Selenium基础知识(8大元素定位概说)
1. By.name()
页面源码如下:
[html] :
<button id="gbqfba"aria-label="Google Search" name="btnK" class="gbqfba"><spanidspanid="gbqfsa">Google Search</span></button>
当我们要用name属性来引用这个button并点击它时,代码如下:
[java] :
public class SearchButtonByName {
public static void main(String[] args){
WebDriver driver = new FirefoxDriver();
driver.get("http://www.forexample.com");
WebElement searchBox =driver.findElement(By.name("btnK"));
searchBox.click();
}
}
2. By.id()
页面源码如下:
[html] :
<button id="gbqfba" aria-label="GoogleSearch" name="btnK" class="gbqfba"><spanidspanid="gbqfsa">Google Search</span></button>
要引用该button并点击它时,代码如下:
[java] :
1.public class SearchButtonById {
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. WebElement searchBox =driver.findElement(By.id("gbqfba"));
10.
11. searchBox.click();
12.
13. }
14.
15.}
3. By.tagName()
该方法可以通过元素的标签名称来查找元素。该方法跟之前两个方法的区别是,这个方法搜索到的元素通常不止一个,所以一般建议结合使用findElements方法来使用。比如我们现在要查找页面上有多少个button,就可以用button这个tagName来进行查找,代码如下:
[java] :
1.public class SearchPageByTagName{
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. List<WebElement> buttons =driver.findElements(By.tagName("button"));
10.
11. System.out.println(buttons.size()); //打印出button的个数
12.
13. }
14.
15.}
另外,在使用tagName方法进行定位时,还有一个地方需要注意的是,通常有些HTML元素的tagName是相同的,如下图(1)所示。

图(1)
从图中我们可以看到,单选框、复选框、文本框和密码框的元素标签都是input,此时单靠tagName无法准确地得到我们想要的元素,需要结合type属性才能过滤出我们要的元素。示例代码如下:
[java]:
1.public class SearchElementsByTagName{
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. List<WebElement> allInputs =driver.findElements(By.tagName("input"));
10.
11. //只打印所有文本框的值
12.
13. for(WebElement e: allInputs){
14.
15. if(e.getAttribute(“type”).equals(“text”)){
16.
17. System.out.println(e.getText().toString()); //打印出每个文本框里的值
18.
19. }
20.
21. }
22.
23.}
24.
25.}
4. By.className()
className属性是利用元素的css样式表所引用的伪类名称来进行元素查找的方法。对于任何HTML页面的元素来说,一般程序员或页面设计师会给元素直接赋予一个样式属性或者利用css文件里的伪类来定义元素样式,使元素在页面上显示时能够更加美观。一般css样式表可能会长成下面这个样子:
[css] :
1..buttonStyle{
2. width: 50px;
3. height: 50px;
4. border-radius: 50%;
5. margin: 0% 2%;
6.}
定义好后,就可以在页面元素中引用上述定义好的样式,如下:
[html] :
1.<buttonnamebuttonname="sampleBtnName" id="sampleBtnId" class="buttonStyle">I'mButton</button>
如果此时我们要通过className属性来查找该button并操作它的话,就可以使用className属性了,代码如下:
[java] :
1.public class SearchElementsByClassName{
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. WebElement searchBox =driver.findElement(By.className("buttonStyle"));
10.
11. searchBox.sendKeys("Hello, world");
12.
13. }
14.
15.}
注意:使用className来进行元素定位时,有时会碰到一个元素指定了若干个class属性值的“复合样式”的情况,如下面这个button:
[html] :
1.<button id="J_sidebar_login" class="btn btn_bigbtn_submit" type="submit">登录</button>
这个button元素指定了三个不同的css伪类名作为它的样式属性值,此时就必须结合后面要介绍的cssSelector方法来定位了,稍后会有详细例子。
5. By.linkText()
这个方法比较直接,即通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接。通常一个超文本链接会长成这个样子:<a href="/intl/en/about.html">About Google</a>。我们定位这个元素时,可以使用下面的代码进行操作:
[java] :
1.public class SearchElementsByLinkText{
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. WebElement aboutLink = driver.findElement(By.linkText("AboutGoogle"));
10.
11. aboutLink.click();
12.
13. }
14.
15.}
6. By.partialLinkText()
这个方法是上一个方法的扩展。当你不能准确知道超链接上的文本信息或者只想通过一些关键字进行匹配时,可以使用这个方法来通过部分链接文字进行匹配。代码如下:
[java] :
1.public class SearchElementsByPartialLinkText{
2.
3. public static void main(String[] args){
4.
5. WebDriver driver = new FirefoxDriver();
6.
7. driver.get("http://www.forexample.com");
8.
9. WebElement aboutLink = driver.findElement(By.partialLinkText("About"));
10.
11. aboutLink.click();
12.
13. }
14.
15.}
注意:使用这种方法进行定位时,可能会引起的问题是,当你的页面中不止一个超链接包含About时,findElement方法只会返回第一个查找到的元素,而不会返回所有符合条件的元素。如果你要想获得所有符合条件的元素,还是只能使用findElements方法。
7. By.xpath()
这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。在正式开始使用XPath进行定位前,我们先了解下什么是XPath。XPath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面,所以我们可以使用XPath的语法来定位页面元素。
假设我们现在以图(2)所示HTML代码为例,要引用对应的对象,XPath语法如下:
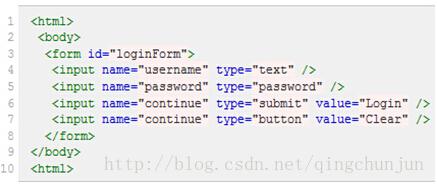
图(2)
绝对路径写法(只有一种),写法如下:
引用页面上的form元素(即源码中的第3行):/html/body/form[1]
这里要注意以下几点:
1. 元素的xpath绝对路径可通过firebug直接查询,一般不需要你手工去写。
2. 一般不推荐使用绝对路径的写法,因为一旦页面结构发生变化,该路径也随之失效,必须重新写。
3. 绝对路径以单/号表示,而下面要讲的相对路径则以//表示,这个区别非常重要。另外需要多说一句的是,当xpath的路径以/开头时,表示让Xpath解析引擎从文档的根节点开始解析。当xpath路径以//开头时,则表示让xpath引擎从文档的任意符合的元素节点开始进行解析。而当/出现在xpath路径中时,则表示寻找父节点的直接子节点,当//出现在xpath路径中时,表示寻找父节点下任意符合条件的子节点,不管嵌套了多少层级(这些下面都有例子,大家可以参照来试验)。弄清这个原则,就可以理解其实xpath的路径可以绝对路径和相对路径混合在一起来进行表示,想怎么玩就怎么玩。
下面是相对路径的引用写法:
查找页面根元素://
查找页面上所有的input元素://input
查找页面上第一个form元素内的直接子input元素(即只包括form元素的下一级input元素,使用绝对路径表示,单/号)://form[1]/input
查找页面上第一个form元素内的所有子input元素(只要在form元素内的input都算,不管还嵌套了多少个其他标签,使用相对路径表示,双//号)://form[1]//input
查找页面上第一个form元素内的最后一个input元素://form[1]//input[last()](注意:在xpath中没有first()这样的方法,用//form[1]//input[1]这种表示法就可以取第一个)
查找页面上第一个form元素://form[1]
查找页面上id为loginForm的form元素://form[@id='loginForm']
查找页面上具有name属性为username的input元素://input[@name='username']
查找页面上id为loginForm的form元素下的第一个input元素://form[@id='loginForm']/input[1](注意:在xpath中没有第0元素这样的表示方法,都是从1开始)
查找页面具有name属性为contiune并且type属性为button的input元素://input[@name='continue'][@type='button']
查找页面上id为loginForm的form元素下第4个input元素://form[@id='loginForm']/input[4]
Xpath功能很强大,所以也可以写得更加复杂一些,如下面图(3)的HTML源码。

图(3)
如果我们现在要引用id为“J_password”的input元素,该怎么写呢?我们可以像下面这样写:
[java] :
1.WebElement password = driver.findElement(By.xpath("//*[@id='J_login_form']/dl/dt/input[@id='J_password']"));
也可以写成:
[java] :
1.WebElement password =driver.findElement(By.xpath("//*[@id='J_login_form']/*/*/input[@id='J_password']"));
这里解释一下,其中//*[@id=’J_login_form’]这一段是指在根元素下查找任意id为J_login_form的元素,此时相当于引用到了form元素。后面的路径必须按照源码的层级依次往下写。因为我们要找的input元素包含在一个dt标签内,而dt又包含在dl标签内,所以中间必须写上dl和dt两层,才到input这层。当然我们也可以用*号省略具体的标签名称,但元素的层级关系必须体现出来,比如我们不能写成//*[@id='J_login_form']/input[@id='J_password'],这样肯定会报错的。
前面讲的都是xpath中基于准确元素属性的定位,其实xpath作为定位神器也可以用于模糊匹配。比如下面图(4)所示代码:

图(4)
这段代码中的“退出”这个超链接,没有标准id元素,只有一个rel和href,不是很好定位。不妨我们就用xpath的几种模糊匹配模式来定位它吧,主要有三种方式,举例如下。
a. 用contains关键字,定位代码如下:
[java] :
1.driver.findElement(By.xpath(“//a[contains(@href,‘logout’)]”));
这句话的意思是寻找页面中href属性值包含有logout这个单词的所有a元素,由于这个退出按钮的href属性里肯定会包含logout,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名。
b. 用start-with,定位代码如下:
[java] :
1.driver.findElement(By.xpath(“//a[starts-with(@rel, ‘nofo’)]));
这句的意思是寻找rel属性以nofo开头的a元素。其中@后面的rel可以替换成元素的任意其他属性。
c. 用Text关键字,定位代码如下:
[java] :
1.driver.findElement(By.xpath(“//*[text()=’退出’]));
这个方法可谓相当霸气啊。直接查找页面当中所有的退出二字,根本就不用知道它是个a元素了。这种方法也经常用于纯文字的查找。
另外,如果知道超链接元素的文本内容,也可以用
[java] :
1.driver.findElement(By.xpath(“//a[contains(text(), ’退出’)]));
这种方式一般用于知道超链接上显示的部分或全部文本信息时,可以使用。
最后,关于xpath这种定位方式,webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素,所以这是一个非常费时的操作,如果你的脚本中大量使用xpath做元素定位的话,将导致你的脚本执行速度大大降低,所以请慎用。
8. By.cssSelector()
cssSelector这种元素定位方式跟xpath比较类似,但执行速度较快,而且各种浏览器对它的支持都相当到位,所以功能也是蛮强大的。
下面是一些常见的cssSelector的定位方式:
定位id为flrs的div元素,可以写成:#flrs 注:相当于xpath语法的//div[@id=’flrs’]
定位id为flrs下的a元素,可以写成 #flrs > a 注:相当于xpath语法的//div[@id=’flrs’]/a
定位id为flrs下的href属性值为/forexample/about.html的元素,可以写成: #flrs > a[href=”/forexample/about.html”]
如果需要指定多个属性值时,可以逐一加在后面,如#flrs> input[name=”username”][type=”text”]。
明白基本语法后,我们来尝试用cssSelector方式来引用图(3)中选中的那个input对象,代码如下:
[java] view plaincopy
1.WebElement password =driver.findElement(By.cssSelector("#J_login_form>dl>dt>input[id=’J_password’]"));
同样必须注意层级关系,这个不能省略。
cssSelector还有一个用处是定位使用了复合样式表的元素,之前在第4种方式className里面提到过。现在我们就来看看如何通过cssSelector来引用到第4种方式中提到的那个button。button代码如下:
[html] :
1.<button id="J_sidebar_login"class="btn btn_big btn_submit" type="submit">登录</button>
cssSelector引用元素代码如下:
[java] :
1.driver.findElement(By.cssSelector("button.btn.btn_big.btn_submit"))
这样就可以顺利引用到使用了复合样式的元素了。
此外,cssSelector还有一些高级用法,如果熟练后可以更加方便地帮助我们定位元素,如我们可以利用^用于匹配一个前缀,$用于匹配一个后缀,*用于匹配任意字符。例如:
匹配一个有id属性,并且id属性是以”id_prefix_”开头的超链接元素:a[id^='id_prefix_']
匹配一个有id属性,并且id属性是以”_id_sufix”结尾的超链接元素:a[id$='_id_sufix']
匹配一个有id属性,并且id属性中包含”id_pattern”字符的超链接元素:a[id*='id_pattern']
Selenium基础知识(8大元素定位概说)的更多相关文章
- 基础知识--:before伪元素和:after伪元素
http://book.51cto.com/art/201108/285688.htm 3.7 替换指定位置 大家都知道before和after是前.后的意思.但是奇怪的是,CSS中的:before ...
- Selenium基础知识(元素定位的调试)
对一个不能直接定位的元素来说,调试是很常见的事,所以这里也简单总结了一下. 调试定位元素的工具很多,介绍也多,就不一一介绍了.下次有时间再补充.以下是我常用调试的方法(浏览器自带的控制台调试,仅介绍一 ...
- Selenium基础知识(三)元素判断
一.由于有些页面加载完后,某些元素还没有加载,这样就会导致异常,脚本稳定性变差 为了解决这个问题,selenium提供了WebDriverWait以及implicitly_wait()等待 WebDr ...
- [Selenium With C#基础教程] Lesson-02 Web元素定位
作者:Surpassme 来源:http://www.jianshu.com/p/cfd4ed1daabd 声明:本文为原创文章,如需转载请在文章页面明显位置给出原文链接,谢谢. 使用Selenium ...
- 1、selenium 8大元素定位方式
元素定位方式: id name css class_name tag_name partial_link link_text : driver. find_element_by_link_text(& ...
- Selenium:WebDriver简介及元素定位
参考内容:官方API文档,下载链接:http://download.csdn.net/detail/kwgkwg001/4004500 虫师:<selenium2自动化测试实战-基于python ...
- 跟浩哥学自动化测试Selenium -- 浏览器的基本操作与元素定位(3)
浏览器的基本操作与元素定位 通过上一章学习,我们已经学会了如何设置驱动路径,如何创建浏览器对象,如何打开一个网站,接下来我们要进行一些复杂的操作比如先打开百度首页,在打开博客园,网页后退,前进等等,甚 ...
- Selenium 基础知识
被测产品是B/S 结构,那么推荐selenium selenium 并不是单纯的一个工具,他是一组工具的集合 1. selenium IDE 是嵌入到Firefox浏览器中的一个插件,实现简单的浏览器 ...
- 【转】【selenium+Python WebDriver】之元素定位不到解决办法
感谢: 煜妃的<Python+Selenium定位不到元素常见原因及解决办法(报:NoSuchElementException)> ClassName定位报错问题:<[Python] ...
随机推荐
- Ajax发送GET、POST请求和响应XML数据案例
1.新建工程 新建一个java web工程,新建一个Servlet文件 AServlet.java,用于返回get和post请求. public class AServlet extends Http ...
- Halcon学习笔记——条形码的定位与识别
一维码的原理与结构 条码基本原理是利用条纹和间隔或宽窄条纹(间隔)构成二进制的”0“和”1“,反映的是某种信息. 一维条码数据结构,分四个区域.组成分别为静区.起始/终止符.校验符.数据符. 一维条码 ...
- 三、thymeleaf的使用
1.简介 thymleaf是一个基于html的页面模板,springboot极力推荐使用它,代替jsp. API地址:https://www.thymeleaf.org/doc/tutorials/3 ...
- Spring cloud ReadTimeout 问题解决
今天使用Spring cloud @FeignClient 调用远程服务的时候,出现readTimeout问题,通过找资料解决方式如下 在Spring.properties 配置文件中添加如下属性解决 ...
- clean code 第一章笔记
我们都曾有过这样的经历:自己写的烂程序竟然可以运行,然后就认为能运行的烂代码总比什么都没有强.还会有这样的想法:总有一天我会修改它.但是,LeBlanc(勒布朗)法则表示:稍后等于永不(Later e ...
- iview框架下,modal内容过长,select选项位置不对
问题 modal组件中内容过长,超过一屏,有滚动条后,里面包含的select组件选项内容,位置会不对 解决 在使用select的时候添加transfer属性
- <head>标签和它的小伙伴们
head标签是HTML文档中最基本的必须元素之一(body:对,还有我): <html> <head> <title>文档的标题</title> < ...
- Android setTag()/getTag()
View中的setTag(Onbect)表示给View添加一个格外的数据,以后可以用getTag()将这个数据取出来. 可以用在多个Button添加一个监听器,每个Button都设置不同的setTag ...
- MySQL数据库备份与还原
备份数据库 1.使用mysqldump命令备份 备份一个数据库:mysqldump -u 用户名 -p密码 数据库名 [表名1,表名2...]>备份文件路径及名字.sql 如 ...
- php模拟post提交
<?php $url = "xxxxx"; // 用户名 $loginName = ''; // 密码 $pwd = ''; // service $serviceName ...