Python【BeautifulSoup解析和提取网页数据】
【解析数据】
使用浏览器上网,浏览器会把服务器返回来的HTML源代码翻译为我们能看懂的样子
在爬虫中,也要使用能读懂html的工具,才能提取到想要的数据
【提取数据】是指把我们需要的数据从众多数据中挑选出来
点击右键-显示网页源代码,在这个页面里去搜索会更加准确
安装
pip install BeautifulSoup4(Mac电脑需要输入pip3 install BeautifulSoup4)
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
解析数据
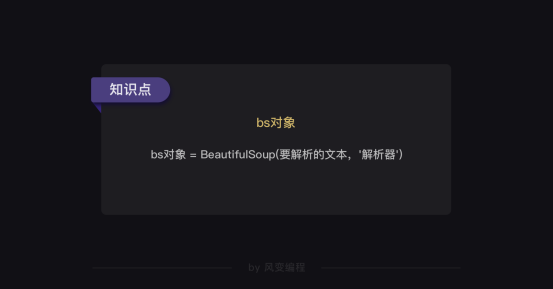
在括号中,输入两个参数,
第0个参数,必须是字符串类型;
第1个参数是解析器 这里使用用的是一个Python内置库:html.parser
import requests from bs4 import BeautifulSoup
#引入BS库 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') html = res.text soup = BeautifulSoup(html,'html.parser') #把网页解析为BeautifulSoup对象 print(type(soup)) #查看soup的类型 soup的数据类型是 <class 'bs4.BeautifulSoup'> soup是一个BeautifulSoup对象。 print(soup)
# 打印soup
response.text和soup 打印出的内容一模一样
它们属于不同的类:<class 'str'> 与<class 'bs4.BeautifulSoup'> 前者是字符串,后者是已经被解析过的BeautifulSoup对象
打印出来一样的原因:BeautifulSoup对象在直接打印的时候会调用对象内的str方法,所以直接打印 bs 对象显示字符串是str的返回结果
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
提取数据

find()与find_all()
是BeautifulSoup对象的两个方法
可以匹配html的标签和属性用法一样
区别
find()只提取首个满足要求的数据
find_all()提取出的是所有满足要求的数据
import requests
from bs4 import BeautifulSoup
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html'
res = requests.get (url)
print(res.status_code)
soup = BeautifulSoup(res.text,'html.parser')
item = soup.find('div') #使用find()方法提取首个<div>元素,并放到变量item里。
print(type(item)) #打印item的数据类型
print(item) #打印item
200
<class 'bs4.element.Tag'> #是一个Tag类对象
<div>大家好,我是一个块</div>
items = soup.find_all('div') #用find_all()把所有符合要求的数据提取出来,并放在变量items里
print(type(items)) #打印items的数据类型
print(items) #打印items
200
<class 'bs4.element.ResultSet'> #是一个ResultSet类的对象
[<div>大家好,我是一个块</div>, <div>我也是一个块</div>, <div>我还是一个块</div>]
#列表结构,其实是Tag对象以列表结构储存了起来,可以把它当做列表来处理
soup.find('div',class_='books')
class_ 和python语法中的类 class区分,避免程序冲突
还可以使用其它属性,比如style属性等
括号中的参数:标签和属性可以任选其一,也可以两个一起使用,这取决于我们要在网页中提取的内容
import requests # 调用requests库
from bs4 import BeautifulSoup # 调用BeautifulSoup库
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')# 返回一个Response对象,赋值给res
html= res.text# 把Response对象的内容以字符串的形式返回
soup = BeautifulSoup( html,'html.parser') # 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
print(type(items)) #打印items的数据类型 #items数据类型是<class 'bs4.element.ResultSet>, 前面说过可以把它当做列表list
#for循环遍历列表
for item in items:
print('想找的数据都包含在这里了:\n',item) # 打印item
print(type(item)) #<class 'bs4.element.Tag'> 是Tag对象
#####################################################################
Tag对象
find()和find_all()打印出来的东西还不是目标数据,里面含着HTML标签
xxxxx
items = soup.find_all(class_='books') # 通过定位标签和属性提取我们想要的数据
for item in items:
print(type(item))
数据类型是<class 'bs4.element.Tag'>,是Tag对象
此时,需要用到Tag对象的三种常用属性与方法
此外,提取Tag对象中的文本,用到Tag对象的另外两种属性——Tag.text,和Tag['属性名']

import requests # 调用requests库
from bs4 import BeautifulSoup # 调用BeautifulSoup库
res =requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 返回一个response对象,赋值给res
html=res.text
# 把res解析为字符串
soup = BeautifulSoup( html,'html.parser')
# 把网页解析为BeautifulSoup对象
items = soup.find_all(class_='books') # 通过匹配属性class='books'提取出我们想要的元素
for item in items: # 遍历列表items
kind = item.find('h2') # 在列表中的每个元素里,匹配标签<h2>提取出数据
title = item.find(class_='title') # 在列表中的每个元素里,匹配属性class_='title'提取出数据
brief = item.find(class_='info') # 在列表中的每个元素里,匹配属性class_='info'提取出数据
print(kind.text,'\n',title.text,'\n',title['href'],'\n',brief.text) # 打印书籍的类型、名字、链接和简介的文字
##################################################################
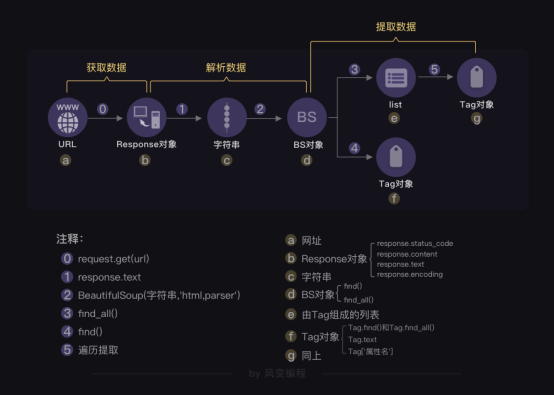
对象的变化过程
开始用requests库获取数据,
到用BeautifulSoup库来解析数据,
再继续用BeautifulSoup库提取数据,
不断经历的是我们操作对象的类型转换。
################################################################
提取扩展
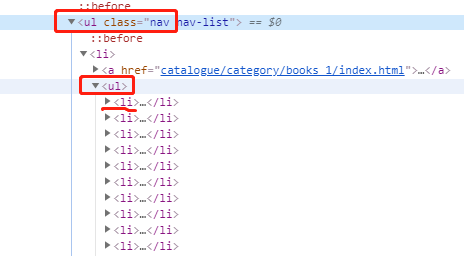
嵌套提取好几层:
find('ul',class_='nav').find('ul').find_all('li')
#提取个人理解:
每一个find的属性或者标签都是对应的层
Python【BeautifulSoup解析和提取网页数据】的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests from bs4 import BeautifulSoup url = "http://www.cntour.cn/" strhtml = requ ...
- python爬虫-提取网页数据的三种武器
常用的提取网页数据的工具有三种xpath.css选择器.正则表达式 1.xpath 1.1在python中使用xpath必须要下载lxml模块: lxml官方文档 :https://lxml.de/i ...
- 接着上次的python爬虫,今天进阶一哈,局部解析爬取网页数据
*解析网页数据的仓库 用Beatifulsoup基于lxml包lxml包基于html和xml的标记语言的解析包.可以去解析网页的内容,把我们想要的提取出来. 第一步.导入两个包,项目中必须包含beau ...
- Python使用xslt提取网页数据
1,引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第一部分,实验 ...
- 怎么用Python写爬虫抓取网页数据
机器学习首先面临的一个问题就是准备数据,数据的来源大概有这么几种:公司积累数据,购买,交换,政府机构及企业公开的数据,通过爬虫从网上抓取.本篇介绍怎么写一个爬虫从网上抓取公开的数据. 很多语言都可以写 ...
- 03:requests与BeautifulSoup结合爬取网页数据应用
1.1 爬虫相关模块命令回顾 1.requests模块 1. pip install requests 2. response = requests.get('http://www.baidu.com ...
- 解析获得的网页数据(XML文件或JSON文件)
1.解析XML:使用Pull方式. 需要导入jar包:xmlpull-xpp3-1.1.4c.jar //Pull解析XML文件 private void parseXMLWithPull(Strin ...
- python抓网页数据【ref:http://www.1point3acres.com/bbs/thread-83337-1-1.html】
前言:数据科学越来越火了,网页是数据很大的一个来源.最近很多人问怎么抓网页数据,据我所知,常见的编程语言(C++,java,python)都可以实现抓网页数据,甚至很多统计\计算的语言(R,Matla ...
- python3+beautifulSoup4.6抓取某网站小说(三)网页分析,BeautifulSoup解析
本章学习内容:将网站上的小说都爬下来,存储到本地. 目标网站:www.cuiweijuxs.com 分析页面,发现一共4步:从主页进入分版打开分页列表.打开分页下所有链接.打开作品页面.打开单章内容. ...
随机推荐
- yum安装错误记录
原因:使用yum安装libvirt以后,后续没有使用yum -remove 包名去移除这个包,接着使用源码安装了libvirt服务,当我卸载源码安装的libvirt以后,通过yum重新安装libvir ...
- (转)supervisor
转载:https://www.cnblogs.com/zhoujinyi/p/6073705.html 进程管理supervisor的简单说明 背景: 项目中遇到有些脚本需要通过后台进程运行,保证不被 ...
- SpringCloud介绍及入门(二)
接口的实现 在user_service_interface中添加一个User的类. 增加私有属性 id,name , 并利用快捷键Alt+Insert 实现get,set的快速生成. 实体类User ...
- Go by Example-流控制语句之if/else
Go by Example-流控制语句之if/else Go中的if/else的用法和其他语言没什么区别,在格式要求上保留了类似Python中的一些特性. 基本概念 在条件判断语法 if/else 中 ...
- vue使用install函数把组件做成插件方便全局调用
在vue项目中,我们可以自定义组件,像element-ui一样使用Vue.use()方法来使用,具体实现方法: 1.首先新建一个Cmponent.vue文件 // Cmponent.vue <t ...
- Bitmap: 使用Bitmap作为绘图缓冲时设置抗锯齿
android上绘图时常用的抗锯齿方法是: paint.setAntiAlias(true); 但是在以Bitmap作为绘图缓冲绘制时,绘制出来的Bitmap可能仍然有锯齿,此时可以在绘制开始前加上下 ...
- keras多层感知机MLP
肯定有人要说什么多层感知机,不就是几个隐藏层连接在一起的吗.话是这么说,但是我觉得我们首先要自己承认自己高级,不然怎么去说服(hu nong)别人呢 from keras.models import ...
- 起步 - 安装 Git
安装 Git 是时候动手尝试下 Git 了,不过得先安装好它.有许多种安装方式,主要分为两种,一种是通过编译源代码来安装:另一种是使用为特定平台预编译好的安装包. 从源代码安装 若是条件允许,从源代码 ...
- SpringCloud学习成长之 十 高可用服务注册中心
文章 第一篇: 服务的注册与发现(Eureka) 介绍了服务注册与发现,其中服务注册中心Eureka Server,是一个实例,当成千上万个服务向它注册的时候,它的负载是非常高的,这在生产环境上是不太 ...
- Node中使用MySQL报错:TypeError: Cannot read property 'query' of undefined
Node中使用MySQL报错: TypeError: Cannot read property 'query' of undefined at /Users/sipeng/Desktop/彭思/201 ...