18.linux日志收集数据到hdfs上面
先创建一个目录

在这个job目录下创建upload.sh文件

[hadoop@node1 ~]$ pwd
/home/hadoop
[hadoop@node1 ~]$ mkdir job
[hadoop@node1 ~]$ ls
Desktop Downloads job Music Pictures Templates
Documents hive logs mysql-community-release-el7-.noarch.rpm Public Videos
[hadoop@node1 ~]$ cd job/
[hadoop@node1 job]$ vim upload.sh
对upload.sh进行编辑
#!/bin/bash #set java env
export JAVA_HOME=/opt/modules/jdk1..0_65
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH #set hadoop env
export HADOOP_HOME=/opt/modules/hadoop-2.6.
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH log_src_dir=/home/hadoop/logs/log/
log_toupload_dir=/home/hadoop/logs/toupload/
hdfs_root_dir=/data/clickLog// echo "log_src_dir:"$log_src_dir
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log ]]; then
# if [ "access.log" = "$fileName" ];then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
#打印信息
echo "moving $log_src_dir$fileName to $log_toupload_dir"xxxxx_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"xxxxx_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing
echo $log_toupload_dir"xxxxx_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi done #找到列表文件willDoing
ls $log_toupload_dir | grep will |grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file:"$line
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名) ,此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" |while read line
do
#打印信息
echo "puting...$line to hdfs path.....$hdfs_root_dir"
hadoop fs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
然后新建目录,并上传日志文件
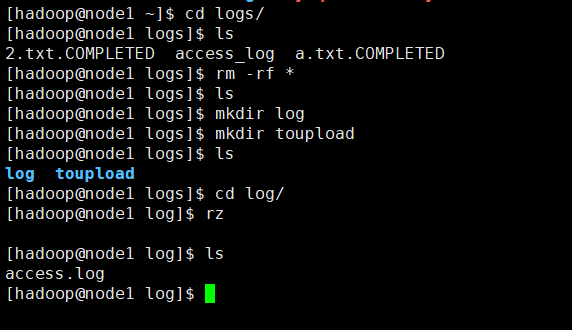
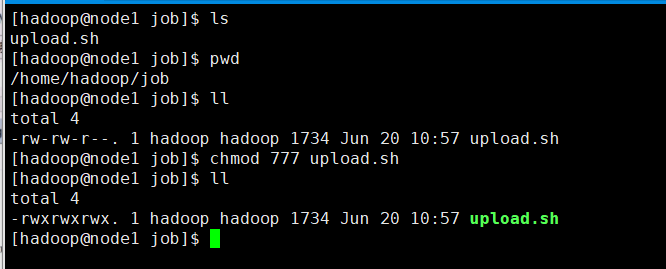
给脚本赋予权限
[hadoop@node1 job]$ ls
upload.sh
[hadoop@node1 job]$ pwd
/home/hadoop/job
[hadoop@node1 job]$ ll
total
-rw-rw-r--. hadoop hadoop Jun : upload.sh
[hadoop@node1 job]$ chmod upload.sh
[hadoop@node1 job]$ ll
total
-rwxrwxrwx. hadoop hadoop Jun : upload.sh
[hadoop@node1 job]$
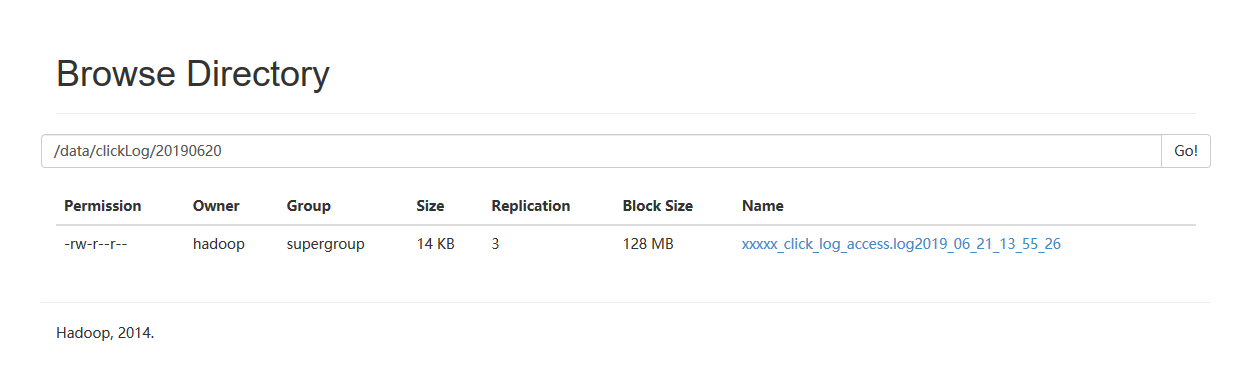
在HDFS上新建目录

执行脚本

可以看到结果

18.linux日志收集数据到hdfs上面的更多相关文章
- 日志审计与分析实验三(rsyslog服务器端和客户端配置)(Linux日志收集)
Linux日志收集 一.实验目的: 1.掌握rsyslog配置方法 2.配置rsyslog服务收集其他Linux服务器日志: C/S架构:客户端将其日志上传到服务器端,通过对服务器端日志的查询,来实现 ...
- 大数据学习——实现多agent的串联,收集数据到HDFS中
采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs,使用agent串联 根据需求,首先定义以下3大要素 第一台flume agent l ...
- Flume + HDFS + Hive日志收集系统
最近一段时间,负责公司的产品日志埋点与收集工作,搭建了基于Flume+HDFS+Hive日志搜集系统. 一.日志搜集系统架构: 简单画了一下日志搜集系统的架构图,可以看出,flume承担了agent与 ...
- Linux下rsyslog日志收集服务环境部署记录
rsyslog 可以理解为多线程增强版的syslog. 在syslog的基础上扩展了很多其他功能,如数据库支持(MySQL.PostgreSQL.Oracle等).日志内容筛选.定义日志格式模板等.目 ...
- Linux下rsyslog日志收集服务环境部署记录【转】
rsyslog 可以理解为多线程增强版的syslog. 在syslog的基础上扩展了很多其他功能,如数据库支持(MySQL.PostgreSQL.Oracle等).日志内容筛选.定义日志格式模板等.目 ...
- Flume-NG + HDFS + HIVE 日志收集分析
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- Scribe+HDFS日志收集系统安装方法
1.概述 Scribe是facebook开源的日志收集系统,可用于搜索引擎中进行大规模日志分析处理.其通常与Hadoop结合使用,scribe用于向HDFS中push日志,而Hadoop通过MapRe ...
- Linux下单机部署ELK日志收集、分析环境
一.ELK简介 ELK是elastic 公司旗下三款产品ElasticSearch .Logstash .Kibana的首字母组合,主要用于日志收集.分析与报表展示. ELK Stack包含:Elas ...
- Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式
Linux就这个范儿 第18章 这里也是鼓乐笙箫 Linux读写内存数据的三种方式 P703 Linux读写内存数据的三种方式 1.read ,write方式会在用户空间和内核空间不断拷贝数据, ...
随机推荐
- OFDM发端硬件实现原理图
OFDM时域削峰法的详细说明可参考:https://www.cnblogs.com/achangchang/p/11037498.html
- 【线性代数】2-1:解方程组(Ax=b)
title: [线性代数]2-1:解方程组(Ax=b) toc: true categories: Mathematic Linear Algebra date: 2017-08-31 15:08:3 ...
- C++类中函数(构造函数、析构函数、拷贝构造函数、赋值构造函数)
[1]为什么空类可以创建对象呢? 示例代码如下: #include <iostream> using namespace std; class Empty { }; void main() ...
- Sqlite3错误:Recursive use of cursors not allowed 的解决方案
感悟] 写完这篇日志后,有调了一段时间程序,又有了一点心得分享下: 一)爬稳定的数(dong)据(xi)最好存储下来,特别是数据库在国外的那种,下载时间成本太高昂了,存起来再处理,会节约很多时间: 二 ...
- 内置对象 Date
1.内置对象 a)语言自带的对象 b)提供了常用的,基本的功能 Date 1.定义的方法 a) 获取当前时间 var date1=new Date(); co ...
- 部署Hadoop2.0高性能集群
废话不多说直接实战,部署Hadoop高性能集群: 拓扑图: 一.实验前期环境准备: 1.三台主机配置hosts文件:(复制到另外两台主机上) [root@tiandong63 ~]# more /et ...
- AT3576 Popping Balls
AT3576 Popping Balls 好题!一种以前没怎么见过的思路! %%ywy 以什么方式,什么位置统计本质不同的方案,才能不重不漏是处理所有计数问题的主心骨. 本题难以容斥.难以DP. 所以 ...
- Leetcode题目102.二叉树的层次遍历(队列-中等)
题目描述: 给定一个二叉树,返回其按层次遍历的节点值. (即逐层地,从左到右访问所有节点). 例如: 给定二叉树: [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 ...
- A*算法解决15数码问题_Python实现
1问题描述 数码问题常被用来演示如何在状态空间中生成动作序列.一个典型的例子是15数码问题,它是由放在一个4×4的16宫格棋盘中的15个数码(1-15)构成,棋盘中的一个单元是空的,它的邻接单元中的数 ...
- P4104 [HEOI2014]平衡
友情提醒:取模太多真的会TLE!!! P4104 [HEOI2014]平衡 题解 本题属于 DP-整数划分 类问题中的 把整数 n 划分成 k 个不相同不大于 m 的正整数问题 设置DP状态 f[ ...