使用pandas筛选出指定列值所对应的行
在pandas中怎么样实现类似mysql查找语句的功能:
select * from table where column_name = some_value;
pandas中获取数据的有以下几种方法:
- 布尔索引
- 位置索引
- 标签索引
- 使用API
假设数据如下:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})

布尔索引
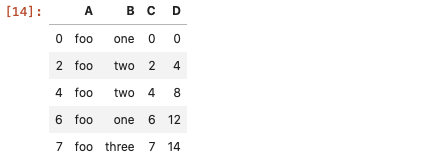
该方法其实就是找出每一行中符合条件的真值(true value),如找出列A中所有值等于foo
df[df['A'] == 'foo'] # 判断等式是否成立
位置索引
使用iloc方法,根据索引的位置来查找数据的。这个例子需要先找出符合条件的行所在位置
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask) # 返回的是array([0, 2, 4, 6, 7])
df.iloc[pos]
#常见的iloc用法
df.iloc[:3,1:3]

标签索引
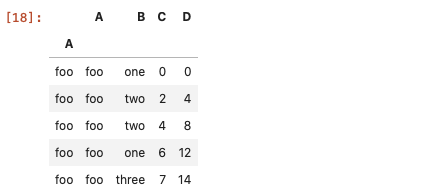
如何DataFrame的行列都是有标签的,那么使用loc方法就非常合适了。
df.set_index('A', append=True, drop=False).xs('foo', level=1) # xs方法适用于多重索引DataFrame的数据筛选
# 更直观点的做法
df.index=df['A'] # 将A列作为DataFrame的行索引
df.loc['foo', :]
# 使用布尔
df.loc[df['A']=='foo']
使用API
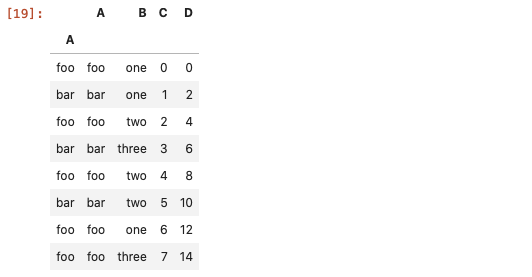
pd.DataFrame.query方法在数据量大的时候,效率比常规的方法更高效。
df.query('A=="foo"')
# 多条件
df.query('A=="foo" | A=="bar"')
数据提取不止前面提到的情况,第一个答案就给出了以下几种常见情况:
1、筛选出列值等于标量的行,用==
df.loc[df['column_name'] == some_value]
2、筛选出列值属于某个范围内的行,用isin
df.loc[df['column_name'].isin(some_values)] # some_values是可迭代对象
3、多种条件限制时使用&,&的优先级高于>=或<=,所以要注意括号的使用
df.loc[(df['column_name'] >= A) & (df['column_name'] <= B)]
4、筛选出列值不等于某个/些值的行
df.loc[df['column_name'] != 'some_value']
df.loc[~df['column_name'].isin('some_values')] #~取反
如果你觉得我的文章还可以,可以关注我的微信公众号,查看更多实战文章:Python爬虫实战之路
也可以扫描下面二维码,添加我的微信公众号

使用pandas筛选出指定列值所对应的行的更多相关文章
- 【452】pandas筛选出表中满足另一个表所有条件的数据
参考:pandas筛选出表中满足另一个表所有条件的数据 参考:pandas:匹配两个dataframe 使用 pd.merge 来实现 on 表示查询的 columns,如果都有 id,那么这是很好的 ...
- jquery实现对象数组 筛选出每条记录中的特定属性字段 及根据某个属性值筛选出指定的元素
jquery实现对象数组 筛选出每条记录中的特定属性字段 直接上图: 源码: /** * 对后端返回的数据,筛选出符合报表的列项,多余的列项去除 */ function filterParams(da ...
- 如何从两个List中筛选出相同的值
问题 现有社保卡和身份证若干,想要匹配筛选出一一对应的社保卡和身份证. 转换为List socialList,和List idList,从二者中找出匹配的社保卡. 模型 创建社保卡类 /** * @a ...
- Pandas 删除指定列中为NaN的行
定位要删除的行 需求:删除指定列中NaN所在行. 如下图,’open‘ 列中有一行为NaN,定位到它,然后删除. 定位: df[np.isnan(df['open'])].index # 这样即可定位 ...
- pandas 如何判断指定列是否(全部)为NaN(空值)
判断某列是否有NaN df['$open'].isnull().any() # 判断open这一列列是否有 NaN 判断某列是否全部为NaN df['$open'].isnull().all() # ...
- pandas 筛选某一列最大值最小值 sort_values、groupby、max、min
高效方法: dfs[dfs['delta'].isnull()==False].sort_values(by='delta', ascending=True).groupby('Call_Number ...
- ext js 4.0 grid表格根据列值的不同给行设置不同的背景颜色
Code: Ext.create('Ext.grid.Panel', { ... viewConfig: { getRowClass: function(record) { return record ...
- pandas神坑:如果列有NAN,则默认给数据转换为float类型!给pandas列指定不同的数据类型。
今天碰到一个错误,一个字典取值报keyError, 一查看key, 字符串类型的数字后面多了小数点0, 变成了float的样子了. 发现了pandas一个坑:如果列有NAN,则默认给数据转换为floa ...
- Pandas 筛选操作
# 导入相关库 import numpy as np import pandas as pd 在数据处理过程中,经常会遇到要筛选不同要求的数据.通过 Pandas 可以轻松时间,这一篇我们来看下如何使 ...
随机推荐
- 3.windows-oracle实战第三课 -表的管理
oracle的核心 多表查询.存储过程.触发器 字符型: char 定义 最大2000字符,例如“char(10) '小韩' 前4个字符放小韩,后添加6个空格补全,查询极快 varchar2(2 ...
- IntelliJ IDEA 2019.2.2在16GB内存下的性能调优
开发工具 IntelliJ IDEA 2019.2.2 x64 idea64.exe.vmoptions -m -m -XX:ReservedCodeCacheSize=m -XX:+UseConcM ...
- MJServer部署
工具: 1.jdk-8u60-macosx-x64.dmg 2.MjServer.zip 3.eclipse-jee-kepler-SR2-macosx-cocoa-x86_64.tar.gz 4.a ...
- 流程控制 if-while-for -语句
if 语句是用来判断条件的真假,是否成立,如果为ture就执行,为flase则跳过 1.python用缩进表示代码的归属 2.同一缩进的代码,称之为代码块,默认缩进4个 if 语句结构 ...
- set_include_path详细解释(转)
首先我们来看这个全局变量:__FILE__它表示文件的完整路径(当然包括文件名在内)也就是说它根据你文件所在的目录不同,有着不同的值:当然,当它用在包行文件中的时候,它的值是包含的路径: 然后:我们看 ...
- Git log 中文乱码
以下三条命令搞定(系统是centos 7.4) git config --global i18n.commitencoding utf-8 git config --global i18n.logo ...
- centos7 国内镜像yum安装mysql5.7
我这里是采用纯净的系统,刚装的centos7,而且选择的最小安装所以基本上是什么环境都没有的,然后这篇文章主要针对于小白 检查mysql环境是否已存在 虽然我的是纯净系统,但别人的不能保证,为了避免发 ...
- Maven 仓库搜索服务和私服搭建
Maven 仓库搜索服务 使用maven进行日常开发的时候,一个常见问题就是如何寻找需要的依赖,我们可能只知道需要使用类库的项目名称,但是添加maven依赖要求提供确切的maven坐标,这时就可以使用 ...
- 2019-2020-1 20199324《Linux内核原理与分析》第三周作业
第二章 操作系统是如何工作的 一.知识点总结 1.计算机的三个法宝 存储程序计算机 函数调用堆栈机制.堆栈:是C语言程序运行时必须使用的记录函数调用路径和参数存储的空间. 中断 2.堆栈相关的寄存器和 ...
- 因为AI,所以爱
作为技术驱动型公司 自我颠覆的核心就是技术上有所突破 2019技术奇点大会上,创始人行在提出 「未来,大数据和人工智能 将成为商业升级的智能发动机」 这与我们的使命不谋而合 时间退回到2016年的冬天 ...