Java-数据类型与编码(ASCII、Unicode 和 UTF-8)
机械硬盘硬件结构(了解)https://diy.pconline.com.cn/cpu/study_cpu/1009/2215404_all.html
一、数据储存单位
1.bit(位)
https://www.bilibili.com/video/av55918101
计算机数据在硬盘中,以机械硬盘为例,其内部由磁性材料制成。磁极有 N\S 两级,可表示两种状态。可以看成 0/1。这是计算机最小储存单位,称为位。
2.Byte(字节)
一块磁盘中有许多这样的小磁块,可以表示许多 0/1。而 0/1 正好可以表示二进制数。
单单看一个二进制数并没有什么价值。上个世纪 60 年代,美国制定了一套字符编码,对英语字符与二进制数之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了 128 个字符的编码。如空格(SPACE)是 32(00100000),大写字母 A 是 65(01000001)。这 128 个符号(包括 32 个不能打印出来的控制符号),只占用了一个字节的后面 7 位,最前面的一位统一规定为 0。
ASCII 码中 1 Byte = 8 bit,后来也就默认一字节等于八位了。
二、编码
1.字符
字符并不是一个储存单位,而是一个语言符号。由此来引出码表与编码问题。
英语用 128 个符号使用 ASCII 码表就够了,但是用来表示其他语言,128 个符号是不够的。
简体中文常见的码表是 GB2312,使用两个 Byte 表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
2.Unicode 码表
世界上这么多国家,存在着多种码表,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它对应的码表,否则用错误的码表解读,就会出现乱码。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,是一种所有符号的码表。
Unicode 现在的规模可以容纳 100 多万个符号。每个符号的编码都不一样。如,U+0041 表示英语的大写字母 A,U+4E25 表示汉字严(具体的符号对应表,可以查询 unicode.org,或者专门的 汉字对应表)。
以往一套码表对应一种编码方式。如 ASCII 中 8 bit 为一个字符,GB2312 中 16 bit 为一个字符。用了 Unicode 后就不行了,靠前的字符二进制数值小,靠后的字符二进制数值大。
若全部以最长字符的位数去编码,那靠前的字符就会出现许多 0 填充,造成了许多空间浪费。所以用了 Unicode 码表后,计算机要以多少位去编码就是一个问题。
3.UTF-8 编码(由 RFC 3629 定义)
首先 UTF-8 是 Unicode 的实现方式之一。其它实现方式还有 UTF-16((UCS-2)字符用两个字节或四个字节表示)和 UTF-32((UCS-4)字符用四个字节表示)
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它使用 1~4 个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
- 对于 n(n > 1)字节的符号,第一个字节的前 n 位都设为 1,第 n + 1 位设为0,后面字节的前两位一律设为 10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母 x 表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
以汉字严为例
- 严的 Unicode 是 4E25(100111000100101)
- 根据上表,4E25 处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是 1110xxxx 10xxxxxx 10xxxxxx。
- 从严的最后一个二进制位开始,依次从后向前填入格式中的 x,多出的位补 0。这样就得到了严的 UTF-8 编码 11100100 10111000 10100101,转换成十六进制就是 E4B8A5。
三、Java 基本数据类型
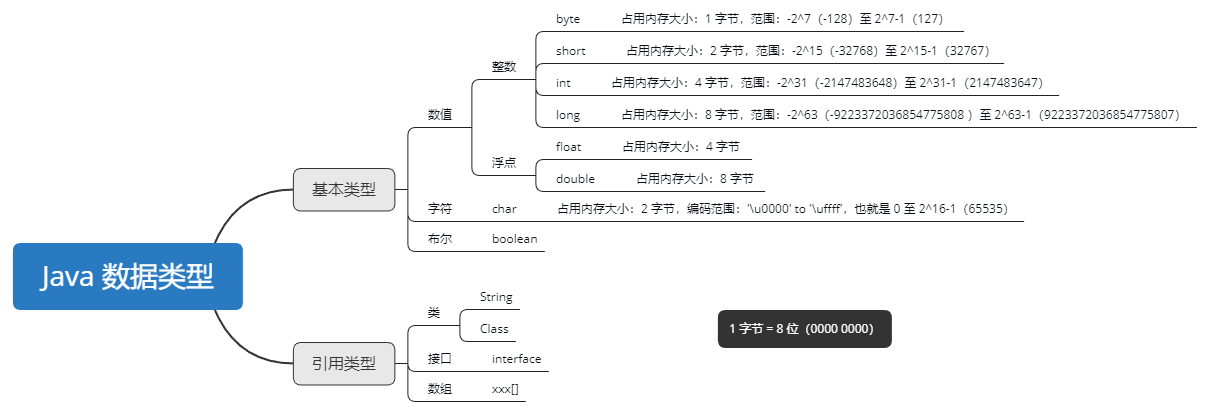
关于 boolean 型存储
Java 虚拟机中会将 boolean 映射到 int,使用 1 来表示 true,0 表示 false。
即 boolean 型占用 1 bit。
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.3.4
关于浮点型范围
https://blog.csdn.net/shichimiyasatone/article/details/85276316
关于自动拆装箱
https://www.cnblogs.com/dolphin0520/p/3780005.html
关于类型转换
- 当在计算中有不同精度的数时,Java 会将低精度的操作数转换成高精度的操作数,然后进行运算。运算的结果也是高精度的值。
- 将一个高精度的值转换成低精度值的时,要确定这个高精度类型变量的值是否能够在低精度中表示。
- 低精度到高精度为自动类型转换((byte,short,char)--int--long--float--double)
- 高精度到低精度为强制类型转换
https://docs.oracle.com/javase/specs/jls/se8/html/jls-4.html#jls-4.2.1
https://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://www.ruanyifeng.com/blog/2014/12/unicode.html
Java-数据类型与编码(ASCII、Unicode 和 UTF-8)的更多相关文章
- 字符编码 ASCII,Unicode和UTF-8的关系
转自:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143166410626 ...
- 字符编码 ASCII unicode UTF-8
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(b ...
- 35 编码 ASCII Unicode UTF-8 ,字符串的编码、io流的编码
* 编码表: * 信息在计算机上是用二进制表示的,这种表示法让人理解就很困难.为保证人类和设备,设备和计算机之间能进行正确的信息交换,人们编制的统一的信息交换代码,这就是ASCII码表 *ASCII ...
- Java用native2ascii命令做unicode编码转换
背景:在做Java开发的时候,常常会出现一些乱码,或者无法正确识别或读取的文件,比如常见的validator验证用的消息资源(properties)文件就需要进行Unicode重新编码.原因是java ...
- JAVA中最方便的Unicode转换方法
在命令行界面用native2ascii工具 1.将汉字转为Unicode: C:\Program Files\Java\jdk1.5.0_04\bin>native2ascii 测试 ...
- Java 字符编码 ASCII、Unicode、UTF-8、代码点和代码单元
1 ASCII码 统一规定英语字符与二进制位之间的关系.ASCII码一共规定了128个字符的编码.例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001). ...
- 文字编码ASCII,GB2312,GBK,GB18030,UNICODE,UCS,UTF的解析
众所周知,一个文字从输入到显示到存储是有一个固定过程的,其过程为:输入码(根据输入法不同而不同)→机内码(根据语言环境不同而不同,不同的系统语言编码也不一样)→字型码(根据不同的字体而不同)→存储码( ...
- 【转】关于字符编码,你所需要知道的(ASCII,Unicode,Utf-8,GB2312…)
转载地址:http://www.imkevinyang.com/2010/06/%E5%85%B3%E4%BA%8E%E5%AD%97%E7%AC%A6%E7%BC%96%E7%A0%81%EF%BC ...
- 【转】【编码】ANSI,ASCII,Unicode,UTF8之一
不同的国家和地区制定了不同的标准,由此产生了 GB2312.GBK.GB18030.Big5.Shift_JIS 等各自的编码标准.这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称 ...
- 关于JAVA字符编码:Unicode,ISO-8859-1,GBK,UTF-8编码及相互转换
我们最初学习计算机的时候,都学过ASCII编码. 但是为了表示各种各样的语言,在计算机技术的发展过程中,逐渐出现了很多不同标准的编码格式, 重要的有Unicode.UTF.ISO-8859-1和中国人 ...
随机推荐
- 不升级Element-UI 版本为时间选择器增加标记功能
Element-UI里的date-picker是个优秀的时间选择器,支持的选项很多,定制型很强.不过date-picker在2.12版本之前并不支持自定义单元格样式,也就是2.12的cellClass ...
- springboot项目logback.xml或者logback-spring.xml中读取不到application.yml或application.properties配置文件中的配置解决办法
在springboot项目中我们可能想要实现不同环境的日志项目配置不同,比如我想让不同环境的日志路径不同. 这时候我们很容易想: 1.到将日志路径配置在springboot的:application- ...
- odoo 常用模型的简写
<act_window>是窗口操作模型ir.actions.act_window <menuitem>是菜单项模型ir.ui.menu <report>是报表操作模 ...
- Almost Regular Bracket Sequence CodeForces - 1095E (线段树,单点更新,区间查询维护括号序列)
Almost Regular Bracket Sequence CodeForces - 1095E You are given a bracket sequence ss consisting of ...
- python: 错误处理try详解 ,traceback调用栈, 调试(logging)
摘录:https://www.liaoxuefeng.com/wiki/1016959663602400/1017598873256736 错误处理 调试 错误处理 高级语言都会使用内置的一套try. ...
- Loadrunner:管理员权限启动报错“win10 为了对电脑进行保护,已经阻止此应用”
问题 最近在尝试做性能测试,由于 Loadrunner 必须用管理员身份启动(普通用户权限启动会遇到各种权限不足的问题) 但是用管理员身份启动时,报错了:win10 为了对电脑进行保护,已经阻止此应用 ...
- CSS基础学习-7.CSS元素分类
- Linux常用命令type、date
Linux命令类型: 内置命令(shell内置):cd is shell builtin 外部命令:命令 is /usr/bin/命令,在文件系统的某个路径下有一个与命令名称相应的可执行文件 type ...
- 数据管理必看!Kendo UI for jQuery过滤器状态保持
Kendo UI for jQuery最新试用版下载 Kendo UI目前最新提供Kendo UI for jQuery.Kendo UI for Angular.Kendo UI Support f ...
- HDU 6039 - Gear Up | 2017 Multi-University Training Contest 1
建模简析: /* HDU 6039 - Gear Up [ 建模,线段树,图论 ] | 2017 Multi-University Training Contest 1 题意: 给你n个齿轮,有些齿轮 ...