7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析
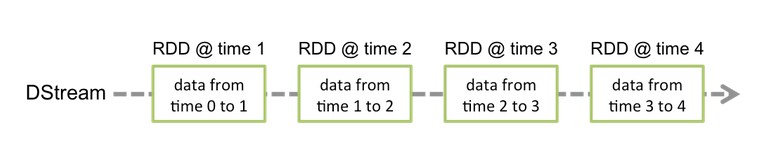
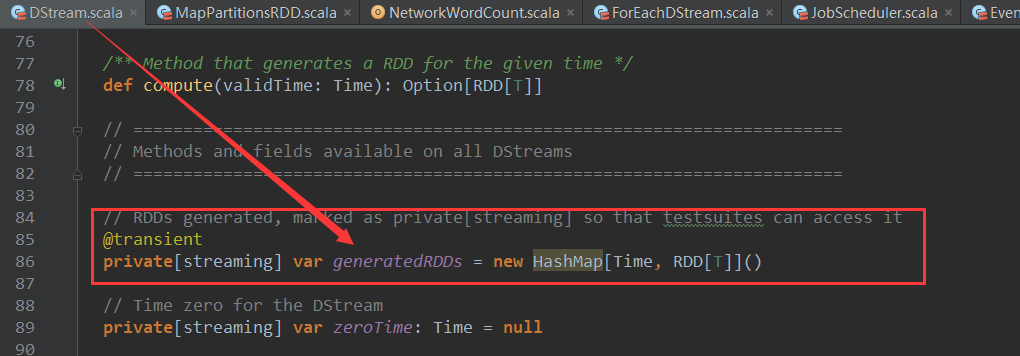
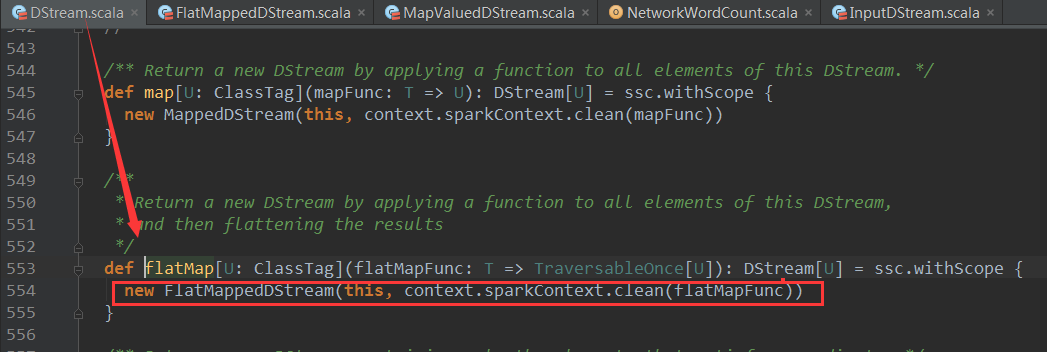
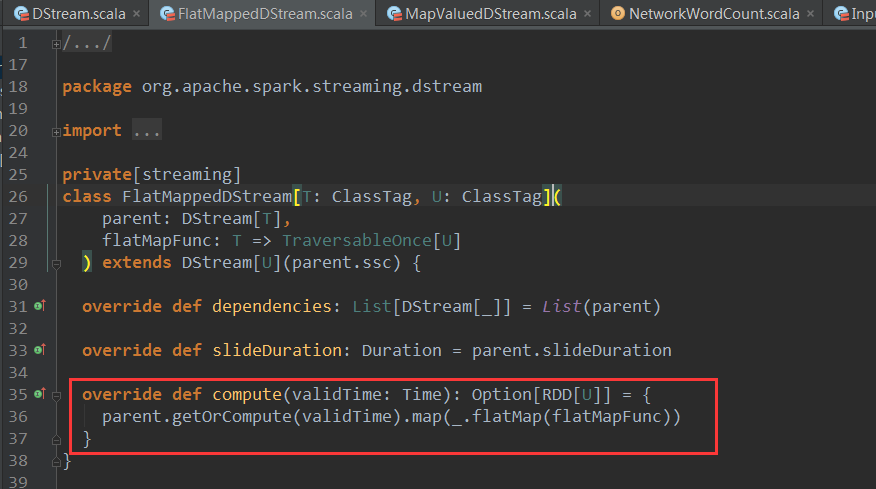
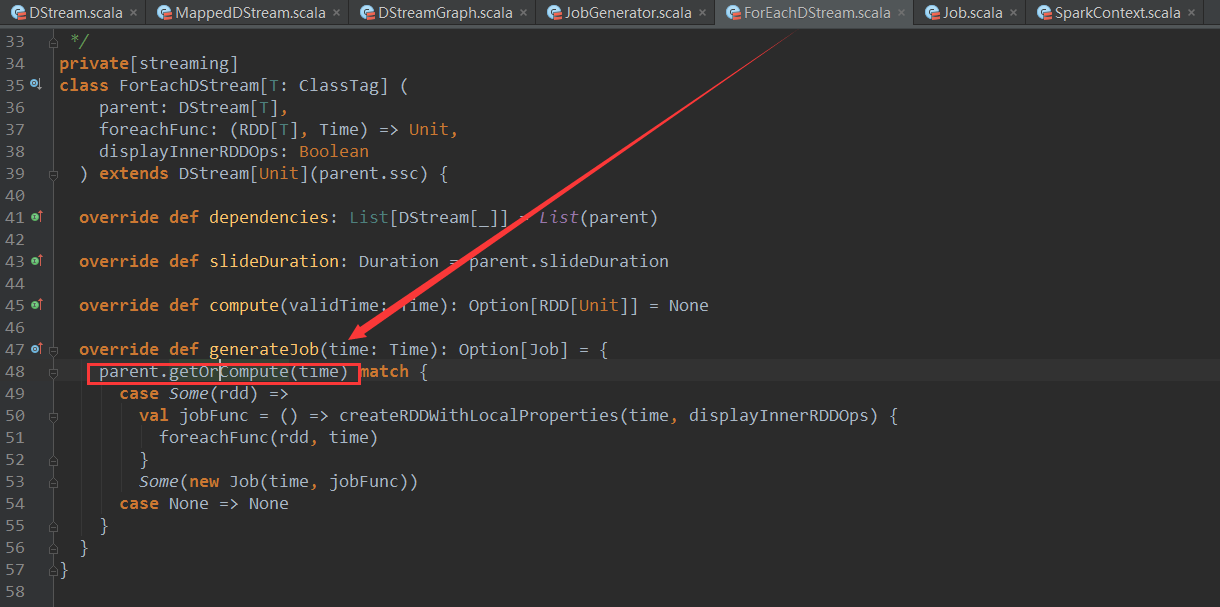
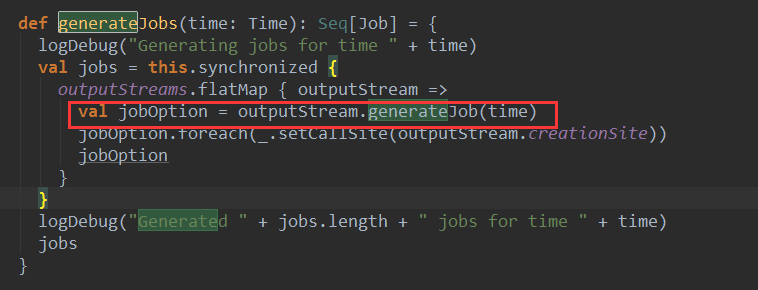
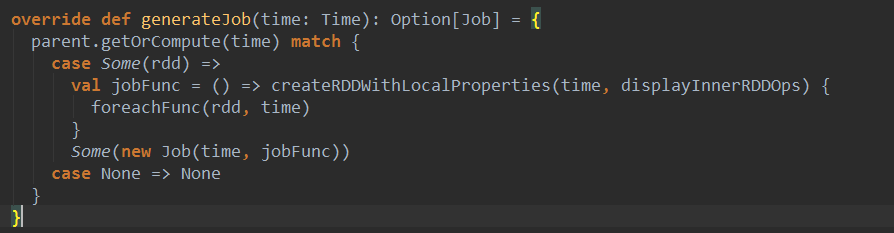
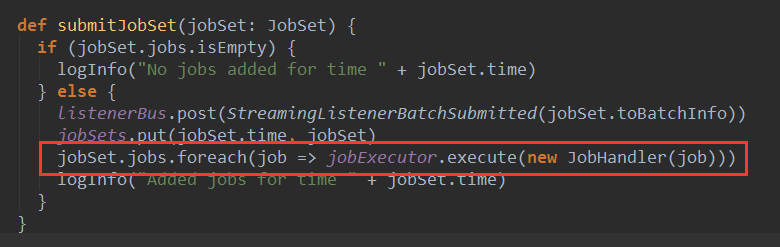
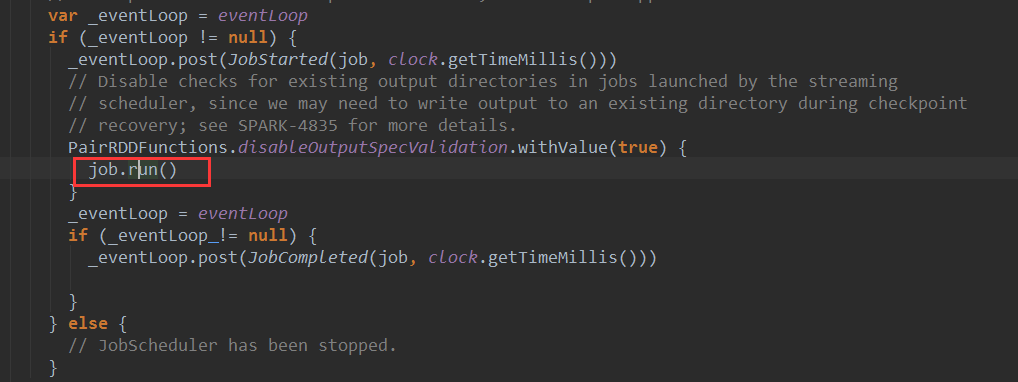
上篇博客讨论了Spark Streaming 程序动态生成Job的过程,并留下一个疑问: JobScheduler将动态生成的Job提交,然后调用了Job对象的run方法,最后run方法的调用是如何触发RDD的Action操作,从而真正触发Job的执行的呢?本文就具体讲解这个问题。
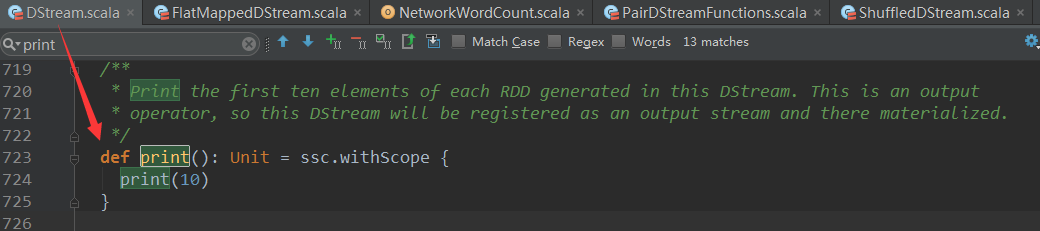
object WordCount{def main(args:Array[String]):Unit={val sparkConf =newSparkConf().setMaster("local[4]").setAppName("WordCount")val ssc =newStreamingContext(sparkConf,Seconds(1))val lines = ssc.socketTextStream("localhost",9999)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x =>(x,1)).reduceByKey(_+_)wordCounts.print()ssc.start()ssc.awaitTermination()}}



| Output Operation | Meaning |
|---|---|
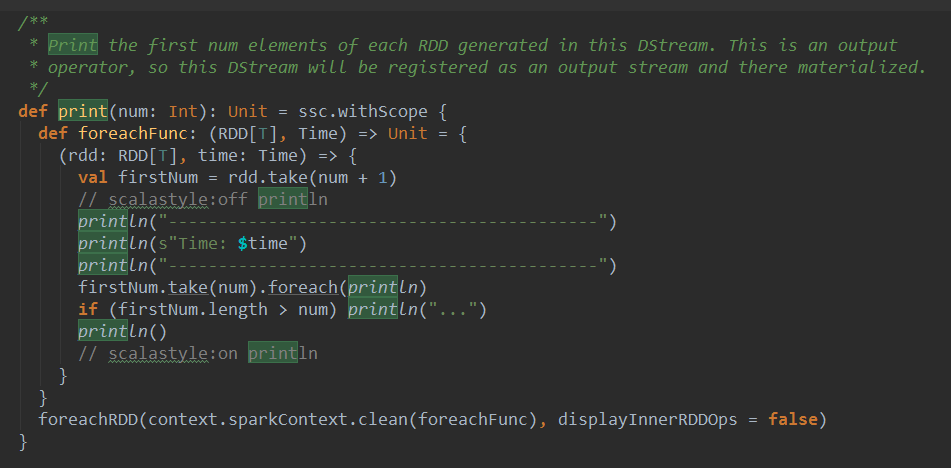
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based onprefix and suffix: "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: "prefix-TIME_IN_MS[.suffix]". Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |


7.spark Streaming 技术内幕 : 从DSteam到RDD全过程解析的更多相关文章
- 9. Spark Streaming技术内幕 : Receiver在Driver的精妙实现全生命周期彻底研究和思考
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序需要不断接收新数据,然后进行业务逻辑 ...
- Spark streaming技术内幕6 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作,S ...
- 6.Spark streaming技术内幕 : Job动态生成原理与源码解析
原创文章,转载请注明:转载自 周岳飞博客(http://www.cnblogs.com/zhouyf/) Spark streaming 程序的运行过程是将DStream的操作转化成RDD的操作, ...
- 贯通Spark Streaming JobScheduler内幕实现和深入思考
本节主要内容: 一.SparkStreaming Job生成深度思考 二.SparkStreaming Job生成源码解析 JobScheduler的地位非常的重要,所有的关键都在JobSchedul ...
- 16.Spark Streaming源码解读之数据清理机制解析
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 本期内容: 一.Spark Streaming 数据清理总览 二.Spark Streami ...
- 10.Spark Streaming源码分析:Receiver数据接收全过程详解
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 在上一篇中介绍了Receiver的整体架构和设计原理,本篇内容主要介绍Receiver在 ...
- Spark技术内幕:Sort Based Shuffle实现解析
在Spark 1.2.0中,Spark Core的一个重要的升级就是将默认的Hash Based Shuffle换成了Sort Based Shuffle,即spark.shuffle.manager ...
- 9.Spark Streaming
Spark Streaming 1 Why Apache Spark 2 关于Apache Spark 3 如何安装Apache Spark 4 Apache Spark的工作原理 5 spark弹性 ...
- Spark Streaming的优化之路—从Receiver到Direct模式
作者:个推数据研发工程师 学长 1 业务背景 随着大数据的快速发展,业务场景越来越复杂,离线式的批处理框架MapReduce已经不能满足业务,大量的场景需要实时的数据处理结果来进行分析.决 ...
随机推荐
- [net tools]nethogs
nethogs 按照从大到小排列占用网络流量的进程 还可以用jnettop察看,总的流量
- 求前n项正整数的倒数和
求前n项正整数的倒数和 前n项正整数的和是一个发散的序列,学过高等数学的这个都知道.所以它没有一个精确的公式,但是近似的公式是有的: 1 + 1/2 + 1/3 + …… + 1/n ≍ ln n + ...
- 解决华为手机用rem单位,内容超出屏幕宽度问题
在H5手机页面上,用rem单位布局,配合js计算出一个根节点的font-size(原理是屏幕宽度乘以一个固定比例,如1/100),之后页面中所有的px全都换算成了rem单位来写,优点是能适配各种不同屏 ...
- [洛谷P1338] 末日的传说
洛谷题目链接:末日的传说 题目描述 只要是参加jsoi活动的同学一定都听说过Hanoi塔的传说:三根柱子上的金片每天被移动一次,当所有的金片都被移完之后,世界末日也就随之降临了. 在古老东方的幻想乡, ...
- Spring Boot 启动报错:LoggingFailureAnalysisReporter
17:57:19: Executing task 'bootRun'... Parallel execution with configuration on demand is an incubati ...
- 【BZOJ3884】上帝与集合的正确用法 [欧拉定理]
上帝与集合的正确用法 Time Limit: 5 Sec Memory Limit: 128 MB[Submit][Status][Discuss] Description Input 第一行一个T ...
- css优先级机制
所谓CSS优先级,即是指CSS样式在浏览器中被解析的先后顺序. 1.important >(内联样式)Inline style >(内部样式)Internal style sheet ...
- 【Python学习笔记】Pandas库之DataFrame
1 简介 DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表. 或许说它可能有点像matlab的矩阵,但是matlab的矩阵只能放数值型值(当然matla ...
- C++学习之路(二):引用
(1)引用是变量的别名 引用的基本定义格式:类型 &引用名 = 变量名 例如:int a = 1; int &b = a,这里b是a的别名,b与a都指向了同一块内存单元. 对于引用而言 ...
- Linux 入门记录:四、Linux 系统常用命令
一.日期时间 命令 date 查看.设置当前系统时间: date -u 格林威治时间 date %Y-%m-%d 显示格式化的时间 date -s "23:00" 使用 -s 参数 ...