【Django+Element UI】使用一个接口文件,搞定分页获取数据,模糊查询后分页获取数据
1:序列化获取数据的接口设计
1:分页获取序列化数据 2:是个能传参数的接口
class Society(APIView): def post(self, request):
keywords = str(request.data.get("keywords"))
data = {}
try:
s_data = models.Society.objects.filter(name__contains=keywords).order_by('id') # 模糊查询 pg = PageNumberPagination()
pg.max_page_size = 200
pg.page_size_query_param = "size"
pager_roles = pg.paginate_queryset(queryset=s_data, request=request, view=self)
ser = PagerSerialiser(instance=pager_roles, many=True)
data["code"] = 200
data["count"] = len(s_data) # 获取总数量
data["data"] = ser.data
return Response(data)
except Exception as e:
data["code"] = 444
data["message"] = "请求异常"
return JsonResponse(data)
2:前端代码的设计
1:创建2个关键词keywords_raw,keywords,当没有使用搜索功能时,我们传上去的是keywords,它是空值,所以接口会返回给我们所有的数据,分页请求的keywords也是空值,所以这个时候的请求数据是所有的 2:当我们在输入框上输入了关键词keywords_raw,点击时,这个时候将keywords_raw的值赋值给keywords,这样子去请求就可以做到搜索关键词后的分页点击是属于搜索关键词的数据 代码: HTML:
<input type="text" class="form-control" placeholder="输入关键词查找社团" v-model="keywords_raw"> <button @click="search"> 搜索</button> JS: data:{
keywords_raw: "",
keywords: "",
} // 钩子函数渲染数据
created() {
// 数据渲染
axios.post('/society/get/?page=1&size=6', {
keywords: this.keywords # 上传的参数是keywords 这个时候还是空值,请求的数据是所有的
}).then(response => {
this.totals = parseInt(response.data.count)
response.data.data.some((item, i) => {
this.society_data.unshift({
societHead: item.head,
societUser: item.user,
societName: item.name,
societMember: item.member,
societTime: item.time.substring(0, 10),
pk: item.id,
})
})
}).catch(error => {
alert("请重新登录")
window.location.href = '/login/'
})
} // 搜索:
// search
search() {
if ( this.keywords_raw == "") {
alert("输入框不能为空")
} else {
this.society_data =[]
// 请求的时候赋值给keywords
this.keywords =this.keyword_raw # 直接同步两个参数
axios.post('/society/get/?page=1&size=6', {
keywords: this.keywords_raw
}).then(response => {
this.totals = parseInt(response.data.count)
response.data.data.some((item, i) => {
this.society_data.unshift({
societHead: item.head,
societUser: item.user,
societName: item.name,
societMember: item.member,
societTime: item.time.substring(0, 10),
pk: item.id, })
})
}).catch(error => {
console.log(error) })
}
} // 分页
handleSizeChange(val) {
console.log(`每页 ${val} 条`);
},
handleCurrentChange(val) { this.society_data = [],
axios.post('/society/get/?page=' + val + '&size=6', {
keywords: this.keywords # 上传的是参数是关键词
}).then(response => {
this.totals = parseInt(response.data.count)
response.data.data.some((item, i) => {
this.society_data.unshift({
societHead: item.head,
societUser: item.user,
societName: item.name,
societMember: item.member,
societTime: item.time.substring(0, 10),
pk: item.id, })
})
}).catch(error => {
console.log(error) })
},
3:效果图
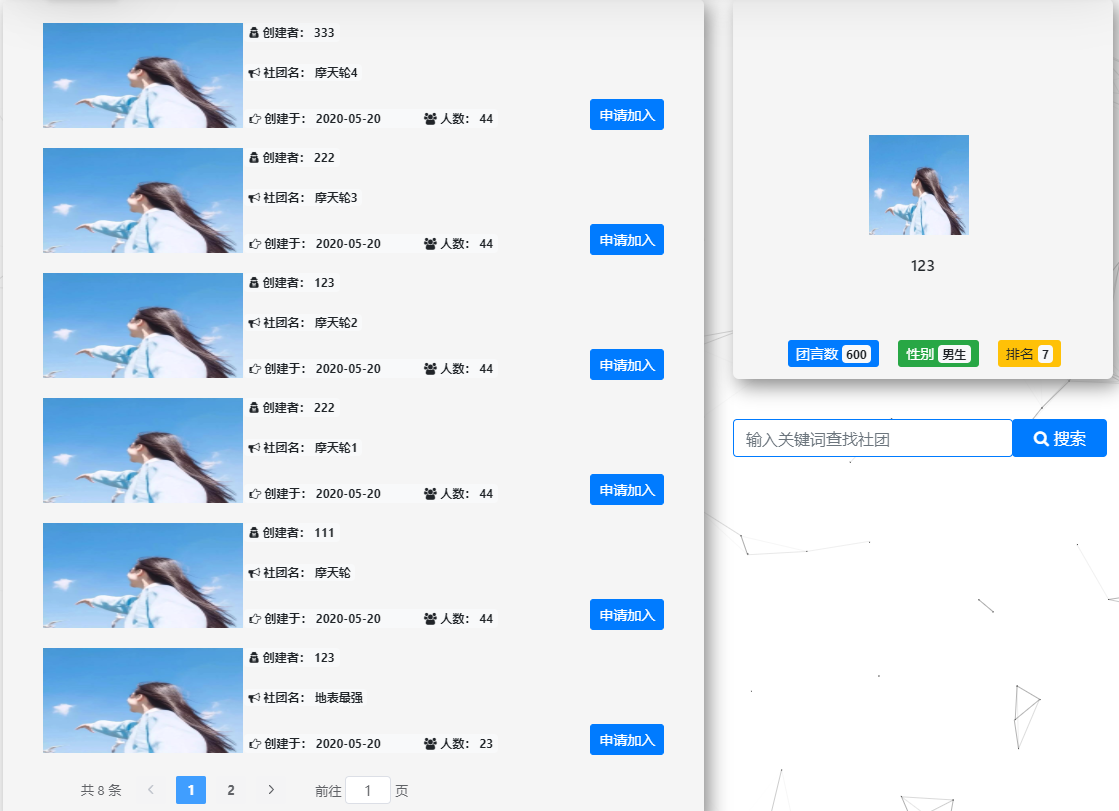
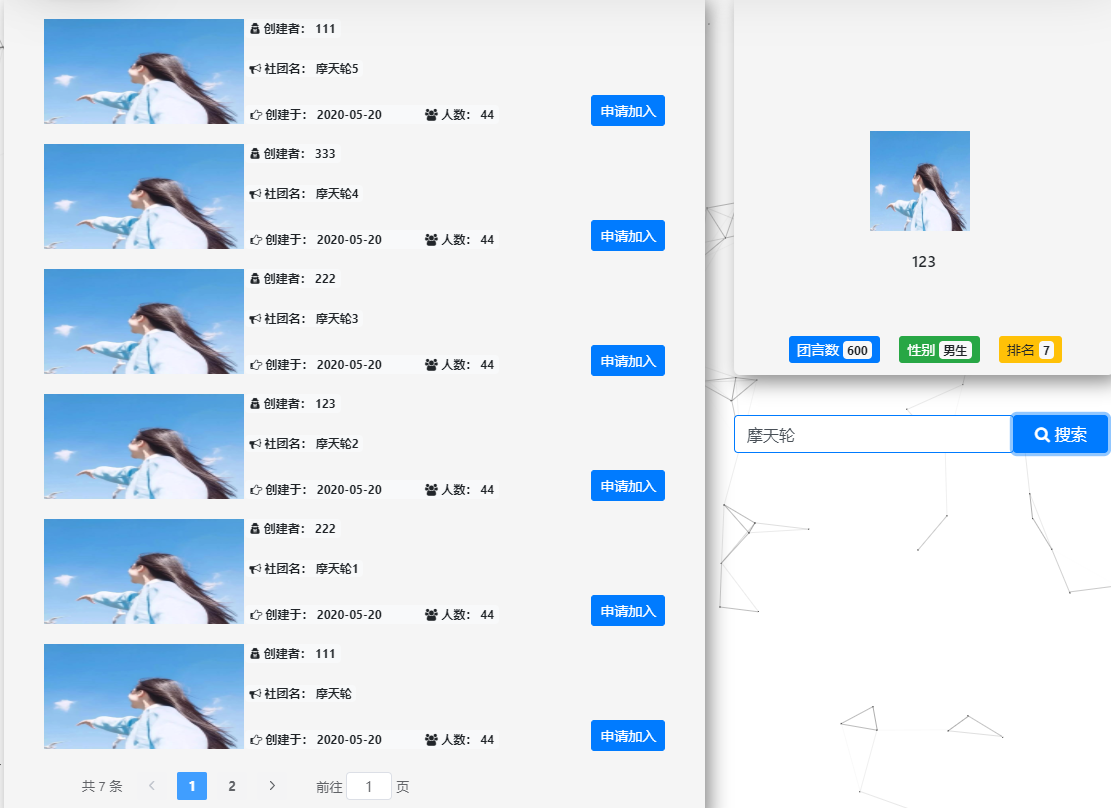
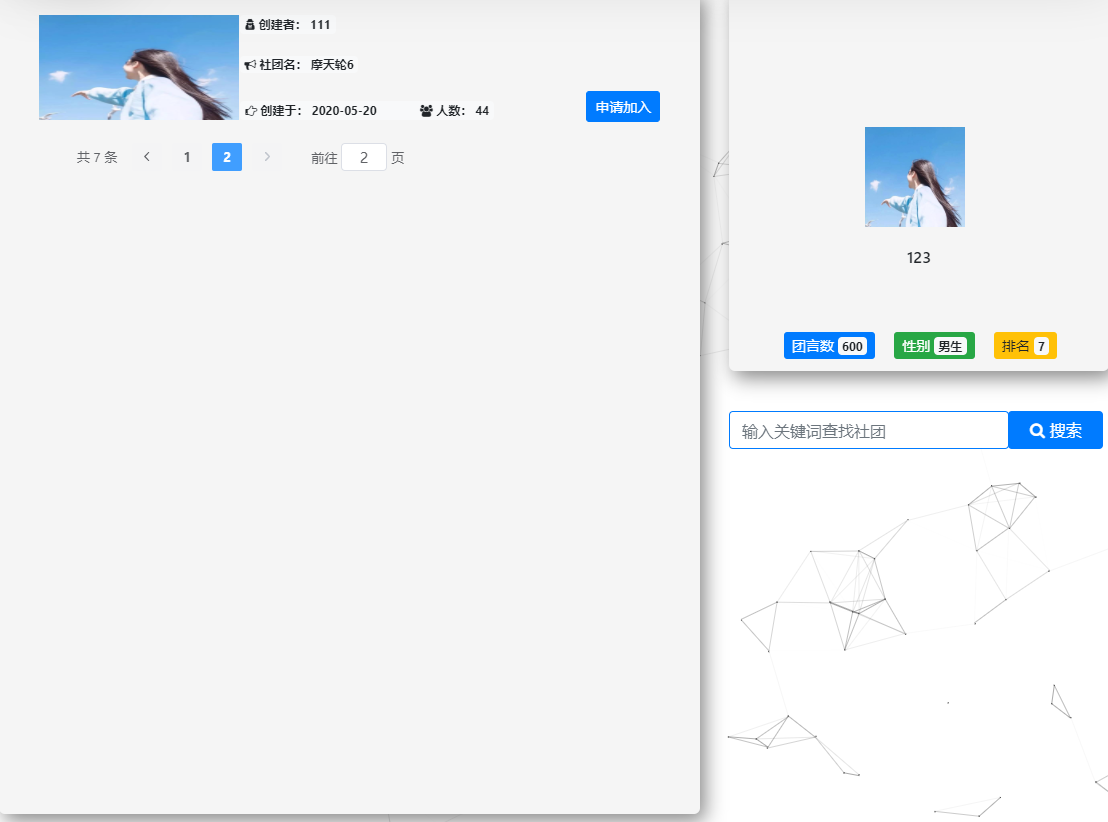

【Django+Element UI】使用一个接口文件,搞定分页获取数据,模糊查询后分页获取数据的更多相关文章
- 一个PHP文件搞定微信H5支付
/ 更新于 2018-07-02 / 8 条评论 过年期间也坚持要撸码啊接着给博客除草,在这个小除夕是情人节的一天,祝大家新年快乐,情人节能够顺利脱单~~~ 回归正题,这篇文章介绍一下微信H5支付, ...
- 转:C4项目中验证用户登录一个特性就搞定
转:C4项目中验证用户登录一个特性就搞定 在开发过程中,需要用户登陆才能访问指定的页面这种功能,微软已经提供了这个特性. // 摘要: // 表示一个特性,该特性用于限制调用 ...
- 企业sudo权限规划详解 (实测一个堆命令搞定)
简述问题: 随着公司的服务器越来越多,人员流动性也开始与日俱增,以往管理服务器的陈旧思想应当摒弃,公司需要有 更好更完善的权限体系,经过多轮沟通和协商,公司一致决定重新整理规划权限体系 ...
- 编写Java程序,在硬盘中选取一个 txt 文件,读取该文档的内容后,追加一段文字“[ 来自新华社 ]”,保存到一个新的 txt 文件内
查看本章节 查看作业目录 需求说明: 在硬盘中选取一个 txt 文件,读取该文档的内容后,追加一段文字"[ 来自新华社 ]",保存到一个新的 txt 文件内 实现思路: 创建 Sa ...
- django实战(二)--带多字段模糊查询的分页(也是不容易)
上节我们实现了分页功能,这节我们要实现对模糊查询后的结果进行分页.(引入了bootstrap框架) urls.py from django.urls import path from . import ...
- ASP.NET MVC搭建项目后台UI框架—6、客户管理(添加、修改、查询、分页)
目录 ASP.NET MVC搭建项目后台UI框架—1.后台主框架 ASP.NET MVC搭建项目后台UI框架—2.菜单特效 ASP.NET MVC搭建项目后台UI框架—3.面板折叠和展开 ASP.NE ...
- java 查询路径中所有文件夹和文件的名称,支持文件名模糊查询
java 查询路径中所有文件夹和文件的名称,支持文件名模糊查询 有时候我们遇到需要查询服务器或者本机某个路径下有哪些文件?或者根据文件名称模糊搜索文件,那么就可以使用本方法:可以获取某个路径下所有文件 ...
- vue+element ui 的上传文件使用组件
前言:工作中用到 vue+element ui 的前端框架,使用到上传文件,则想着封装为组件,达到复用,可扩展.转载请注明出处:https://www.cnblogs.com/yuxiaole/p/9 ...
- Django+element ui前后端不分离的博客程序
最近把去年写的一个烂尾博客(使用了django1.11和element ui)又重新完善了一下,修改了样式和增加了新功能 github链接:https://github.com/ngauerh/Nag ...
随机推荐
- 萌新带你开车上p站(番外篇)
本文由“合天智汇”公众号首发,作者:萌新 前言 这道题目应该是pwnable.kr上Toddler's Bottle最难的题目了,涉及到相对比较难的堆利用的问题,所以拿出来分析. 登录 看看源程序 程 ...
- tp5.1 模型 where多条件查询 like 查询
来源:https://blog.csdn.net/qq_41241684/article/details/87866416 所以我改成这样: $paperTypeModel = new PaperTy ...
- Task Scheduler API Error 80041318
https://stackoverflow.com/questions/42307917/task-scheduler-api-error-80041318/42462235#42462235 Hi ...
- Spring5参考指南:SpringAOP简介
文章目录 AOP的概念 Spring AOP简介 Spring AOP通知类型 写过程序的都知道OOP即面向对象编程. 从最开始的面向过程编程,到后面的面向对象编程,程序的编写方式发生了重大的变化,面 ...
- 分享一批国内常用的tracker地址
本期先分享一批国内能用地址,下一期我会出一期取代迅雷的下载的工具教程. udp://p4p.arenabg.com:1337/announce udp://tracker.tiny-vps.com:6 ...
- 杭电60题--part 1 HDU1003 Max Sum(DP 动态规划)
最近想学DP,锻炼思维,记录一下自己踩到的坑,来写一波详细的结题报告,持续更新. 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1003 Problem ...
- 2019 ICPC 银川网络赛 D. Take Your Seat (疯子坐飞机问题)
Duha decided to have a trip to Singapore by plane. The airplane had nn seats numbered from 11 to nn, ...
- CentOS安装boost
安装其实很简单的: tar zxvf boost_1_59_0.tar.gz cd boost_1_59_0 ./bootstrap.sh --prefix=/usr/local/boost ./b2 ...
- UIResponder相关
UIResponder是OC中一个响应事件的类.UIApplication.UIView.UIViewController都是它的子类.UIWindow是UIView的子类,因此也能响应事件. UIR ...
- CSS中的间距设置与盒子模型
CSS间距 内补白 外补白 盒子模型 CSS间距 很多时候我们为了美观,需要对内容进行留白设置,这时候就需要设置间距了. 内补白 设置元素的内间距 padding: 检索或设置对象四边的内部边距 pa ...