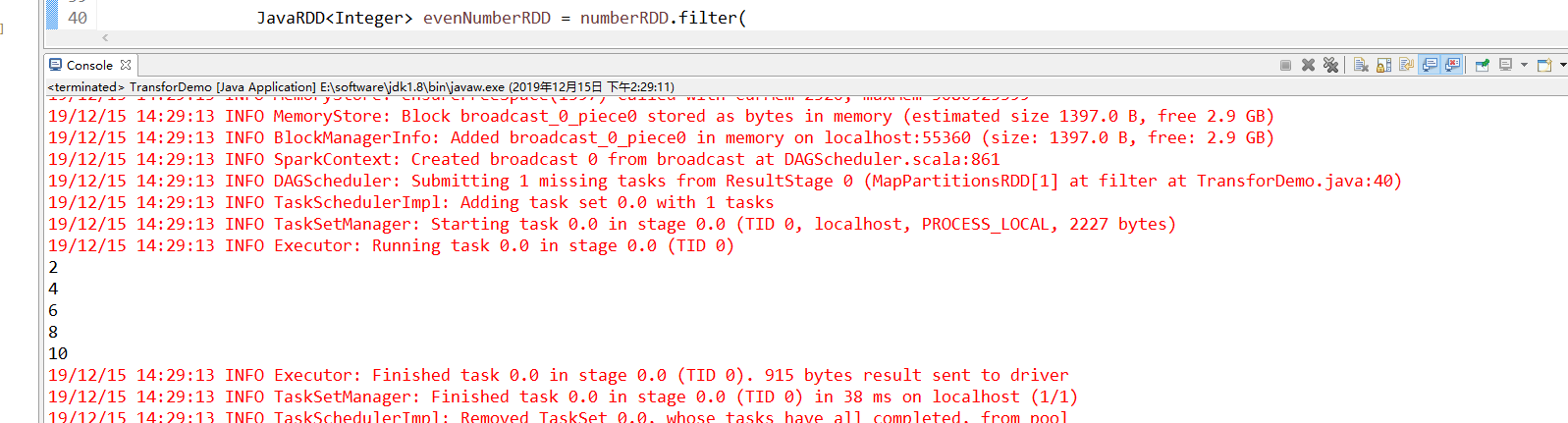
filter:过滤出集合中的偶数
添加filter()方法
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; public class TransforDemo { public static void main(String[] args) {
//map();
filter();
} private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行filter()
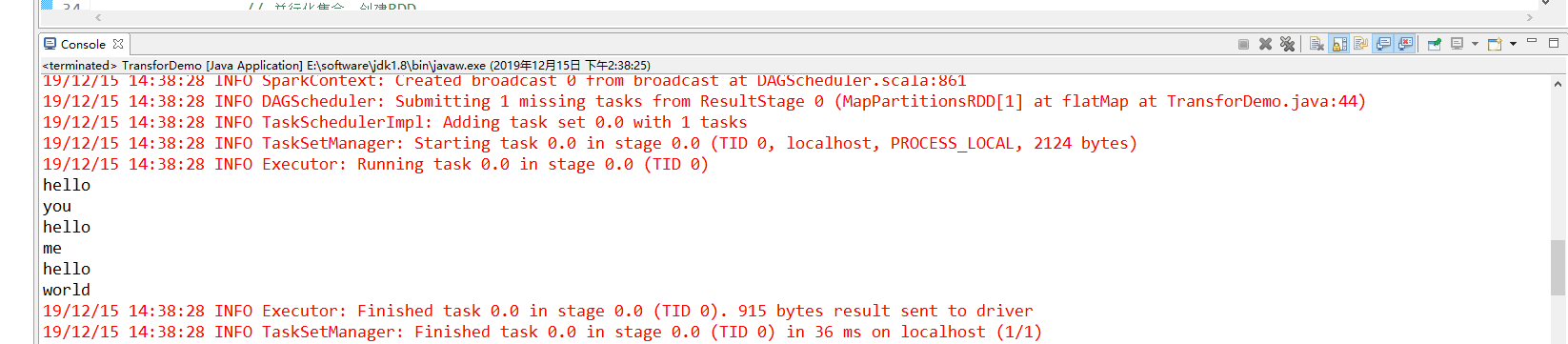
flatMap案例
flatMap案例:将文本行拆分为多个单词
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; public class TransforDemo { public static void main(String[] args) {
//map();
//filter();
flatMap() ;
} private static void flatMap() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("flatMap")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world"); // 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList); // 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; // 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
} }); // 打印新的RDD
words.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); // 关闭JavaSparkContext
sc.close(); } private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码
GroupBYkey案例
将每个班级的成绩进行分组
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class TransforDemo { public static void main(String[] args) {
//map();
//filter();
//flatMap() ;
groupByKey();
} private static void groupByKey() { // 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("groupByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", ),
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", )); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
// groupByKey算子,返回的还是JavaPairRDD
// 但是,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型
// 也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 那么接下来,我们是不是就可以通过groupedScores这种JavaPairRDD,很方便地处理某个分组内的数据
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey(); // 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Iterable<Integer>> t)
throws Exception {
System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void flatMap() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("flatMap")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world"); // 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList); // 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; // 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
} }); // 打印新的RDD
words.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); // 关闭JavaSparkContext
sc.close(); } private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码
SortByKey 案例
将学生分数进行排序
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class TransforDemo { public static void main(String[] args) {
//map();
//filter();
//flatMap() ;
// groupByKey();
sortByKey();
} private static void sortByKey() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("sortByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> scoreList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "tom"),
new Tuple2<Integer, String>(, "marry"),
new Tuple2<Integer, String>(, "jack")); // 并行化集合,创建RDD
JavaPairRDD<Integer, String> scores = sc.parallelizePairs(scoreList); // 对scores RDD执行sortByKey算子
// sortByKey其实就是根据key进行排序,可以手动指定升序,或者降序
// 返回的,还是JavaPairRDD,其中的元素内容,都是和原始的RDD一模一样的
// 但是就是RDD中的元素的顺序,不同了
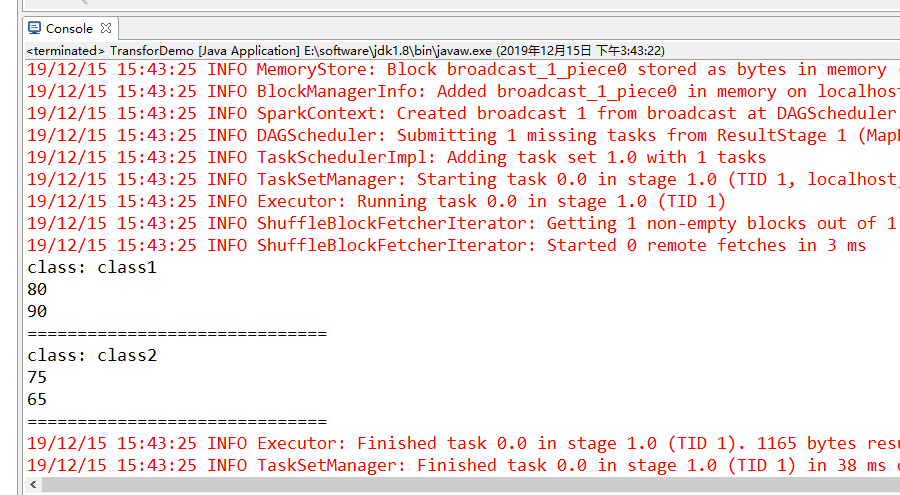
JavaPairRDD<Integer, String> sortedScores = scores.sortByKey(false); // 打印sortedScored RDD
sortedScores.foreach(new VoidFunction<Tuple2<Integer,String>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<Integer, String> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
} }); // 关闭JavaSparkContext
sc.close(); } private static void groupByKey() { // 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("groupByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", ),
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", )); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
// groupByKey算子,返回的还是JavaPairRDD
// 但是,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型
// 也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 那么接下来,我们是不是就可以通过groupedScores这种JavaPairRDD,很方便地处理某个分组内的数据
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey(); // 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Iterable<Integer>> t)
throws Exception {
System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void flatMap() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("flatMap")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world"); // 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList); // 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; // 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
} }); // 打印新的RDD
words.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); // 关闭JavaSparkContext
sc.close(); } private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码
join案例
打印学生成绩
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class TransforDemo { public static void main(String[] args) {
//map();
//filter();
//flatMap() ;
// groupByKey();
//sortByKey();
join();
} private static void join() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("join")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> studentList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "jack"),
new Tuple2<Integer, String>(, "tom")); List<Tuple2<Integer, Integer>> scoreList = Arrays.asList(
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, )); // 并行化两个RDD
JavaPairRDD<Integer, String> students = sc.parallelizePairs(studentList);
JavaPairRDD<Integer, Integer> scores = sc.parallelizePairs(scoreList); // 使用join算子关联两个RDD
// join以后,还是会根据key进行join,并返回JavaPairRDD
// 但是JavaPairRDD的第一个泛型类型是之前两个JavaPairRDD的key的类型,因为是通过key进行join的
// 第二个泛型类型,是Tuple2<v1, v2>的类型,Tuple2的两个泛型分别为原始RDD的value的类型
// join,就返回的RDD的每一个元素,就是通过key join上的一个pair
// 什么意思呢?比如有(1, 1) (1, 2) (1, 3)的一个RDD
// 还有一个(1, 4) (2, 1) (2, 2)的一个RDD
// join以后,实际上会得到(1 (1, 4)) (1, (2, 4)) (1, (3, 4))
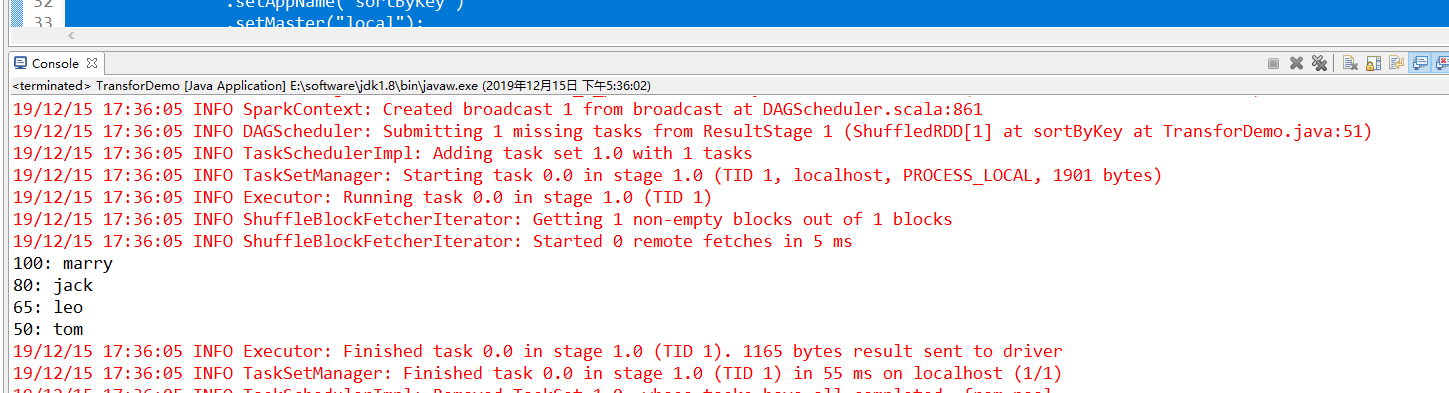
JavaPairRDD<Integer, Tuple2<String, Integer>> studentScores = students.join(scores); // 打印studnetScores RDD
studentScores.foreach( new VoidFunction<Tuple2<Integer,Tuple2<String,Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> t)
throws Exception {
System.out.println("student id: " + t._1);
System.out.println("student name: " + t._2._1);
System.out.println("student score: " + t._2._2);
System.out.println("===============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void sortByKey() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("sortByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> scoreList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "tom"),
new Tuple2<Integer, String>(, "marry"),
new Tuple2<Integer, String>(, "jack")); // 并行化集合,创建RDD
JavaPairRDD<Integer, String> scores = sc.parallelizePairs(scoreList); // 对scores RDD执行sortByKey算子
// sortByKey其实就是根据key进行排序,可以手动指定升序,或者降序
// 返回的,还是JavaPairRDD,其中的元素内容,都是和原始的RDD一模一样的
// 但是就是RDD中的元素的顺序,不同了
JavaPairRDD<Integer, String> sortedScores = scores.sortByKey(false); // 打印sortedScored RDD
sortedScores.foreach(new VoidFunction<Tuple2<Integer,String>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<Integer, String> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
} }); // 关闭JavaSparkContext
sc.close(); } private static void groupByKey() { // 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("groupByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", ),
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", )); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
// groupByKey算子,返回的还是JavaPairRDD
// 但是,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型
// 也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 那么接下来,我们是不是就可以通过groupedScores这种JavaPairRDD,很方便地处理某个分组内的数据
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey(); // 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Iterable<Integer>> t)
throws Exception {
System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void flatMap() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("flatMap")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world"); // 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList); // 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; // 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
} }); // 打印新的RDD
words.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); // 关闭JavaSparkContext
sc.close(); } private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码
cogroup案例:打印学生成绩
package com.it19gong.sparkproject; import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class TransforDemo { public static void main(String[] args) {
//map();
//filter();
//flatMap() ;
// groupByKey();
//sortByKey();
//join();
cogroup(); } private static void cogroup() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("cogroup")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> studentList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "jack"),
new Tuple2<Integer, String>(, "tom")); List<Tuple2<Integer, Integer>> scoreList = Arrays.asList(
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, )); // 并行化两个RDD
JavaPairRDD<Integer, String> students = sc.parallelizePairs(studentList);
JavaPairRDD<Integer, Integer> scores = sc.parallelizePairs(scoreList); // cogroup与join不同
// 相当于是,一个key join上的所有value,都给放到一个Iterable里面去了
// cogroup,不太好讲解,希望大家通过动手编写我们的案例,仔细体会其中的奥妙
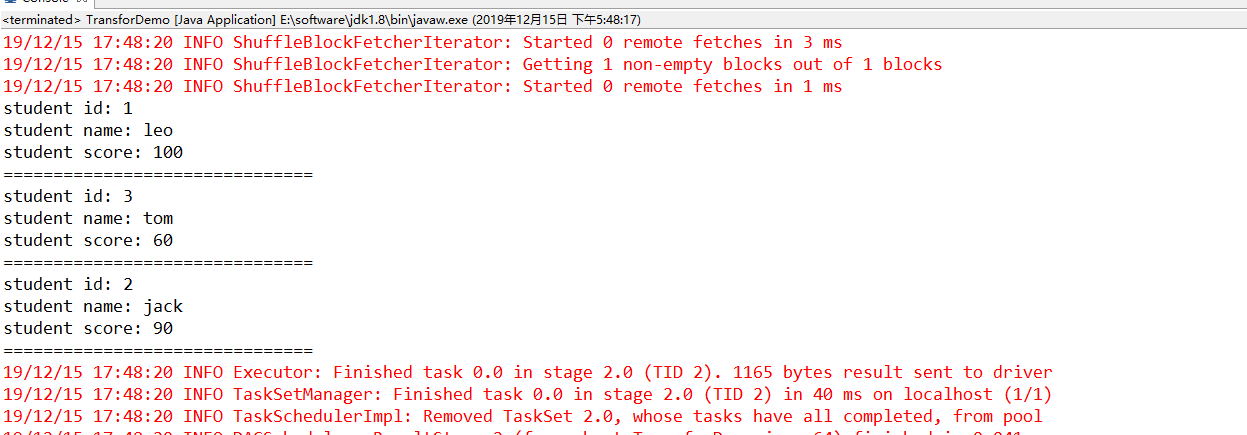
JavaPairRDD<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> studentScores =
students.cogroup(scores); // 打印studnetScores RDD
studentScores.foreach( new VoidFunction<Tuple2<Integer,Tuple2<Iterable<String>,Iterable<Integer>>>>() { private static final long serialVersionUID = 1L; @Override
public void call(
Tuple2<Integer, Tuple2<Iterable<String>, Iterable<Integer>>> t)
throws Exception {
System.out.println("student id: " + t._1);
System.out.println("student name: " + t._2._1);
System.out.println("student score: " + t._2._2);
System.out.println("===============================");
} }); // 关闭JavaSparkContext
sc.close();
} private static void join() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("join")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> studentList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "jack"),
new Tuple2<Integer, String>(, "tom")); List<Tuple2<Integer, Integer>> scoreList = Arrays.asList(
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, ),
new Tuple2<Integer, Integer>(, )); // 并行化两个RDD
JavaPairRDD<Integer, String> students = sc.parallelizePairs(studentList);
JavaPairRDD<Integer, Integer> scores = sc.parallelizePairs(scoreList); // 使用join算子关联两个RDD
// join以后,还是会根据key进行join,并返回JavaPairRDD
// 但是JavaPairRDD的第一个泛型类型是之前两个JavaPairRDD的key的类型,因为是通过key进行join的
// 第二个泛型类型,是Tuple2<v1, v2>的类型,Tuple2的两个泛型分别为原始RDD的value的类型
// join,就返回的RDD的每一个元素,就是通过key join上的一个pair
// 什么意思呢?比如有(1, 1) (1, 2) (1, 3)的一个RDD
// 还有一个(1, 4) (2, 1) (2, 2)的一个RDD
// join以后,实际上会得到(1 (1, 4)) (1, (2, 4)) (1, (3, 4))
JavaPairRDD<Integer, Tuple2<String, Integer>> studentScores = students.join(scores); // 打印studnetScores RDD
studentScores.foreach( new VoidFunction<Tuple2<Integer,Tuple2<String,Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<Integer, Tuple2<String, Integer>> t)
throws Exception {
System.out.println("student id: " + t._1);
System.out.println("student name: " + t._2._1);
System.out.println("student score: " + t._2._2);
System.out.println("===============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void sortByKey() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("sortByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<Integer, String>> scoreList = Arrays.asList(
new Tuple2<Integer, String>(, "leo"),
new Tuple2<Integer, String>(, "tom"),
new Tuple2<Integer, String>(, "marry"),
new Tuple2<Integer, String>(, "jack")); // 并行化集合,创建RDD
JavaPairRDD<Integer, String> scores = sc.parallelizePairs(scoreList); // 对scores RDD执行sortByKey算子
// sortByKey其实就是根据key进行排序,可以手动指定升序,或者降序
// 返回的,还是JavaPairRDD,其中的元素内容,都是和原始的RDD一模一样的
// 但是就是RDD中的元素的顺序,不同了
JavaPairRDD<Integer, String> sortedScores = scores.sortByKey(false); // 打印sortedScored RDD
sortedScores.foreach(new VoidFunction<Tuple2<Integer,String>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<Integer, String> t) throws Exception {
System.out.println(t._1 + ": " + t._2);
} }); // 关闭JavaSparkContext
sc.close(); } private static void groupByKey() { // 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("groupByKey")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Tuple2<String, Integer>> scoreList = Arrays.asList(
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", ),
new Tuple2<String, Integer>("class1", ),
new Tuple2<String, Integer>("class2", )); // 并行化集合,创建JavaPairRDD
JavaPairRDD<String, Integer> scores = sc.parallelizePairs(scoreList); // 针对scores RDD,执行groupByKey算子,对每个班级的成绩进行分组
// groupByKey算子,返回的还是JavaPairRDD
// 但是,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型
// 也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 那么接下来,我们是不是就可以通过groupedScores这种JavaPairRDD,很方便地处理某个分组内的数据
JavaPairRDD<String, Iterable<Integer>> groupedScores = scores.groupByKey(); // 打印groupedScores RDD
groupedScores.foreach(new VoidFunction<Tuple2<String,Iterable<Integer>>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Iterable<Integer>> t)
throws Exception {
System.out.println("class: " + t._1);
Iterator<Integer> ite = t._2.iterator();
while(ite.hasNext()) {
System.out.println(ite.next());
}
System.out.println("==============================");
} }); // 关闭JavaSparkContext
sc.close(); } private static void flatMap() {
// 创建SparkConf
SparkConf conf = new SparkConf()
.setAppName("flatMap")
.setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 构造集合
List<String> lineList = Arrays.asList("hello you", "hello me", "hello world"); // 并行化集合,创建RDD
JavaRDD<String> lines = sc.parallelize(lineList); // 对RDD执行flatMap算子,将每一行文本,拆分为多个单词
// flatMap算子,在java中,接收的参数是FlatMapFunction
// 我们需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型
// call()方法,返回的类型,不是U,而是Iterable<U>,这里的U也与第二个泛型类型相同
// flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素
// 多个元素,即封装在Iterable集合中,可以使用ArrayList等集合
// 新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; // 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable<String>(hello, you)
@Override
public Iterable<String> call(String t) throws Exception {
return Arrays.asList(t.split(" "));
} }); // 打印新的RDD
words.foreach(new VoidFunction<String>() { private static final long serialVersionUID = 1L; @Override
public void call(String t) throws Exception {
System.out.println(t);
}
}); // 关闭JavaSparkContext
sc.close(); } private static void filter() {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("filter").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf); // 模拟集合
List<Integer> numbers = Arrays.asList(, , , , , , , , , ); // 并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 对初始RDD执行filter算子,过滤出其中的偶数
// filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的
// 但是,唯一的不同,就是call()方法的返回类型是Boolean
// 每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑
// 来判断这个元素是否是你想要的
// 如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false JavaRDD<Integer> evenNumberRDD = numberRDD.filter( new Function<Integer, Boolean>() { private static final long serialVersionUID = 1L; // 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % == ;
} }); // 打印新的RDD
evenNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
} }); // 关闭JavaSparkContext
sc.close();
} private static void map() {
//创建SparkConf
SparkConf conf = new SparkConf().setAppName("map").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
//构建集合
List numbers = Arrays.asList(,,,,);
//并行化集合,创建初始RDD
JavaRDD<Integer> numberRDD = sc.parallelize(numbers); // 使用map算子,将集合中的每个元素都乘以2
// map算子,是对任何类型的RDD,都可以调用的
// 在java中,map算子接收的参数是Function对象
// 创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型
// 同时call()方法的返回类型,也必须与第二个泛型类型同步
// 在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素
// 所有新的元素就会组成一个新的RDD // 所有新的元素就会组成一个新的RDD
JavaRDD<Integer> multipleNumberRDD = numberRDD.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception { return v1 * ; }
}); multipleNumberRDD.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); }
}
运行代码

27.Spark中transformation的介绍的更多相关文章
- Hanlp分词1.7版本在Spark中分布式使用记录
新发布1.7.0版本的hanlp自然语言处理工具包差不多已经有半年时间了,最近也是一直在整理这个新版本hanlp分词工具的相关内容.不过按照当前的整理进度,还需要一段时间再给大家详细分享整理的内容.昨 ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- Spark中经常使用工具类Utils的简明介绍
<深入理解Spark:核心思想与源代码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源代码分析>一书正式出版上市 <深入理解Spark:核心思想与源代码分析 ...
- Spark中的编程模型
1. Spark中的基本概念 Application:基于Spark的用户程序,包含了一个driver program和集群中多个executor. Driver Program:运行Applicat ...
- SPARK在linux中的部署,以及SPARK中聚类算法的使用
眼下,SPARK在大数据处理领域十分流行.尤其是对于大规模数据集上的机器学习算法.SPARK更具有优势.一下初步介绍SPARK在linux中的部署与使用,以及当中聚类算法的实现. 在官网http:// ...
- 在Spark中自定义Kryo序列化输入输出API(转)
原文链接:在Spark中自定义Kryo序列化输入输出API 在Spark中内置支持两种系列化格式:(1).Java serialization:(2).Kryo serialization.在默认情况 ...
- 在 Spark 中使用 IPython Notebook
本文是从 IPython Notebook 转化而来,效果没有本来那么好. 主要为体验 IPython Notebook.至于题目,改成<在 IPython Notebook 中使用 Spark ...
- 什么是spark(六)Spark中的对象
Spark中的对象 Spark的Conf,极简化的场景,可以设置一个空conf给sparkContext,在执行spark-submit的时候,系统会默认给sparkContext赋一个SparkCo ...
- spark——spark中常说RDD,究竟RDD是什么?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是spark专题第二篇文章,我们来看spark非常重要的一个概念--RDD. 在上一讲当中我们在本地安装好了spark,虽然我们只有lo ...
随机推荐
- Gym - 101981E 思维
Gym - 101981EEva and Euro coins 题意:给你两个长度皆为n的01串s和t,能做的操作是把连续k个相同的字符反转过来,问s串能不能变成t串. 一开始把相同的漏看了,便以为是 ...
- Python基础之各种推导式玩法
一.推导式套路 除了我们之前所学习的列表推导式和生成器表达式之外,还有字典推导式.集合推导式等等. 下面就是一个以列表推导式为例的推导式详细格式,同样适用于其他推导式. variable = [out ...
- 小程序开发--API之登录授权逻辑
小程序登录授权获取逻辑 原生的小程序提供许多开放接口供使用者开发,快速建立小程序内的用户体系. 下面将小程序校验.登录.授权.获取用户信息诸多接口串联起来,以便更直观的认识到这些接口是如何在实际应用中 ...
- swoole入门到实战打造高性能赛事直播平台☆
第1章 课程介绍 本章主要是介绍了swoole的一些特性,以及使用场景,并且分享了swoole在其他公司的一些案例,最后重点讲解了swoole学习的一些准备工作. 第2章 PHP 7 源码安装 本 ...
- [提权]CVE-2018-8120漏洞复现
0x01 漏洞名称 Windows操作系统Win32k的内核提权漏洞 0x02 漏洞编号 CVE-2018-8120 0x03 漏洞描述 部分版本Windows系统win32k.sys组件的NtUse ...
- vue 脚手架安装
首先安装node.js npm 配置全局安装路径和缓存 node 安装路径下新建两个目录,node_cache和node_global npm config set prefix "E:\n ...
- js的一些笔试面试题
1. 判断字符串是否是这样组成的,第一个必须是字母,后面可以是字母.数字.下划线,总长度为5-20 var reg = /^[a-zA-Z][a-zA-Z_0-9]{4,19}$/; reg.test ...
- 安卓打包apk
打apk包的环境依赖 1.jdk 2.sdk 3.ndk 打apk包的工具 gradle mkdir /usr/local/Android cd /usr/local/Android mkdir sd ...
- Java同步数据结构之ConcurrentSkipListMap/ConcurrentSkipListSet
引言 上一篇Java同步数据结构之Map概述及ConcurrentSkipListMap原理已经将ConcurrentSkipListMap的原理大致搞清楚了,它是一种有序的能够实现高效插入,删除,更 ...
- 关于Mysql中GROUP_CONCAT函数返回值长度的坑
1.GROUP_CONCAT函数: 功能:将group by产生的同一个分组中的值连接起来,返回一个字符串结果. 语法:group_concat( [distinct] 要连接的字段 [order b ...