storm是如何保证at least once语义的?
正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

------------------------正文开始---------------------------
storm中的一些原语:
要说明上面的问题,得先了解storm中的一些原语,比如:
tuple和message
tuple:在storm中,消息是通过tuple来抽象表示的,每个tuple知道它从哪里来,应往哪里去,包含了其在tuple-tree(如果是anchored的话)或者DAG中的位置,等等信息。
spout
spout充当了tuple的发送源,spout通过和其它消息源,比如kafka交互,将消息封装为tuple,发送到流的下游。
bolt
bolt是tuple的实际处理单元,通过从spout或者另一个bolt接收tuple,进行业务处理,将自己加入tuple-tree(通过在emit方法中设置anchors)或DAG,然后继续将tuple发送到流的下游。
acker
acker是一种特殊的bolt,其接收来自spout和bolt的消息,主要功能是追踪tuple的处理情况,如果处理完成,会向tuple的源头spout发送确认消息,否则,会发送失败消息,spout收到失败的消息,根据配置和自定义的情况会进行消息的丢弃、重放处理。
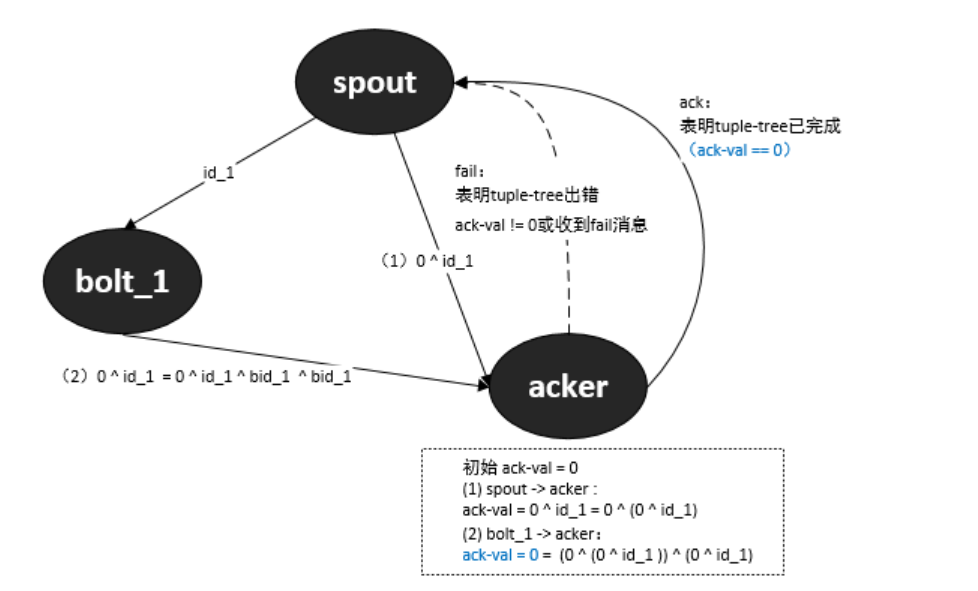
spout、bolt、acker的关系:
spout将tuple发送给流的下游的bolts.
bolt收到tuple,处理后发送给下游的bolts.
spout向acker发送请求ack的消息.
bolt向acker发送请求ack的消息.
acker向bolt和spout发送确认ack的消息.
简单的关系如下所示:

上图展示了spout、bolts等形成了一个DAG,如何追踪这个DAG的执行过程,就是storm保证仅处理一次消息的语义的机制所在。
storm如何追踪消息(tuple)的处理
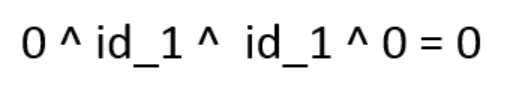
spout在调用emit/emitDirect方法发送tuple时,会以单播或者广播的方式,将消息发送给流的下游的component/task/bolt,如果配置了acker,那么会在每次emit调用之后,向acker发送请求ack的消息:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; spout向acker发送请求ack消息
;;;;;;;;;;;;;;;;;;;;;;;;;;;; ;; rooted?表示是否设置了acker
(if (and rooted?
(not (.isEmpty out-ids)))
(do
(.put pending root-id [task-id
message-id
{:stream out-stream-id :values values}
(if (sampler) (System/currentTimeMillis))])
(task/send-unanchored task-data
;;表示这是一个流初始化的消息
ACKER-INIT-STREAM-ID
;;将下游组件的out-id和0组成一个异或链,发送给acker用于追踪
[root-id (bit-xor-vals out-ids) task-id]
overflow-buffer)) ;; 如果没有配置acker,则调用自身的ack方法
(when message-id
(ack-spout-msg executor-data task-data message-id
{:stream out-stream-id :values values}
(if (sampler) ) "0:")))
从上面的代码可以看出,每次emit tuple后,spout会向acker发送一个流ID为ACKER-INIT-STREAM-ID的消息,用于将DAG或者tuple-tree中的节点信息交给acker,acker会利用这个信息来追踪tuple-tree或DAG的完成。
而spout调用emit/emitDirect方法,将tuple发到下游的bolts,也同时会发送用于追踪DAG完成情况的信息:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; spout向流的下游emit消息
;;;;;;;;;;;;;;;;;;;;;;;;;;;; (let [tuple-id (if rooted?
;; 如果有acker,tuple的MessageId会包含一个<root-id,id>的哈希表
;; root-id和id都是long型64位整数
(MessageId/makeRootId root-id id)
(MessageId/makeUnanchored))
;;实例化tuple
out-tuple (TupleImpl. worker-context
values
task-id
out-stream-id
tuple-id)] ;; 发送至队列,最终发送给流的下游的task/bolt
(transfer-fn out-task
out-tuple
overflow-buffer)
))
如果是spout -> bolt或者bolt -> bolt,这个信息就是tuple的MessageId,其内部维护一个哈希表:
// map anchor to id
private Map<Long, Long> _anchorsToIds;
键为root-id,表示spout,值表示tuple在tuple-tree或者DAG的根(spout)或者经过的边(bolt),但这里没有利用任何常规意义上的“树”的算法,而是采用异或的方式来存储这个值:
spout -> bolt,值被初始化为一个long型64位整数.
bolt -> bolt,值被初始化为一个long型64位整数,并和_anchorsToIds中的旧值进行按位异或,将结果更新到_anchorsToIds中.
如果是spout -> acker,或者bolt -> acker,那么用于追踪的是tuple的values:
spout -> acker : [root-id (bit-xor-vals out-ids) task-id]
bolt -> acker : [root (bit-xor id ack-val) ..]
下面给出上面调用的bit-xor-vals和bit-xor方法的代码:
(defn bit-xor-vals
[vals]
(reduce bit-xor vals)) (defn bit-xor
"Bitwise exclusive or"
{:inline (nary-inline 'xor)
:inline-arities >?
:added "1.0"}
([x y] (. clojure.lang.Numbers xor x y))
([x y & more]
(reduce1 bit-xor (bit-xor x y) more)))
示例
说起来有点抽象,看个例子。
假设我们有1个spout,n个bolt,1个acker:
1.spout
spout发送tuple到下游的bolts:
;; id_1是发送到bolt_1的tuple-id,依此类推
spout :
->bolt_1 : id_1
->bolt_2 : id_2
..
->bolt_n : id_n
2.bolt
bolt收到tuple,在execute方法中进行必要的处理,然后调用emit方法,最后调用ack方法:
;; bolt_1调用emit方法,追踪消息的这样一个值:让id_1和bid_1按位进行异或.
;; bid_1和id_1类似,是个long型的64位随机整数,在emit这一步生成
bolt_1 emit : id_1 ^ bid_1
;; bolt_1调用ack方法,并将值表达为如下方式的异或链的结果
bolt_1 ack : 0 ^ bid_1 ^ id_1 ^ bid_1 = 0 ^ id_1
以上,可以看出bolt进行了emit-ack组合后,其自身在异或链中的作用消失了,也就是说tuple在此bolt得到了处理。
(当然,此时的ack还没有得到acker的确认,假设acker确认了,那么上面所说的tuple在bolt得到了处理就成立了。)
来看看acker的确认。
3.acker
acker收到来自spout的tuple:
;; spout发消息给acker,tuple的MessageId包含下面的异或链的结果
spout -> acker : 0 ^ id_1 ^ id_2 ^ .. ^ id_n
;; acker收到来spout的消息,对tuple的ackVal进行处理,如下所示:
acker : 0 ^ (0 ^ id_1 ^ id_2 ^ .. ^ id_n) = 0 ^ id_1 ^ id_2 ^ .. ^ id_n
acker收到来自bolt的tuple:
;; bolt_1发消息给acker:
bolt_1 -> acker : 0 ^ id_1
;; acker维护的对应此tuple的源spout的ackVal :
ackVal : 0 ^ id_1 ^ id_2 ^ .. ^ id_n
;; acker进行确认,也就是拿上面的两个值进行异或:
acker : (0 ^ id_1) ^ (0 ^ id_1 ^ id_2 ^ .. ^ id_n) = 0 ^ id_2 ^ .. ^ id_n
可以看出,bolt_1向acker请求ack,acker收到请求ack,异或之后,id_1的作用消失。也就是说,bolt_1已处理完毕这个tuple。
所以,在acker看来,如果某个bolt的处理完成,则此bolt在异或链中的作用就消失了。
如果所有的bolt 都得到处理,那么acker将会观察到ackVal值变成了0:
ackVal = 0
= (0 ^ id_1) ^ (0 ^ id_1 ^ .. ^ id_n) ^ .. (0 ^ id_n)
= (0 ^ 0) ^ (id_1 ^ id_1) ^ (id_2 ^ id_2) ^ .. ^ (id_n ^ id_n)
如果出现了ackVal = 0,说明两个可能:
spout发送的tuple都处理完成,tuple-tree或者DAG已完成。
概率性出错,也就是说在极小的概率下,即使不按上面的确认流程来走,异或链的结果也可能出现0.但这个概率极小,小到什么程度呢?
用官方的话说就是,如果每秒发送1万个ack消息,50,000,000年时才可能发生这种情况。
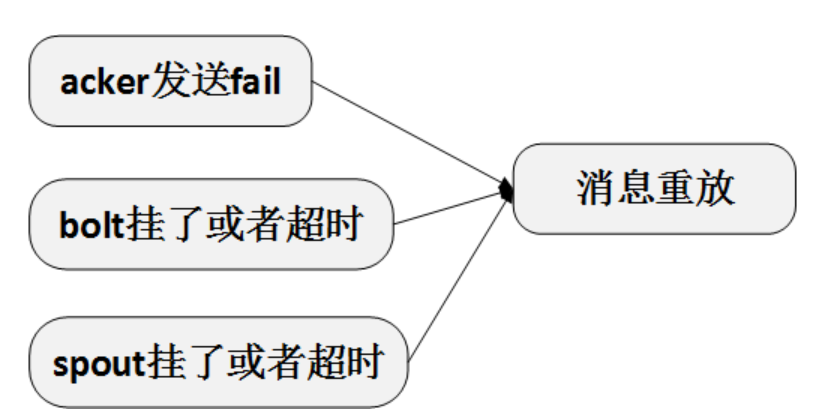
如果ackVal不为0,说明tuple-tree或DAG没有完成。如果长时间不为0,通过超时,可以触发一个超时回调,在这个回调中调用spout的fail方法,来进行重放。
如此,就保证了消息处理不会漏掉,但可能会重复。
转自:https://blog.csdn.net/gsky1986/article/details/46984229
storm是如何保证at least once语义的?的更多相关文章
- storm是怎样保证at least once语义的
背景 本篇看看storm是通过什么机制来保证消息至少处理一次的语义的. storm中的一些原语 要说明上面的问题,得先了解storm中的一些原语,比方: tuple和message 在storm中,消 ...
- storm如何保证at least once语义?
背景 前期收到的问题: 1.在Topology中我们可以指定spout.bolt的并行度,在提交Topology时Storm如何将spout.bolt自动发布到每个服务器并且控制服务的CPU.磁盘等资 ...
- storm基础框架分析
背景 前期收到的问题: 1.在Topology中我们可以指定spout.bolt的并行度,在提交Topology时Storm如何将spout.bolt自动发布到每个服务器并且控制服务的CPU.磁盘等资 ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- storm(二)消息的可靠处理
storm 通过 trident保证了对消息提供不同的级别.beast effort,at least once, exactly once. 一个tuple 从spout流出,可能会导致大量的tup ...
- Storm VS Flink ——性能对比
1.背景 Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分布式实时计算框架.其中 Apache Storm(以下简称"Storm")在美团点评实时 ...
- Storm实践(一):基础知识
storm简介 Storm是一个分布式实时流式计算平台,支持水平扩展,通过追加机器就能提供并发数进而提高处理能力:同时具备自动容错机制,能自动处理进程.机器.网络等异常. 它可以很方便地对流式数据进行 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm与Spark Streaming比较
前言spark与hadoop的比较我就不多说了,除了对硬件的要求稍高,spark应该是完胜hadoop(Map/Reduce)的.storm与spark都可以用于流计算,但storm对应的场景是毫秒级 ...
随机推荐
- 使用 ServerSocket 建立聊天服务器-2
1. 从serverListener中可以看出,每一个客户端创建新的请求之后,都会把它分配给一个独立的chatsocket ,但是每一个ChatSocket都是相互独立的,他们之间并不能沟通,所以要新 ...
- vue报错 :NavigationDuplicated {_name: "NavigationDuplicated", name: "NavigationDuplicated"}
解决的几种办法 https://blog.csdn.net/weixin_43202608/article/details/98884620 这个适合所有vue的UI框架 在main.js下添加一下代 ...
- web+页面支持批量下载吗
一.此方法火狐有些版本是不支持的 window.location.href = 'https://*****.oss-cn-**.aliyuncs.com/*********';二.为了解决火狐有些版 ...
- 二维bit模板
#include<bits/stdc++.h> using namespace std; typedef long long ll; #define N 1100 const int mo ...
- CSPS分数取mod赛92-93
我好菜啊..... 92只会打暴力,93暴力都不会了 模拟92, T1:直接ex_gcd加分类讨论即可 T2:考场只会打暴搜,正解为排序后线段树解决,排序的关键字为a+b,因为如果ai<bj&a ...
- 《MySQL数据分析实战》八句箴言前四句解析
大家好,我是jacky朱元禄,很高兴继续跟大家学习<MySQL数据分析实战>,从本节课程开始,jacky将从SQL语句入手,给大家解析八句箴言: 不管三七二十一,先把数据show来看: 数 ...
- 不用中间变量交换a和b的值?
a = b = a = a+b b = a-b a = a-b print(a,b) a = b = a = a^b b = b^a a = a^b print(a,b) a = b = a,b = ...
- CF786E ALT
题意 有一棵 \(n\) 个点的树和 \(m\) 个人,第 \(i\) 个人从 \(u_i\) 走到 \(v_i\) 现在要发宠物,要求一个人要么他自己发到宠物,要么他走的路径上的都有宠物. 求最小代 ...
- getLocation需要在app.json中声明permission字段,解决办法
具体开发方法如下: 在 app.json 里面增加 permission 属性配置(小游戏需在game.json中配置): "permission": { "scope. ...
- [大数据相关] Hive中的全排序:order by,sort by, distribute by
写mapreduce程序时,如果reduce个数>1,想要实现全排序需要控制好map的输出,详见Hadoop简单实现全排序. 现在学了hive,写sql大家都很熟悉,如果一个order by解决 ...