C 封装一个通用链表 和 一个简单字符串开发库
引言
这里需要分享的是一个 简单字符串库和 链表的基库,代码也许用到特定技巧.有时候回想一下,
如果我读书的时候有人告诉我这些关于C开发的积淀, 那么会走的多直啊.刚参加工作的时候做桌面开发,
服务是C++写,界面是C#写.那时候刚进去评级我是中级,因为他问我关于系统锁和信号量都答出来.开发一段
时间,写C#也写的很溜.后面招我那个人让我转行就写C++和php,那时候就开始学习C++有关知识.
后面去四川工作了,开发安卓,用eclipse + java语法 + android jdk,开发前端,用起来,我的感受,都相似,就是api名字
有点长. 都是那老套路,后来四川公司黄了. 辗转又来了北京做C系列还有php开发. 说了这么多, 我想说下面几个问题.
1. 你写的是 C# 和 java吗,还只是.net/jdk的积木 , 写了那么多这样的代码,你感到疑惑吗?
2.假如你也感到过疑惑, 推荐去看看 Linux程序开发 或 unix环境编程, 网络编程
//2.1 不推荐认真学C++, 学了好多,看了好多书,还是不明觉历,觉得是在杂耍! 如果喜欢C,把市面上好的C书都看一遍,敲一遍!
3. 因为随着年纪增长,效率太重要了, 需要去找到学到那些一招鲜吃遍天的东西, 其它的让年起人去拼搏吧.
有时候想想,做软件开发,初中就够了,高中绰绰有余,大学研究生都暴遣天物. 大家觉得呢.
又扯了一会儿蛋, 今天分享的还是很有用的,但是感觉没接触这样黑科技的还是有点难. 或者说封装一个框架还是有难度的,
或者,哪怕再小的一个库封装完毕都是不容易的.而我们分享的是封装库的库. 个人比较水,打脸要轻打.
用到的资源
list 测试demo http://download.csdn.net/detail/wangzhione/9428243
入行第一篇博文 C的回归(国内超一线) http://blog.codingnow.com/2007/09/c_vs_cplusplus.html
再扯一点, 2015 北京平均工资最高的三个职业 IT 特殊服务业 电子设备. 如果你穷你真的需要 认真学习编程,不要太沉迷于框架的学习中.
真的 人穷就应该多编程, 别人抢红包,你 需要写代码, , ,
这篇博文分享的框架后面都加了一点内容, 也简单补充一下. 内容很多基本都是垃圾. 首先 以一个 不区分大小写的函数压马路.
- /*
- * 这是个不区分大小写的比较函数
- * ls : 左边比较字符串
- * rs : 右边比较字符串
- * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
- */
- extern int str_icmp(const char* ls, const char* rs);
构造如下, 看完这里基本就可以关闭,毕竟后面更啰嗦!
- /*
- * 这是个不区分大小写的比较函数
- * ls : 左边比较字符串
- * rs : 右边比较字符串
- * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
- */
- int
- str_icmp(const char* ls, const char* rs)
- {
- int l, r;
- if(!ls || !rs)
- return (int)ls - (int)rs;
- do {
- if((l=*ls++)>='a' && l<='z')
- l -= 'a' - 'A';
- if((r=*rs++)>='a' && r<='z')
- r -= 'a' - 'A';
- } while(l && l==r);
- return l-r;
- }
到这里 基本上就值了. 学到上面函数 也算温故C 基础吧! O(∩_∩)O哈哈~
前言
终于到这里了,扯的有点多. 首先来看一下今天主要写的通用链表的接口,看设计
- #ifndef _H_LIST
- #define _H_LIST
- #include <schead.h>
- /*
- * 这个万能单链表库 前提所有结点都是堆上分配的,设计的比较老了,能用
- *注意
- * 1.使用的时候,需要加上 _LIST_HEAD; 宏
- * 2.创建的第一句话就是 list head = NULL; 开始从空链表开始list的生涯
- */
- struct __lnode {
- struct __lnode* next;
- };
- // 不多说了一定放在想使用链表结构的结构体头部
- #define _LIST_HEAD \
- struct __lnode __ln;
- // 简单链表结构, 当你使用这个链表的时候 需要 list_t head = NULL; 开始使用之旅
- typedef void* list_t;
- /*
- * 采用头查法插入结点, 第一使用需要 list_t head = NULL;
- *返回 _RT_OK 表示成功!
- * ph : 指向头结点的指针
- * node : 待插入的结点对象
- */
- extern int list_add(list_t* ph, void* node);
- /*
- * 链表中查找函数,查找失败返回NULL,查找成功直接返回那个结点,推荐不要乱改,否则就崩了.
- *如果需要改的话,推荐 用 list_findpop, 找到并弹出
- * h : 链表头结点
- * cmp : 查找的比较函数
- * left : cmp(left, right) 用的左结点
- * : 返回查找的结点对象
- */
- extern void* list_find(list_t h, icmp_f cmp, const void* left);
- /*
- * 查找到要的结点,并弹出,需要你自己回收
- * ph : 指向头结点的指针
- * cmp : 比较函数,将left同 *ph中对象按个比较
- * left : cmp(left, x) 比较返回 0 >0 <0
- * : 找到了退出/返回结点, 否则返回NULL
- */
- extern void* list_findpop(list_t *ph, icmp_f cmp, const void* left);
- /*
- * 这里获取当前链表长度, 推荐调用一次就记住len
- * h : 当前链表的头结点
- * : 返回 链表长度 >=0
- */
- extern int list_len(list_t h);
- /*
- * 查找索引位置为idx的结点,找不见返回NULL
- * h : 当前结点
- * idx : 查找的索引值[0,len)
- * : 返回查到的结点,如果需要删除的推荐调用 list_pop(&h, idx);
- */
- extern void* list_get(list_t h, int idx);
- /*
- * 按照索引弹出并返回结点, 需要自己回收这个结点 推荐 free(list_pop...);
- * ph : 指向链表结点的指针
- * idx : 弹出的索引
- * return : 无效的弹出,返回NULL
- */
- void* list_pop(list_t* ph, int idx);
- /*
- * 返回结点node 的上一个结点,如果node = NULL, 返回最后一个结点
- * h : 当前链表结点
- * node : 待查找的结点信息
- * return : 返回查找到的结点,不存在返回NULL
- */
- void* list_front(list_t h, void* node);
- /*
- * 这个宏推荐不使用, 主要返回结点n的下一个结点
- * 第一种使用方法 node->next = (void*)list_node(n), 另一种是 list_node(n) = node;
- * n : 当前结点
- */
- #define list_next(n) \
- (((struct __lnode*)n)->next)
- /*
- * 和 list_add 功能相似,但是插入位置在尾巴那
- * ph : 待插入结点的指针
- * node : 待插入的当前结点
- */
- int list_addlast(list_t* ph, void* node);
- /*
- * 在链表的第idx索引处插入结点,也必须需要 list_t head = NULL; 在idx过大的时候
- *插入尾巴处,如果<0直接返回 _RT_EP. 成功了返回 _RT_OK
- * ph : 指向头结点的指针
- * idx : 结点的索引处
- * node : 待插入的结点
- */
- int list_addidx(list_t* ph, int idx, void* node);
- /*
- * 这里的销毁函数,只有这些数据都是栈上的才推荐这么做,会自动让其指向NULL
- * ph : 指向当前链表结点的指针
- */
- void list_destroy(list_t* ph);
- #endif // !_H_LIST
这里接口使用的 extern声明的希望外部直接使用, 没有extern的外部可以使用,属于扩展功能.
对于上面接口 简单的测试 代码如下
- #include <list.h>
- struct lint {
- _LIST_HEAD;
- int node;
- };
- //简单创建函数
- static struct lint* __lint_new(int node)
- {
- struct lint* ln = malloc(sizeof(struct lint));
- if(ln){
- ln->node = node;
- }
- return ln;
- }
- //简单打印函数
- static void __lint_puts(list_t head)
- {
- int len = list_len(head);
- int i;
- printf("当前链表中数据结果如下:");
- for(i=; i<len; ++i){
- struct lint* tl = list_get(head, i);
- printf("%d ", tl->node);
- }
- putchar('\n');
- }
- /*
- * 这里简单测试一下 关于链表的常用接口
- */
- int main(int argc, char* argv[])
- {
- list_t head = NULL;
- int arrs[] = { , , , , , , , };
- int i;
- //这里添加结点
- for(i=; i<sizeof(arrs)/sizeof(*arrs); ++i)
- list_add(&head, __lint_new(arrs[i]));
- __lint_puts(head);
- //这里删除一个结点
- free(list_pop(&head, ));
- __lint_puts(head);
- //删除第二个结点
- free(list_pop(&head, ));
- __lint_puts(head);
- list_destroy(&head);
- return ;
- }
测试了几个简答接口. 注释比较详细, 写的也比较简单相对于Linux内核的数据结构而言. 这里是个开门红.
临摹几遍都能理解C接口的简单设计.
正文
其实呀上面代码主要突出一个设计, 实现而言还是比较容易,因为结构有了,算法就能够写好了. 例如 获取某个结点的源码
- /*
- * 这里获取当前链表长度, 推荐调用一次就记住len
- * h : 当前链表的头结点
- * : 返回 链表长度 >=0
- */
- int list_len(list_t h)
- {
- int len = ;
- while(h){
- ++len;
- h = list_next(h);
- }
- return len;
- }
很基础也容易理解, 大多数代码其实结构设计好实现也就是时间问题, 也等同于业务了. 精妙的东西没有那么多, 魔鬼藏在细节里.向那些这个池那个组,都名次解释.
很普通.现在我们只谈设计, 最后会给出完整的代码. 同样还有一种结构, (状态不好,加班太多了,写的很水望见谅,因为很多东西说出来还是做不出来,做出来说的不好.)
看下面关于简单字符串设计代码
- #ifndef _H_TSTRING
- #define _H_TSTRING
- #include <schead.h>
- //------------------------------------------------简单字符串辅助操作----------------------------------
- /*
- * 主要采用jshash 返回计算后的hash值
- * 不冲突率在 80% 左右还可以, 不要传入NULL
- */
- extern unsigned str_hash(const char* str);
- //------------------------------------------------简单文本字符串辅助操作----------------------------------
- #ifndef _STRUCT_TSTRING
- #define _STRUCT_TSTRING
- //简单字符串结构,并定义文本字符串类型tstring
- struct tstring {
- char* str; //字符串实际保存的内容
- int len; //当前字符串大小
- int size; //字符池大小
- };
- typedef struct tstring* tstring;
- #endif // !_STRUCT_TSTRING
- //文本串栈上创建内容,不想用那些技巧了,就这样吧
- #define TSTRING_CREATE(var) \
- struct tstring var = { NULL, , }
- #define TSTRING_DESTROY(var) \
- free(var.str)
- /*
- * tstring 的创建函数, 会根据str创建一个 tstring结构的字符串
- *
- * str : 待创建的字符串
- *
- * ret : 返回创建好的字符串,如果创建失败返回NULL
- */
- extern tstring tstring_create(const char* str);
- /*
- * tstring 完全销毁函数
- * tstr : 指向tsting字符串指针量的指针
- */
- extern void tstring_destroy(tstring* tstr);
- /*
- * 向简单文本字符串tstr中添加 一个字符c
- * tstr : 简单字符串对象
- * c : 待添加的字符
- * ret : 返回状态码 见 schead 中 _RT_EB 码等
- */
- extern int tstring_append(tstring tstr, int c);
- /*
- * 向简单文本串中添加只读字符串
- * tstr : 文本串
- * str : 待添加的素材串
- * ret : 返回状态码主要是 _RT_EP _RT_EM
- */
- extern int tstring_appends(tstring tstr, const char* str);
- //------------------------------------------------简单文件辅助操作----------------------------------
- /*
- * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL.
- * 需要事后使用 tstring_destroy(&ret); 销毁这个字符串对象
- * path : 文件路径
- * ret : 返回创建好的字符串内容,返回NULL表示读取失败
- */
- extern tstring file_malloc_readend(const char* path);
- /*
- * 文件写入,没有好说的,会返回 _RT_EP _RT_EM _RT_OK
- * path : 文件路径
- * str : 待写入的字符串
- * ret : 返回写入的结果
- */
- extern int file_writes(const char* path, const char* str);
- /*
- * 文件追加内容, 添加str内同
- * path : 文件路径
- * str : 待追加的文件内同
- * : 返回值,主要是 _RT_EP _RT_EM _RT_OK 这些状态
- */
- extern int file_append(const char* path, const char* str);
- #endif // !_H_TSTRING
这个串可以用在读取一个大串,主要解决的问题是内存空间分配问题,还可以用.最大浪费就50%.
现在我们简单说一下具体实现,其实一看
- #ifndef _STRUCT_TSTRING
- #define _STRUCT_TSTRING
- //简单字符串结构,并定义文本字符串类型tstring
- struct tstring {
- char* str; //字符串实际保存的内容
- int len; //当前字符串大小
- int size; //字符池大小
- };
- typedef struct tstring* tstring;
- #endif // !_STRUCT_TSTRING
全部明白了. 就是 len表现当前str中保存的长度, size表现当前str的容量.分配代码如下
- //简单分配函数,智力一定会分配内存的, len > size的时候调用这个函数
- static int __tstring_realloc(tstring tstr, int len)
- {
- int size = tstr->size;
- for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= )
- ;
- //分配内存
- char *nstr = realloc(tstr->str, size);
- if (NULL == nstr) {
- SL_NOTICE("realloc(tstr->str:0x%p, size:%d) is error!", tstr->str, size);
- return _RT_EM;
- }
- tstr->str = nstr;
- tstr->size = size;
- return _RT_OK;
- }
len是新的str大小.后面展现 全部的演示代码.
- #include <tstring.h>
- #include <sclog.h>
- /*
- * 主要采用jshash 返回计算后的hash值
- * 不冲突率在 80% 左右还可以, 不要传入NULL
- */
- unsigned
- str_hash(const char* str)
- {
- size_t i, h = strlen(str), sp = (h >> ) + ;
- unsigned char* ptr = (unsigned char*)str;
- for (i = h; i >= sp; i -= sp)
- h ^= ((h<<) + (h>>) + ptr[i-]);
- return h ? h : ;
- }
- /*
- * tstring 的创建函数, 会根据str创建一个 tstring结构的字符串
- *
- * str : 待创建的字符串
- *
- * ret : 返回创建好的字符串,如果创建失败返回NULL
- */
- tstring
- tstring_create(const char* str)
- {
- tstring tstr = calloc(, sizeof(struct tstring));
- if (NULL == tstr) {
- SL_NOTICE("calloc is sizeof struct tstring error!");
- return NULL;
- }
- tstring_appends(tstr, str);
- return tstr;
- }
- /*
- * tstring 完全销毁函数
- * tstr : 指向tsting字符串指针量的指针
- */
- void tstring_destroy(tstring* tstr)
- {
- if (tstr && *tstr) { //展现内容
- free((*tstr)->str);
- free(*tstr);
- *tstr = NULL;
- }
- }
- //文本字符串创建的度量值
- #define _INT_TSTRING (32)
- //简单分配函数,智力一定会分配内存的, len > size的时候调用这个函数
- static int __tstring_realloc(tstring tstr, int len)
- {
- int size = tstr->size;
- for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= )
- ;
- //分配内存
- char *nstr = realloc(tstr->str, size);
- if (NULL == nstr) {
- SL_NOTICE("realloc(tstr->str:0x%p, size:%d) is error!", tstr->str, size);
- return _RT_EM;
- }
- tstr->str = nstr;
- tstr->size = size;
- return _RT_OK;
- }
- /*
- * 向简单文本字符串tstr中添加 一个字符c
- * tstr : 简单字符串对象
- * c : 待添加的字符
- * ret : 返回状态码 见 schead 中 _RT_EM 码等
- */
- int tstring_append(tstring tstr, int c)
- {
- //不做安全检查
- int len = tstr->len + ; // c + '\0' 而len只指向 字符串strlen长度
- //需要进行内存分配,唯一损失
- if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len)))
- return _RT_EM;
- tstr->len = --len;
- tstr->str[len - ] = c;
- tstr->str[len] = '\0';
- return _RT_OK;
- }
- /*
- * 向简单文本串中添加只读字符串
- * tstr : 文本串
- * str : 待添加的素材串
- * ret : 返回状态码主要是 _RT_EP _RT_EM
- */
- int tstring_appends(tstring tstr, const char* str)
- {
- int len;
- if (!tstr || !str || !*str) {
- SL_NOTICE("check param '!tstr || !str || !*str'");
- return _RT_EP;
- }
- len = tstr->len + strlen(str) + ;
- if ((len > tstr->size) && (_RT_EM == __tstring_realloc(tstr, len)))
- return _RT_EM;
- //这里复制内容
- strcpy(tstr->str + tstr->len, str);
- tstr->len = len - ;
- return _RT_OK;
- }
- //------------------------------------------------简单文件辅助操作----------------------------------
- /*
- * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL.
- * 需要事后使用 tstring_destroy(&ret); 销毁这个字符串对象
- * path : 文件路径
- * ret : 返回创建好的字符串内容,返回NULL表示读取失败
- */
- tstring file_malloc_readend(const char* path)
- {
- int c;
- tstring tstr;
- FILE* txt = fopen(path, "r");
- if (NULL == txt) {
- SL_NOTICE("fopen r path = '%s' error!", path);
- return NULL;
- }
- //这里创建文件对象,创建失败直接返回
- if ((tstr = tstring_create(NULL)) == NULL) {
- fclose(txt);
- return NULL;
- }
- //这里读取文本内容
- while ((c = fgetc(txt))!=EOF)
- if (_RT_OK != tstring_append(tstr, c))
- break;
- fclose(txt);//很重要创建了就要释放,否则会出现隐藏的句柄bug
- return tstr;
- }
- /*
- * 文件写入,没有好说的,会返回 _RT_EP _RT_EM _RT_OK
- * path : 文件路径
- * str : 待写入的字符串
- * ret : 返回写入的结果
- */
- int file_writes(const char* path, const char* str)
- {
- FILE* txt;
- //检查参数问题
- if (!path || !str) {
- SL_NOTICE("check is '!path || !str'");
- return _RT_EP;
- }
- if ((txt = fopen(path, "w")) == NULL) {
- SL_NOTICE("fopen w path = '%s' error!", path);
- return _RT_EF;
- }
- //这里写入信息
- fputs(str, txt);
- fclose(txt);
- return _RT_OK;
- }
- /*
- * 文件追加内容, 添加str内同
- * path : 文件路径
- * str : 待追加的文件内同
- * : 返回值,主要是 _RT_EP _RT_EM _RT_OK 这些状态
- */
- int
- file_append(const char* path, const char* str)
- {
- FILE* txt;
- //检查参数问题
- if (!path || !str) {
- SL_NOTICE("check is '!path || !str'");
- return _RT_EP;
- }
- if ((txt = fopen(path, "a")) == NULL) {
- SL_NOTICE("fopen a path = '%s' error!", path);
- return _RT_EF;
- }
- //这里写入信息
- fputs(str, txt);
- fclose(txt);
- return _RT_OK;
- }
相比云风的那个玩具要简单的多,而且针对性很强,就为了大字符串. 转存用.还可以一试.
到这里就到了今天一个主题. 主要测试list demo. 首先看运行的结果图
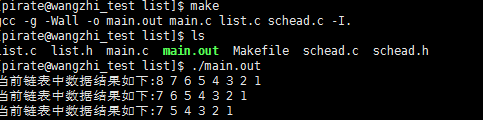
首先看Makefile 文件
- main.out:main.c list.c schead.c
- gcc -g -Wall -o $@ $^ -I.
再看schead.h 文件
- #ifndef _H_CHEAD
- #define _H_CHEAD
- #include <stdio.h>
- #include <stdlib.h>
- #include <stdbool.h>
- #include <errno.h>
- #include <string.h>
- #include <time.h>
- #include <stdint.h>
- #include <stddef.h>
- /*
- * 1.0 错误定义宏 用于判断返回值状态的状态码 _RF表示返回标志
- * 使用举例 :
- int flag = scconf_get("pursue");
- if(flag != _RT_OK){
- sclog_error("get config %s error! flag = %d.", "pursue", flag);
- exit(EXIT_FAILURE);
- }
- * 这里是内部 使用的通用返回值 标志
- */
- #define _RT_OK (0) //结果正确的返回宏
- #define _RT_EB (-1) //错误基类型,所有错误都可用它,在不清楚的情况下
- #define _RT_EP (-2) //参数错误
- #define _RT_EM (-3) //内存分配错误
- #define _RT_EC (-4) //文件已经读取完毕或表示链接关闭
- #define _RT_EF (-5) //文件打开失败
- /*
- * 1.1 定义一些 通用的函数指针帮助,主要用于基库的封装中
- * 有构造函数, 释放函数, 比较函数等
- */
- typedef void* (*pnew_f)();
- typedef void(*vdel_f)(void* node);
- // icmp_f 最好 是 int cmp(const void* ln,const void* rn); 标准结构
- typedef int(*icmp_f)();
- /*
- * 1.2 最简单的 判断字符串是否为空白字符代码, true为真
- */
- #define sh_isspace(c) \
- (c==' '||c=='\t'||c=='\n'||c=='\r'||c=='\v'||c=='\f')
- /*
- * 2.0 如果定义了 __GNUC__ 就假定是 使用gcc 编译器,为Linux平台
- * 否则 认为是 Window 平台,不可否认宏是丑陋的
- */
- #if defined(__GNUC__)
- //下面是依赖 Linux 实现,等待毫秒数
- #include <unistd.h>
- #include <sys/time.h>
- #define SLEEPMS(m) \
- usleep(m * )
- #else
- // 这里创建等待函数 以毫秒为单位 , 需要依赖操作系统实现
- #include <Windows.h>
- #include <direct.h> // 加载多余的头文件在 编译阶段会去掉
- #define inline __inline //附加一个内联函数宏
- #define rmdir _rmdir
- /**
- * Linux sys/time.h 中获取时间函数在Windows上一种移植实现
- **tv : 返回结果包含秒数和微秒数
- **tz : 包含的时区,在window上这个变量没有用不返回
- ** : 默认返回0
- **/
- extern int gettimeofday(struct timeval* tv, void* tz);
- //为了解决 不通用功能
- #define localtime_r(t, tm) localtime_s(tm, t)
- #define SLEEPMS(m) \
- Sleep(m)
- #endif /*__GNUC__ 跨平台的代码都很丑陋 */
- //3.0 浮点数据判断宏帮助, __开头表示不希望你使用的宏
- #define __DIFF(x, y) ((x)-(y)) //两个表达式做差宏
- #define __IF_X(x, z) ((x)<z&&(x)>-z) //判断宏,z必须是宏常量
- #define EQ(x, y, c) EQ_ZERO(__DIFF(x,y), c) //判断x和y是否在误差范围内相等
- //3.1 float判断定义的宏
- #define _FLOAT_ZERO (0.000001f) //float 0的误差判断值
- #define EQ_FLOAT_ZERO(x) __IF_X(x,_FLOAT_ZERO) //float 判断x是否为零是返回true
- #define EQ_FLOAT(x, y) EQ(x, y, _FLOAT_ZERO) //判断表达式x与y是否相等
- //3.2 double判断定义的宏
- #define _DOUBLE_ZERO (0.000000000001) //double 0误差判断值
- #define EQ_DOUBLE_ZERO(x) __IF_X(x,_DOUBLE_ZERO) //double 判断x是否为零是返回true
- #define EQ_DOUBLE(x,y) EQ(x, y, _DOUBLE_ZERO) //判断表达式x与y是否相等
- //4.0 控制台打印错误信息, fmt必须是双引号括起来的宏
- #ifndef CERR
- #define CERR(fmt, ...) \
- fprintf(stderr,"[%s:%s:%d][error %d:%s]" fmt "\r\n",\
- __FILE__, __func__, __LINE__, errno, strerror(errno),##__VA_ARGS__)
- #endif/* !CERR */
- //4.1 控制台打印错误信息并退出, t同样fmt必须是 ""括起来的字符串常量
- #ifndef CERR_EXIT
- #define CERR_EXIT(fmt,...) \
- CERR(fmt,##__VA_ARGS__),exit(EXIT_FAILURE)
- #endif/* !ERR */
- #ifndef IF_CERR
- /*
- *4.2 if 的 代码检测
- *
- * 举例:
- * IF_CERR(fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP), "socket create error!");
- * 遇到问题打印日志直接退出,可以认为是一种简单模板
- * code : 要检测的代码
- * fmt : 必须是""括起来的字符串宏
- * ... : 后面的参数,参照printf
- */
- #define IF_CERR(code, fmt, ...) \
- if((code) < ) \
- CERR_EXIT(fmt, ##__VA_ARGS__)
- #endif //!IF_CERR
- //5.0 获取数组长度,只能是数组类型或""字符串常量,后者包含'\0'
- #ifndef LEN
- #define LEN(arr) \
- (sizeof(arr)/sizeof(*(arr)))
- #endif/* !ARRLEN */
- //6.0 程序清空屏幕函数
- #ifndef CONSOLE_CLEAR
- #ifndef _WIN32
- #define CONSOLE_CLEAR() \
- system("printf '\ec'")
- #else
- #define CONSOLE_CLEAR() \
- system("cls")
- #endif/* _WIN32 */
- #endif /*!CONSOLE_CLEAR*/
- //7.0 置空操作
- #ifndef BZERO
- //v必须是个变量
- #define BZERO(v) \
- memset(&v,,sizeof(v))
- #endif/* !BZERO */
- //9.0 scanf 健壮的
- #ifndef SAFETY_SCANF
- #define SAFETY_SCANF(scanf_code,...) \
- while(printf(__VA_ARGS__),scanf_code){\
- while(getchar()!='\n');\
- puts("输入出错,请按照提示重新操作!");\
- }\
- while(getchar()!='\n')
- #endif /*!SAFETY_SCANF*/
- //10.0 简单的time帮助宏
- #ifndef TIME_PRINT
- #define TIME_PRINT(code) {\
- clock_t __st,__et;\
- __st=clock();\
- code\
- __et=clock();\
- printf("当前代码块运行时间是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\
- }
- #endif /*!TIME_PRINT*/
- //11.0 等待的宏 这里 已经处理好了
- #define _STR_PAUSEMSG "请按任意键继续. . ."
- extern void sh_pause(void);
- #ifndef INIT_PAUSE
- # ifdef _DEBUG
- # define INIT_PAUSE() atexit(sh_pause)
- # else
- # define INIT_PAUSE() (void) /* 别说了,都重新开始吧 */
- # endif
- #endif/* !INIT_PAUSE */
- //12.0 判断是大端序还是小端序,大端序返回true
- extern bool sh_isbig(void);
- /**
- * sh_free - 简单的释放内存函数,对free再封装了一下
- **可以避免野指针
- **pobj:指向待释放内存的指针(void*)
- **/
- extern void sh_free(void** pobj);
- /**
- * 获取 当前时间串,并塞入tstr中长度并返回
- ** 使用举例
- char tstr[64];
- puts(gettimes(tstr, LEN(tstr)));
- **tstr : 保存最后生成的最后串
- **len : tstr数组的长度
- ** : 返回tstr首地址
- **/
- extern int sh_times(char tstr[], int len);
- #endif/* ! _H_CHEAD */
主要是跨平台的一些帮助宏,开发中用到的通用宏.具体schead.c实现如下
- #include <schead.h>
- //简单通用的等待函数
- void
- sh_pause(void)
- {
- rewind(stdin);
- printf(_STR_PAUSEMSG);
- getchar();
- }
- //12.0 判断是大端序还是小端序,大端序返回true
- bool
- sh_isbig(void)
- {
- static union {
- unsigned short _s;
- unsigned char _cs[sizeof(unsigned short)];
- } __ut = { };
- return __ut._cs[] == ;
- }
- /**
- * sh_free - 简单的释放内存函数,对free再封装了一下
- **可以避免野指针
- **@pobj:指向待释放内存的指针(void*)
- **/
- void
- sh_free(void** pobj)
- {
- if (pobj == NULL || *pobj == NULL)
- return;
- free(*pobj);
- *pobj = NULL;
- }
- #if defined(_MSC_VER)
- /**
- * Linux sys/time.h 中获取时间函数在Windows上一种移植实现
- **tv : 返回结果包含秒数和微秒数
- **tz : 包含的时区,在window上这个变量没有用不返回
- ** : 默认返回0
- **/
- int
- gettimeofday(struct timeval* tv, void* tz)
- {
- time_t clock;
- struct tm tm;
- SYSTEMTIME wtm;
- GetLocalTime(&wtm);
- tm.tm_year = wtm.wYear - ;
- tm.tm_mon = wtm.wMonth - ; //window的计数更好写
- tm.tm_mday = wtm.wDay;
- tm.tm_hour = wtm.wHour;
- tm.tm_min = wtm.wMinute;
- tm.tm_sec = wtm.wSecond;
- tm.tm_isdst = -; //不考虑夏令时
- clock = mktime(&tm);
- tv->tv_sec = (long)clock; //32位使用,接口已经老了
- tv->tv_usec = wtm.wMilliseconds * ;
- return _RT_OK;
- }
- #endif
- /**
- * 获取 当前时间串,并塞入tstr中C长度并返回
- ** 使用举例
- char tstr[64];
- puts(gettimes(tstr, LEN(tstr)));
- **tstr : 保存最后生成的最后串
- **len : tstr数组的长度
- ** : 返回tstr首地址
- **/
- int
- sh_times(char tstr[], int len)
- {
- struct tm st;
- time_t t = time(NULL);
- localtime_r(&t, &st);
- return (int)strftime(tstr, len, "%F %X", &st);
- }
后面是list.c的具体实现了
- #include <list.h>
- /*
- * 采用头查法插入结点, 第一使用需要 list_t head = NULL;
- *返回 _RT_OK 表示成功!
- * ph : 指向头结点的指针
- * node : 待插入的结点对象
- */
- int
- list_add(list_t* ph, void* node)
- {
- if (ph == NULL || node == NULL){
- CERR("list_add 检查到(pal == NULL || node == NULL)!");
- return _RT_EP;
- }
- list_next(node) = *ph;
- *ph = node;
- return _RT_OK;
- }
- /*
- * 链表中查找函数,查找失败返回NULL,查找成功直接返回那个结点,推荐不要乱改,否则就崩了.
- *如果需要改的话,推荐 用 list_findpop, 找到并弹出
- * h : 链表头结点
- * cmp : 查找的比较函数
- * left : cmp(left, right) 用的左结点
- * : 返回查找的结点对象
- */
- void*
- list_find(list_t h, icmp_f cmp, const void* left)
- {
- struct __lnode* head;
- if(cmp == NULL || left == NULL){
- CERR("list_find 检查到(cmp == NULL || left == NULL)!");
- return NULL;
- }
- //找到结果直接结束
- for(head = h; head; head = head->next)
- if(cmp(left, head) == )
- break;
- return head;
- }
- /*
- * 查找到要的结点,并弹出,需要你自己回收
- * ph : 指向头结点的指针
- * cmp : 比较函数,将left同 *ph中对象按个比较
- * left : cmp(left, x) 比较返回 0 >0 <0
- * : 找到了退出/返回结点, 否则返回NULL
- */
- void*
- list_findpop(list_t *ph, icmp_f cmp, const void* left)
- {
- struct __lnode *head, *tmp;
- if((!ph) || (!cmp) || (!left) || !(head = *ph)){
- CERR("check find {(!ph) || (!cmp) || (!left) || !(head = *ph)}!");
- return NULL;
- }
- //头部检测
- if(cmp(left, head) == ){
- *ph = head->next;
- return head;
- }
- //后面就是普通的
- while((tmp = head->next)){
- if(cmp(left, tmp) == ){
- head->next = tmp->next;
- break;
- }
- head = tmp;
- }
- return tmp; //仍然没有找见
- }
- /*
- * 这里获取当前链表长度, 推荐调用一次就记住len
- * h : 当前链表的头结点
- * : 返回 链表长度 >=0
- */
- int list_len(list_t h)
- {
- int len = ;
- while(h){
- ++len;
- h = list_next(h);
- }
- return len;
- }
- /*
- * 查找索引位置为idx的结点,找不见返回NULL
- * h : 当前结点
- * idx : 查找的索引值[0,len)
- * : 返回查到的结点,如果需要删除的推荐调用 list_pop(&h, idx);
- */
- void*
- list_get(list_t h, int idx)
- {
- if(h==NULL || idx < ){
- CERR("check is {h==NULL || idx < 0}");
- return NULL;
- }
- //主要查找函数,代码还是比较精简的还是值得学习的
- while(h){
- if(idx-- == )
- return h;
- h = list_next(h);
- }
- if(idx > )
- CERR("check is idx >= length!, idx-length=%d.", idx);
- return NULL;
- }
- /*
- * 按照索引弹出并返回结点, 需要自己回收这个结点 推荐 free(list_pop...);
- * ph : 指向链表结点的指针
- * idx : 弹出的索引
- * return : 无效的弹出,返回NULL
- */
- void*
- list_pop(list_t* ph, int idx)
- {
- struct __lnode *head, *front;//第一个是要找的结点,后面是它的前驱结点
- if((!ph) || (idx<) || !(head=*ph)){
- CERR("check is {(!ph) || (idx<0) || !(head=*ph)}");
- return NULL;
- }
- for(front = NULL; head && idx>; --idx){
- front = head;
- head = head->next;
- --idx;
- }
- if(idx>){
- CERR("check is idx>length, idx-length = %d.", idx);
- return NULL;
- }
- //下面就是找到的请况,返回结果
- if(front == NULL)
- *ph = head->next;
- else
- front->next = head->next;
- return head;
- }
- /*
- * 返回结点node 的上一个结点,如果node = NULL, 返回最后一个结点
- * h : 当前链表结点
- * node : 待查找的结点信息
- * return : 返回查找到的结点,不存在返回NULL
- */
- void*
- list_front(list_t h, void* node)
- {
- struct __lnode* head = h; //直接跑到崩溃同strcpy
- while(head->next && head->next != node)
- head = head->next;
- return head->next == node ? head : NULL;
- }
- /*
- * 和 list_add 功能相似,但是插入位置在尾巴那
- * ph : 待插入结点的指针
- * node : 待插入的当前结点
- */
- int
- list_addlast(list_t* ph, void* node)
- {
- struct __lnode* head;
- if(!ph || !node){
- CERR("check is {!ph || !node}! not nothing in it!");
- return _RT_EP;
- }
- list_next(node) = NULL;//将这个结点的置空
- if(!(head=*ph)){ //插入的是头结点直接返回
- *ph = node;
- return _RT_OK;
- }
- while(head->next)
- head = head->next;
- head->next = node;
- return _RT_OK;
- }
- /*
- * 在链表的第idx索引处插入结点,也必须需要 list_t head = NULL; 在idx过大的时候
- *插入尾巴处,如果<0直接返回 _RT_EP. 成功了返回 _RT_OK
- * ph : 指向头结点的指针
- * idx : 结点的索引处
- * node : 待插入的结点
- */
- int
- list_addidx(list_t* ph, int idx, void* node)
- {
- struct __lnode* head;
- if(!ph || idx< || !node){ //以后可能加入 idx < 0的尾巴插入细则
- CERR("check is {!ph || idx<0 || !node}! Don't naughty again!");
- return _RT_EP;
- }
- //插入做为头结点
- if(!(head=*ph) || idx == ){
- list_next(node) = *ph;
- *ph = node;
- return _RT_OK;
- }
- while(head->next && idx>){
- --idx;
- head = head->next;
- }
- list_next(node) = head->next;
- head->next = node;
- return _RT_OK;
- }
- /*
- * 这里的销毁函数,只有这些数据都是栈上的才推荐这么做,会自动让其指向NULL
- * ph : 指向当前链表结点的指针
- */
- void
- list_destroy(list_t* ph)
- {
- struct __lnode *head, *next;
- if((!ph) || !(head=*ph))
- return;
- do{ //do 循环可以省略一次判断,但是有点丑陋
- next = head->next;
- free(head);
- }while((head=next));
- *ph = NULL;
- }
关于list写的比较多,也有一点简单理解,上面虽然简陋,但是很精简,很指导不知道朋友学习使用,很通用的实在库. 到这里我们的一些都
这么随意的介绍完了.
再次分享个人学习习惯,别人说的太多,还是不懂,直接让我看代码就可以了,每次都是对着代码敲明白了.当然老外的书说的很明白,不得不服.
一下就懂了. 每一个大功能都是一个个小模块组成了, 没经过坑坑洼洼, 自己都不相信自己可以. 不管怎么选择都很公平,需要是 用 高付出, 在第8号当铺典当
你想要的东西.
共勉.希望的我的家人常快乐, 儿子在外对不住您们了, 目送飞云,一切安好!

后记
错误是难免的,欢迎交流技术. 其实这个框架整体代码去年早就写好了, 后面有了点项目感悟,重新构建一下,提升性能,
就简单分享在这,值得和我一样菜的人学习交流. 设计很重要,但绝壁不是设计模式. 拜~,有机会 下次再分享感悟.
C 封装一个通用链表 和 一个简单字符串开发库的更多相关文章
- 封装一个通用递归算法,使用TreeIterator和TreeMap来简化你的开发工作。
在实际工作中,你肯定会经常的对树进行遍历,并在树和集合之间相互转换,你会频繁的使用递归. 事实上,这些算法在逻辑上都是一样的,因此可以抽象出一个通用的算法来简化工作. 在这篇文章里,我向你介绍,我封装 ...
- 封装一个通用的PopupWindow
上篇文章是关于建造者设计模式的,今天顺便封装一个通用的 PopupWindow 来实践一下, 同时也方便以后使用 PopupWindow,本文将从下面几个方面来介绍 PopupWindow 及其封装, ...
- C 构造一个 简单配置文件读取库
前言 最近看到这篇文章, json引擎性能对比报告 http://www.oschina.net/news/61942/cpp-json-compare?utm_source=tuicool 感觉技术 ...
- 一步一步教你从零开始写C语言链表---构建一个链表
版权声明:本文为博主原创文章,如有需要,请注明转载地址:http://blog.csdn.net/morixinguan.若是侵权用于商业用途,请联系博主,否则将追究责任 https://blog ...
- 【算法】C++用链表实现一个箱子排序附源代码详解
01 箱子排序 1.1 什么是分配排序? 分配排序的基本思想:排序过程无须比较关键字,而是通过"分配"和"收集"过程来实现排序.它们的时间复杂度可达到线性阶:O ...
- 编写一个通用的Makefile文件
1.1在这之前,我们需要了解程序的编译过程 a.预处理:检查语法错误,展开宏,包含头文件等 b.编译:*.c-->*.S c.汇编:*.S-->*.o d.链接:.o +库文件=*.exe ...
- Linux C编程学习之开发工具3---多文件项目管理、Makefile、一个通用的Makefile
GNU Make简介 大型项目的开发过程中,往往会划分出若干个功能模块,这样可以保证软件的易维护性. 作为项目的组成部分,各个模块不可避免的存在各种联系,如果其中某个模块发生改动,那么其他的模块需要相 ...
- LeetCode 笔记系列六 Reverse Nodes in k-Group [学习如何逆转一个单链表]
题目:Given a linked list, reverse the nodes of a linked list k at a time and return its modified list. ...
- 写一个ajax程序就是如此简单
写一个ajax程序就是如此简单 ajax介绍: 1:AJAX全称为Asynchronous JavaScript and XML(异步JavaScript和XML),指一种创建交互式网页应用的网页开发 ...
随机推荐
- 【bzoj4720】[NOIP2016]换教室 期望dp
题目描述 对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程.在可以选择的课程中,有2n节课程安排在n个时间段上.在第i(1≤i≤n)个时间段上,两节内容相同的课程同时在不同的 ...
- 【刷题】BZOJ 4259 残缺的字符串
Description 很久很久以前,在你刚刚学习字符串匹配的时候,有两个仅包含小写字母的字符串A和B,其中A串长度为m,B串长度为n.可当你现在再次碰到这两个串时,这两个串已经老化了,每个串都有不同 ...
- [洛谷P4139]上帝与集合的正确用法
题目大意:多次询问,每次给你$p$询问$2^{2^{2^{\dots}}}\bmod p$ 题解:扩展欧拉定理,求出$\varphi(p)$即可.因为$2^{2^{2^{\dots}}}>> ...
- PowerDesigner 快捷键
一般快捷键 快捷键 说明 F4 打开检查模型窗口,检查模型 F5 如果图窗口内的图改变过大小,恢复为原有大小即正常大小 F6 放大图窗口内的图 F7 缩小图窗口内的图 F8 在图窗口内中查看全部图内容 ...
- ACE线程管理机制-线程的创建与管理
转载于:http://www.cnblogs.com/TianFang/archive/2006/12/04/581369.html 有过在不同的操作系统下用c++进行过多线程编程的朋友对那些线程处理 ...
- POJ3468:A Simple Problem with Integers(线段树模板)
A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Total Submissions: 149972 ...
- mysql的concat用法
问题提出:mybatis的mapper文件中的模糊查询: mysql CONCAT()函数用于将多个字符串连接成一个字符串,是最重要的mysql函数之一,下面就将为您详细介绍mysql CONCAT( ...
- bzoj 4724 [POI2017]Podzielno 二分+模拟
[POI2017]Podzielno Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 364 Solved: 160[Submit][Status][ ...
- java removeAll和重写equals、hashcode引起的性能问题
问题背景: 上周发现了一个spark job的执行时间从原来的10-15分钟延迟到了7个小时!wtf,这是出了什么事引起了这么大的性能问题!! 立马查看job的运行日志,发现多次运行都是在某一个固定的 ...
- c# txt 文件上传、写入TXT文件、创建图形验证码
asp.net mvc 图片上传 html 在使用包含文件上传控件的表单时,必须使用 enctype="multipart/form-data" 属性 <form encty ...