利用爬虫、SMTP和树莓派3B发送邮件&续集&(爬取墨迹天气预报信息)
-----------------------------------------------学无止境-----------------------------------------------
前言:大家好,欢迎来到誉雪飞舞的博客园,我的每篇文章都是自己用心编写,
算不上精心但是足够用心分享我的自学知识,希望大家能够指正我,互相学习成长。
转载请注明:https://www.cnblogs.com/wyl-pi/p/10637688.html
先给大家道个歉,我的上一篇文章中没有在树莓派的交互界面进行操作实验,而且我答应大家一定会把这个实验补上,虽然没太有空整理,
但是自己说出来的承诺,我必须要兑现,认真对待我的每一篇文章,认真对待我的每个读者,认真对待自己的内心,不能应付着就过去了,
所以我特意给挤出时间怀着愧疚与坚定地心情再次分享完善这个小项目。

一开始出了很多问题,果然还是那句金句名言,切勿眼高手低
既然答应给大家一个交代,那咱们一个个慢慢说:
1、上来直接运行有错误的说缺乏bs4、beautifulsoup库,命令安装;
#python2:
sudo apt-get install python-bs4
sudo pip install beautifulsoup4
#python3:
sudo apt-get install python3-bs4
sudo pip3 install beautifulsoup4
关于报错信息:pip3无效命令的解决
首先安装setuptools(一定要用sudo管理员权限做,如果长时间连接不上主机Ctrl+C,重新执行命令)
cd /usr/local/src/
sudo wget --no-check-certificate https://pypi.python.org/packages/source/s/setuptools/setuptools-19.6.tar.gz
tar -zxvf setuptools-19.6.tar.gz
cd setuptools-19.6/
python3 setup.py build
python3 setup.py install
其次安装pip3(网络不佳很正常,多试几次多试几次)
cd /usr/local/src/
sudo wget --no-check-certificate https://pypi.python.org/packages/source/p/pip/pip-8.0.2.tar.gz
tar -zxvf pip-8.0.2.tar.gz
cd pip-8.0.2/
python3 setup.py build
python3 setup.py install
https://www.jianshu.com/p/d4c1a08b993f
测试安装成功,运行命令pip3成功

2、报错信息:
FeatureNotFound: Couldn't find a tree builder with the features you requeste https://blog.csdn.net/qq_16546829/article/details/79405605
在报错代码中把函数参数中所有的"lxml"改成"html.parser"
#例子:
bs = BeautifulSoup(r, 'lxml').find(....
#改成 bs = BeautifulSoup(r, 'html.parser').find(....
html.parser是调用python解析器,但是没有解决lxml库不能用的问题啊
3、看到差别了吧,使用win10_url无法打开网页,你可以试试,所以问题就很严重了,我们根本打不开网页,
所以后续的爬虫工作根本从源头就已经宣告over了.....这也是一个小细节。

4、中文编码报错信息与解决方案:

这个报错信息很显然就是一贯的中文编码问题,让人很头疼,我加上了:
#!/home/pi/SmartHome/SMTP/ok'
#*_*coding:utf-8_*_
但依然没卵用,随即我百度找到一位网友写的文章如下:
https://blog.csdn.net/weixin_39221360/article/details/79525341
注意如果你的设备同时安装了 Python 2.x 和 Python 3.x,你需要用 python3 运行
Python 3.x:
$python3 myScript.py
当你安装包的时候,如果有可能安装到了 Python 2.x 而不是 Python 3.x 里,就需要使用:
$sudo python3 setup.py install
如果用 pip 安装,你还可以用pip3 安装 Python 3.x 版本的包:
$pip3 install beautifulsoup4
https://blog.csdn.net/DoctorLDQ/article/details/73230026
解决方法有三中:
1.在命令行修改,仅本会话有效:
1)通过>>>sys.getdefaultencoding()查看当前编码(若报错,先执行>>>import sys >>>reload(sys));
2)通过>>>sys.setdefaultencoding('utf8')设置编码
2.较繁琐,最有效
1)在程序文件中以下三句
import sys
reload(sys)
sys.setdefaultencoding('utf8')
3.修改Python本环境(推荐)
在Python的Lib\site-packages文件夹下新建一个sitecustomize.py文件,内容为:
#coding=utf8
import sys
reload(sys)
sys.setdefaultencoding('utf8')
重启Python解释器,发现编码已被设置为utf8,与方案二同效;这是因为系统在Python启动的时候,自行调用该文件,
设置系统的默认编码,而不需要每次都手动加上解决代码,属于一劳永逸的解决方法。
#在这里我是用的是以下方法,感觉很方便,但是最后一个我感觉很好一劳永逸不错不错,但是我没找着....
import sys
reload(sys)
sys.setdefaultencoding('utf8')
5、header的改变,这也是一处一定要注意的细节。
如何获取网页的header{ ...}方法我还是简单说一下吧,会的自行略过,去自己电脑打开的网页copy吧。
打开url,F12 然后 Ctrl+R ,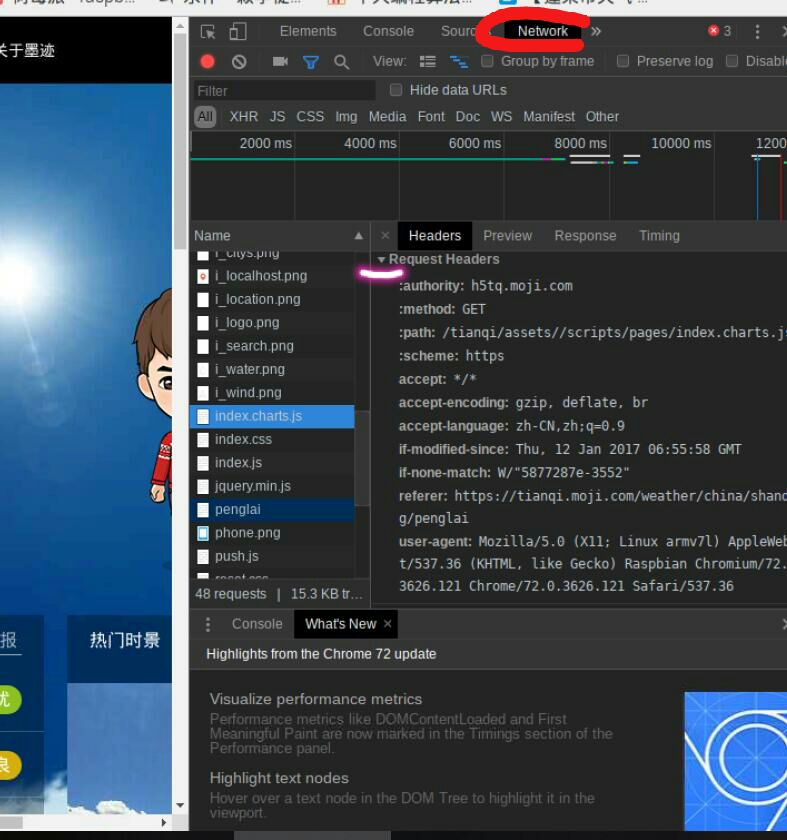
按照以下格式进行选取,写入我们的程序中。(不要漏掉逗号!!!!)
header = {
'authority':'h5tq.moji.com',
'accept':'image/webp,image/apng,image/*,*/*;q=0.8',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'cache-control':'no-cache',
'pragma':'no-cache',
'referer':'https://tianqi.moji.com/weather/china/shandong/penglai',
'user-agent':'Mozilla/5.0 (X11; Linux armv7l) AppleWebKit/537.36 (KHTML, like Gecko) Raspbian Chromium/72.0.3626.121 Chrome/72.0.3626.121 Safari/537.36'
}
6、....还没么,今下午几个小时整理的比较急 ,如果还有什么问题请留言评论或者私信我都可以。
#利用树莓派发送天气预报邮件
import time
import smtplib
import requests
import random
import socket
import bs4
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from bs4 import BeautifulSoup
from email.mime.text import MIMEText
from email.header import Header def get_content(url):
header = {
'authority':'h5tq.moji.com',
'accept':'image/webp,image/apng,image/*,*/*;q=0.8',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'cache-control':'no-cache',
'pragma':'no-cache',
'referer':'https://tianqi.moji.com/weather/china/shandong/penglai',
'user-agent':'Mozilla/5.0 (X11; Linux armv7l) AppleWebKit/537.36 (KHTML, like Gecko) Raspbian Chromium/72.0.3626.121 Chrome/72.0.3626.121 Safari/537.36'
}
timeout = random.choice(range(80, 180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'utf-8'
break
except socket.timeout as e:
print( '3:', e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print( '4:', e)
time.sleep(random.choice(range(20, 60)))
return rep.text def get_weather(url,data):
air_list = []
weather_list = []
#weather_status = []
soup = BeautifulSoup(data,'lxml')
div = soup.find('div',{'class' : 'forecast clearfix'}) air_quality = div.find('strong',class_='level_2').string #空气质量
date = div.find('a',href='https://tianqi.moji.com/today/china/shandong/penglai').string
wind_direction = div.find('em').string #风向
wind_grade = div.find('b').string #风速
ul = div.find('ul',{'class' : 'clearfix'}) ## 天气情况抽取 ##
a = []
li = ul.find_all('li')
j=0
#return li
for i in li:
j+=1
if j==2:
a = i
a = str(a).replace('\n','').replace('\t','').replace(' ','').replace("</li>","").replace('\r','')
a = a.replace('<li><span>','').replace('<imgalt=','').replace('src="https://h5tq.moji.com/tianqi/assets/images/weather/','')
a = a.replace('.png/></span>','').replace('.png"/></span>','').replace('"','').replace('\t','') for x in range(100,-1,-1):
#print("w{0}".format(x))
a = a.replace(("w{0}".format(x)),'') if(len(a)==2):
a = a[0:1]
if(len(a)==4):
a = a[0:2]
#print(a) for day in li:
if not isinstance(day,bs4.element.Tag):
date = day.find('a',href='https://tianqi.moji.com/today/china/shandong/penglai').string weather_list.append(day.string)
if not isinstance(day,bs4.element.Tag):
wind_direction = day.find('em').string
wind_grade = day.find('b').string Tempreture = weather_list[2]
air_quality =air_quality.replace("\n","").replace(' ','')
#air_quality = str(air_quality).replace('\n','').replace(' ','')
#print("data {0} Tempreture {1}".format(date,Tempreture))
return (" 时 间 : {}\n 天气情况: {}\n 温 度 : {}\n 风 向 : {}\n 风 速 : {}\n 空气质量: {}\n".format(date,a,Tempreture,wind_direction,wind_grade,air_quality)) def send_email(email):
'''
sender = input('From: ')
password = input('password: ')
smtp_server = input('SMTP_Server: ')
''' ## FROM ##
sender = 'wyl13****25@sohu.com'
sent_host = 'smtp.sohu.com'
sent_user = 'wyl13*****25@sohu.com'
sent_pass = '****密码****' ## TO ##
receivers = ['13****25@qq.com','2******09@qq.com'] #message = MIMEText("亲爱的,我现在来播报今天的蓬莱天气。\n(嗯...其实现在还只能看不能播)如下所示:\n 时 间| 天气情况 | 温 度 | 风 向 | 风 速 | 空气质量\n'{0}\n".format(result),'plain','utf-8')
message = MIMEText("亲爱的今天蓬莱天气是这样的呦 :\n{}\n".format(result),'plain','utf-8') ## JUST USE TO DISPLAY ##
message['From'] = Header('树莓派(From)','utf-8')
message['To'] = Header('win10(To)','utf-8')
Subject = "今天的天气预报详情,来自树莓派!"
message['Subject'] = Header(Subject,'utf-8') #标题
try:
server = smtplib.SMTP()
#server = smtplib.SMTP(sent_host,25)
print("SMTP complete") server.connect(sent_host,25)
print("connect complete") #server.set_debuglevel(1)
server.login(sent_user,sent_pass)
print("login complete") server.sendmail(sender,receivers[0],message.as_string())
print("邮件发送成功")
#server.quit() except smtplib.SMTPException:
print("Error:发生未知错误,无法发送邮件!") if __name__ == '__main__':
result =[]
#win10_url = 'http://tianqi.moji.com/weather/china/shandong/penglai'
url = 'https://tianqi.moji.com/weather/china/shandong/penglai'
data = get_content(url)
result = get_weather(url,data)
result = str(result).replace("\\r","").replace('\t','').replace('\r','').replace("\\n","")
print("result is \n{}\n".format(result))
#send_email(result)
最后测试结果如下:
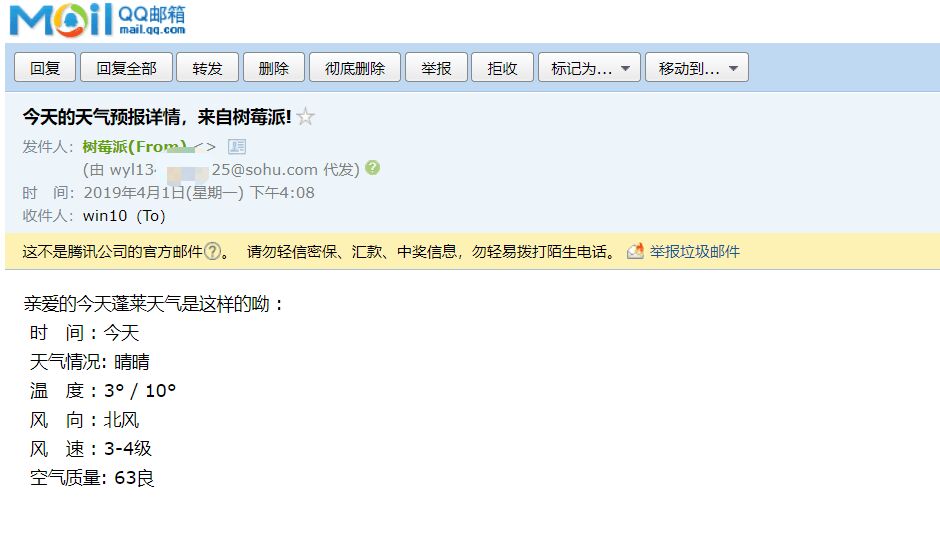
大家应该也看到了有个很明显的BUG就是晴晴,
但是经过我的测试,在python3下完全ok,毕竟3才是未来的霸主,2就不要花太多心思了。
我上面也有pip3的教程,安装好了,把我们所需的库安装到位,打开方式切换为python3IDLE否则默认都是python2IDLE
而且。。。而且python2中也没有运行结果没有输出,也许是因为python2 和 python3 的输出函数不一样所致,
python2 中print 没有括号,python3中更加严谨规范带有括号。

终于兑现了,舒心了不少....整理的不够到位的地方还请指正。
过一阵子再给大家更新一个带语音播报的邮件出来?我也不知道没想好,会分享给大家,敬请期待吧。
当然这篇教程只是用来学习,请勿进行商业活动甚至非法活动,切勿侵害他人权益,提前声明概不负责。
如果觉得我的文章还不错,关注一下,顶一下 ,我将会用心去创作更好的文章,敬请期待。
利用爬虫、SMTP和树莓派3B发送邮件&续集&(爬取墨迹天气预报信息)的更多相关文章
- 利用爬虫、SMTP和树莓派3B发送邮件(爬取墨迹天气预报信息)
-----------------------------------------学无止境----------------------------------------- 前言:大家好,欢迎来到誉雪 ...
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- 【图文详解】scrapy爬虫与动态页面——爬取拉勾网职位信息(2)
上次挖了一个坑,今天终于填上了,还记得之前我们做的拉勾爬虫吗?那时我们实现了一页的爬取,今天让我们再接再厉,实现多页爬取,顺便实现职位和公司的关键词搜索功能. 之前的内容就不再介绍了,不熟悉的请一定要 ...
- 爬虫入门(三)——动态网页爬取:爬取pexel上的图片
Pexel上有大量精美的图片,没事总想看看有什么好看的自己保存到电脑里可能会很有用 但是一个一个保存当然太麻烦了 所以不如我们写个爬虫吧(๑•̀ㅂ•́)و✧ 一开始学习爬虫的时候希望爬取pexel上的 ...
- 爬虫系列2:Requests+Xpath 爬取租房网站信息
Requests+Xpath 爬取租房网站信息 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
- 爬虫—Selenium爬取JD商品信息
一,抓取分析 本次目标是爬取京东商品信息,包括商品的图片,名称,价格,评价人数,店铺名称.抓取入口就是京东的搜索页面,这个链接可以通过直接构造参数访问https://search.jd.com/Sea ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图: 1.网页分析 (1)分析 URL 规律 我们首先使用 Chrome 浏览器打开 豆瓣电影 T ...
随机推荐
- iOS一个很好的内存检测工具
虽然Xcode提供了instrument来检测内存,但是使用起来怎么看都很麻烦.然后有一个很不错的内存泄露的检测工具MLeaksFinder,使用的话不需要注入任何代码,直接导入库就行了.出现泄露的时 ...
- [转]Python中下划线以及命名空间的意义
Python 用下划线作为变量前缀和后缀指定特殊变量/方法. 主要存在四种情形 1. 1. object # public 2. __object__ # special, python sys ...
- 解决pycharm无法导入本地包的问题
在用python写爬虫程序时,import 行无法通过,具体情况如下: pycharm运行程序后,程序pass了,但是出现了警告,如下图所示: 这是由于该程序不在根目录下,无法导入本地包,解决办法如下 ...
- HDU4825 Xor Sum
题意 给定一个集合后, 求一组查询中每个数和集合中任一元素异或的最大值. 题解 异或的规律是这样的 1 ^ 1 = 0, 0 ^ 0 = 0, 1 ^ 0 = 1, 0 ^ 1 = 1, 而最大值即是 ...
- HDU 1290 献给杭电五十周年校庆的礼物(面分割空间 求得到的最大空间数目)
传送门: 献给杭电五十周年校庆的礼物 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Other ...
- 课时53.video标签(掌握)
这节课来学习一下html5中新增的标签,我们先来看一下,html5中新增了哪些标签? 打开W3school的网页,点击参考手册中的HTML/HTML5标签,有一个按字母顺序排列的标签,但凡标签后面带有 ...
- Kubernetes对象模型
原文发表于https://www.fangzhipeng.com/kubernetes/2018/10/13/k8s-object-model/ 欢迎访问我的方志朋的博客 Kubernetes对象 在 ...
- 大专生自学iOS到找到工作的前前后后
先做个自我介绍,我13年考上一所很烂专科民办的学校,学的是生物专业,具体的学校名称我就不说出来献丑了.13年我就辍学了,我在那样的学校,一年学费要1万多,但是根本没有人学习,我实在看不到希望,我就退学 ...
- 暂存,本人博客有bug,正在全力修复。
当阳光洒满大地,当清晨的凝露如水滴滋润着世间万物,我就在这里.我在这里静静的看着这一切,这宁静的美好.耳边传来的英文歌曲.手里拿着的带着书香的书,时光倒流仿佛回到了多年前的清晨,那时的我每天读书背英语 ...
- Linux每日一命令:【00】总纲
Linux每日一命令更新频率为每周5篇. 文章结构如下: 简介 语法 选项 参数 常用实例 实用技巧(可选) 参考文档 文章目录如下: 2018-02-19 20:15 -- Linux每日一命令:[ ...