从零自学Hadoop(07):Eclipse插件
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们的第一个Cluster搞定了,按平常的搭建集群来说,应该是至少3个DataNode的,应为默认的一份HDFS文件分成3份,所以最少也得3个DataNode的服务器,但由于本机就一块硬盘,内存也不大,所以,勉强的用2份。
在这里我们开始使用MyCluster了,有个Eclipse的插件用上去后,对HDFS文件的处理就比较方便了,我们开始吧!
Eclipse
我们直接去官网下个Eclipse,不要太旧的就行了。为了大家的方便,下面放一个官网的地址。
Eclipse插件
一:原因
为什么要用这个插件了?有什么好处了?
因为我们待分析的文件需要从客户端通过rpc传到NameNode,所以在linux中,是找不到这个文件的,相当于是做了个隔离,所以用个插件就很方便的上传这些文件了,还可以查看目录结构,文件内容。分析后结果也是很方便的查看的到。
二:地址
https://github.com/winghc/hadoop2x-eclipse-plugin
在Release中,我们可以看到有3个编译好的jar包。都是2.0以上的版本,所以对于hadoop2.0以上的都可以用。
三:安装
将插件放入eclipse的插件目录,“eclipse\plugins”。
重启Eclipse
进入Windows->Preferences
选择Hadoop的路径
四:查Hadoop配置信息
首先,我们得知道我们的NameNode和HDFS的地址。
我们进入ambari登陆页面。
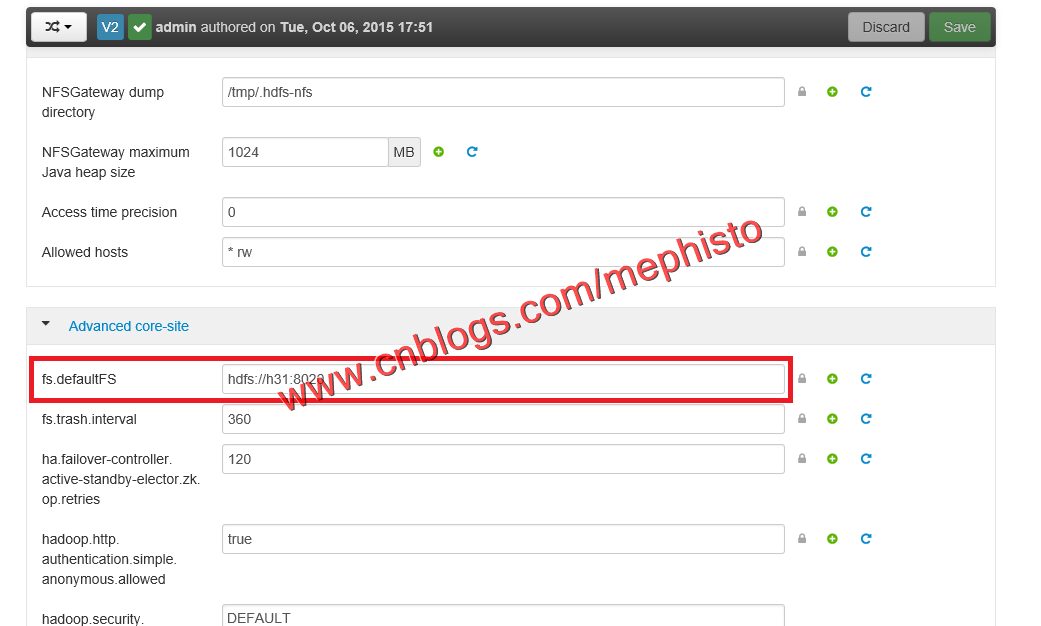
选中HDFS->Config,圈中的就是HDFS的地址。
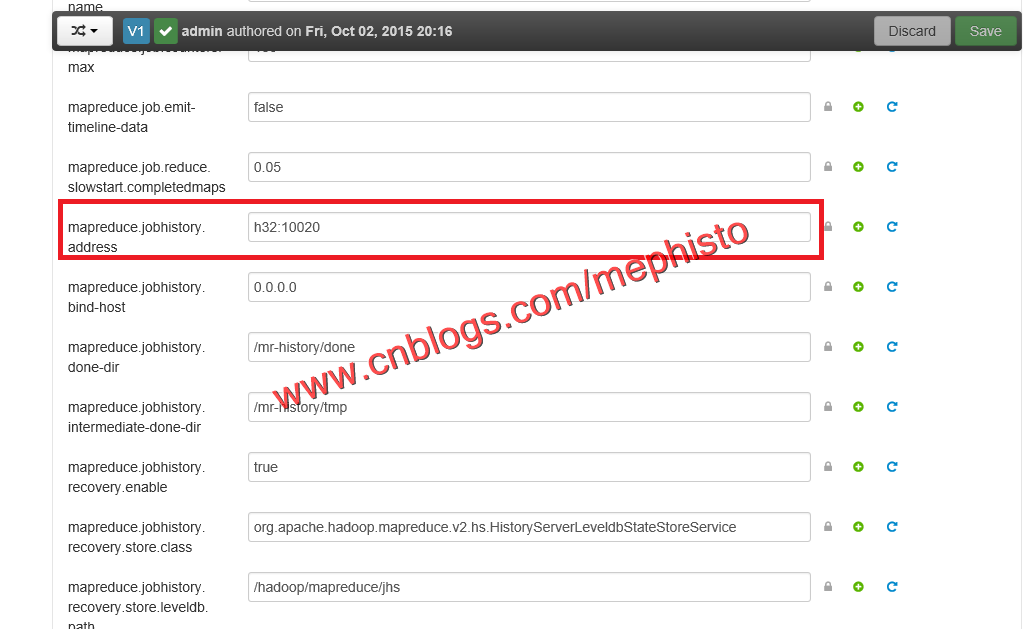
选中MapReduce2->Config,圈中的就是MapReduce地址
五:配置
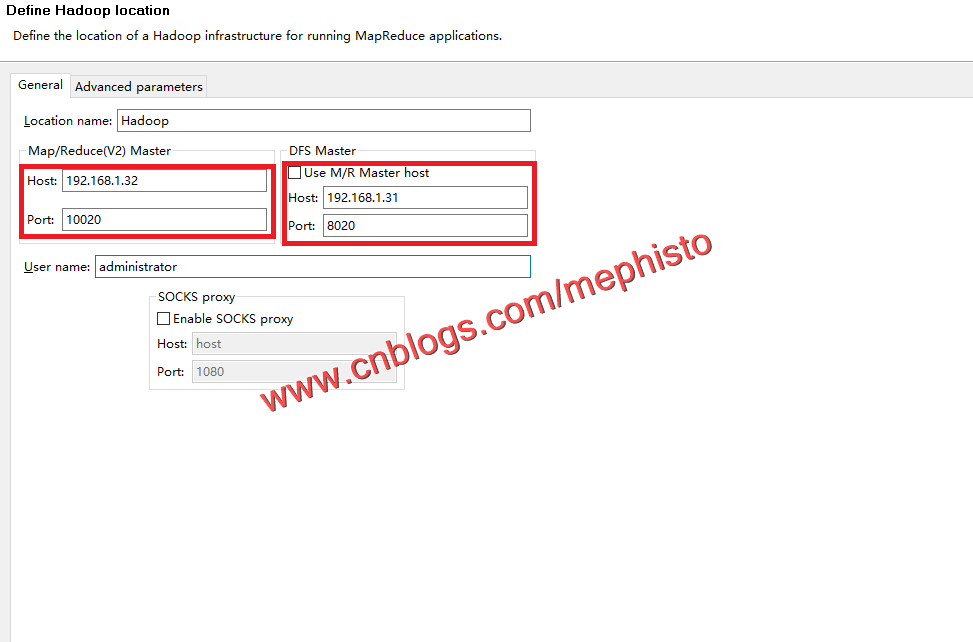
打开Eclipse插件,右键新建一个Hadoop location
编辑圈中的地方。
六:连接
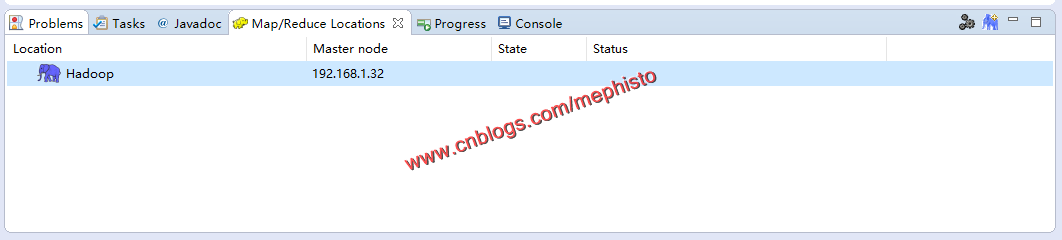
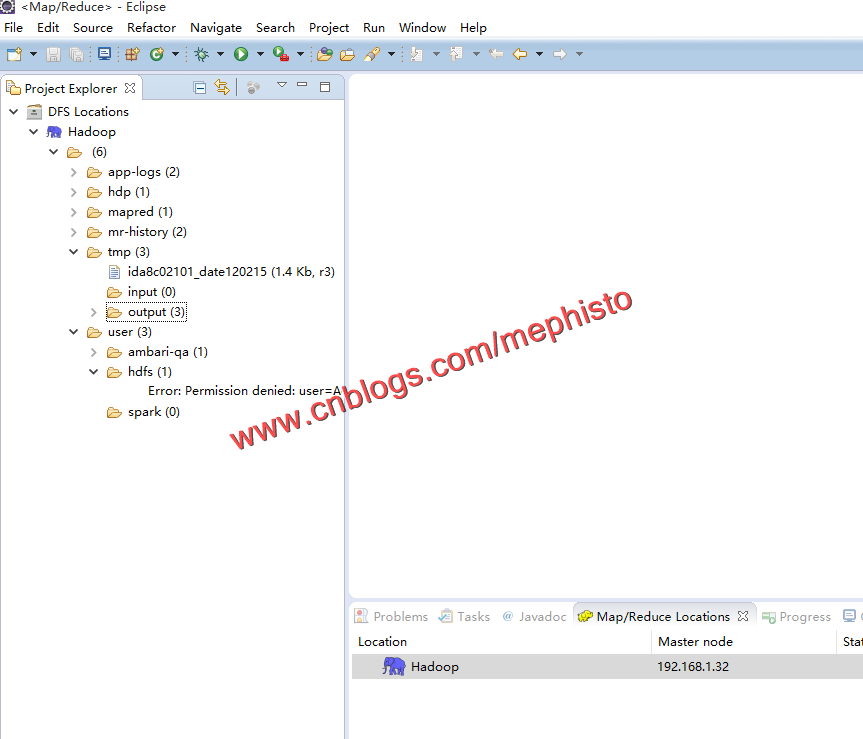
双击DFS Locations_>Hadoop
就可以看到如下的目录结构

新建插件项目
一:新建项目
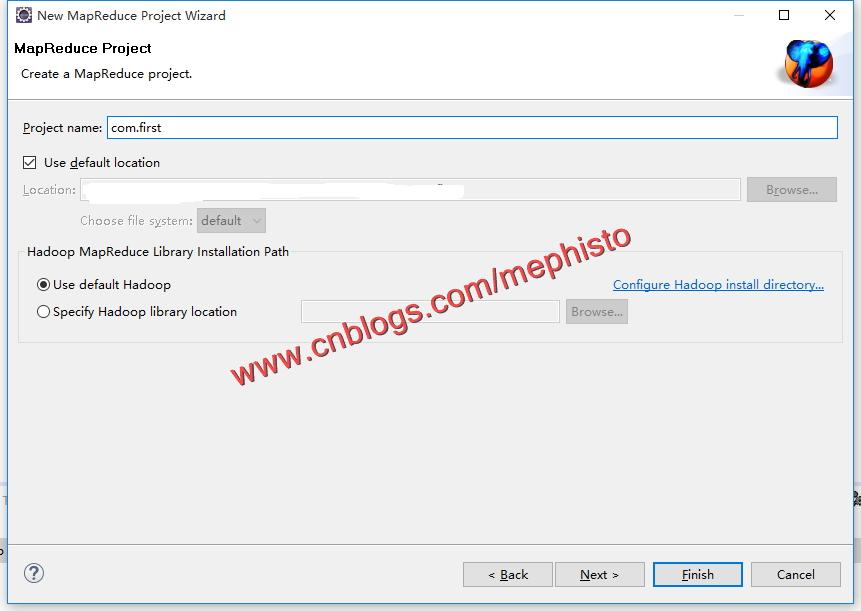
打开File->New Project->Map/Reduce Project
下一步,输入项目名称。
点击完成,我们可以看到一个简易的Map/Reduce项目完成。
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。


系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
从零自学Hadoop(07):Eclipse插件的更多相关文章
- 从零自学Hadoop系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 从零自学Hadoop(01):认识Hadoop ...
- 从零自学Hadoop(08):第一个MapReduce
阅读目录 序 数据准备 wordcount Yarn 新建MapReduce 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是 ...
- 从零自学Hadoop(09):使用Maven构建Hadoop工程
阅读目录 序 Maven 安装 构建 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Source ...
- 从零自学Hadoop(11):Hadoop命令上
阅读目录 序 概述 Hadoop Common Commands User Commands Administration Commands File System Shell 引用 系列索引 本文版 ...
- 从零自学Hadoop(22):HBase协处理器
阅读目录 序 介绍 Observer操作 示例下载 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,Sour ...
- Hadoop2 自己动手编译Hadoop的eclipse插件
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- 从零自学Hadoop(20):HBase数据模型相关操作上
阅读目录 序 介绍 命名空间 表 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(21):HBase数据模型相关操作下
阅读目录 序 变量 数据模型操作 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 ...
- 从零自学Hadoop(19):HBase介绍及安装
阅读目录 序 介绍 安装 系列索引 本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作. 文章是哥(mephisto)写的,SourceLink 序 上一篇, ...
随机推荐
- WCF局域网内使用代理无法访问解决方法
问题描述 在大部分事业单位上网都是需要使用代理的,前几天带着一个同事写的程序过来部署,部署以后各个客户端通过WCF相互通讯,那么其中一个地方在本地局域网测试是没有问题的. 后发现一部分是原因是由于代理 ...
- 解决ASP.NET Core Mvc文件上传限制问题
一.简介 在ASP.NET Core MVC中,文件上传的最大上传文件默认为20MB,如果我们想上传一些比较大的文件,就不知道怎么去设置了,没有了Web.Config我们应该如何下手呢? 二.设置上传 ...
- C# 委托应用总结
一.什么是委托 1.1官方解释 委托是一种定义方法签名的类型.当实例化委托时,您可以将其实例与任何具有兼容签名的方法相关联.您可以通过委托实例调用方法. 1.2个人理解 委托就是执行方法(函数)的一个 ...
- mysql 日期函数总结
1.0 格式化:DATE_FORMAT() 函数用于以不同的格式显示日期/时间数据. 语法 DATE_FORMAT(date,format) date 参数是合法的日期.format 规定日期/时间的 ...
- SQL Server 2005 数据库 可疑状态
KJDY数据库名称 ALTER DATABASE KJDY SET EMERGENCY ---修改数据库为 紧急模式 ALTER DATABASE KJDY SET SINGLE_USER ---单用 ...
- html5数字和颜色输入框
html5功能强大,数字和颜色输入框例子 效果:http://hovertree.com/code/html5/rxujb6g8.htm <!DOCTYPE html> <html& ...
- 【MVC拾遗】MVC的单元测试简单学习总结
关于测试的必要性什么的已经在 重构与测试 里扯过了.倒也没必要说,写的代码多了自然就明白这个东西重要性. 当时说了坐等被推动去学习单元测试来着,然而等着被人推动的结果就是根本就没人来推你.o(∩_∩) ...
- Hibernate总结(三)
在Hibernate(二)中,简单总结了表与表之间的级联操作,但是并没有总结查询操作,这一篇将总结Hibernate查询所实现的加载策略. 加载策略: 立刻加载:马上去数据库中查询 延迟加载:当使用数 ...
- [翻译] Autoac 最佳实践和建议
使用嵌套的 ILifetimeScope 解析服务 Autofac 被设计为跟踪(track)和清理(dispose)资源.为确保资源被正确处理,务必将长时间运行的应用程序分成小的工作单元 (请求或事 ...
- keleyi菜单0.1.5版本发布了
keleyi菜单是一个让你轻松创建向上弹出菜单的jquery插件. 最新版本0.1.5增加了显示三角形的功能,当一级菜单包含有子菜单时,会在一级菜单的右侧显示一个小三角形.如图所示: 查看例子:htt ...